
▣ 1.1 오라클 데이터 베이스 서버의 구조를 알아야해요
+-------------------+ +-----------------+ +---------------+
| data buffer cache | | redo log buffer | | shared pool |
| | | | | |
| | | | | |
+-------------------+ +-----------------+ +---------------+
|| ||
[DBWR] [LGWR]
|| ||
\/ \/
+-----------+ +------------------+ +--------------+
| data file | | redo log file | | control file |
+-----------+ +------------------+ +--------------+
클라이언트 ------------------> 서버
User process server process
select ename, sal 1. 오라클 메모리에서 data 를 검색
from emp 2. 없으면 database 에서 data 를 검색
order by sal desc; 3. 오라클 메모리에 결과 데이터를 올립니다.
4. 정렬 작업은 개별 메모리인 pga 에서 정렬합니다.
5. 결과를 user process 에게 전달
오라클 데이터 베이스의 구조는 ?
1. 데이터 베이스
2. 메모리 오라클 메모리를 따로 두는 이유는 ? 메모리에 데이터를 올려놓고 데이터 검색을 빠르게 하기 위해서 입니다.
예: 사전 ------------------------------ 단어장
(database) ( 오라클 메모리)
실습:
-
sys 유져로 접속합니다.
$ sqlplus "/as sysdba"x
-
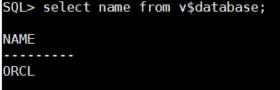
오라클 db 의 이름을 확인합니다.
SQL> select name from v$database;
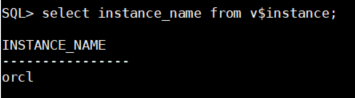
- 오라클 메모리(instance)의 이름을 확인합니다.
SQL> select instance_name from v$instance;
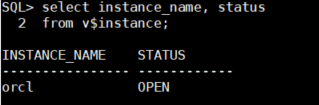
문제1. 오라클 메모리가 잘 열려있는지 확인하시오 !
select instance_name, status
from v$instance;
▣ 1.2 오라클 데이터 베이스 메모리의 구조를 알아야해요
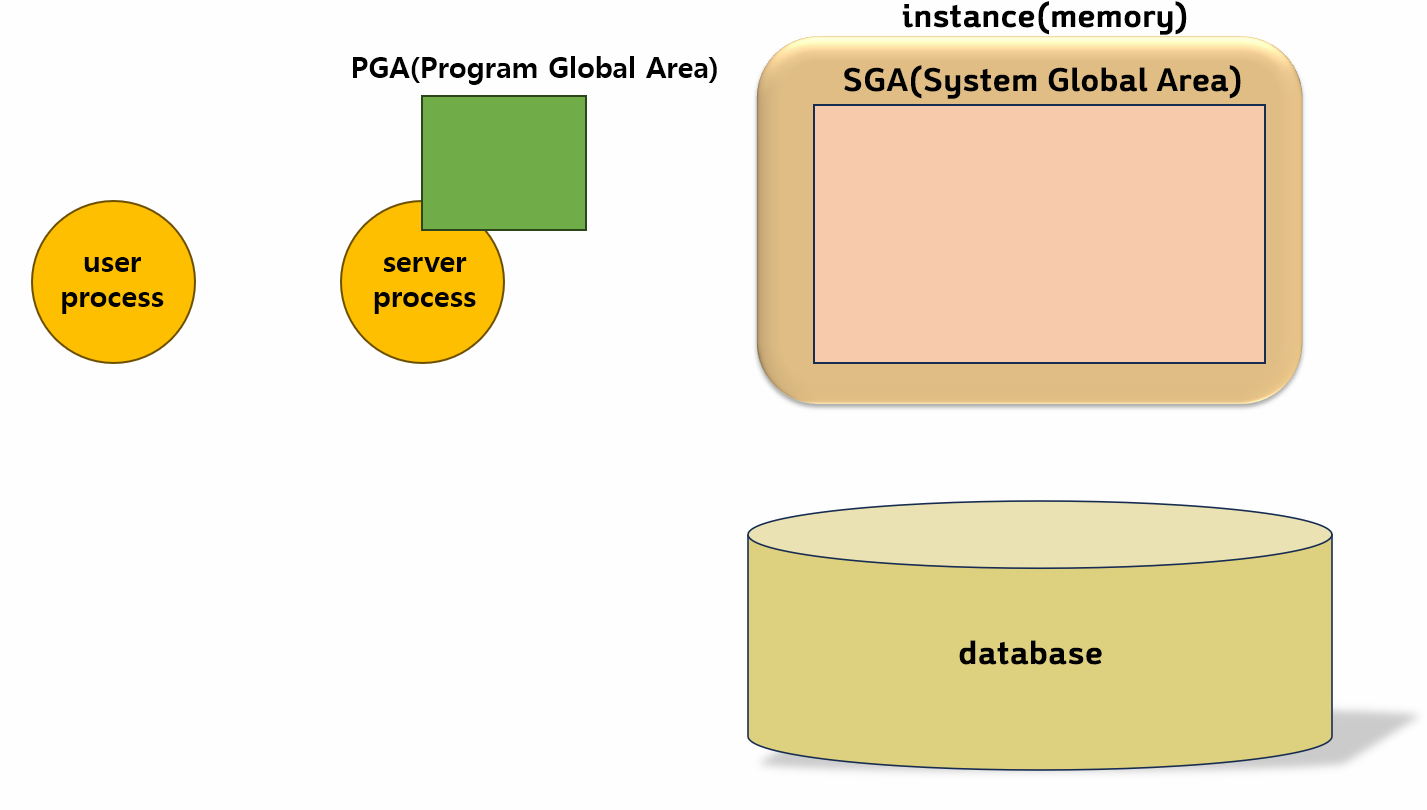
1️⃣ 오라클 메모리의 2가지 큰 구조
-
SGA ( System Global Area) : 오라클 프로세서들이 공유해서 사용하는 공유 메모리 영역입니다.
-
PGA ( Program Global Area) : 서버 프로세서가 개별적으로 사용하는 메모리 영역입니다. 이 영역에서 정렬 작업과 해쉬조인을 합니다.
위의 2개의 영역이 memory_target 이라는 파라미터로 통합되고 관리되고 있습니다. 자동으로 관리되고 있습니다.
자동으로 관리되고 있다는것은 오라클 메모리 영역의 각각의 사이즈를 오라클이 스스로 조절합니다.
dba 는 그냥 memory_target 사이즈만 셋팅해 놓으면 끝입니다.
2️⃣ 실습1. 현재 memory_target 사이즈가 몇으로 셋팅되어있는지 확인합니다.
$ sqlplus "/ as sysdba"
SQL> show parameter memory_target
낮시간 : sga > pga
밤시간 : sga < pga
낮에는 계속 insert 가 일어나고 간단한 쿼리문이 수행된다면
밤에는 낮에 입력한 데이터를 집계해서 통계값들을 구하는 쿼리문이 돕니다.
⭐ 문제1. 현재 sga 사이즈와 pga 사이즈가 어떻게 셋팅되어 있는지 확인하세요 !

▩ 1.3 공유풀(shared pool)이 왜 필요한지 알아야해요.
질문: shared pool 의 역할이 무엇인가요 ?
답: parsing 을 최소화 하기 위한 메모리 영역입니다.
parsing 의 뜻 ? 사람이 알아볼 수 있는 SQL과 같은 코드를 기계어로 변환
SQL을 실행하면 파싱을 하는데 파싱된 데이터를 Shared pool 에 올리고 재사용을 합니다. 재사용하므로 다시 파싱하지 않습니다.
이 파싱이 cpu 를 많이 사용하는 값비싼 작업니다.
※ select 문의 처리과정 3가지 (★★★)
유져 프로세서 ----------------------------> 서버 프로레서 select empno, ename,sal 파싱을 수행
from emp
where ename='SCOTT';
-
파싱(parsing) : - 문법 검사(syntex check) : SQL이 문법적으로 문제가 없는지
- 의미 검사(symentic check) : emp 테이블이 db 에 있는지파싱 결과물 3가지 ? 1. SQL문장 2. 실행계획 3. Parse tree (실행가능한 코드)
위의 3가지 결과물을 shared pool 에 library cache 에 올립니다.
왜 올리는가? 다음번에 똑같은 문장이 들어오면 파싱과정을 생략하려고
-
실행(execute) : 옵티마이져가 생성해준 실행계획으로 실행 데이터를 검색하는 작업입니다.
-
패치(fetch) : 서버 프로세서 ----------------> 유져 프로세서
결과 데이터실습 주제: 똑같은 sql이 들어와야 파싱과정을 생략할 수 있다고 했는데 그럼 똑같은 sql이 무엇인가 ?
-
대소문자 구분:
예: SELECT ENAME,SAL FROM EMP WHERE EMPNO=7788;
select ename,sal from emp where empno=7788; -
공백, 들여쓰기 구분
예: select empno, ename, sal from emp;
select empno, ename, sal from emp; -
리터럴 SQL 구분
예: select empno, ename, sal from emp where empno = 7788;
select empno, ename, sal from emp where empno = 7902;
실습1: dbever 로 오라클에 접속합니다.
실습2: 아래의 sql을 실행합니다.
select empno,ename,sal from emp where empno = 7788;
실습3: 실습2의 sql이 shared pool 에 있는지 확인합니다.
select sql_id, child_number, sql_text
from vsql%'
order by last_load_time desc;
SELECT * FROM TABLE(dbms_xplan.display_cursor('', 0 ,'ALLSTATS LAST'));
실습4: 실습2 의 sql에 공백을 좀더 넣어서 실행합니다.
select empno,ename,sal from emp where empno = 7788;
실습5: 실습4의 sql이 shared pool 에 있는지 확인합니다.
select sql_id, child_number, sql_text
from vsql%'
order by last_load_time desc;
SELECT * FROM TABLE(dbms_xplan.display_cursor('', 0 ,'ALLSTATS LAST'));
▩ 1.4 데이터베이스 버퍼 캐쉬(database buffer cache) 가 왜 필요한지 알아야해요.
다음과 같이 SQL문을 실행했다고 해볼께요.
select sal
from emp
where ename='SCOTT';
버퍼 캐쉬가 필요한 이유?
한번 검색해서 DATA FILE 에서 찾은 데이터를 BUFFER CACHE 에 올리고 다음번에 또 찾을때 BUFFER CACHE에서 검색하려고 필요합니다.
실습1. DB BLOCK 사이즈가 몇인지 확인하시오!
SQL> show parameter db_block_size

※ db buffer cache 를 효율적으로 사용하기 위한 알고리즘 ?
답: LRU(least recent use) 알고리즘
select sal
from emp
where ename='SCOTT';
- 인덱스 스캔 : single block i/o 가 발생
- Full table 스캔 : multi block i/o 가 발생
dba가 이 내용을 알고 있어야하는 이유 ?
답: 자주 엑세스하는 작은 테이블은 테이블의 cache 속성을 nocache 가 아니라 cache로 해주면 좋은 성능을 보입니다.
테이블의 cache 속성이 2가지 ?
-
nocache : index scan 을 하면 MRU 로 블럭을 올리고 full table scan 을 하게 되면 LRU 쪽에 블럭을 올리는 속성
-
cache : index scan 을 하든 full table scan 을 하든 모두 MRU 로 올리는 속성
실습1: putty 에서 scott 유져로 접속합니다.
$ sqlplus scott/tiger
SQL> select table_name, cache
from user_tables
where table_name in ('EMP', 'DEPT');
둘다 nocache 입니다
그런데 만약 emp 테이블이 우리회사에서 정말 자주 엑세스하는 중요한 테이블이다라면?
답: cache 테이블로 변경해줘야합니다.
SQL> alter table emp cache;
SQL> select table_name, cache
from user_tables
where table_name in ('EMP', 'DEPT');
SQL> select sal
from emp
where ename='SCOTT';
문제1. DEPT 테이블의 CACHE 속성을 CACHE 로 변경하시오 !
SQL> alter table dept cache;
SQL> select table_name, cache
from user_tables
where table_name in ('EMP', 'DEPT');
문제2. emp 테이블을 다시 nocache 속성으로 변경하시오 !
SQL> alter table emp nocache;
SQL> select table_name, cache
from user_tables
where table_name in ('EMP', 'DEPT');
문제3. emp 테이블을 cache 속성으로 바꾸지 말고 쿼리 레벨에서 cache 속성이 되게 하시오 !
SQL> select /+ cache / sal
from emp
where ename='SCOTT';
※ (OCP 문제) 어떤 테이블을 CACHE 속성으로 만들어야하는가 ?
답 : 작고 자주 엑세스하는 테이블
▩ 1.5 리두로그 버퍼(redo log buffer) 가 왜 필요한지 알아야해요.
update emp
set sal = 0
where ename='SCOTT';
리두 로그 버퍼에 DB 의 변경사항을 기록하는 이유 ? 장애가 났을때 복구할 때 쓰려고
- DML 작업
- DDL 작업
변경사항은 시간정보와 같이 기록합니다.
DBA 가 제일 1순위로 챙겨야하는 일 ? 1. 데이터 백업이 잘 수행되고 있는지 확인하는일
백업본은 있는데 내가 복구를 못한다면 ? 전문가들이 와서 다 해줍니다.
백업본이 없다 ? 대박 ~ 고난이 시작되는데 3달 갑니다.
복구가 가능한 이유 ? 1. 백업본이 있고
2. 오라클이 계속 리두 버퍼에 변경사항을 기록합니다.
※ UPDATE 문의 처리과정
update emp
set sal = 0
where ename='SCOTT';
-
Parsing : 문법검사, 의미검사를 합니다.
-
execute :
① 데이터를 db buffer cache 에 올립니다.
② 업데이트하려는 해당행에 lock 을 겁니다.
③ redo log buffer 에 변경사항을 기록합니다.
④ rollback buffer 에 3000을 기록합니다.
⑤ 값을 변경(3000-->0 변경)
실습1: 리두 로그 버퍼의 크기를 확인하시오 !
SQL> show parameter log_buffer

▩ 1.6 PGA 메모리 영역
PGA 메모리 영역은 왜 필요한가 ? SQL의 정렬 작업을 하기 위해서 필요합니다.
* 정렬을 일으키는 SQL ? 1. order by
2. sort merge join
3. create index 생성문 실행시
4. intersect, union, minus 가 19c 까지는 정렬을 했는데 21c 부터 정렬을 안합니다.
5. 데이터 분석함수 사용시 현업에서 위의 작업들을 dba 나 개발자들이 수행할 때 대량의 데이터를 정렬하는 경우
out of memory 에러가 나면서 작업이 안되는 경우가 종종 발생합니다.
이런 에러가 나지 않도록 pga 영역의 사이즈 조절을 잘 해야합니다.
pga 영역에 해쉬 area 가 해쉬조인시 해쉬 테이블이 올라가는 공간으로 사용이 됩니다.
해쉬조인 속도를 높이려면 pga 영역의 사이즈를 늘릴 필요가 있습니다.
■ 대량의 데이터를 정렬할 때 또는 해쉬조인의 속도를 빠르게 할 때 pga 영역을 다루는 방법은 ?
pga 영역은 오라클에 의해서 사이즈가 자동 조절 되고 있습니다.
dba 가 memory_target 이라는 파라미터 하나만 설정해 놓으면
나머지는 오라클이 다 알아서 합니다.
낮시간: sga > pga
밤시간: sga < pga
관련 설명 그림: https://cafe.daum.net/oracleoracle/So33/46

■ 실습
#1. memory_target 사이즈가 몇인지 확인하시오 !
SQL> show parameter memory_target
460M
이 사이즈를 늘릴려면 memory_max_target 을 먼저 늘려야 합니다.
memory_max_target 을 늘릴려면 db 를 내렸다 올려야 합니다.
460m 내에서 오라클이 알아서 sga 사이즈와 pga 사이즈를 자동 조절합니다.
#2. sga 영역의 사이즈를 확인하시오 !
@sga.sql
#3. pga 영역의 사이즈를 확인하시오 !
SQL> show parameter pga
pga_aggregate_target big integer 0
#4. 현재 pga 영역의 사용현황을 보고 싶다면 ?
SQL> SELECT a.name, b.value "Current", a.value "Max", (a.value - b.value) "Diff"
FROM VPARAMETER b
WHERE a.name = 'total PGA inuse' AND b.name = 'pga_aggregate_target';
total PGA inuse 0 55280640 55280640
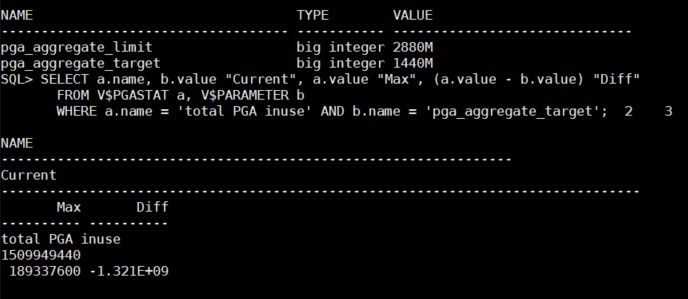
문제1. 과도한 정렬작업을 일으키고 PGA 영역이 사용되는지 사용현황을 확인하시오 !
#1. putty 에서 scott 유져로 접속해서 수행
SELECT e1.sal
from emp e1, emp e2, emp e3, emp e4, emp e5, emp e6, emp e7
order by e3.sal desc;
#2. dbever 에서 sys 나 scott 에서 확인
SELECT a.name, b.value "현재셋팅", a.value "현재사용율"
FROM VPARAMETER b
WHERE a.name = 'total PGA inuse' AND b.name = 'pga_aggregate_target';
현재셋팅이 0 이면 오라클에 의해서 자동 조절되고 있다는것임.
현재 사용율을 실제로 pga 영역에서 사용되고 있는 사용율 입니다.
▩ 1.7 DBWn 프로세서( 데이터베이스 기록자 프로세서 )
- 필수용어:
데이터베이스 버퍼캐쉬는 3개의 버퍼로 구성되어 있습니다.
1. free buffer : 비어있는 버퍼
2. pinned buffer : 비어있지 않은 버퍼( 데이터가 변경되지 않은 버퍼)
3. dirty buffer : 비어있지 않은 버퍼(데이터 변경되어어서 디스크의 데이터와 서로 일치하지 않는 버퍼) select sal
from emp
where ename='SCOTT';
update emp
set sal = 0
where ename='SCOTT';
관련 그림: https://cafe.daum.net/oracleoracle/So33/50
- DBWR 가 하는 역활 ?
Oracle 데이터베이스에서 DBWR(Database Writer)는 매우 중요한 백그라운드 프로세스 중
하나입니다. DBWR의 주된 역할은 버퍼 캐시(Buffer Cache)에서
수정된(더티) 블록을 디스크로 쓰는 것입니다.
이 과정은 데이터베이스의 무결성과 성능을 유지하는 데 중요한 부분을 차지합니다.
■ 실습:
#1. DBWn 백그라운 프로세서가 있는지 조회하시오 !
select pname, spid
from v$process
where pname like 'DBW%';
DBW0 5241
#2. 리눅스 Putty 에서 spid 5241 프로세서를 조회하시오 !
$ ps -ef | grep 5241 | grep -v grep
#3. dbwr 가 얼마나 바쁜지 확인하시오 !
$ top -p 5241
#4. dbwr 를 kill 시키면 어떻게 되는지 확인하시오 !
$ kill -9 5241
SQL> select instance_name from v$instance; <---- 현재 인스턴스의 상태를 확인
지금은 안바뻐서 1개가 떠있는데 dirty buffer 가 많아지면 자동으로 dbwr 의 갯수가 늘어납니다.
문제1. 19c 또는 21c 에서는 dbwr 의 갯수가 몇개인지 확인하시오 !
답: select pname, spid
from v$process
where pname like 'DBW%';
기본 2개가 뜨고 있습니다. dirty buffer 가 많아지면 자동으로 갯수가 늘어납니다.
▩ 1.8 LGWR (log writer )
LGWR 의 역활 ? 리두 로그 버퍼의 내용을 리두 로그 파일에 내려쓰는 프로세서
chatGPT 에게 질문: 오라클 LGWR 가 리두로그 버퍼의 내용을 리두로그 파일에 내려쓰는
4가지 시점을 알려줘 ?
-
commit 할 때
-
리두로그 버퍼가 어느 정도 찼을때
-
3초마다
-
checkpoint 이벤트(메모리의 내용을 database 에 일괄 적용)
ckpt 프로세서 -------> lgwr 프로세서 ---------> dbwr 프로세서
■ 실습.
#1. v$process 를 조회해서 LGWR 의 SPID 를 알아내세요 !
select pname, spid
from v$process
where pname like 'LGW%';
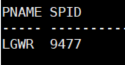
#2. SPID 로 TOP 명령어를 날려서 얼마나 바쁜지 확인하시오 !
$ top -p 310
문제1. LGWR 관련해서 DBA 에게 유용한 스크립트를 1개만 알려줘.라고 chatGPT 에게
물어봅니다.
SELECT
a.name,
b.value AS "Redo Log Buffer Writes",
c.value AS "Redo Log Writes"
FROM
vsysstat b, v$sysstat c
WHERE
a.statistic# = b.statistic# AND
a.statistic# = c.statistic# AND
a.name IN ('redo buffer allocation retries', 'redo writes');
DB 올린 이후에 229번 Lgwr 가 작동했습니다.
문제2. 윤호가 올려준 Shell script 를 수행해서 LGWR 가 현재 작동중 여부를 확인하시오 !
#!/bin/bash
Check if LGWR process is running
lgwrprocess=$(ps -ef | grep "ora_lgwr" | grep -v "grep" | wc -l)
if [ $lgwr_process -gt 0 ]; then
echo "LGWR process is running."
else
echo "LGWR process is not running. Please investigate."
You can add additional actions here, such as sending an alert email or restarting the database.
fi
▩ 1.9 CKPT (checkpoint process)
주기적으로 메모리(instance)에 있는 내용을 db 로 내려쓰는 이벤트를 일으키는 프로세서
ckpt 의 역할 ? 메모리의 내용을 db 로 내려쓰게 하면서 메모리와 db 간의
데이터의 일치를 맞춰주는 역활을 합니다.
이 이벤트 이름을 "checkpoint event" 라고 합니다.
이 작업 주기는 오라클에 의해서 자동으로 관리되고 있습니다.
메모리의 변경사항이 많으면 자주 내려쓰고 별로 없으면 덜 내려씁니다.
■ 실습:
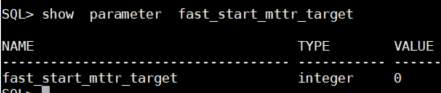
#1. 체크포인트 이벤트 주기가 자동으로 관리되는지 확인하시오 !
SQL> show parameter fast_start_mttr_target
#2. 수동으로 체크포인트 이벤트를 일으킵니다.
SQL> alter system checkpoint;
#3. data file 헤더의 체크포인트 번호를 확인하시오 !
SQL> select file#, checkpoint_change#
from v$datafile_header;
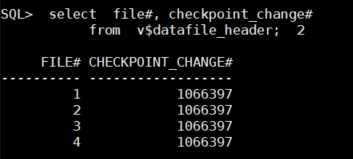
문제1. 체크 포인트를 수동으로 일으키고 데이터 파일 헤더의 체크포인트 번호가 변경되는지
확인하시오 !
문제2. dba.sh 스크립트에 체크포인트를 수동으로 일으키는 명령어를 추가하시오 !
SQL> ed ckpt.sql
$ vi dba.sh
echo "[1] 오라클에 접속하려면 1번을 누르세요
[2] 리눅스 서버에 부하를 확인하려면 2번을 누르세요
[3] 인덱스 정보를 확인하려면 3번을 누르세요
[4] 테이블 스페이스 공간을 확인하려면 4번을 누르세요
[5] db 의 이슈를 확인하려면 5번을 누르세요
[6] sga 영역내의 구성요소들의 현재 사이즈를 확인하려면 6번을 누르세요
[7] 리스너의 상태를 확인하려면 7번을 누르세요
[8] 체크포인트를 수동으로 일으키려면 8번을 누르세요"
echo " "
echo -n "원하는 작업을 선택하세요 "
read aa
echo " "
case $aa in
1) sqlplus sys/oracle_4U as sysdba ;;
2) top ;;
3) sh index.sh ;;
4) sh tablespace2.sh ;;
5) sh o.sh ;;
6) sqlplus sys/oracle_4U as sysdba @sga.sql ;;
7) lsnrctl status;;
8) sqlplus sys/oracle_4U as sysdba @ckpt.sql ;;
esac
