React Native에서 STT-TTS를 활용해 GPT와 음성으로 대화하도록 구현

개요
OpenAI의 Realtime API는 비용이 매우 비싸다. 또 우리는 어시스턴트 API를 사용하고 있었고, 여기에 보이스 모드를 구현하는 것이 목표였다.
API 비용을 최대한 아끼기 위해 OpenAI의 Whisper를 사용하는 대신 STT는 앱 내에서 구현하고, TTS만 OpenAI의 TTS를 활용하는 방향은 어떨지 제안했고, 직접 가능성을 테스트하게 됐다.
처음에는 GPT 앱의 voice 모드를 참고해 어시스턴트가 답변을 생성/재생하는 도중 사용자가 말을 끊으면 답변 생성/재생을 취소하도록 구현하려 했으나, 스피커 환경에서의 하울링과 채팅 상태관리의 어려움, 여러 예외 상황에서 발생하는 의도치 않은 동작 등으로 인해 결국 포기했다.
그 대신 핑퐁 방식으로 대화하도록 설계를 변경했고, 정상적으로 작동하는 것을 확인했다. 핑퐁 방식을 간단하게 요약하면
- 사용자가 voice 모드를 켜면 STT 시작, 끄면 STT 종료
- 사용자의 음성이 인식된 후, 2초간 인식되지 않으면 STT 종료
- 인식된 음성을 사용해 어시스턴트 API Run 수행
- 어시스턴트의 답변을 사용해 TTS API 요청
- TTS API의 응답을 받아 재생
- 재생이 끝나면 STT 시작
이런 식으로 사용자가 말을 멈추면 어시스턴트의 답변이 끝날 때까지 STT를 막는 방식이다. 사용자의 동작을 앱 로직에 가둔다는 점이 조금 마음에 걸리지만, 테스트 해보니 그렇게 불편하지는 않았다. 디테일만 잘 다듬는다면(유저 텍스트 박스를 첫 음성 인식 때 생성하는 등) 충분해 보였다.
이번 포스트에서는 해당 기능을 구현하기까지 있었던 일을 간략히 요약하고, 최종적으로 구현에 성공했던 흐름을 정리해보려고 한다.
라이브러리 선택
STT-TTS를 위한 라이브러리를 써보고, 문제가 있으면 다른 라이브러리로 변경해서 다시 테스트해보는 등의 작업을 진행했다.
최종적으로 선택한 라이브러리는 아래와 같다.
- STT: expo-speech-recognition
- FileSystem: expo-file-system
- TTS play: expo-av
1. STT 라이브러리 선택
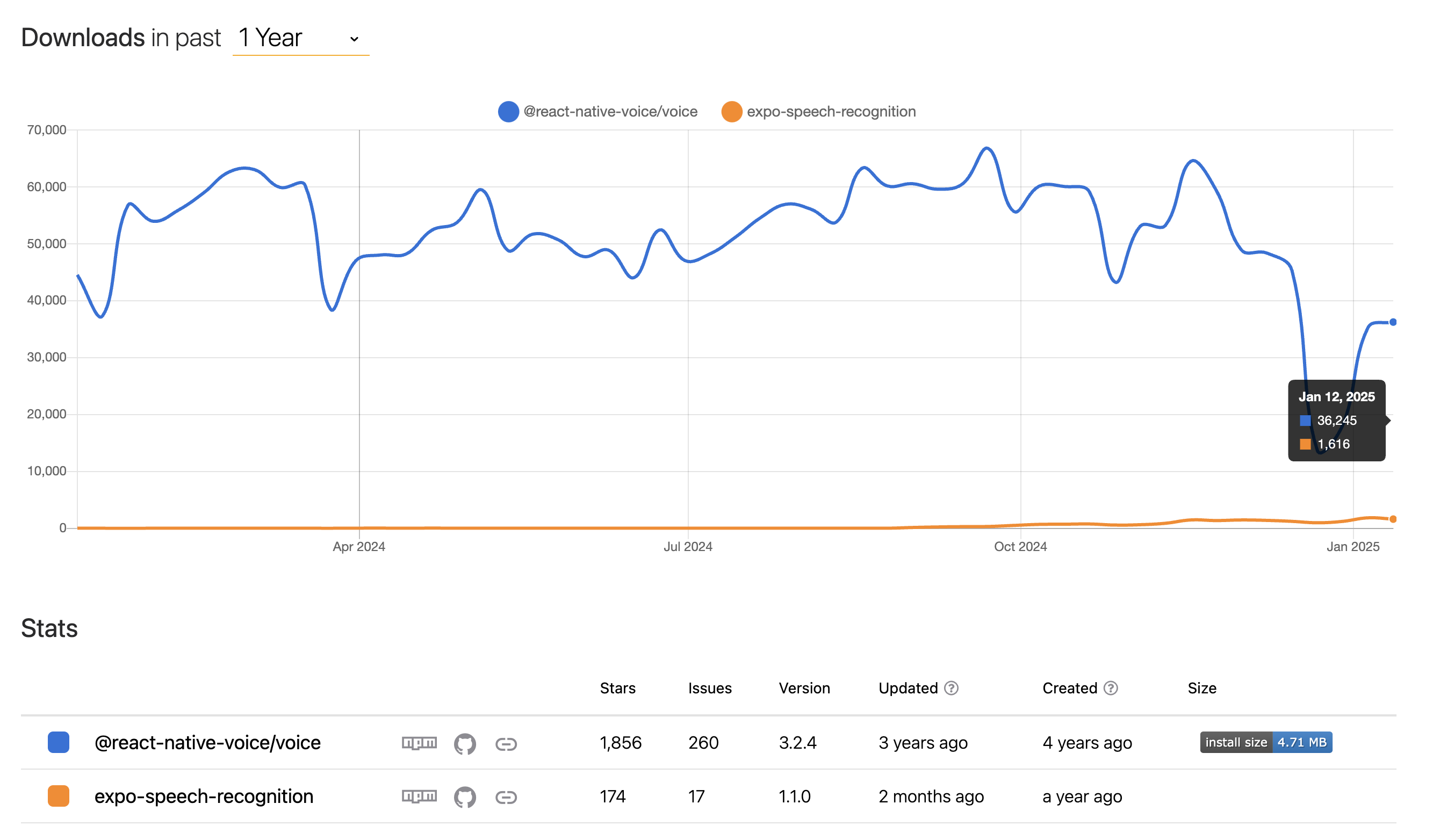
기존에 알던 STT 라이브러리는 @react-native-voice/voice가 있다. 예전에 SeSAC 해커톤에 참여했을 때도 STT 기능이 필요해 해당 라이브러리를 사용했었다.
이번 개발에서도 해당 라이브러리를 사용해봤으나, 몇 가지 문제점이 있었다.
- 음성 인식 객체에 취소/초기화 등의 작업이 불가능해 음성 인식 객체 자체를 삭제/생성해 STT를 끄고 켜야 하는데, 이 과정의 딜레이가 생각보다 길어 반응이 느림
- 3년간 유지 보수가 멈춤 -> 안드로이드 빌드 에러 존재, RN 새 아키텍쳐 미지원
- 버튼을 눌러 음성 인식을 시작/종료하는 흐름으로 설계되어 우리 앱의 목적에 맞추려면 직접 흐름을 구현해야 했고, 그 결과 여러가지 예기치 않은 동작이 발생
구현하며 문제가 생길 때마다 Github Issue를 주로 찾아봤는데, 대부분 라이브러리 코드를 직접 수정하는 patch-package로 해결하고 있는 것 같았다. 이제 막 시작하는 프로젝트에서 유지 보수가 되고 있지 않은 라이브러리를 사용하고 싶지 않았다.
그러던 도중 한 개발자의 댓글을 통해 expo-speech-recognition 라이브러리의 존재를 알게 되었다. 출시된지 1년 된 라이브러리로 사용자 수는 많지 않지만 README가 잘 작성되어 있었기에 한 번 테스트해보자는 마음으로 사용했고, 결과적으로 매우 만족하는 결과를 얻었다.
- 음성 인식 객체를 종료/시작할 때 딜레이가 짧아 반응이 빠름
- 유지 보수가 활발하고, 개발자가 회사에서 직접 사용하고 있어 앞으로도 적극적으로 관리될 것으로 보임
- 음성 인식 이벤트 값에
isFinal필드가 존재해, 최종 인식 결과인지를 쉽게 파악할 수 있음 - 이벤트 리스너 훅을 제공해줘 앱의 목적에 맞게 흐름을 구현하기 수월했고 예외 상황 컨트롤이 쉬움
두 라이브러리를 각각 사용해본 결과, 모든 면에서 expo-speech-recognition이 좋았기 때문에 실제 개발에서도 해당 라이브러리를 사용하기로 결정했다.
2. TTS 재생 라이브러리 선택
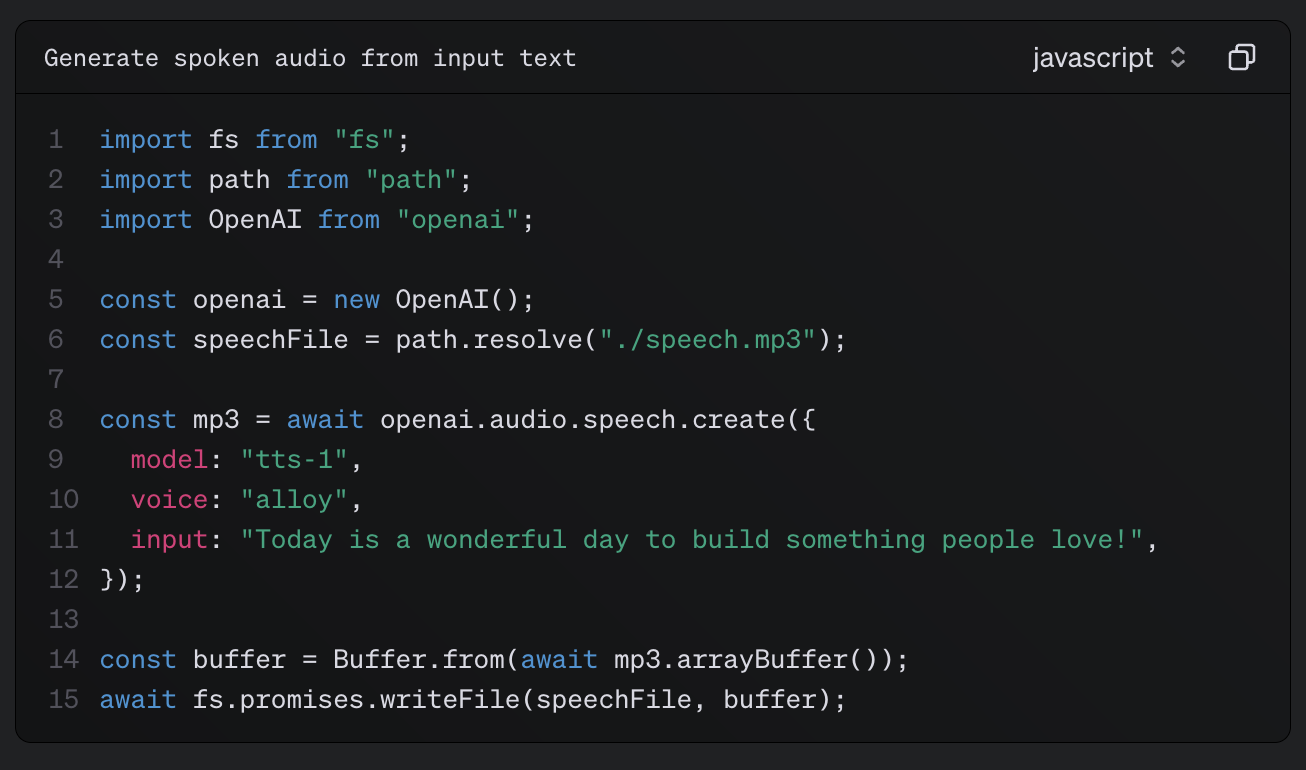
OpenAI TTS 공식 문서를 보면, 응답을 수신해 파일 형태로 저장해야 한다는 것을 알 수 있다.
TTS 데이터를 mp3 파일 형식으로 저장하기 위한 파일 시스템 라이브러리는 expo-file-system을 선택했고, mp3 파일을 재생하기 위한 라이브러리는 expo-av를 선택했다.
Expo 프레임워크를 사용하는 김에 최대한 Expo SDK를 사용하기로 했다.
expo-file-system에는 writeAsStringAsync 함수로 파일 쓰기를 수행할 수 있는데, ArrayBuffer 타입은 들어가지 않아 약간 당황했었다. 이 이야기는 아래에서 마저 진행하겠다.
STT 구현
어시스턴트 API 스트리밍 구현 포스트를 진행했던 코드에 이어서 구현하겠다.
아래 코드 구조를 베이스로 적절히 요약해가며 정리할 예정이다.
// app/index.tsx
import {
addMessageByThreadId,
createThread,
getChatbotAssistantId,
} from "@/openai";
import { useEffect, useState } from "react";
import { Text } from "react-native";
import EventSource from "react-native-sse";
import styled from "styled-components/native";
type Chat = {
id: string;
role: "assistant" | "user";
text: string;
};
type AssistantEvents =
| "thread.run.created"
| "thread.run.queued"
| "thread.run.in_progress"
| "thread.run.step.created"
| "thread.run.step.in_progress"
| "thread.message.created"
| "thread.message.in_progress"
| "thread.message.delta"
| "thread.message.completed"
| "thread.run.step.completed"
| "thread.run.completed"
| "done";
export default function Index() {
const [assistantId, setAssistantId] = useState<string | null>(null);
const [threadId, setThreadId] = useState<string | null>(null);
const [input, setInput] = useState<string>("");
const [chats, setChats] = useState<Chat[]>([]);
const handleInputChange = (text: string) => setInput(text);
const handleRun = async () => {
/* 키보드로 채팅 치고 전송 버튼 누르면 실행되는 로직 */
};
useEffect(() => {
const init = async () => {
const assistantId = await getChatbotAssistantId();
if (assistantId) setAssistantId(assistantId);
const threadId = await createThread();
if (threadId) setThreadId(threadId);
console.log("어시스턴트id, 스레드id 준비 완료");
};
init();
}, []);
return (
<Box>
<ScrollBox>
{chats.map((chat) => (
<ChatBox key={chat.id} $role={chat.role}>
<Text>
{chat.role}: {chat.text}
</Text>
</ChatBox>
))}
</ScrollBox>
<InputBox>
<Input onChangeText={handleInputChange} value={input} />
<Button onPress={handleRun}>
<Text>전송</Text>
</Button>
</InputBox>
</Box>
);
}1. 전송 버튼에 통화시작/통화종료 기능 추가
현재 STT 모드가 활성화 되었는지를 state로 관리하고, input의 길이를 활용하면 된다.
// app/index.tsx
...
export default function Index() {
...
const [isSttMode, setIsSttMode] = useState<boolean>(false);
// 버튼에 들어갈 텍스트이자, 버튼 클릭 로직의 조건을 담당
const btnText = (() => {
if (input.length !== 0) {
return "전송";
} else if (isSttMode) {
return "통화종료";
} else {
return "통화시작";
}
})();
// btnText가 전송이면, 스트리밍 방식으로 어시스턴트 API 사용하는 handleRun 함수 호출
// 전송이 아니면 stt모드 토글
const handleClickBtn = () => {
if (btnText === "전송") {
handleRun();
} else {
setIsSttMode((prev) => !prev);
}
};
...
const handleRun = async () => {
/* 키보드로 채팅 치고 전송 버튼 누르면 실행되는 로직 */
};
return (
<Box>
...
<InputBox>
<Input
onChangeText={handleInputChange}
value={input}
editable={!isSttMode}
/>
<Button onPress={handleClickBtn}>
<Text>{btnText}</Text>
</Button>
</InputBox>
</Box>
);
}isSttMode가 false일 때만 TextInput에 입력할 수 있도록 하기 위해 editable props를 사용했다. HTML의 disabled와 조건이 반대지만, 동일한 기능을 구현할 수 있는 props다.
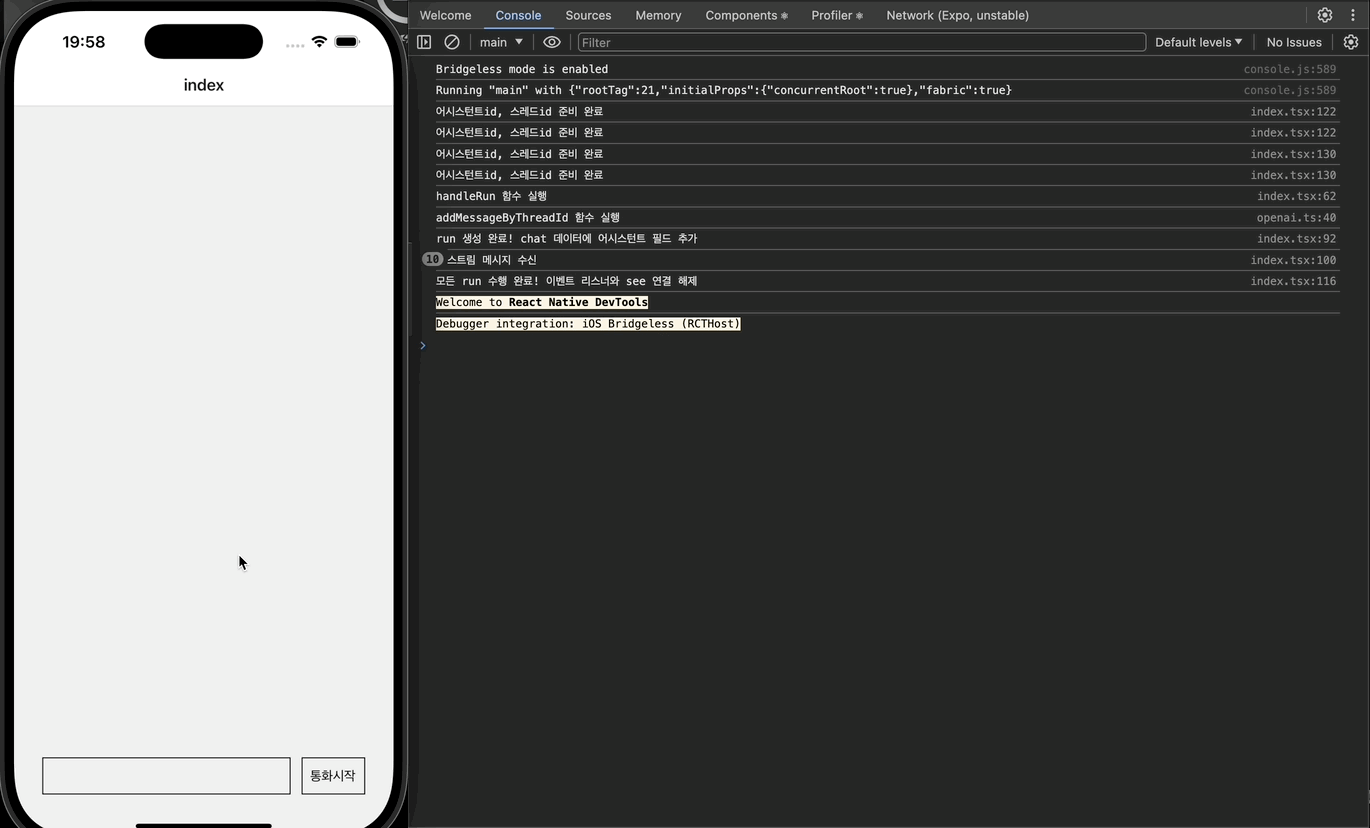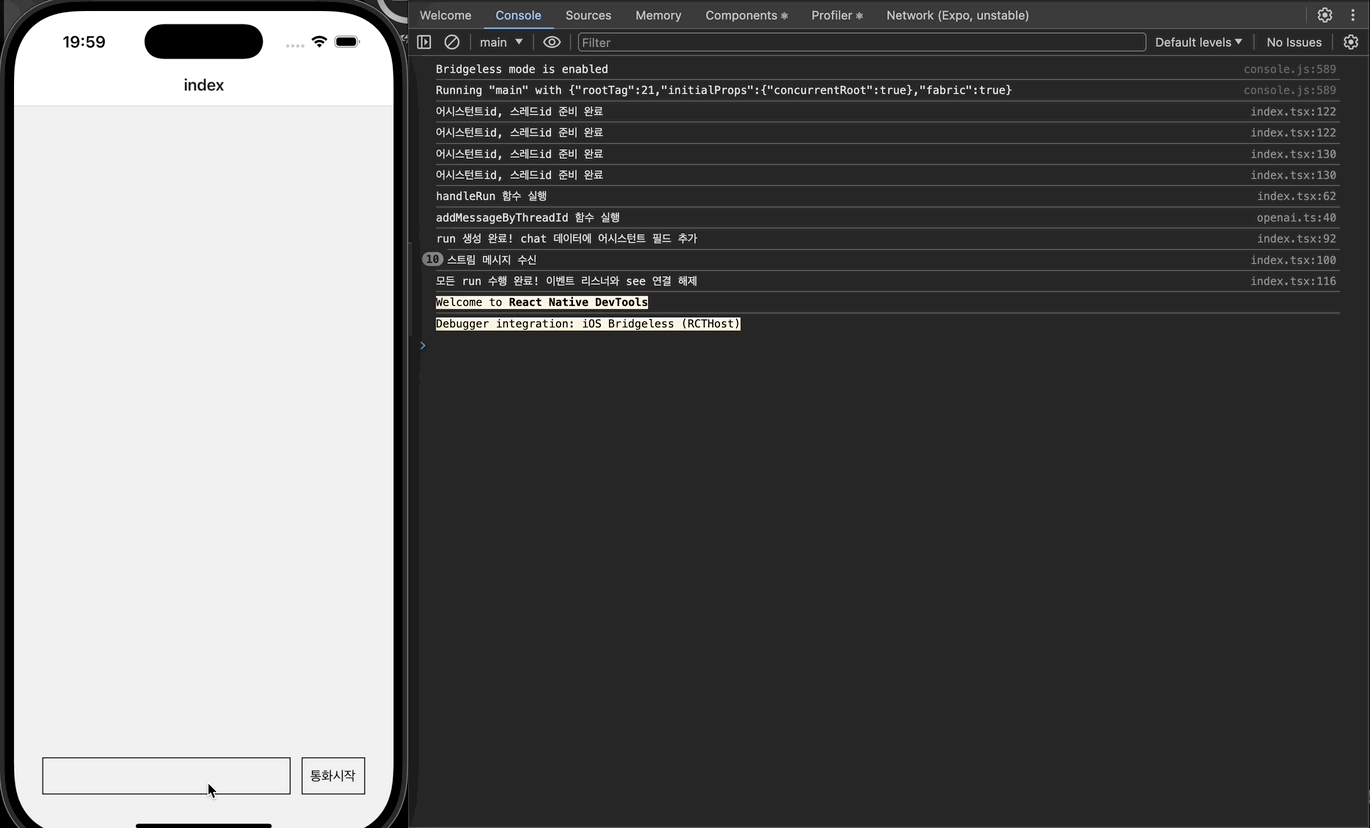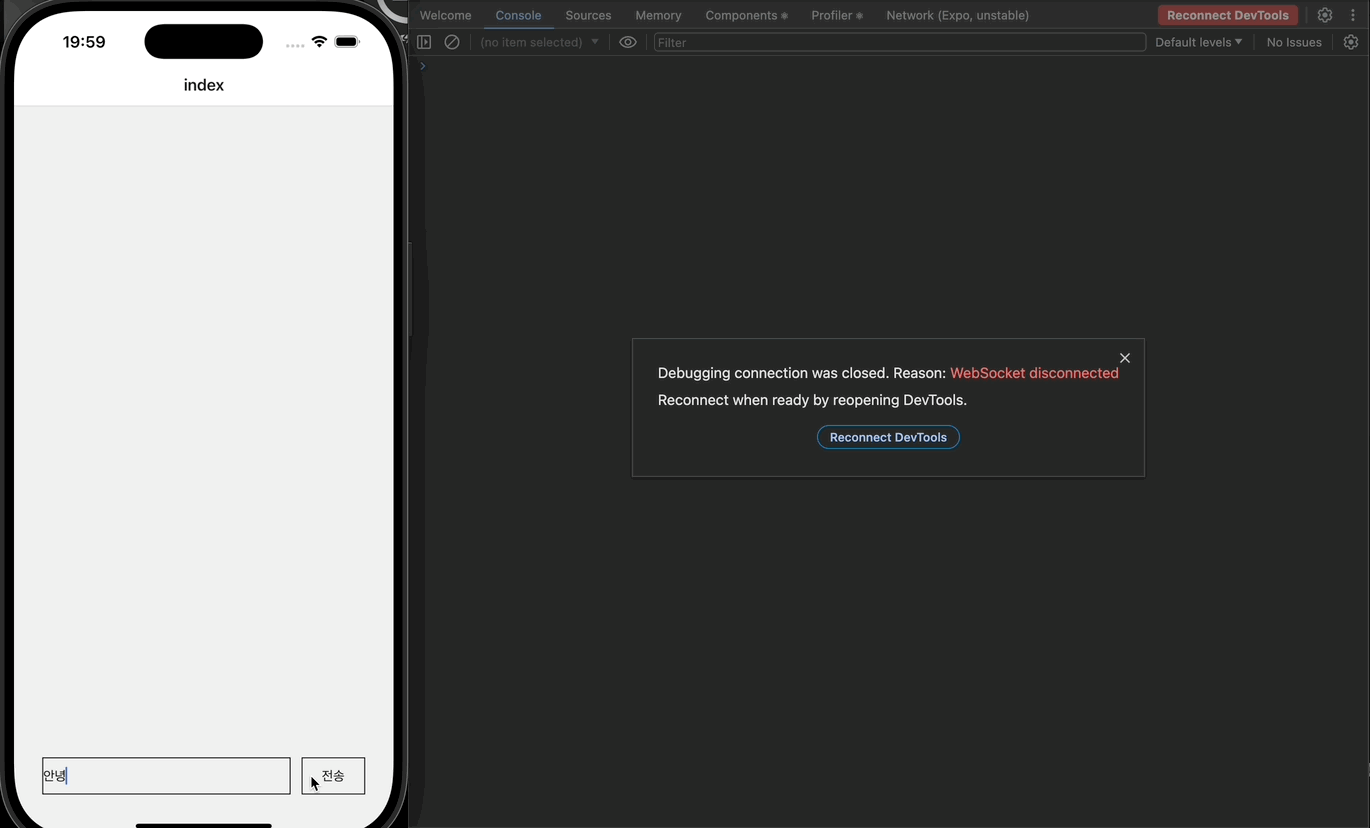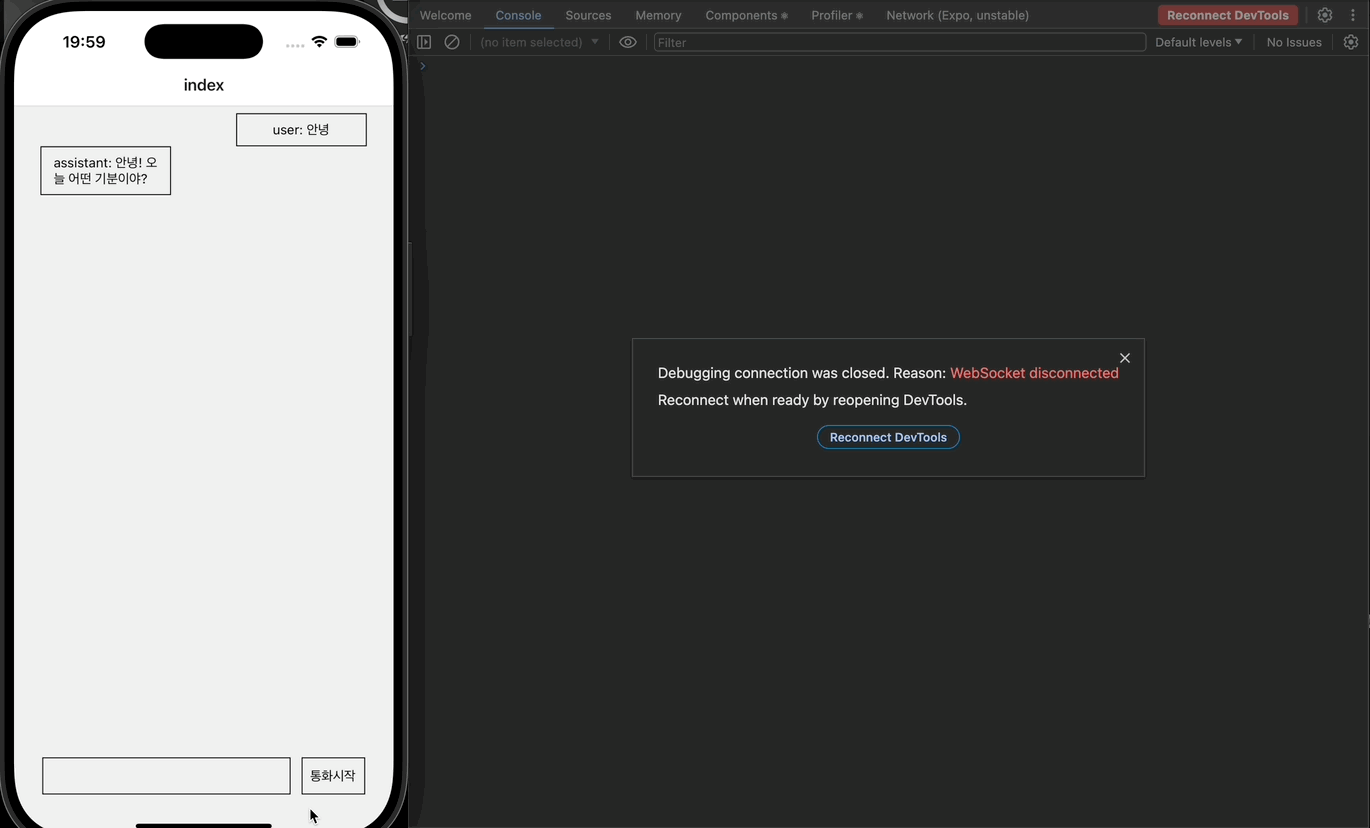
버튼의 텍스트가 잘 변경되고, 전송 역시 잘 된다. 이제 실제로 STT 기능을 구현해보자.
2. expo-speech-recognition 설치
공식 문서에 잘 나와있으며, 라이브러리 설치 후 app.json의 plugins 부분에 추가해주면 된다.
pnpm add expo-speech-recognition{
"expo": {
...
"plugins": [
...
[
"expo-speech-recognition",
{
"microphonePermission": "Allow $(PRODUCT_NAME) to use the microphone.",
"speechRecognitionPermission": "Allow $(PRODUCT_NAME) to use speech recognition.",
"androidSpeechServicePackages": ["com.google.android.googlequicksearchbox"]
}
]
],
...
}
}네이티브 모듈이 추가되었으므로 재빌드를 해주자.
pnpm run ios3. 통화시작/종료에 STT시작/종료 연결
먼저 사용자로부터 마이크/음성 인식 권한을 받아야 한다. ExpoSpeechRecognitionModule.requestPermissionsAsync 함수를 사용하면 된다.
권한에 따라 btnText가 달라져야 하므로 조건문을 수정했고, 컴포넌트 최초 마운트 시에만 권한을 체크하도록 useEffect를 사용했다.
그리고 STT 관련 로직을 모듈화 시키기 위해 useStt라는 커스텀 훅을 만들 것이다. 매개변수로는 isSttMode, assistantId, threadId, setChats를 받는다.
- isSttMode: 음성 인식 모듈을 시작/종료하기 위해
- assistantId, threadId: 어시스턴트 API를 호출하기 위해
- setChats: 음성 인식 결과를 채팅에 반영하기 위해
useStt 훅에 isSttMode에 의존하는 useEffect를 두고, 여기서 STT 시작/종료를 관리한다. isSttMode가 true라면 ExpoSpeechRecognitionModule.start 함수를 실행하고, false라면 ExpoSpeechRecognitionModule.stop 함수를 실행하도록 한다.
isGranted가 false라면 사용자는 isSttMode를 true로 변경시킬 수 없으므로, STT 시작/종료 시 isGranted를 고려하지 않아도 된다.
// app/index.tsx
import {
ExpoSpeechRecognitionModule,
} from "expo-speech-recognition";
import { useStt } from "@/useStt";
...
export default function Index() {
...
const [isSttMode, setIsSttMode] = useState<boolean>(false);
const [isGranted, setIsGranted] = useState<boolean>(true);
// 조건에 isGranted 추가
const btnText = (() => {
if (!isGranted || input.length !== 0) {
return "전송";
} else if (isSttMode) {
return "통화종료";
} else {
return "통화시작";
}
})();
...
// 컴포넌트 마운트 시 마이크 권한 체크
useEffect(() => {
ExpoSpeechRecognitionModule.requestPermissionsAsync().then((res) => {
console.log("마이크 권한 체크 결과: ", res.granted);
setIsGranted(res.granted);
});
}, []);
useStt(isSttMode, assistantId, threadId, setChats); // 커스텀 훅 호출
return (
...
);
}// useStt.ts
import { ExpoSpeechRecognitionModule } from "expo-speech-recognition";
import { Chat } from "./app";
import { Dispatch, SetStateAction, useEffect } from "react";
export const useStt = (
isSttMode: boolean,
assistantId: string | null,
threadId: string | null,
setChats: Dispatch<SetStateAction<Chat[]>>
) => {
// isSttMode 값에 따라 음성 인식을 start/stop 시키는 effect
useEffect(() => {
if (isSttMode) {
console.log("음성 인식 시작");
ExpoSpeechRecognitionModule.start({
lang: "ko-KR",
continuous: true,
interimResults: true,
});
} else {
console.log("음성 인식 종료");
ExpoSpeechRecognitionModule.stop();
}
}, [isSttMode]);
};
ExpoSpeechRecognitionModule.start의 매개변수 각 필드의 의미는 공식 문서에 잘 나와있다.
- lang: 음성 인식 감지용 언어 (ko-KR을 사용하면, 한국어로 인식하지만 영어도 어느정도 감지한다)
- continuous: 음성 인식을 수동으로 stop할 때까지 지속할지 결정
- interimResults: 최종 인식 결과 말고도, 중간중간 인식한 결과들을 반환할지 결정
음성 인식 종료 시점을 커스터마이징 하기 위해 continuous를 true로 줬고, 사용자의 음성이 실시간으로 반영되는 경험을 제공하기 위해 interimResults를 true로 줬다.
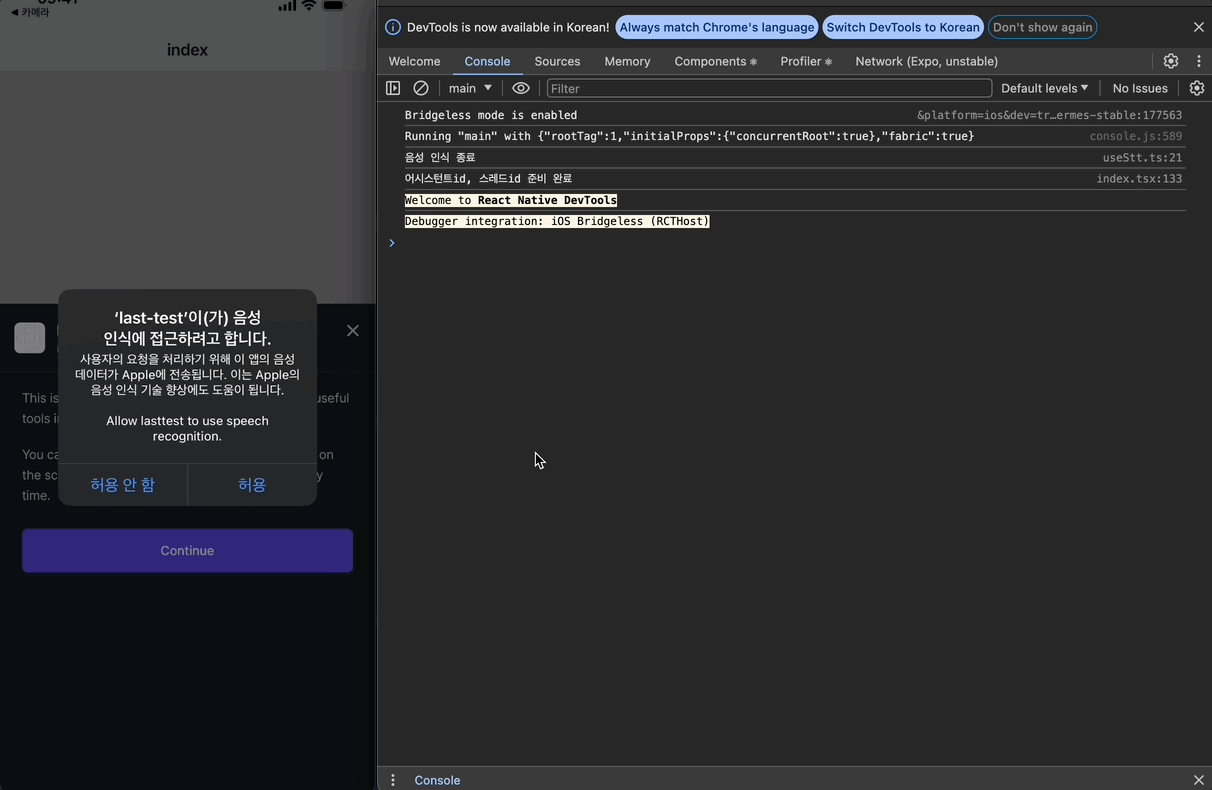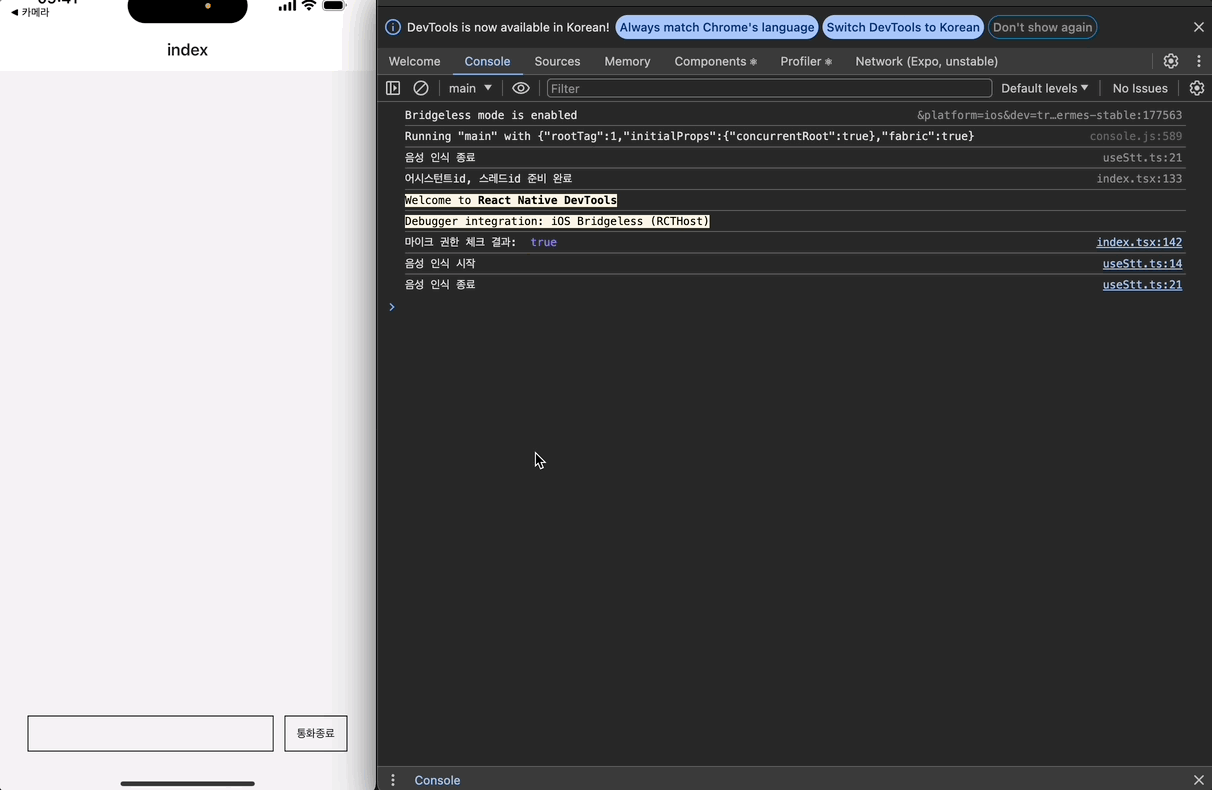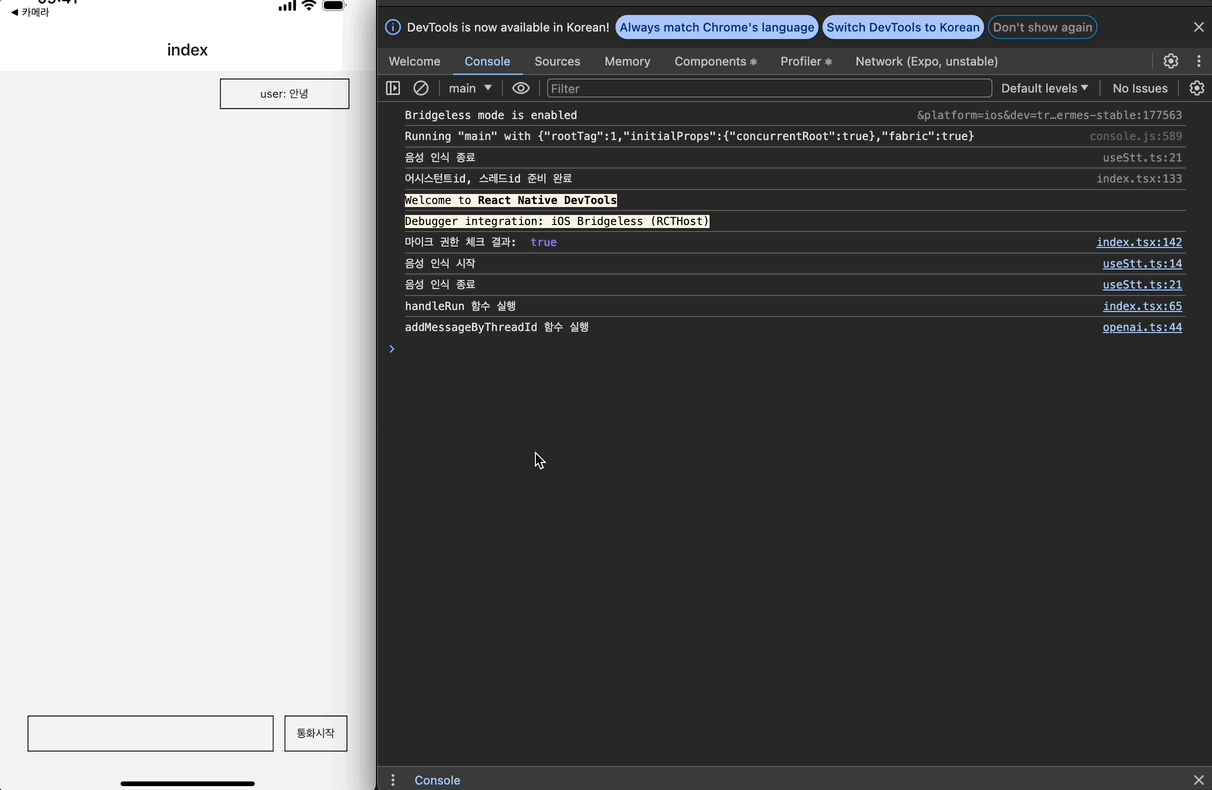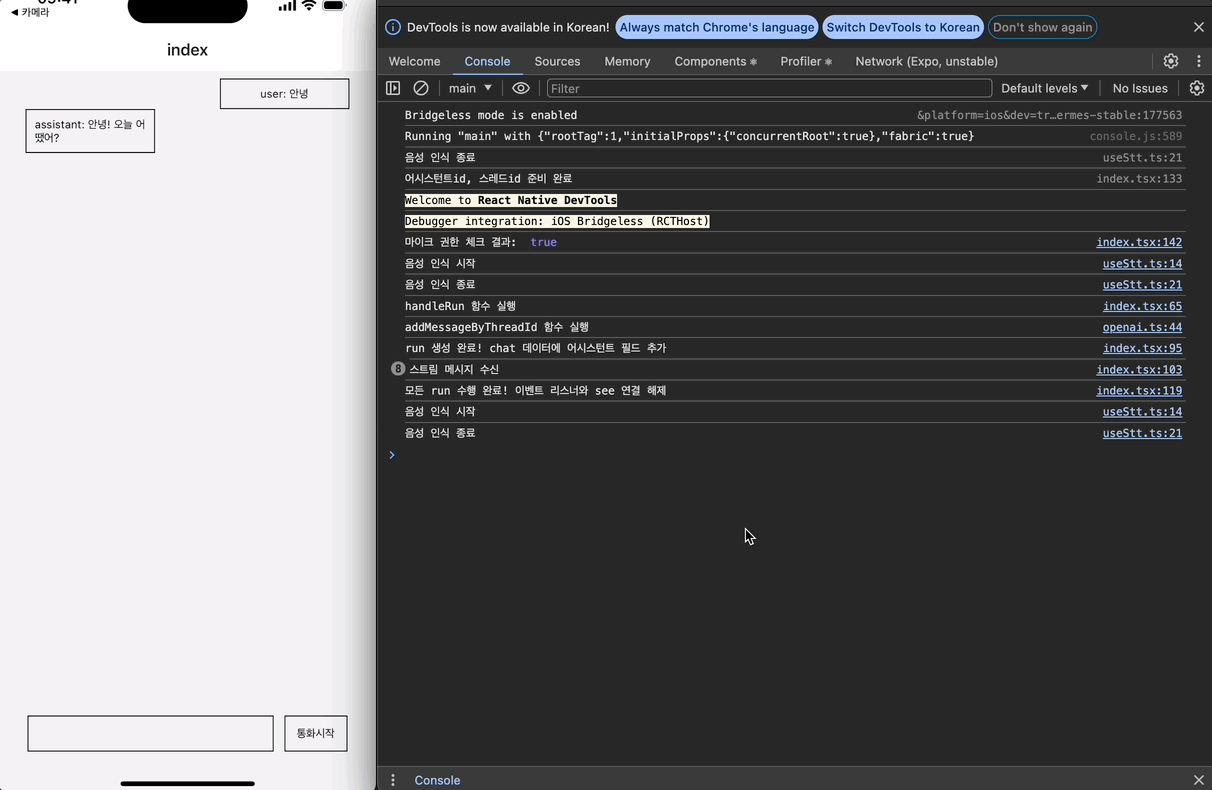
권한을 잘 받아오고, 음성 인식 시작/종료도 잘 되는 것을 알 수 있다. 또한 기존에 구현했던 전송 기능도 잘 작동한다.
이건 주제 밖 이야기지만, 키보드 영역에 레이아웃을 반응시키고 싶다면
KeyboardAvoidingView를 사용하면 된다. 공식 문서
4. STT 이벤트 핸들러 콜백 함수 구현
사용할 이벤트는 start, result 2가지다. expo-speech-recognition이 제공하는 useSpeechRecognitionEvent 훅을 사용해 구현할 예정이다.
사용자가 말을 하다가 멈추면, 2초 후 isLoading을 true로 변경한다. isLoading은 STT 시작/종료를 제어하고, 어시스턴트에게 요청을 보내는 트리거가 된다.
이를 위해 setTimeout을 활용할 것이다. 사용자가 말을 할 때마다 호출되는 result 이벤트에서 기존 setTimeout을 제거한 뒤 새로운 setTimeout을 등록하는 식으로 설계했다.
사용자가 말을 쭉 하다가 2초동안 말을 계속 안 하면 isLoading을 true로 바꿔 STT를 멈추고 어시스턴트에게 요청을 보내는 흐름이다.
// useStt.ts
...
export const useStt = (
isSttMode: boolean,
assistantId: string | null,
threadId: string | null,
setChats: Dispatch<SetStateAction<Chat[]>>
) => {
const [isLoading, setIsLoading] = useState<boolean>(false); // STT/어시스턴트 호출 트리거
const timeoutRef = useRef<NodeJS.Timeout | null>(null); // timeout id 저장
const recognizedRef = useRef<string>(""); // 음성 인식 결과 저장
// STT 모드가 켜져있을 때
// isLoading이 true면 음성 인식 종료하고, false면 음성 인식을 시작하도록 조건 수정
useEffect(() => {
if (isSttMode && !isLoading) {
console.log("음성 인식 시작");
ExpoSpeechRecognitionModule.start({
lang: "ko-KR",
continuous: true,
interimResults: true,
});
} else {
console.log("음성 인식 종료");
ExpoSpeechRecognitionModule.stop();
}
}, [isSttMode, isLoading]);
// 음성 인식이 켜지면 ref 초기화하고 chats state에 user필드 추가
useSpeechRecognitionEvent("start", () => {
recognizedRef.current = "";
setChats((prev) => [...prev, { role: "user", text: "" }]);
});
// 음성 인식이 발생하면, ref랑 state 업데이트 하고 timeout 초기화
useSpeechRecognitionEvent("result", (event) => {
console.log("음성인식", event);
if (event.results[0]?.transcript) {
recognizedRef.current = event.results[0]?.transcript; // 음성인식 결과 ref에 저장
if (timeoutRef.current) clearTimeout(timeoutRef.current); // 기존 timeout 제거
// 새 timeout 생성
timeoutRef.current = setTimeout(() => {
console.log("2초간 말을 멈춰 콜백 실행", timeoutRef.current);
setIsLoading(true); // STT 끄고, 어시스턴트에게 전달하는 로직 실행하는 트리거
}, 2000);
// 채팅 state 업데이트
setChats((prev) => [
...prev.slice(0, -1),
{ role: "user", text: event.results[0]?.transcript },
]);
}
});
};state들이 유기적으로 sideEffect를 일으키는 형태다 보니 흐름을 한 번 정리해보자.
- 초기상황: isSttMode = false, isLoading = false ->
useEffect에 의해 음성 인식 시작 X - 사용자가 버튼을 눌러 isSttMode를 true로 변경 ->
useEffect에 의해 음성 인식 시작 O - 사용자가 말함 -> 음성 인식 결과를
recognizedRef와chats에 반영하고,timeout을 재등록 - 사용자가 2초간 말을 안 함 ->
setTimeout콜백이isLoading을 true로 변경 ->useEffect에 의해 음성 인식 종료
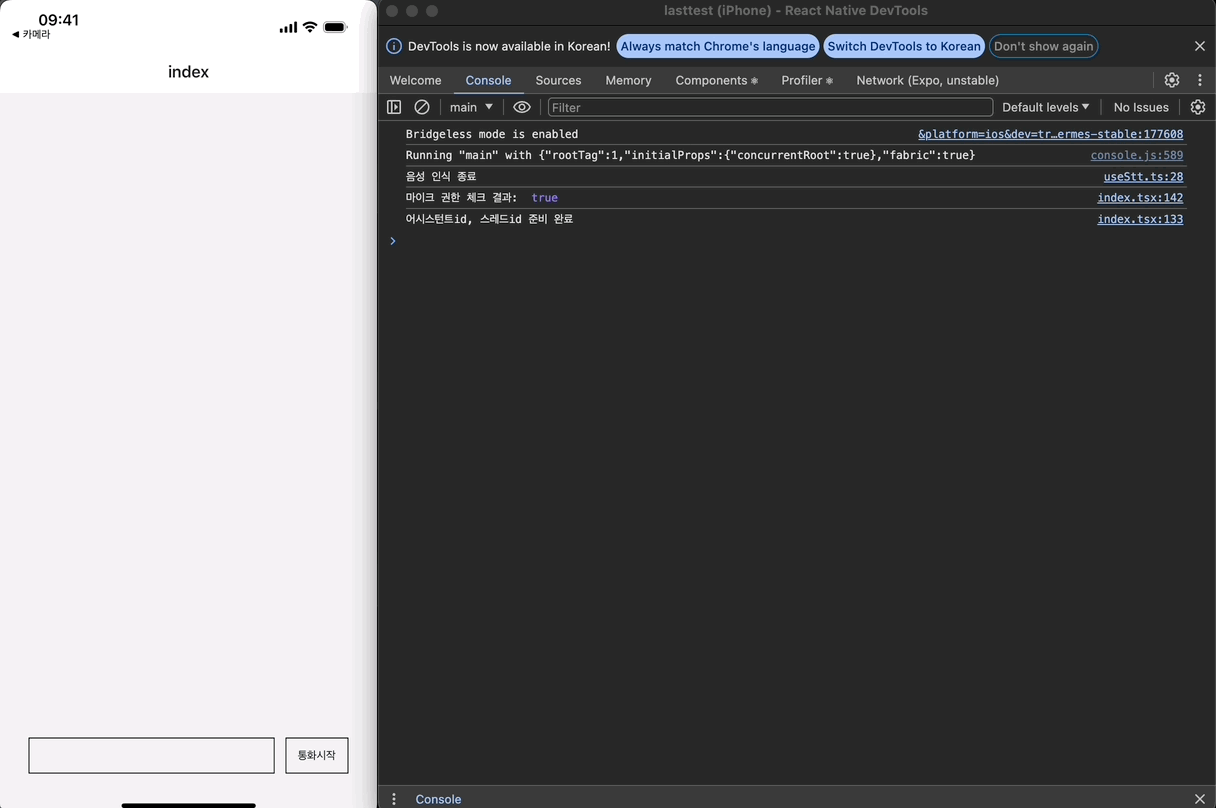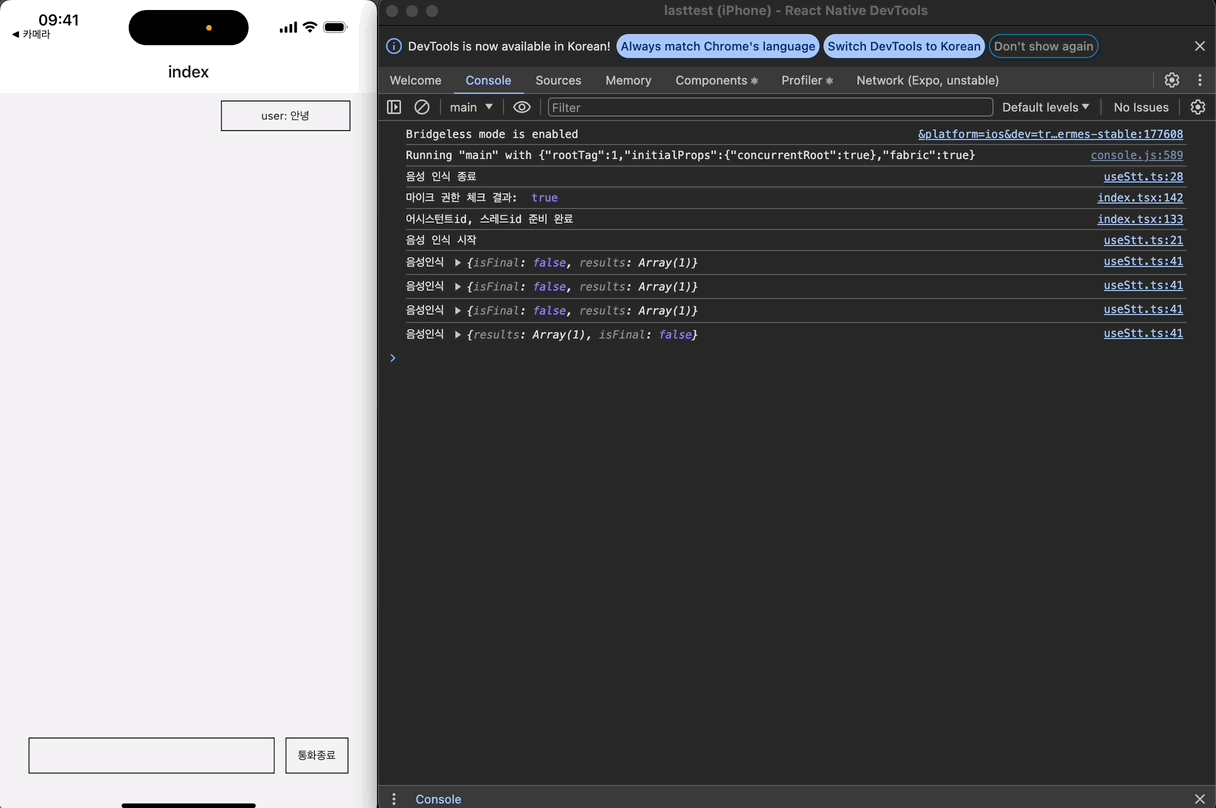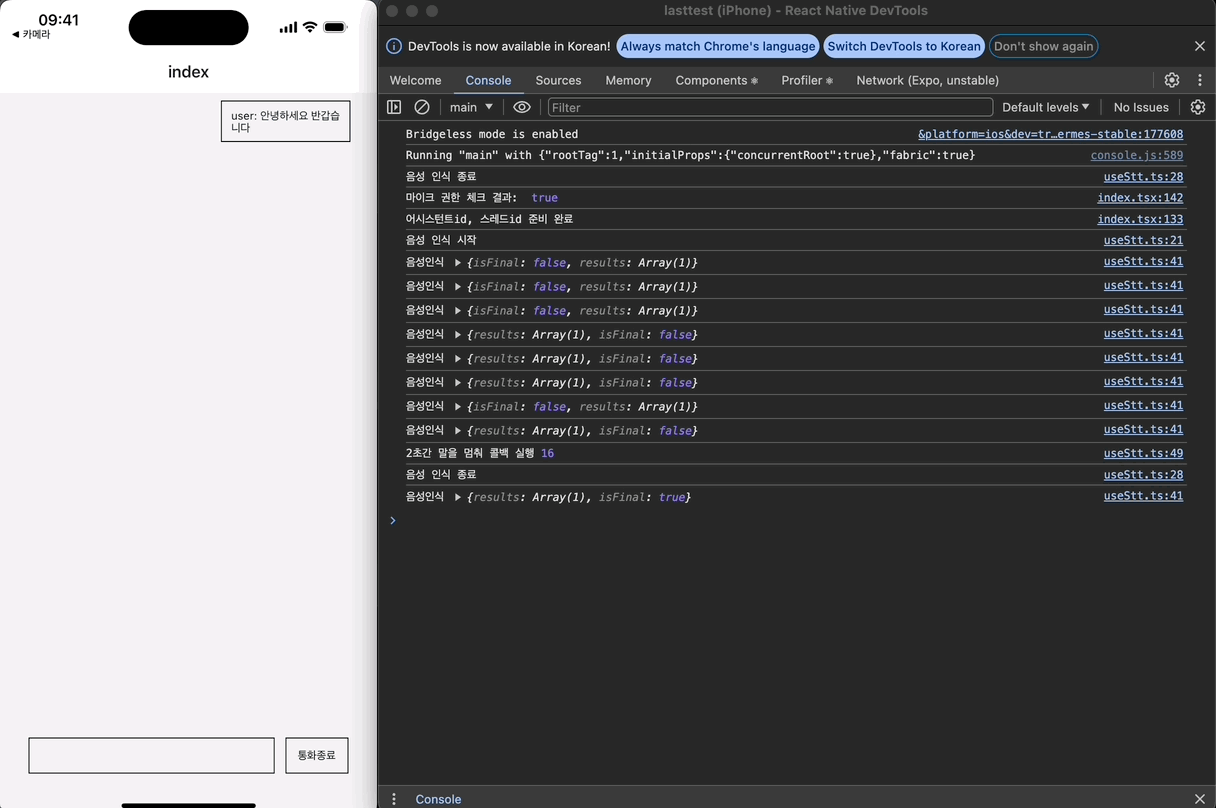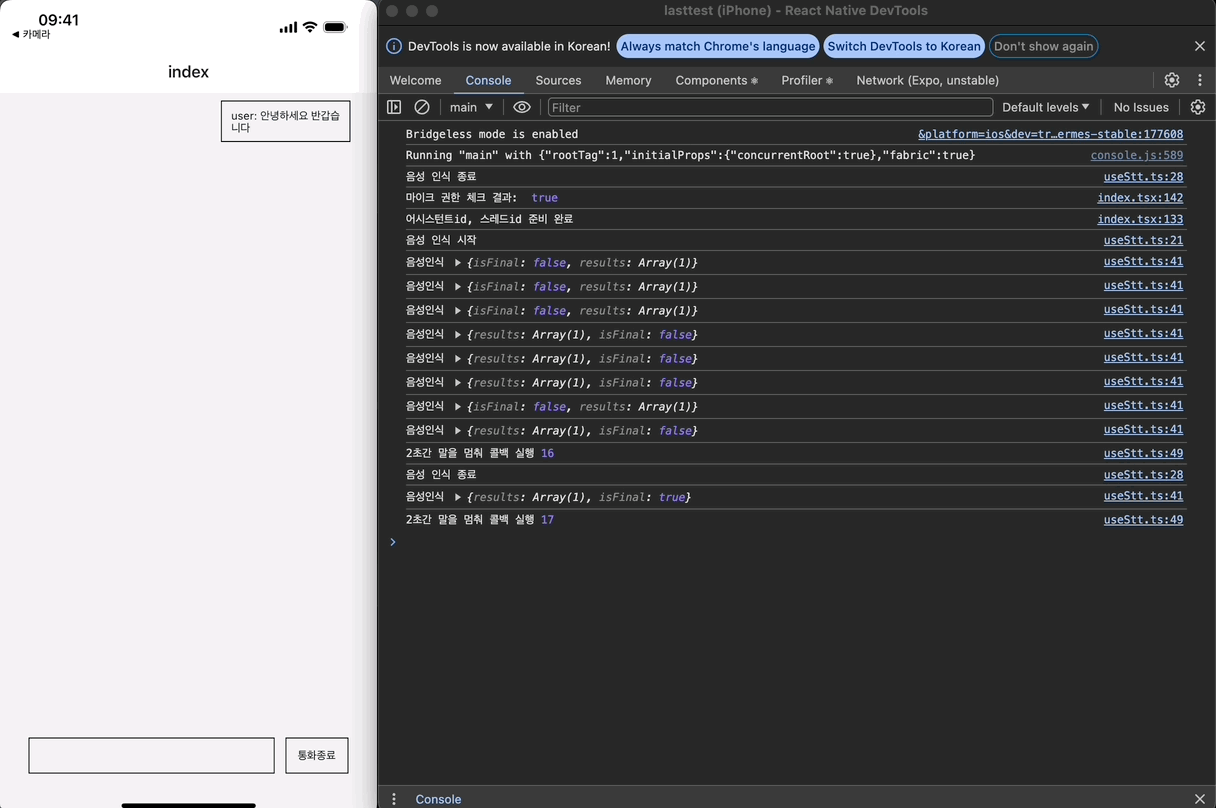
근데, 로그를 보면 이상한 점이 있다. timeout은 한 번만 등록되야 하는데, 두 번 등록되어 두 번 실행되는 문제가 발생하고 있다.
두 번 등록되는 이유를 찾느라 고생을 좀 했는데, 이벤트들을 콘솔 찍어본 결과 STT가 종료될 때 최종 음성 인식 결과를 result 이벤트로 한번 더 전송하기 때문이다.
최종 음성 인식 결과를 수신할 때는 setTimeout을 등록하지 않기 위해 isFinal 값을 활용해 조건문을 추가해보자.
// useStt.ts의 result 이벤트 리스너
useSpeechRecognitionEvent("result", (event) => {
console.log("음성인식", event);
if (event.results[0]?.transcript) {
recognizedRef.current = event.results[0]?.transcript;
if (timeoutRef.current) clearTimeout(timeoutRef.current);
// 최종 값(stop 후 터지는 이벤트)이 아닐 때만 새 setTimeout 추가하기
if (!event.isFinal) {
timeoutRef.current = setTimeout(() => {
console.log("2초간 말을 멈춰 콜백 실행", timeoutRef.current);
setIsLoading(true); // STT 끄고, 어시스턴트에게 전달하는 로직 실행하는 트리거
}, 2000);
}
setChats((prev) => [
...prev.slice(0, -1),
{ role: "user", text: event.results[0]?.transcript },
]);
}
});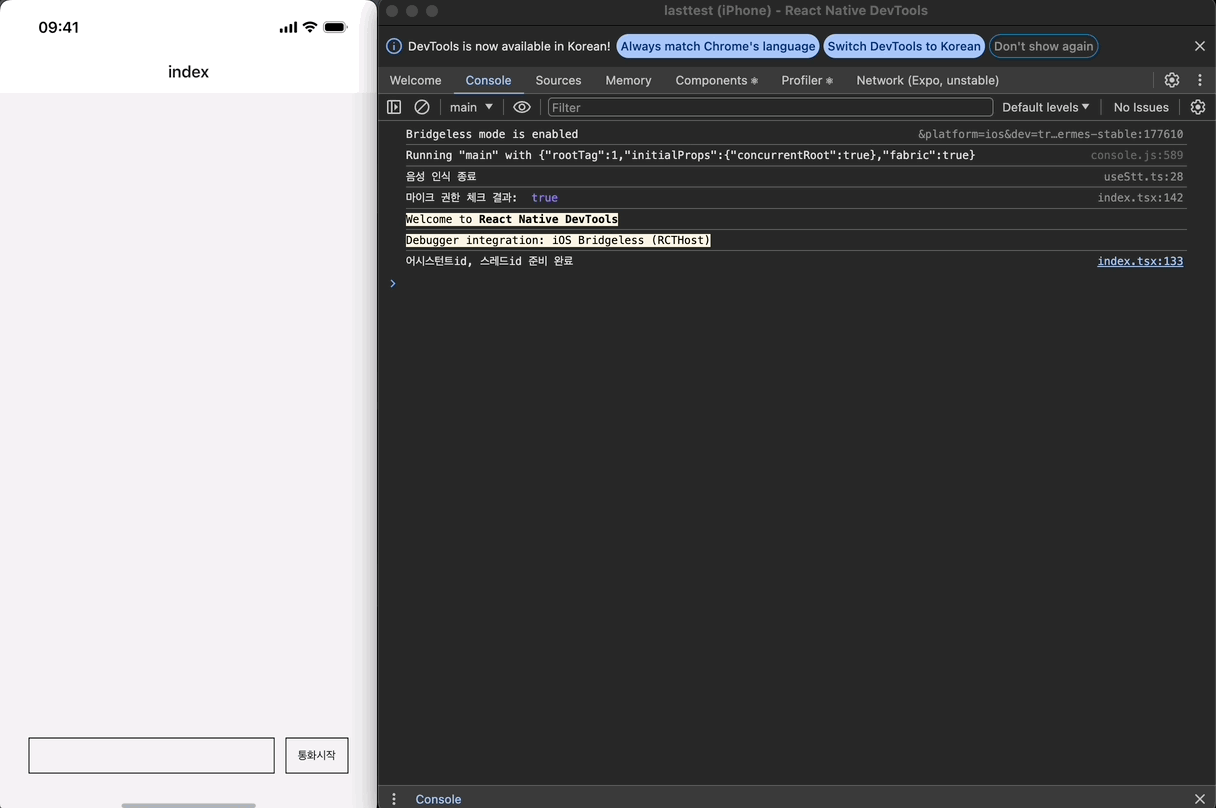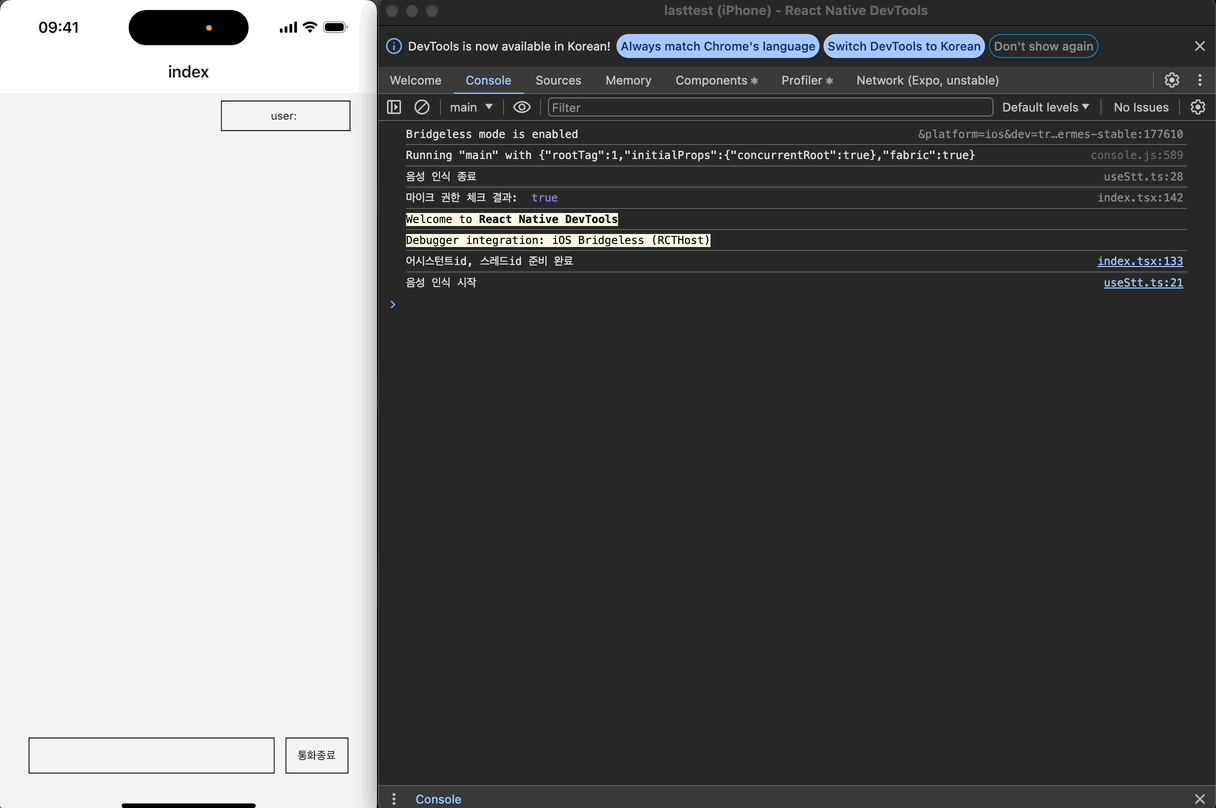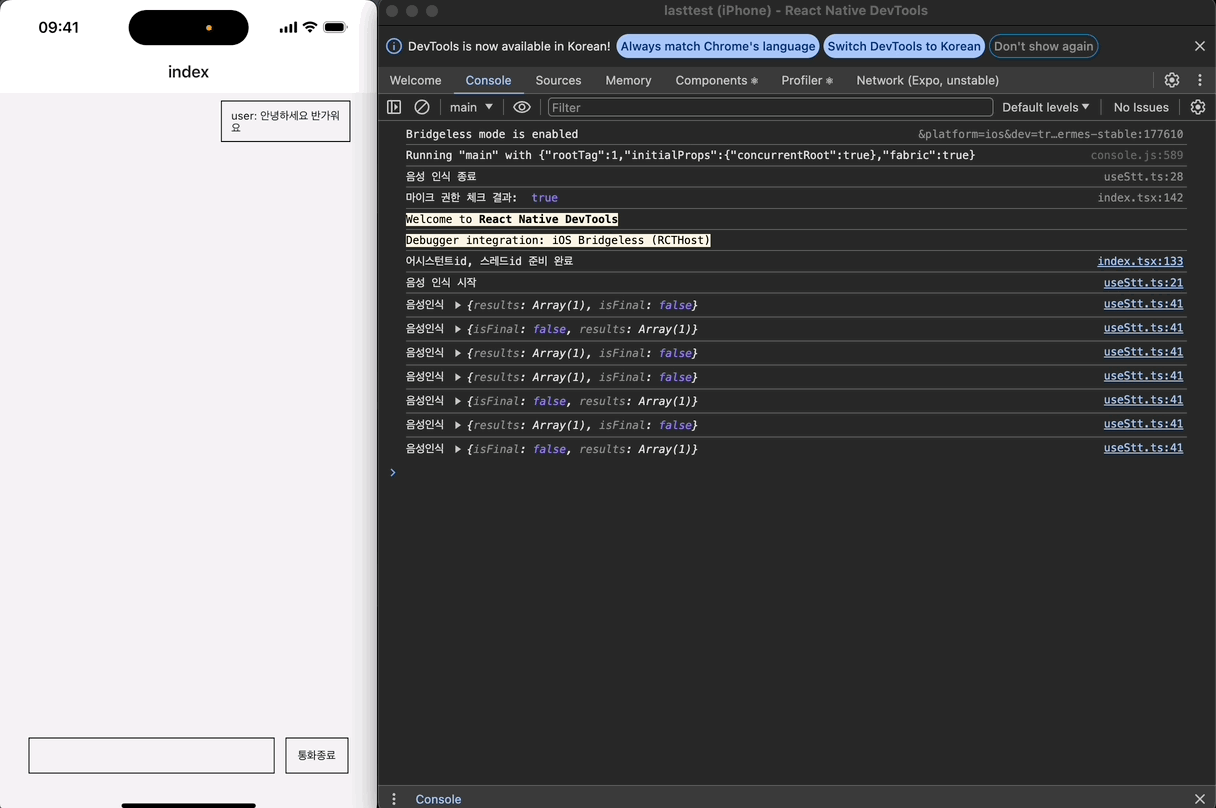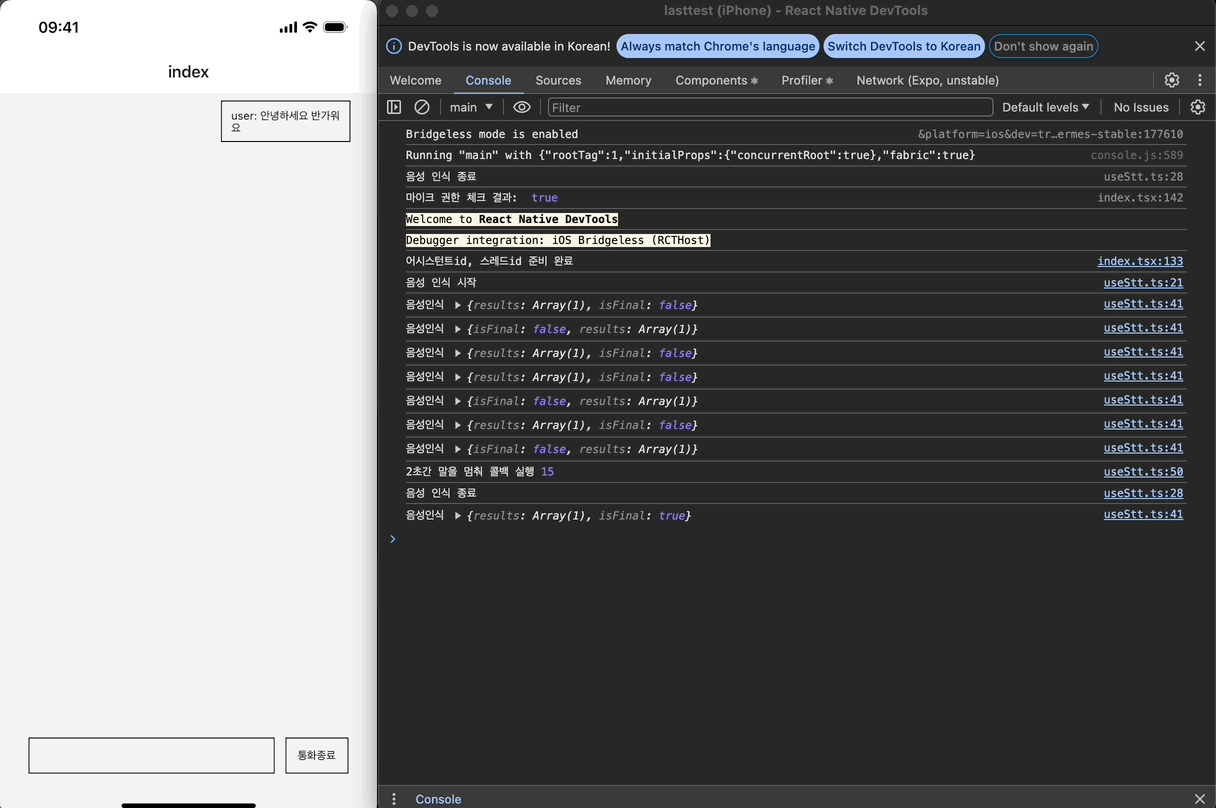
이제 setTimeout이 한 번만 등록되는 것을 확인할 수 있다.
5. 어시스턴트 API를 동작시키는 useEffect 구현
이제 isLoading이 true일 때만, recognizedRef 값을 스레드에 넣고 어시스턴트 API를 Run 시키는 useEffect를 구현하면 된다. runByPolling 함수는 OpenAI 공식 문서를 참고해 구현했다.
// useStt.ts
...
export const useStt = (
isSttMode: boolean,
assistantId: string | null,
threadId: string | null,
setChats: Dispatch<SetStateAction<Chat[]>>
) => {
...
// 어시스턴트 API 동작시키는 effect
useEffect(() => {
const runAssistant = async () => {
if (isSttMode && assistantId && threadId) {
if (isLoading && recognizedRef.current !== "") {
try {
await addMessageByThreadId(recognizedRef.current, threadId);
const newMsgs = await runByPolling(assistantId, threadId);
if (newMsgs) {
setChats(newMsgs);
// TTS 생성을 위해 어시스턴트의 텍스트를 뽑음
const assistantAnswer = newMsgs[newMsgs.length - 1].text;
}
} catch (e) {
console.error(e);
} finally {
setIsLoading(false); // 다시 음성 인식 시작!
}
}
}
};
runAssistant();
}, [assistantId, isLoading, isSttMode, setChats, threadId]);
};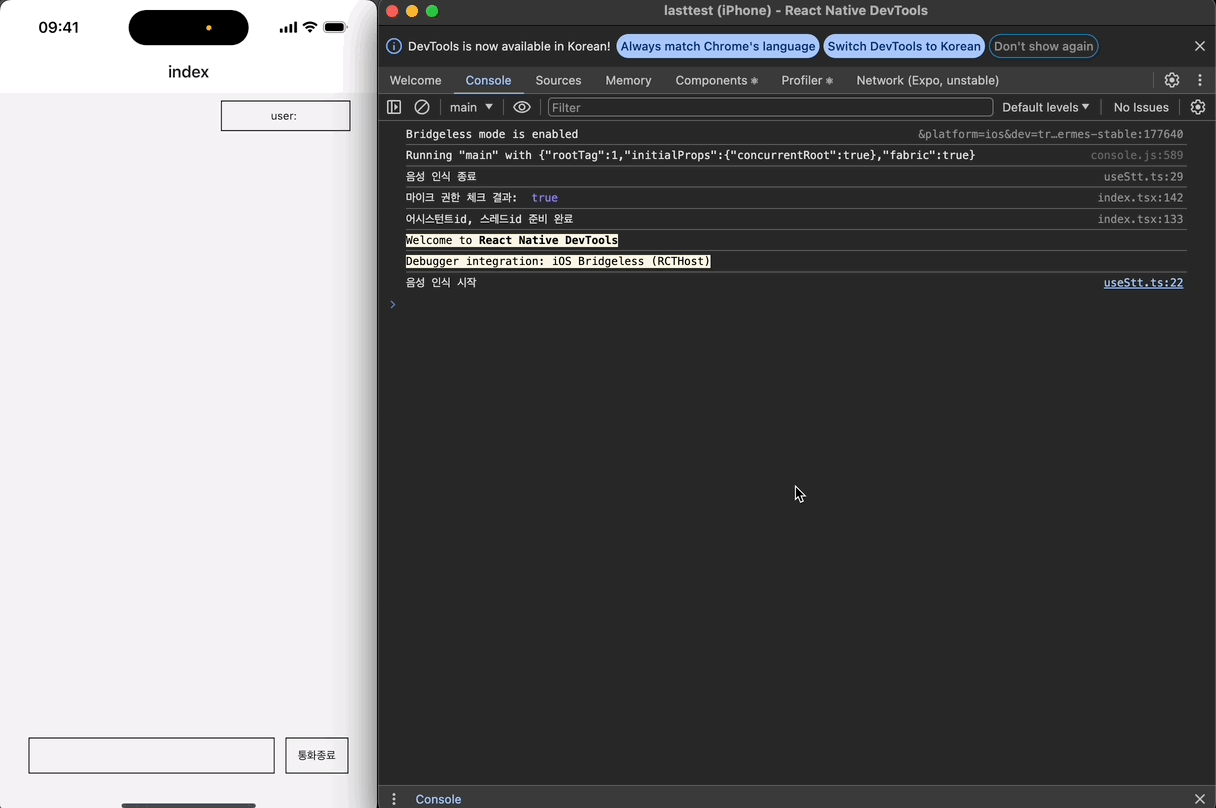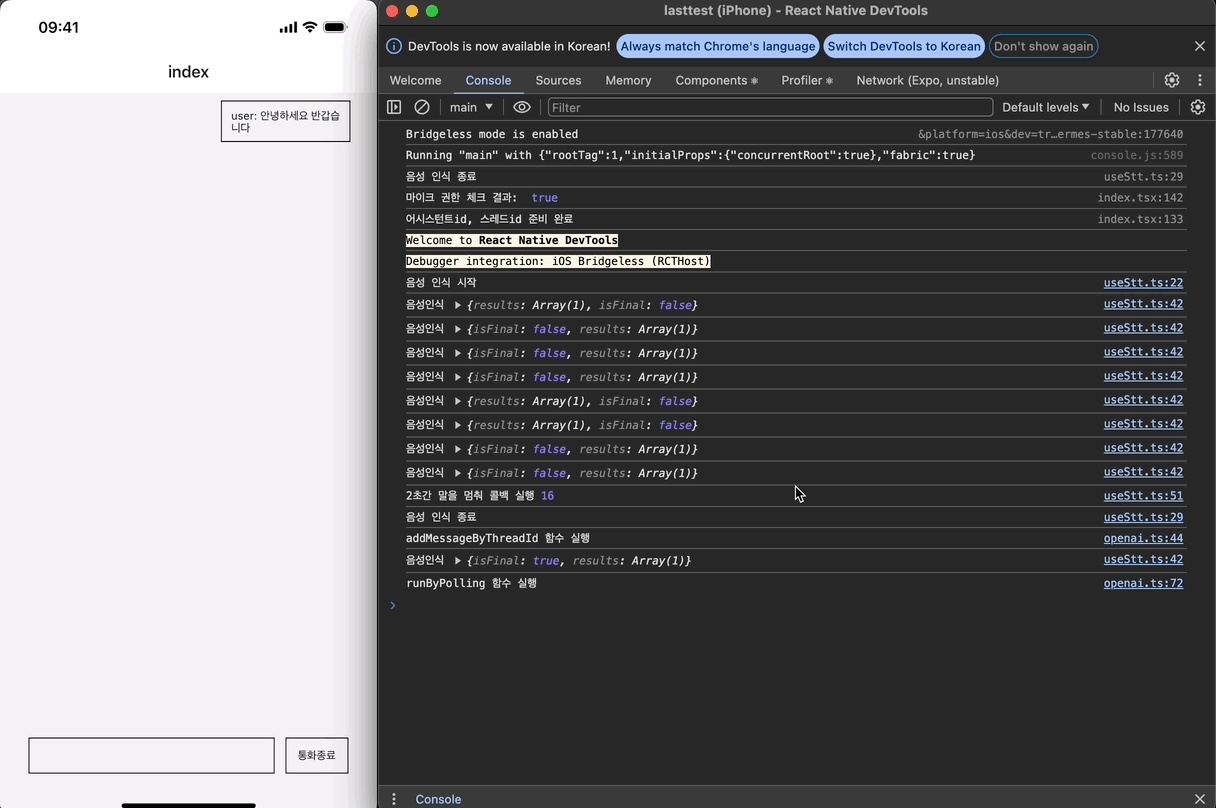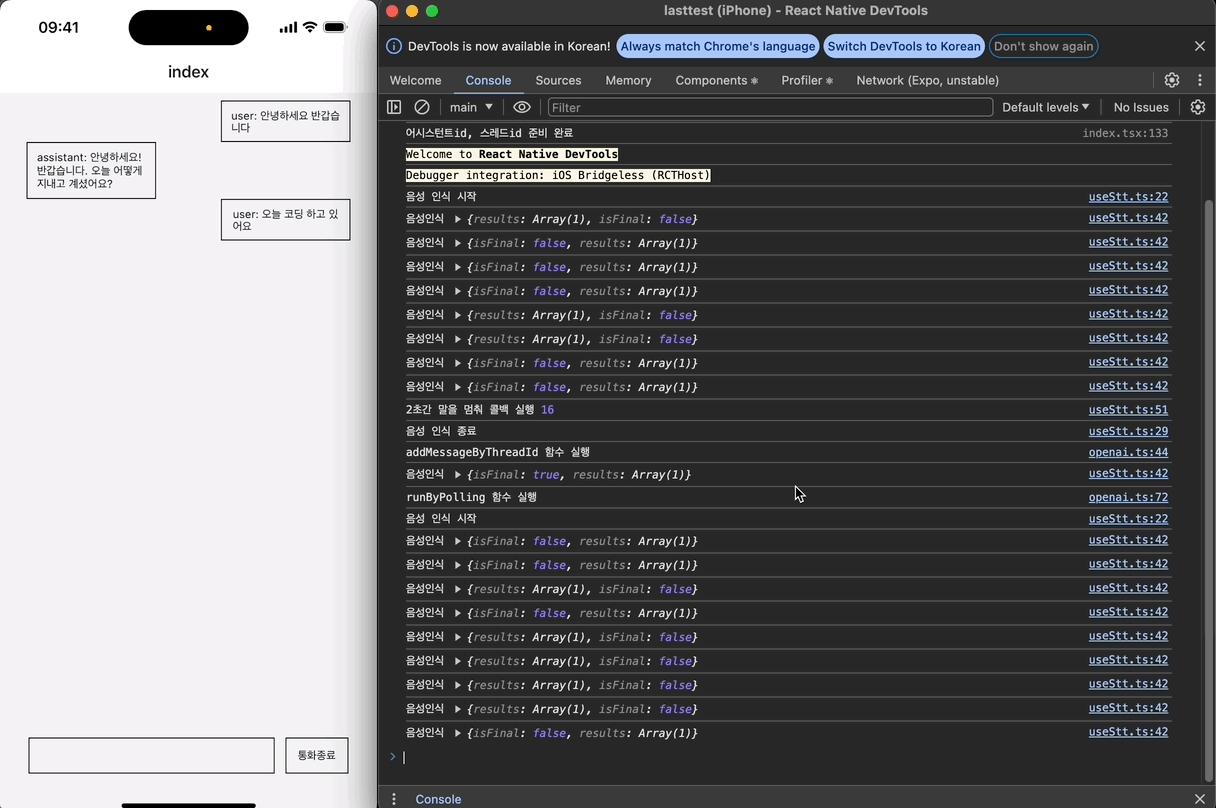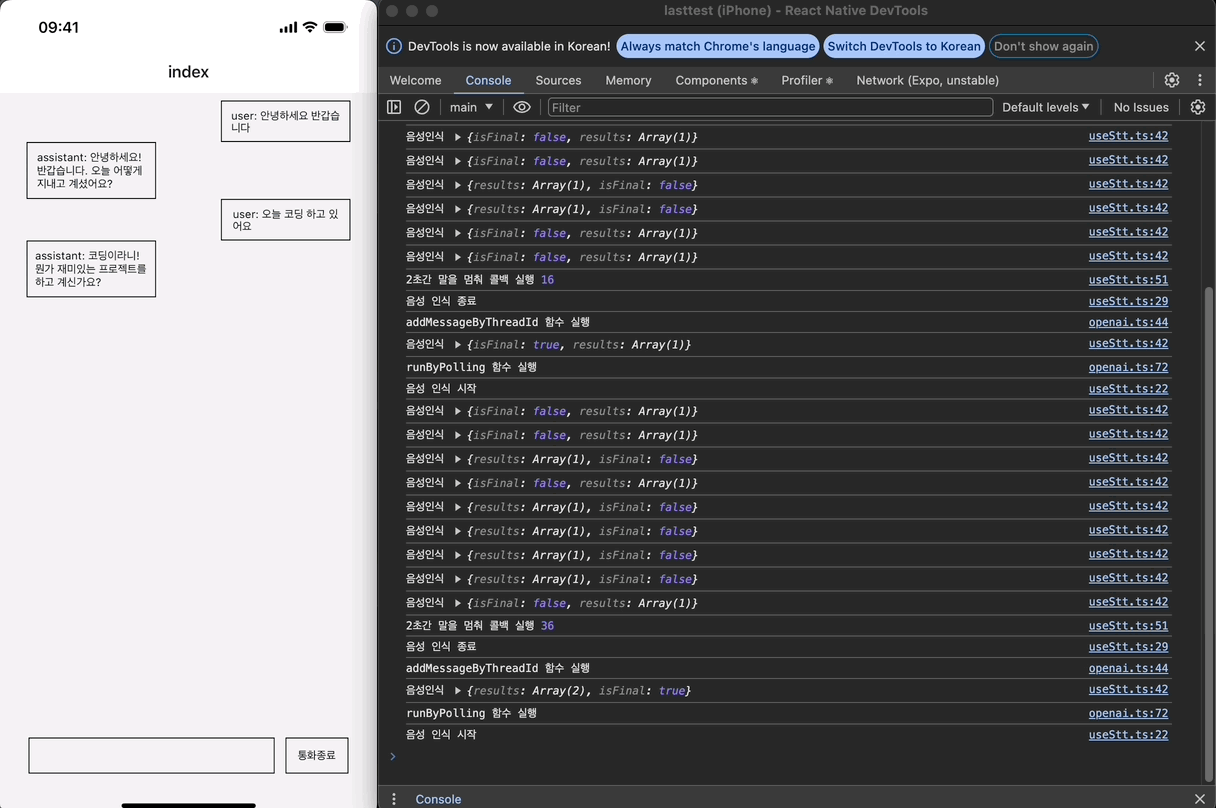
어시스턴트와 대화를 주고받는 형태로 STT가 정상적으로 작동하는 것을 확인할 수 있다!
6. Android에서 setTimeout이 작동하지 않는 문제
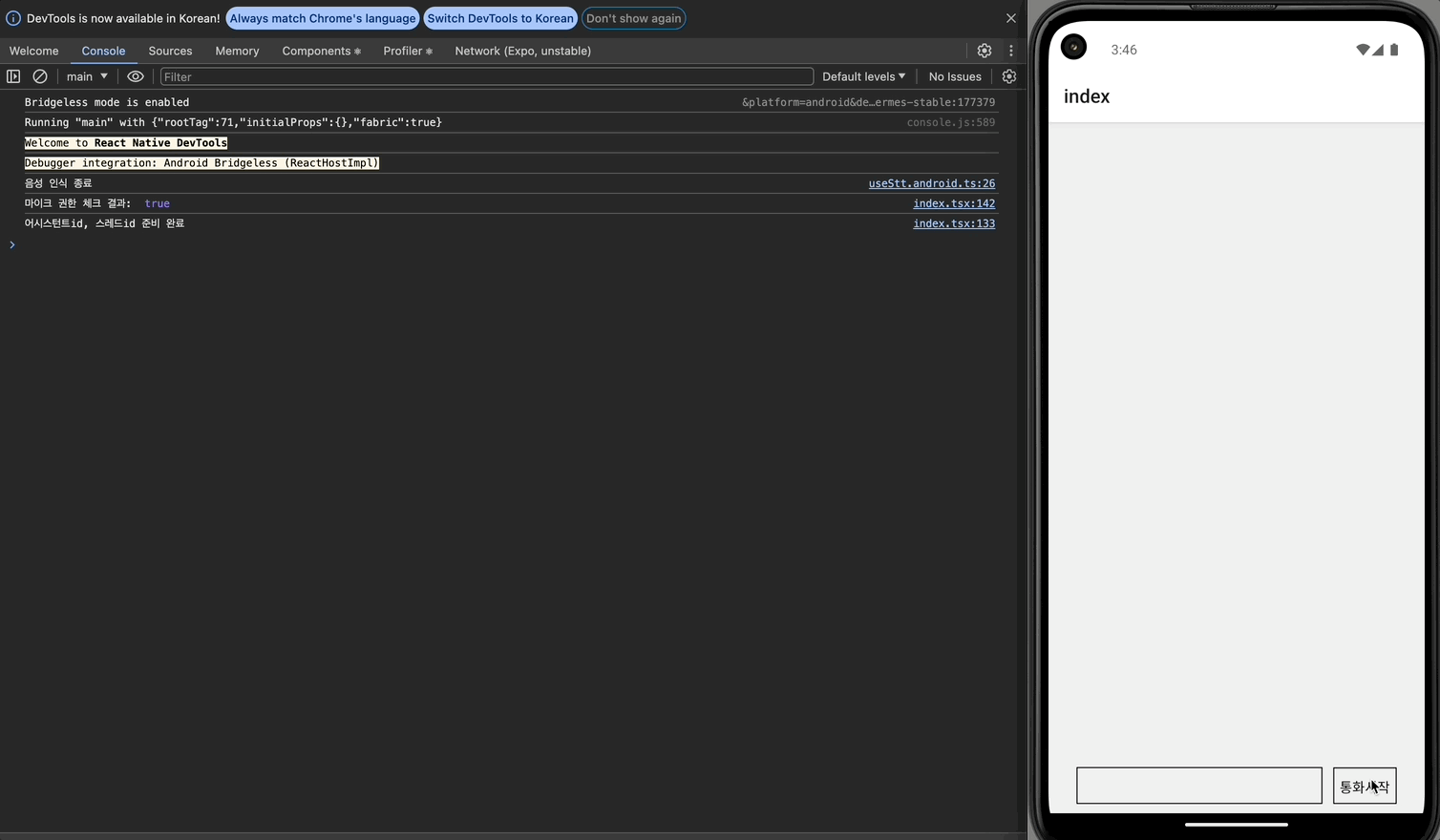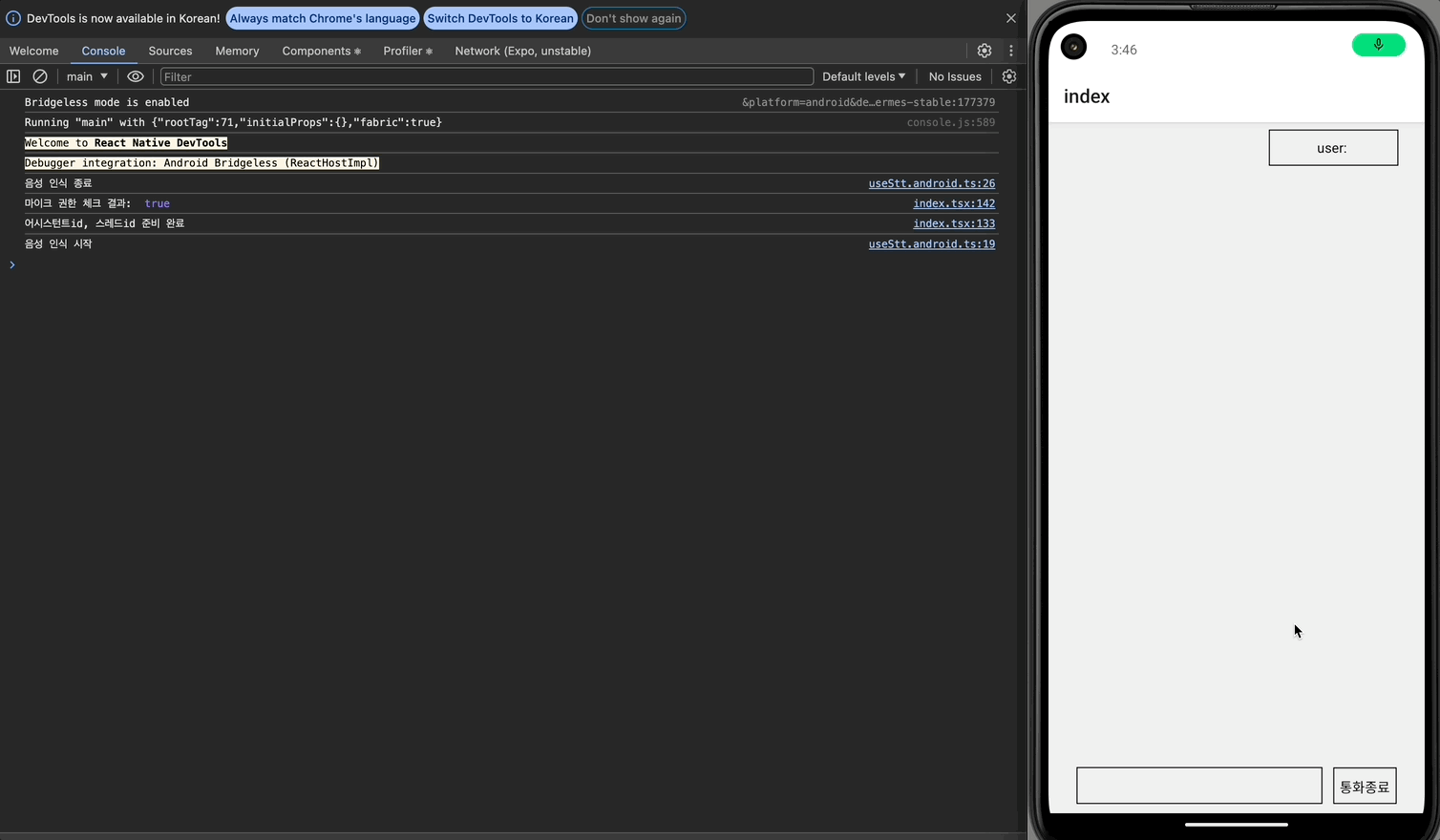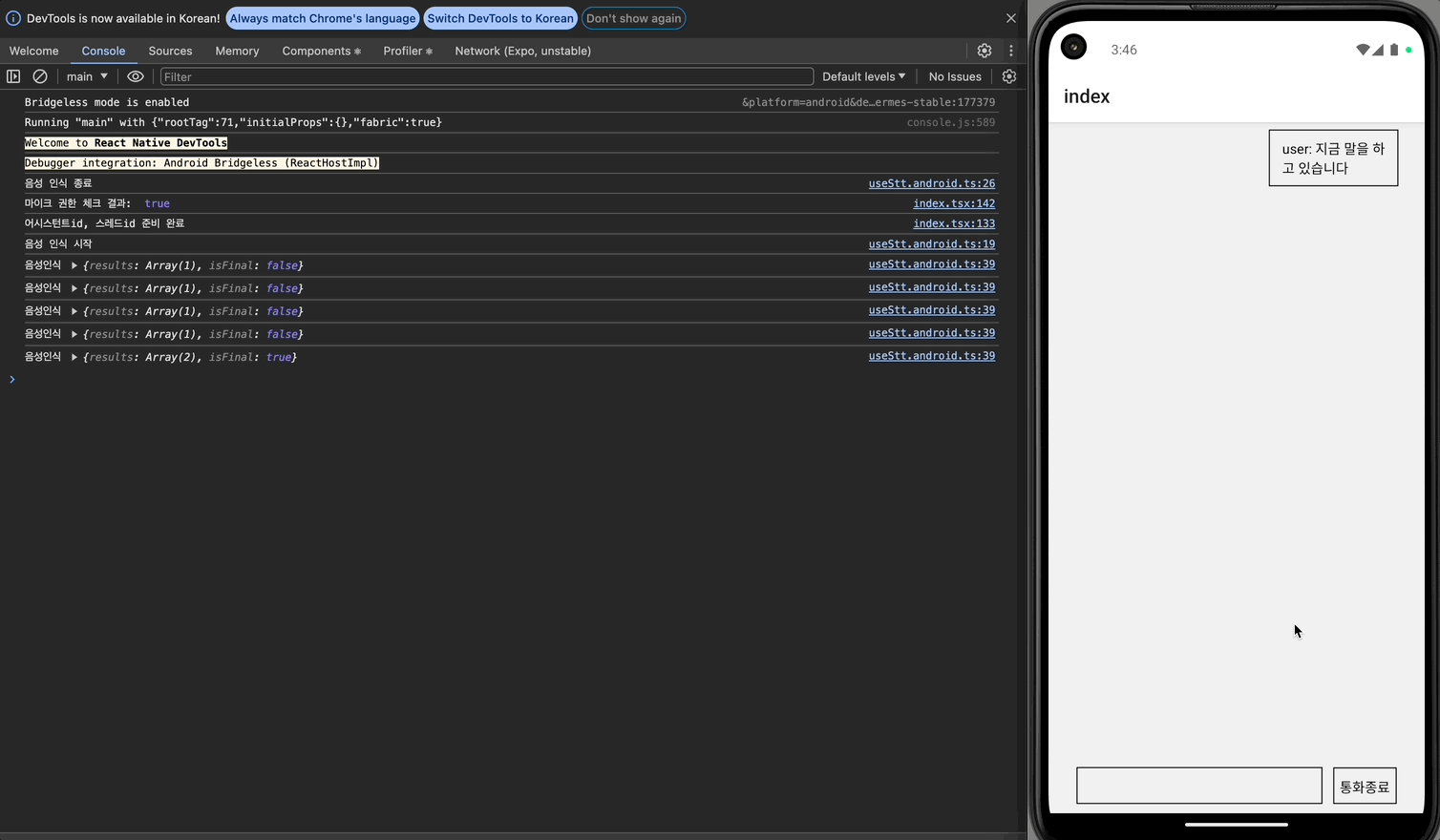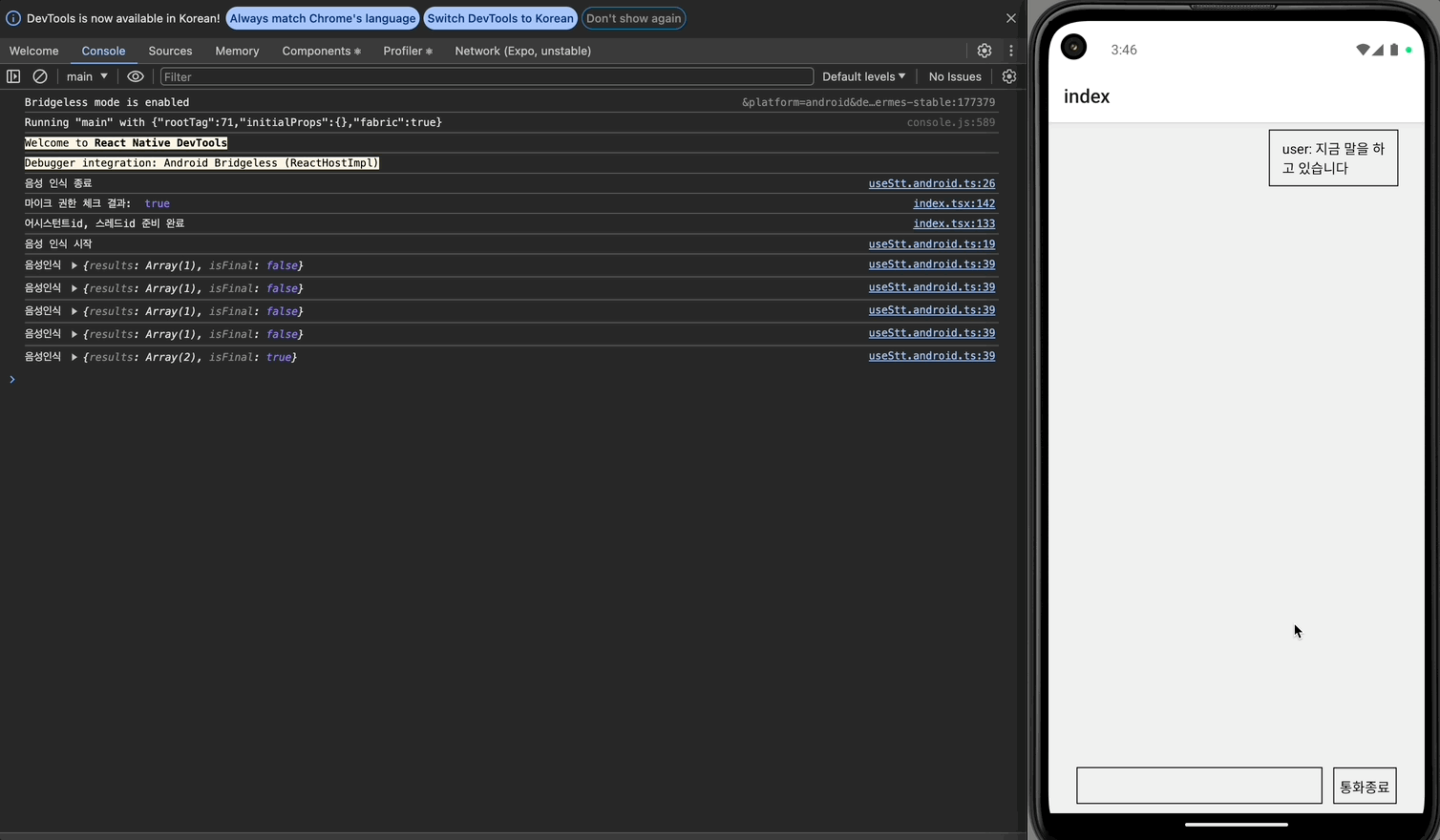
안드로이드에서는 음성인식이 멈춘지 2초가 지나도 setTimeout 콜백이 실행되지 않았다. 이는 OS별 음성 인식 동작 방식이 달라 발생하는 문제로 보인다.
이를 해결하기 위해 expo-speech-recognition이 제공하는 안드로이드용 이벤트인 speechend를 활용하는 안드로이드 전용 useStt 커스텀 훅을 만들기로 했다.

stackoverflow를 참고해 useStt.android.ts를 생성해줬다. 자동으로 안드로이드는 useStt.android.ts를 사용하고, IOS의 경우 useStt.ts를 사용한다.
speechend 이벤트가 발생하기까지 걸리는 침묵 시간은 넉넉히 잡기로 했다. 아래와 같이 androidIntentOptions에 EXTRA_SPEECH_INPUT_COMPLETE_SILENCE_LENGTH_MILLIS를 주면 speechend 이벤트 발생까지 걸리는 시간을 조절할 수 있다.

그리고 speechend 이벤트가 발생하면 2초 뒤 isLoading을 true로 변경하도록 설계했다. 구현해보자.
// useStt.android.ts
...
export const useStt = (
isSttMode: boolean,
assistantId: string | null,
threadId: string | null,
setChats: Dispatch<SetStateAction<Chat[]>>
) => {
...
useEffect(() => {
if (isSttMode && !isLoading) {
console.log("음성 인식 시작");
ExpoSpeechRecognitionModule.start({
lang: "ko-KR",
continuous: true,
interimResults: true,
androidIntentOptions: {
EXTRA_SPEECH_INPUT_MINIMUM_LENGTH_MILLIS: 5000, // speechend 발생을 5초 후로 설정
},
});
} else {
console.log("음성 인식 종료");
ExpoSpeechRecognitionModule.stop();
}
}, [isSttMode, isLoading]);
useSpeechRecognitionEvent("start", () => {
// start 이벤트는 IOS와 동일
});
useSpeechRecognitionEvent("result", (event) => {
console.log("음성인식", event);
if (event.results[0]?.transcript) {
recognizedRef.current = event.results[0]?.transcript;
// setTimeout 제거! speechend 이벤트 콜백에서 처리한다
setChats((prev) => [
...prev.slice(0, -1),
{ role: "user", text: event.results[0]?.transcript },
]);
}
});
// 안드로이드에서 음성인식이 감지되지 않으면 실행될 이벤트
useSpeechRecognitionEvent("speechend", () => {
setTimeout(() => {
console.log("2초간 말을 멈춰 콜백 실행");
setIsLoading(true);
}, 2000);
});
...
useEffect(() => {
const runAssistant = async () => {
// runAssistant 함수도 IOS와 동일
};
runAssistant();
}, [assistantId, isLoading, isSttMode, setChats, threadId]);
};result 이벤트 리스너 콜백에 존재하던 setTimeout을 speechend 이벤트 리스너 콜백으로 이동시켰다.
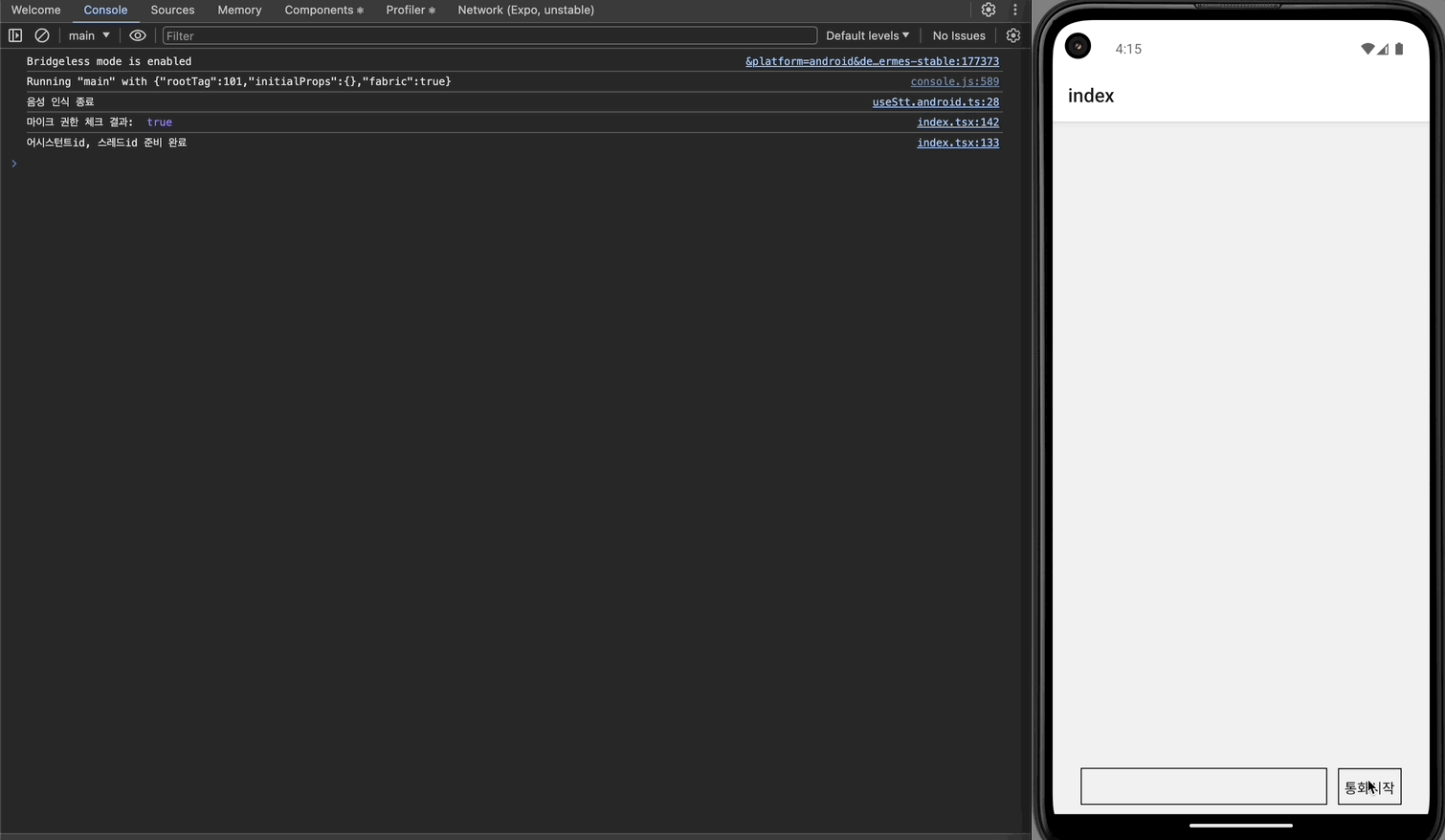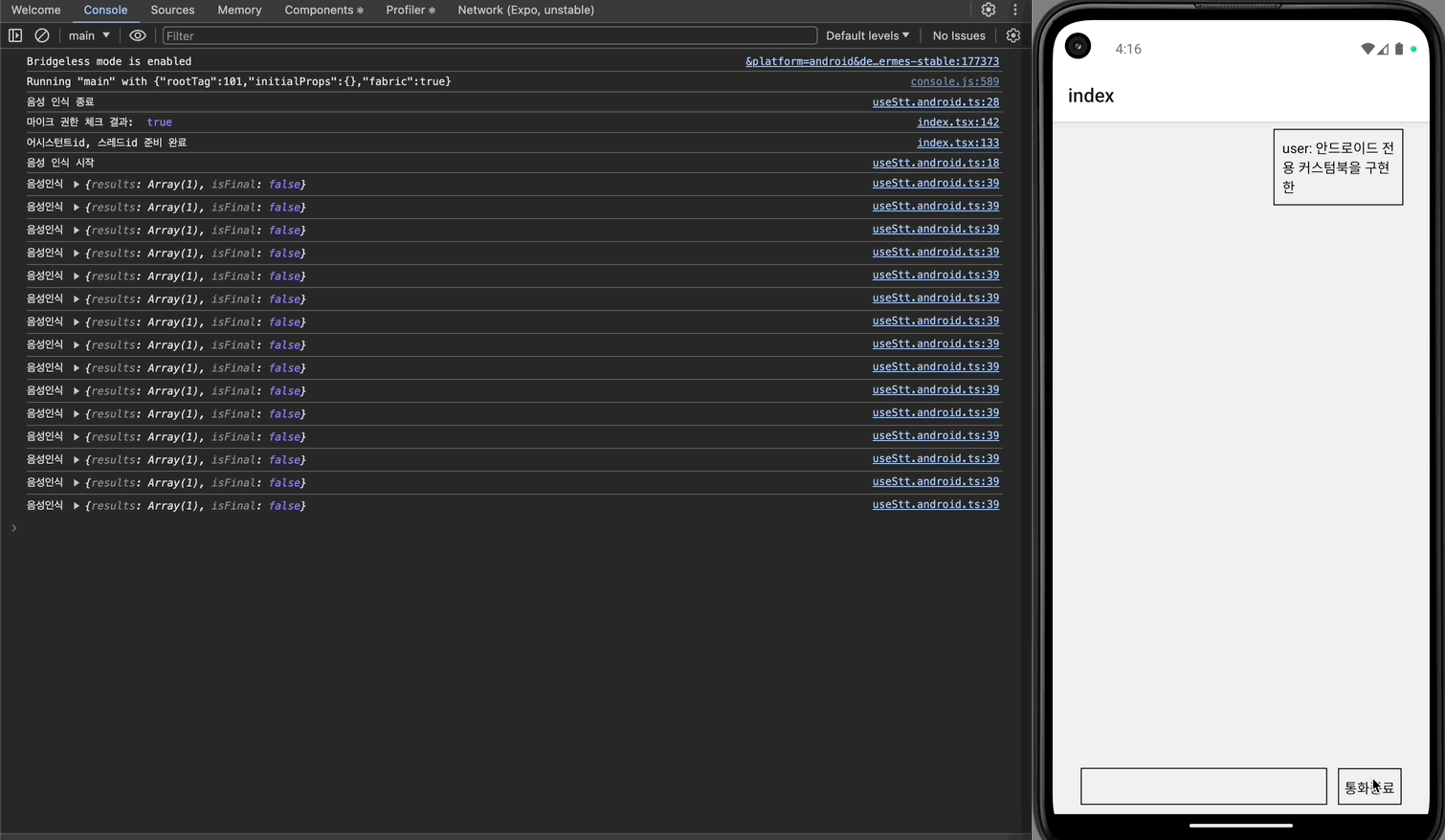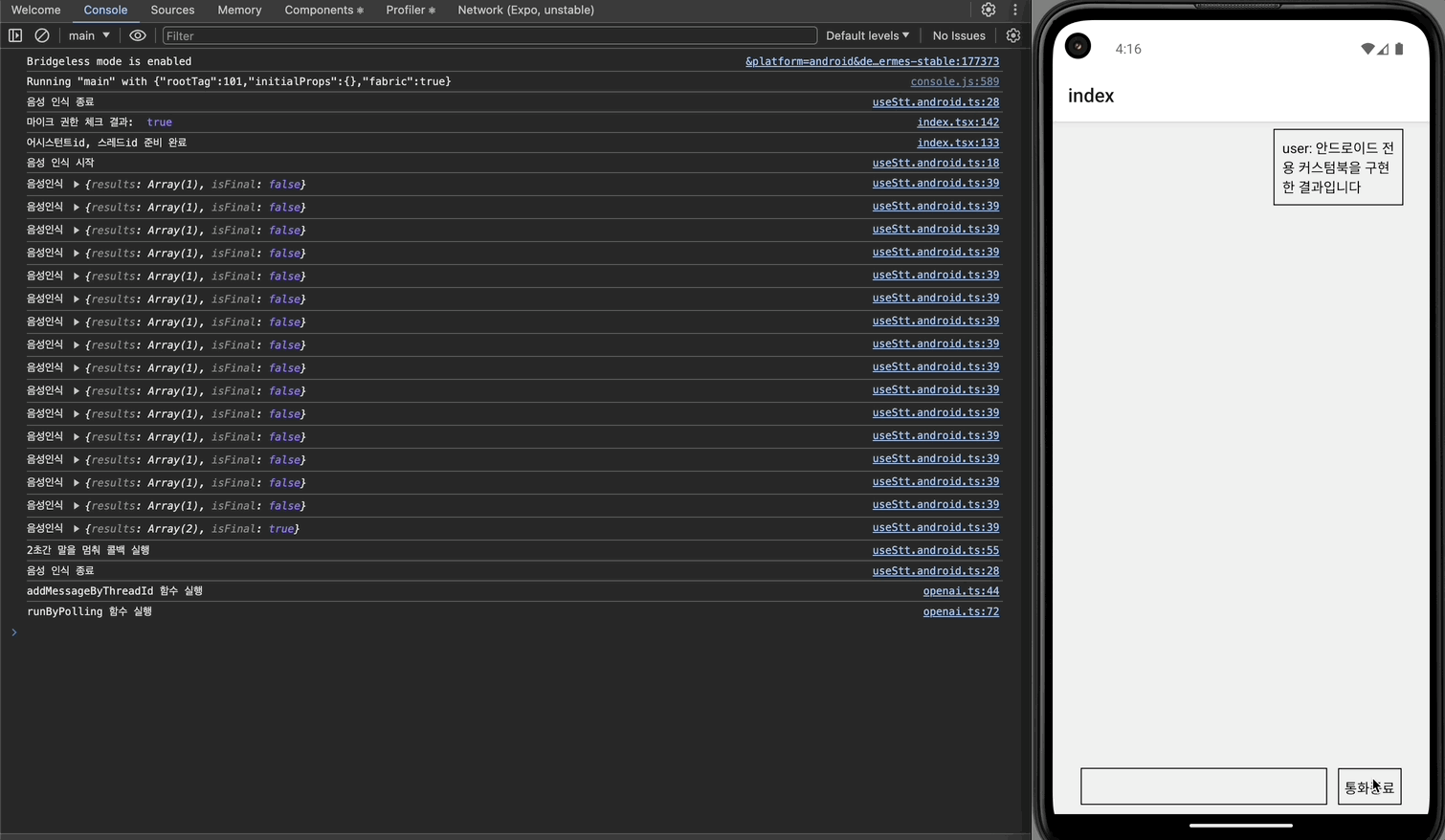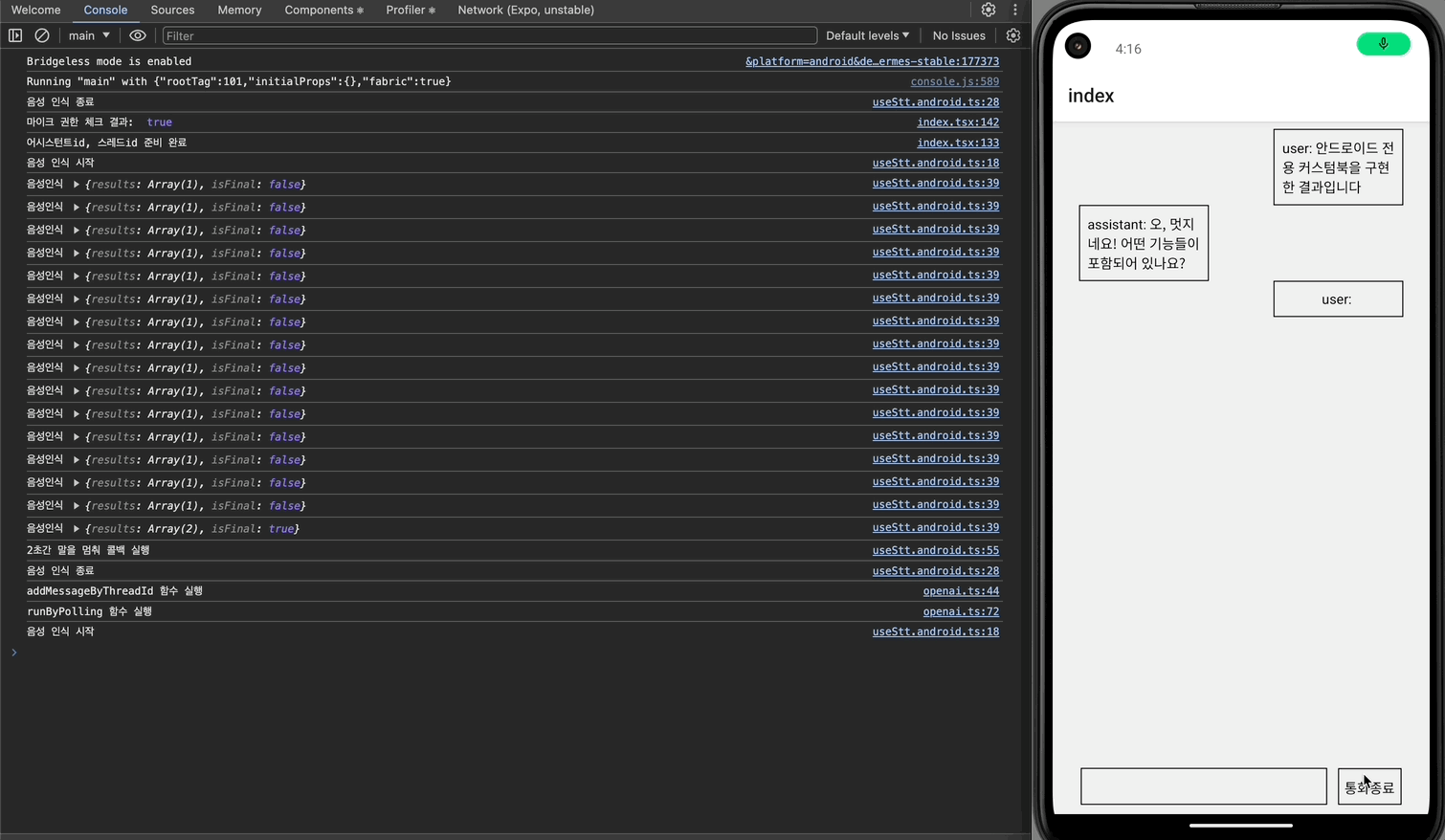
이제 안드로이드에서도 어시스턴트와 대화를 주고받을 수 있게 되었다.
TTS 파일 저장 구현
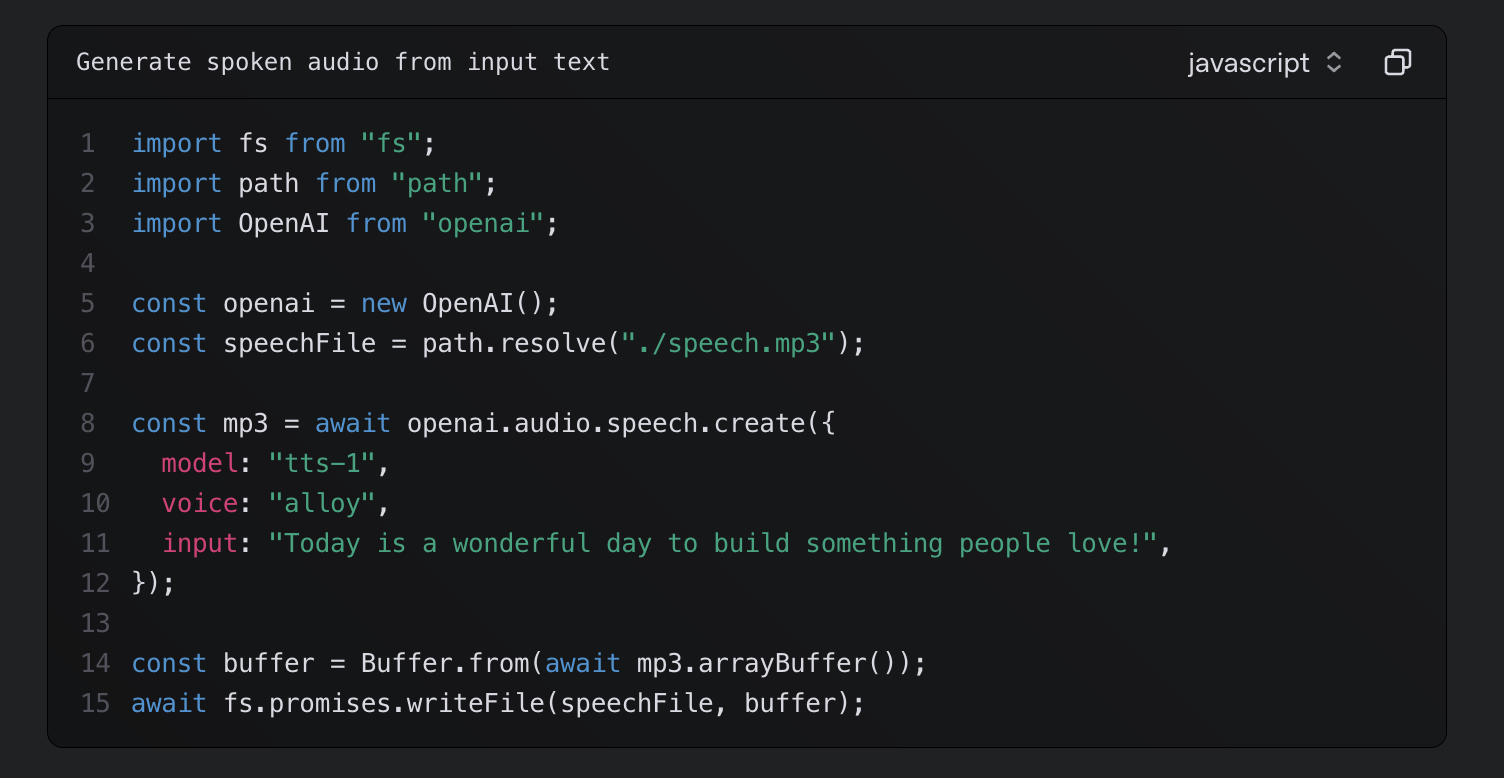
OpenAI 공식 문서를 살펴보면, API의 응답을 arrayBuffer 형식으로 받아와 Buffer로 변환하고 file system을 활용해 파일을 생성해야 한다는 것을 알 수 있다.
파일을 읽고 쓰기 위한 라이브러리로 두 가지를 고려했으나, 유지보수 상태를 고려해 최종적으로 expo-file-system을 선택했다.
- react-native-fs: 이전에 사용해본 라이브러리지만, 현재 유지보수되고 있지 않다.
- expo-file-system: Expo SDK에 포함되어 있어 유지보수가 활발한 편이다.
하지만 expo-file-system 공식 문서에 Buffer를 파일로 작성하는 방법에 대해서는 나와있지 않았고, 나와 비슷한 사례를 찾아보았으나 쉽지 않았다.
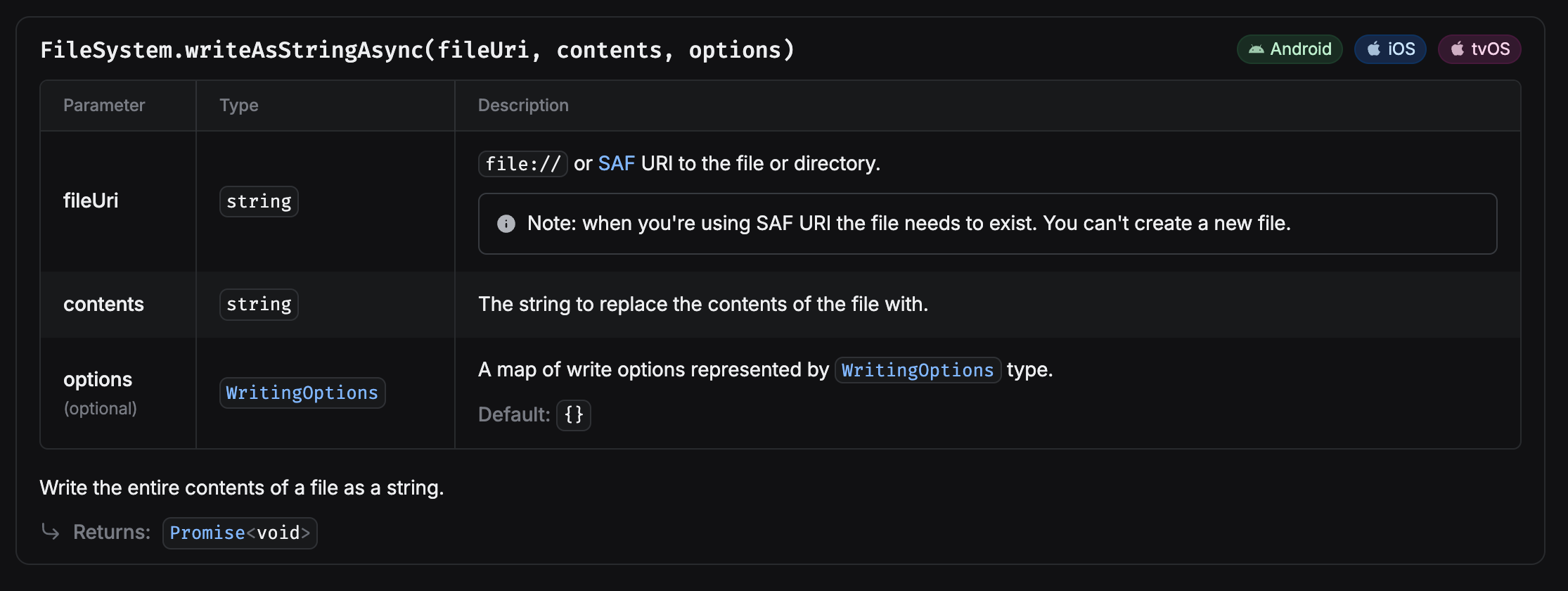
잘 알지 못하는 분야는 GPT를 활용하지 않고 있지만(할루시네이션을 인식할 방법이 없기 때문), 아이디어를 얻기 위해 질문하니 Base64를 활용하는 방법을 제시해줬다. Base64는 문자열이기 때문에 writeAsStringAsync 함수로 파일을 쓸 수 있을 것 같았다.

정말 가능한지 찾아보니 writeAsStringAsync 함수의 Option으로 UTF-8과 Base64 중 하나를 선택할 수 있다는 것을 확인했고, 구현을 시작했다.
1. expo-file-system 설치
공식 문서를 참고해 설치하면 된다.
# pnpm을 사용하는 경우
pnpm dlx expo install expo-file-system
pnpm run android
pnpm run ios2. OpenAI TTS API 함수 구현
OpenAI 공식 문서대로 API를 호출한 뒤, 응답을 캐시 디렉토리에 mp3 파일로 저장하고, uri를 반환하는 getTTSUri 함수를 구현해보자.
// openai.ts
import OpenAI from "openai";
import * as FileSystem from "expo-file-system";
import { Buffer } from "buffer";
...
export const getTTSUri = async (text: string): Promise<string | null> => {
try {
const mp3 = await openai.audio.speech.create({
model: "tts-1",
voice: "alloy",
input: text,
});
const buffer = Buffer.from(await mp3.arrayBuffer()); // 여기까지 공식문서와 동일
const uri = FileSystem.cacheDirectory + Date.now().toString() + ".mp3"; // mp3를 저장할 경로 생성
await FileSystem.writeAsStringAsync(uri, buffer.toString("base64"), {
encoding: "base64",
}); // buffer를 base64로 변환하고, 인코딩 타입도 base64로 지정
console.log("TTS 파일 저장 성공");
return uri; // 저장된 경로 반환
} catch (e) {
console.error("TTS 파일 저장 실패", e);
return null;
}
};방법만 떠오른다면, 코드는 매우 간단하다!
TTS 재생 구현
Expo SDK에는 오디오 파일을 재생하기 위한 두 개의 라이브러리가 존재한다.
- expo-audio: hook을 활용해 조작하는 방식이라 파일 경로가 미리 준비되어 있어야 한다.
- expo-av: 함수를 활용해 조작하는 방식이라 매개변수로 파일 경로를 넘겨주면 된다.
expo-audio 예제  | expo-av 예제 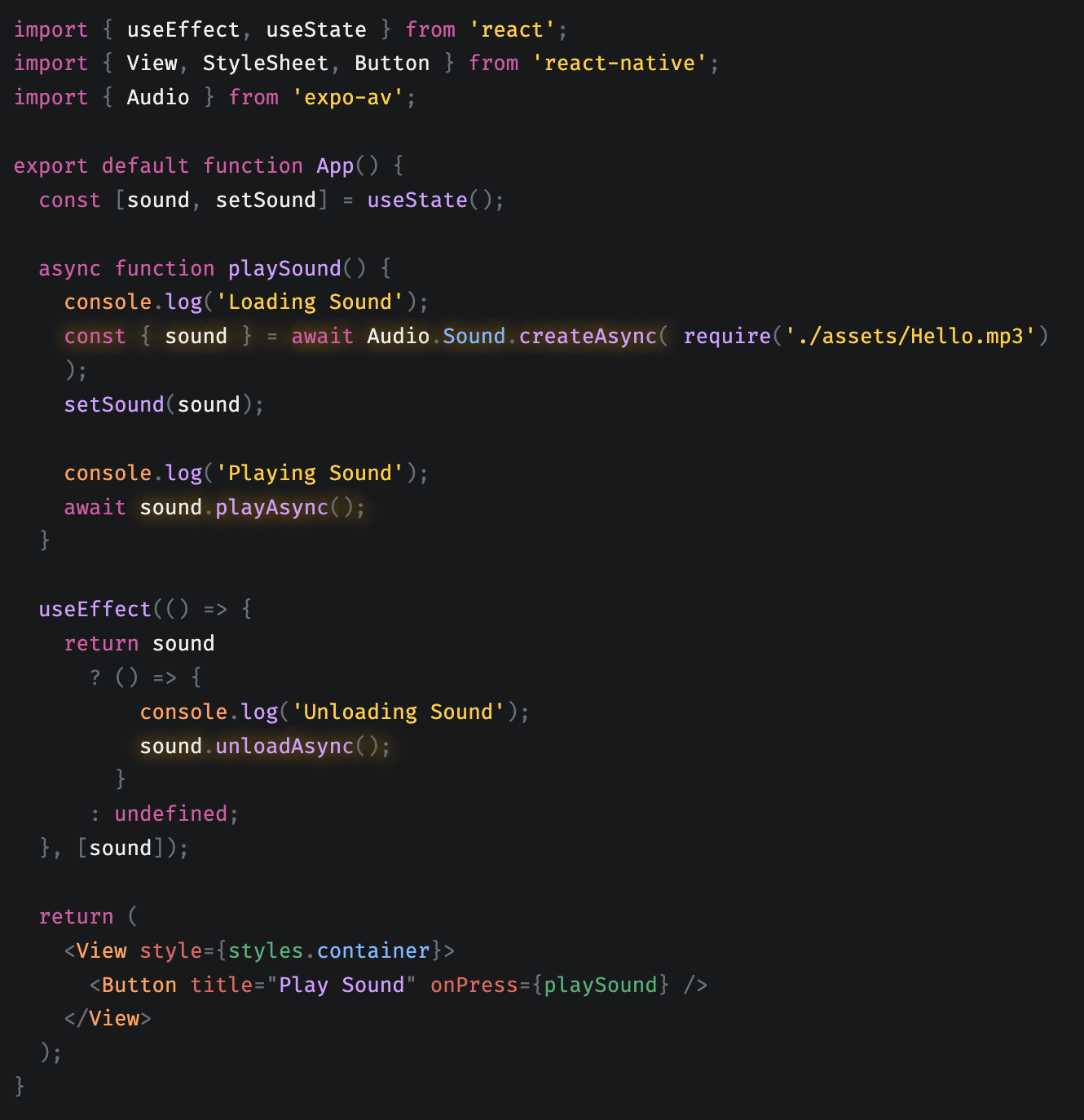 |
|---|
현재 내 코드에서는 getTTSUri가 resolve 되어야만 파일 경로를 알 수 있으므로, 함수로 조작하는 방식인 expo-av 라이브러리를 사용하기로 결정했다.
1. expo-av 라이브러리 설치
역시 공식 문서를 참고해 설치하면 된다.
pnpm dlx expo install expo-av
pnpm run android
pnpm run ios백그라운드 재생/녹음은 수행하지 않을 것이므로,
app.json은 수정하지 않았다.
2. setOnPlaybackStatusUpdate 함수 이해하기
uri를 활용해 audio 객체를 생성하고 재생한 뒤, 재생이 끝나면 isLoading을 false로 변경하도록 구현해야 한다. 그래야만 TTS 재생이 끝난 뒤 STT가 시작된다.
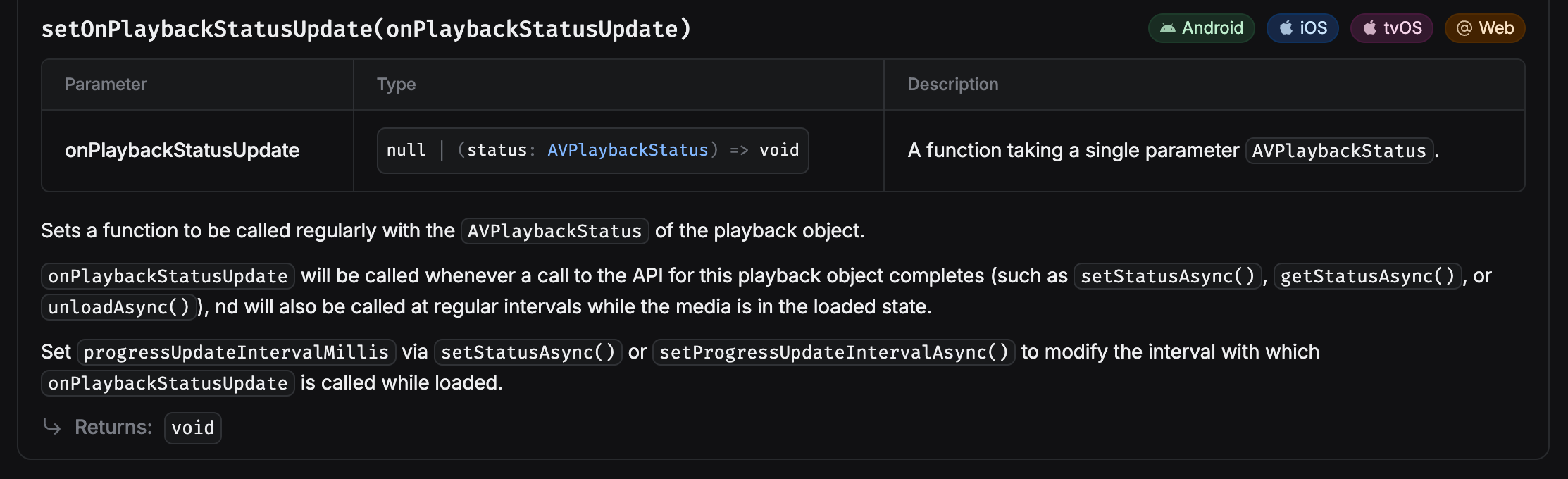
재생이 끝났는지 확인하기 위해 audio 객체의 setOnPlaybackStatusUpdate 함수를 활용할 것이다.

setOnPlaybackStatusUpdate 함수의 콜백 함수 매개변수 타입인 AVPlaybackStatus는 AVPlaybackStatusError와 AVPlaybackStatusSuccess의 유니온으로 구성되어 있다.

재생이 끝났는지 확인하기 위해서는 AVPlaybackStatusSuccess의 didJustFinish가 true인지 확인하면 된다.
즉, AVPlaybackStatus를 AVPlaybackStatusSuccess로 내로잉한 뒤, didJustFinish에 접근해야만 한다. 이 부분에서 좀 해멨었다. (didJustFinish가 안 떠서 deprecated된 줄 알았다...)
3. TTS를 재생하고, 재생이 끝나면 콜백함수를 실행하는 함수 구현
expo-av 공식 문서를 참고하고, setOnPlaybackStatusUpdate 함수를 이해하면 쉽게 구현할 수 있다.
// playTTS.ts
import { Audio } from "expo-av";
export const playTTS = async (uri: string, finishCallbackFn: () => void): Promise<void> => {
try {
// IOS 음소거 토글에 영향받지 않고 재생하기 위한 설정
await Audio.setAudioModeAsync({ playsInSilentModeIOS: true });
// sound 객체 생성
const { sound } = await Audio.Sound.createAsync({ uri }, { shouldPlay: true });
// 재생
await sound.playAsync();
// 재생 상태 업데이트 이벤트 핸들러 구현
sound.setOnPlaybackStatusUpdate((status) => {
// 먼저, AVPlaybackStatusSuccess로 내로잉
if (status.isLoaded) {
// 그리고, 재생이 끝났는지 확인
if (status.didJustFinish) {
finishCallbackFn(); // 매개변수로 받은 콜백함수 실행시키기
sound.unloadAsync(); // sound 객체 반환
}
}
});
} catch (e) {
console.error(e);
}
};if문은 당연히
if (status.isLoaded && status.didJustFinish) { ... }로 축약할 수 있다. 주석을 위해 나눈 것 뿐이다.
useStt 훅에 통합
지금까지 구현한 getTTSUri와 playTTS 함수를 useStt에서 호출해 TTS 재생 기능 구현을 마무리해보자.
useStt.ts와 useStt.android.ts 모두 동일하게 추가하면 된다.
// useStt.ts || useStt.android.ts
...
export const useStt = (
isSttMode: boolean,
assistantId: string | null,
threadId: string | null,
setChats: Dispatch<SetStateAction<Chat[]>>
) => {
...
// 어시스턴트를 run 시키는 useEffect
useEffect(() => {
const runAssistant = async () => {
if (isSttMode && assistantId && threadId) {
if (isLoading && recognizedRef.current !== "") {
try {
await addMessageByThreadId(recognizedRef.current, threadId);
const newMsgs = await runByPolling(assistantId, threadId);
if (newMsgs) {
const assistantAnswer = newMsgs[newMsgs.length - 1].text;
// 어시스턴트의 답변을 TTS mp3 파일로 생성하고, 경로 반환
const uri = await getTTSUri(assistantAnswer);
// TTS mp3 파일을 생성한 뒤에 화면에 채팅 반영하기 위해 아래로 내림
setChats(newMsgs);
if (uri) {
// 경로가 존재하면 mp3를 재생하고, 재생이 종료되면 loading을 false로 변경
playTTS(uri, () => setIsLoading(false));
}
}
} catch (e) {
console.error(e);
}
}
}
};
runAssistant();
}, [assistantId, isLoading, isSttMode, setChats, threadId]);
};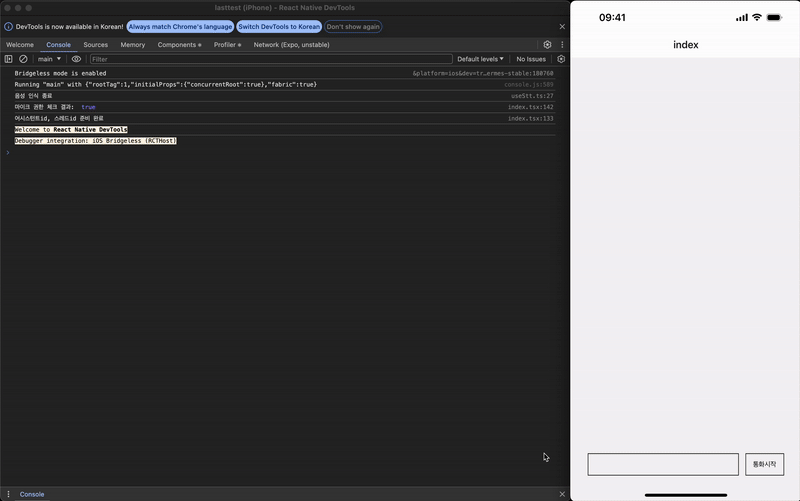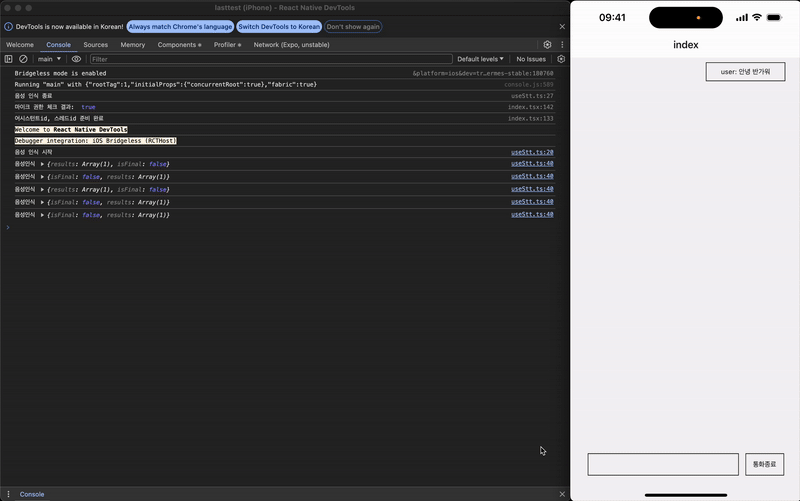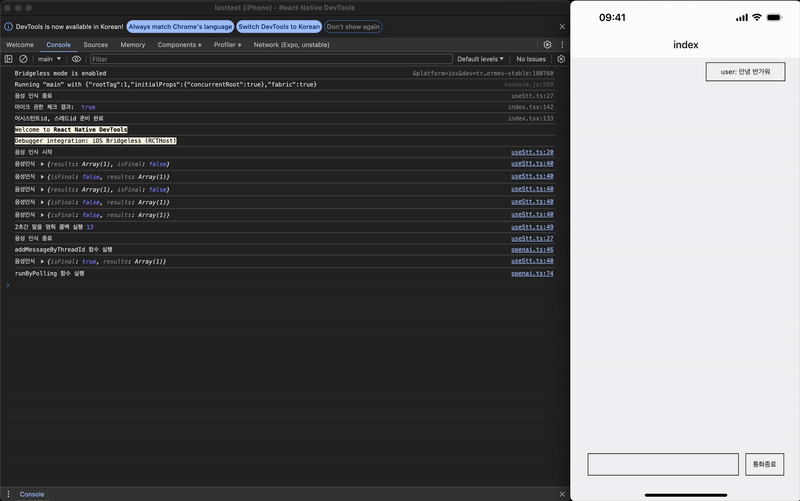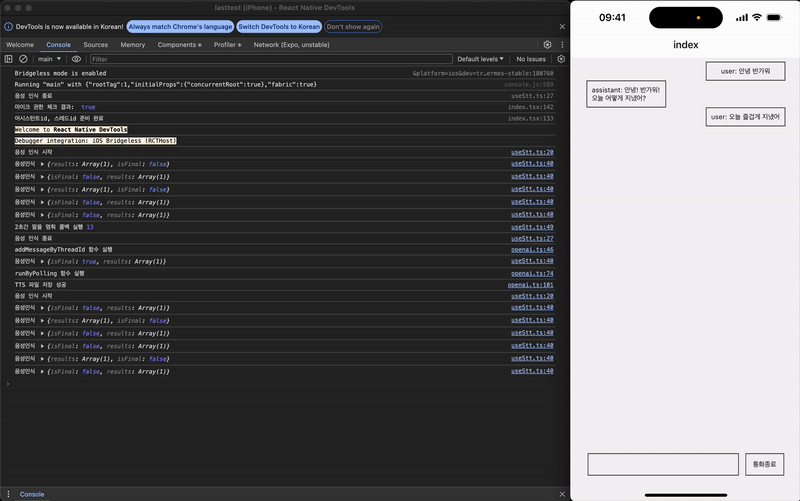
테스트 결과 STT-TTS가 잘 작동하는 것을 확인할 수 있다.
(위 GIF를 클릭하면 유튜브에서 TTS를 실제로 확인할 수 있습니다)
정리
포스팅 도중 실제 앱 개발에 돌입하게 되어 마무리를 짓지 못하다가, 이제서야 작성을 마쳤다.
우리 앱(Melissa)을 잠깐 홍보하자면 몇가지 설문을 기반으로 생성되는 자신만의 서포터 AI와 하루동안 있었던 일에 대해 채팅으로 대화를 나누면, AI를 활용해 채팅 내역으로부터 그림 일기를 생성하고, 캘린더에서 확인할 수 있는 앱이다.
앱 레이아웃과 디자인이 아주 깜찍하다. 주 타겟은 "일기를 쓰기는 귀찮지만, 일상을 기록하고 싶어하는 사람"들로 잡았다. (이거 완전 나잖아?)
현재 MVP 기능 구현과 스토어 배포 자동화를 마친 상태고, 앱스토어와 플레이스토어 심사를 진행 중이라 잠시 시간이 남아 개발 과정에서 있었던 기록할만한 것들을 남겨두려고 한다.
리액트 네이티브 정보는 리액트에 비해 많이 부족하다. expo-speech-recognition도 국내에서 사용해본 후기는 하나도 없었다. 매우 좋은 라이브러리라 STT 기능이 필요하면 적극적으로 사용하면 좋을 것 같다.
정보 부족으로 인해 트러블슈팅 시 주로 Github issue나 stackoverflow, Expo 디스코드를 활용하게 되는데, 개인적으로 국내에 리액트 네이티브 정보가 많아지면 좋겠다는 생각을 가지고 있기 때문에 나 역시 다양한 경험을 잘 정리해 공유하려 하고 있다.
글 읽어주셔서 감사합니다. 혹시 Expo + RN을 사용해 STT, TTS 기능 구현을 시도하고 계시다면 도움이 되었길 바랍니다.
이 글에 대한 가독성, 오탈자/오개념, 코드 오타 등 다양한 지적을 환영합니다!
