▣ 예제 22. RAC 환경에서 모든 인스턴스에 영향을 주는 명령어
-
현재 접속한 노드의 인스턴스에만 영향을 주는 명령어
-
alter system switch logfile;
-
recover 명령어
-
alter system checkpoint local;
-
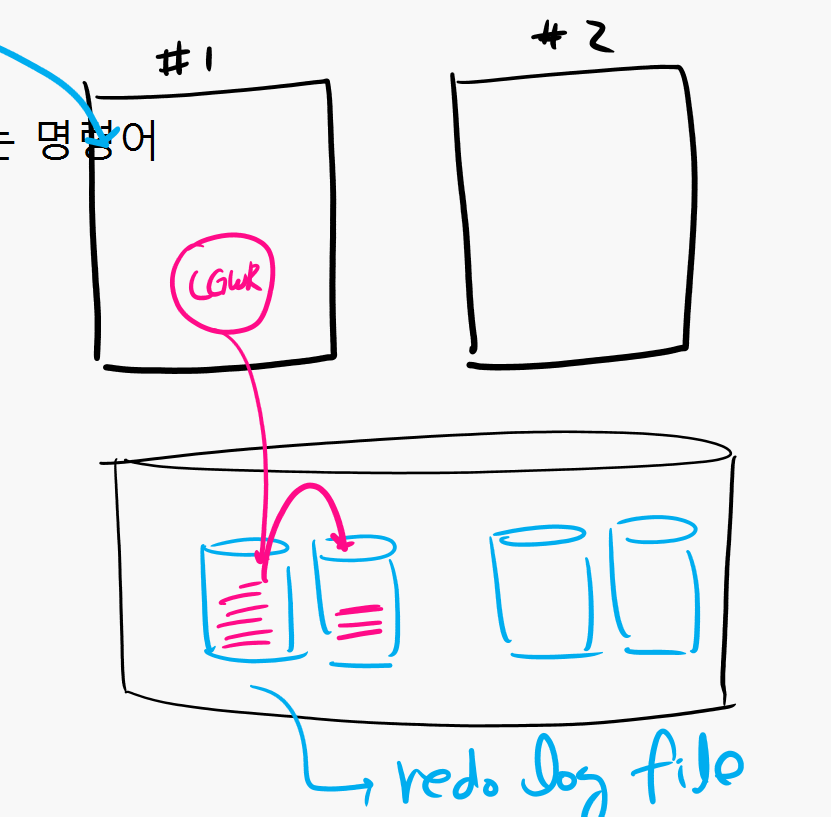
-
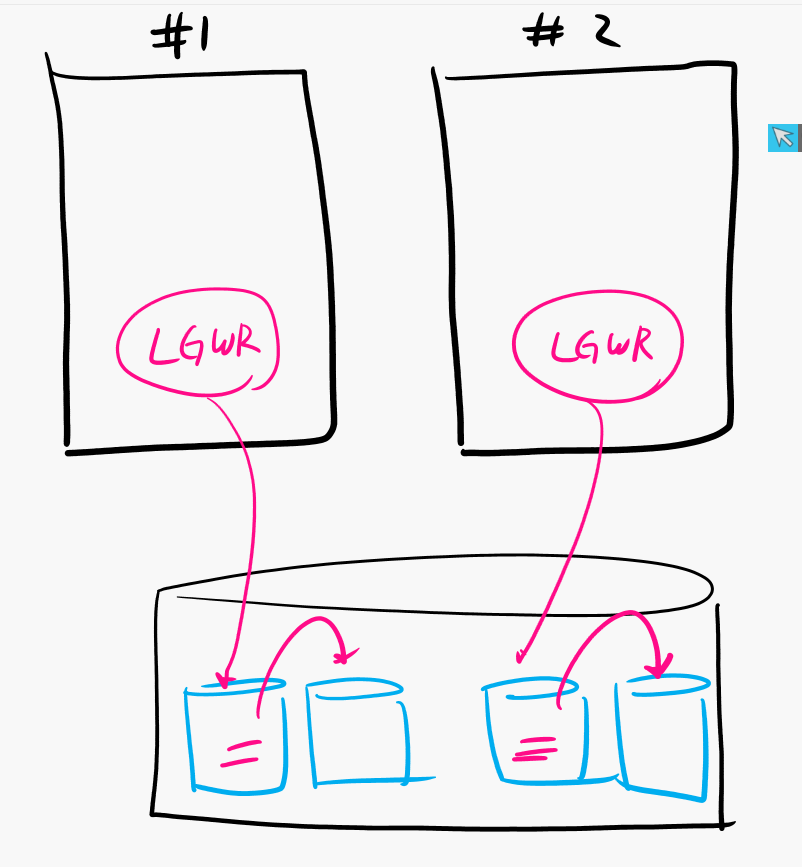
모든 인스턴스에 영향을 주는 명령어
- alter system archive log current ;
로그 스위치를 글로벌 하게 수행하는 명령어
- alter system checkpoint global ;
체크 포인트를 글로벌하게 수행하는 명령어
■ 실습
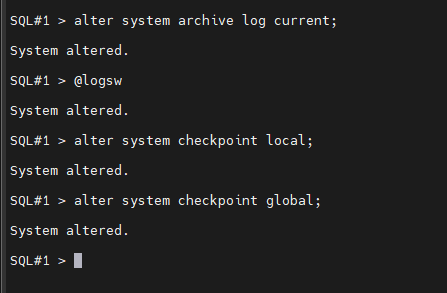
#1. 1번 인스턴스의 리두 로그 파일만 로그 스위치를 일으키시오 !
SQL#1> alter system switch logfile;
#2. 모든 인스턴스의 리두 로그 파일들을 전부 로그 스위치를 일으키시오
SQL#1> alter system archive log current;
#3. 1번 인스턴스에서만 checkpoiont 를 일으키시오 !
SQL#1> alter system checkpoint local;
#4. 모든 인스턴스에서 다 checkpoint 가 일어나게 하시오 !
SQL#1> alter system checkpoint global;
▣ 예제23. RAC 환경에서 전자지갑 사용하는 방법 (책 4-37)
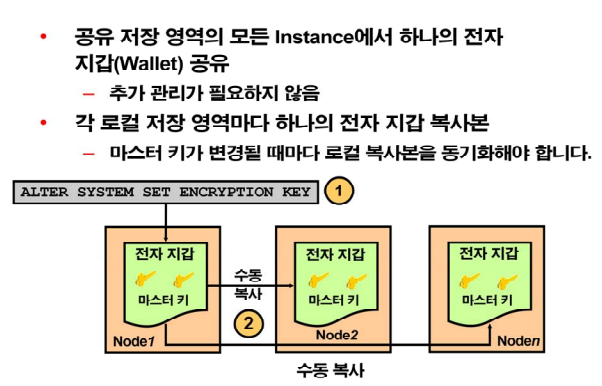
전자 지갑의 용도
특정 데이터를 보호하기 위한 용도로 쓰인다
어떤 중요한 컬럼을 엑세스 하지 못하게 할 때 사용한다.
■ 실습


2번노드
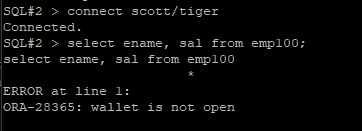
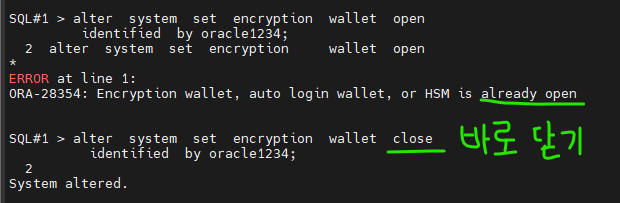
전자지갑이 닫혀 있어서 안보인다
볼려면 열어야 한다
2번 노드에 전자지갑을 copy 해줘야 한다.
전자지갑을 1번 노드에서 2번 노드로 copy 해준다.
scp 명령어는 네트워크를 통해서 다른 컴퓨터로 파일을 copy 하는 리눅스 명령어입니다.
1번노드

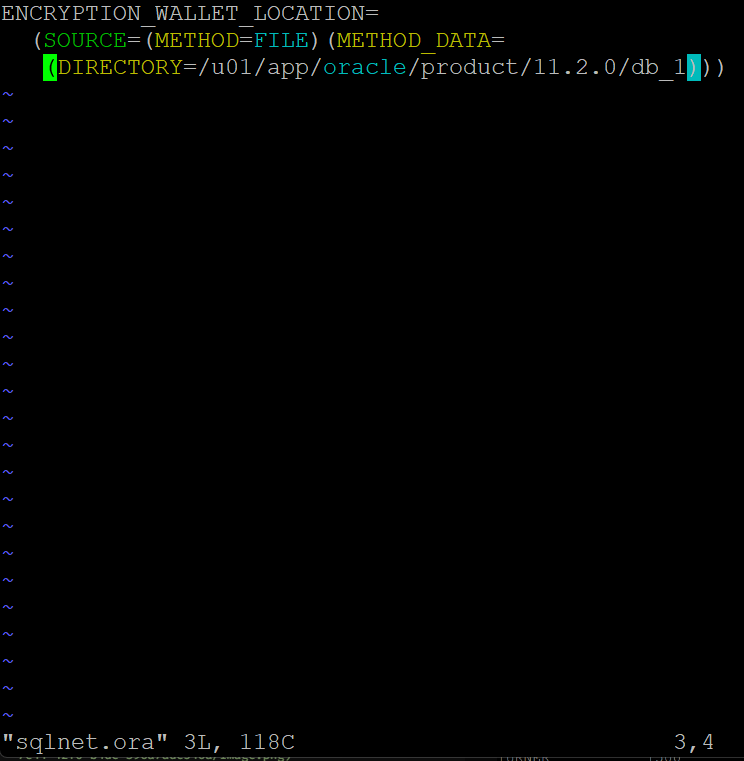

문제1. 전자 지갑을 닫으시오 2번 노드
SQL#2> connect / as sysdba
SQL#2> alter system set encryption wallet close
identified by oracle1234;
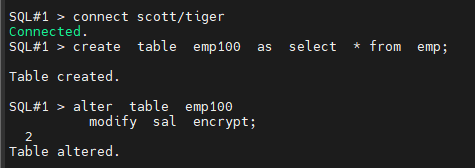
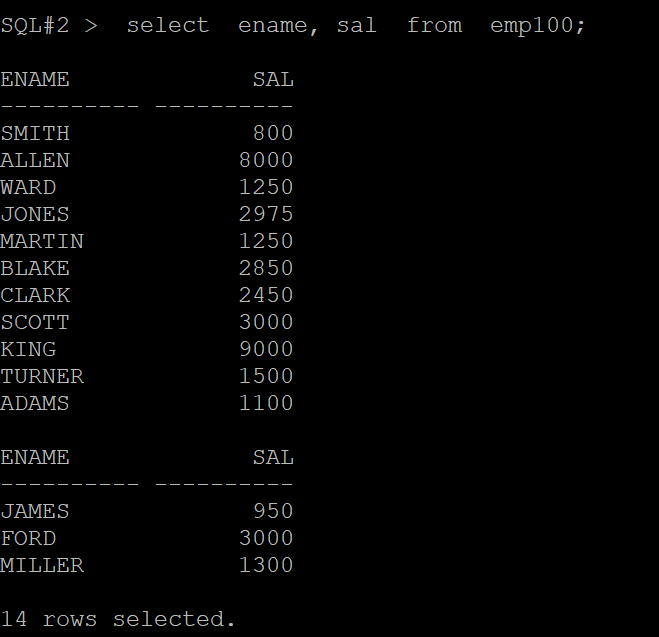
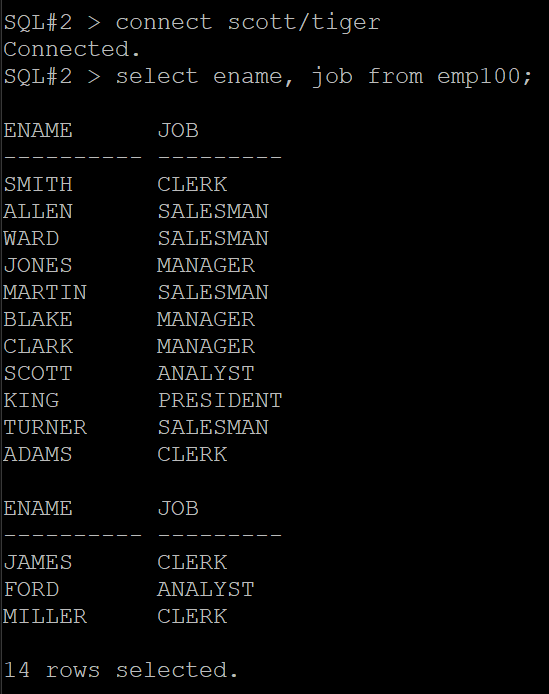
문제2. scott 유져로 접속해서 emp100 테이블에서 ename 과 job 을 조회하시오 @!
답
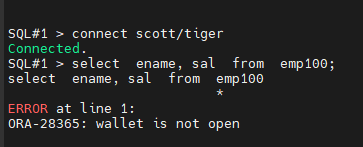
SQL#2> connect scott/tiger
SQL#2> select ename, job from emp100;
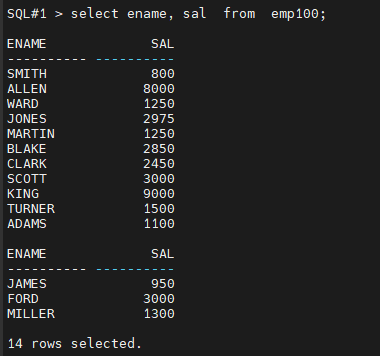
sal 을 암호화해서 조회가 안될 뿐 다른 컬럼들은 조회가 됩니다.
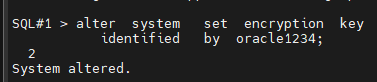
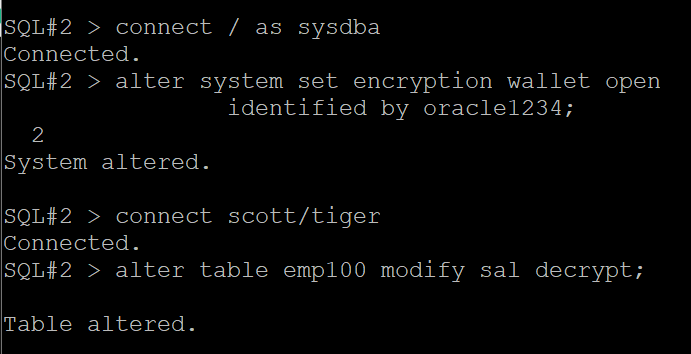
문제3. scott 유져에서 sal 월급을 decrypt 하시오 @
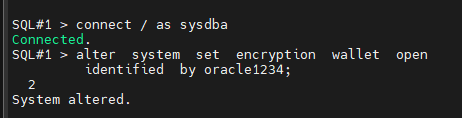
SQL#2> connect / as sysdba
SQL#2> alter system set encryption wallet open
identified by oracle1234;
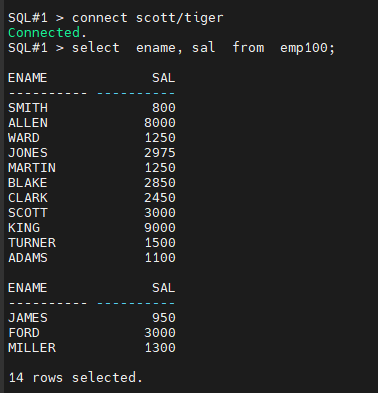
SQL#2> connect scott/tiger
SQL#2> alter table emp100 modify sal decrypt;
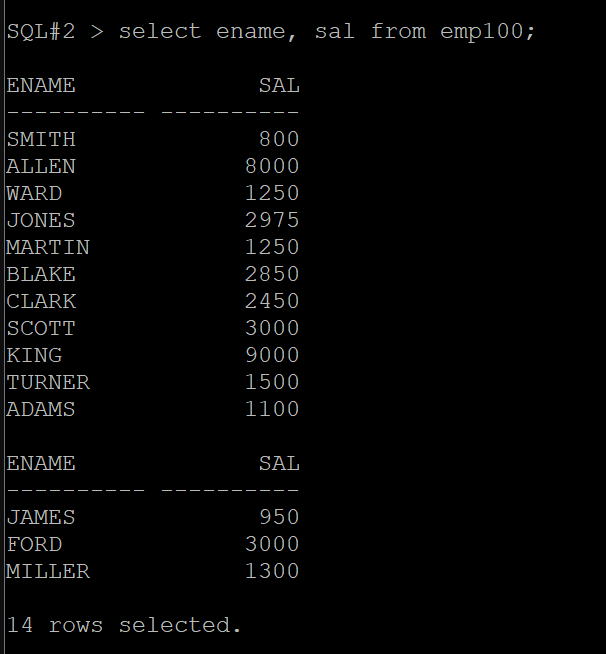
SQL#2> select ename, sal from emp100;
▣ 예제 24. RAC 환경에서 아카이브 로그 모드로 변경하는 방법
■ 실습. RAC 환경에서 노아카이브 모드 --- > 아카이브 모드 변경
#1. 현재 데이터베이스 모드가 무엇인지 확인합니다.
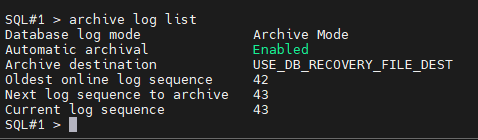
#2. 양쪽 인스턴스를 둘 다 shutdown immediate 로 내립니다.
#3. 한쪽 인스턴스만 mount 로 올립니다.
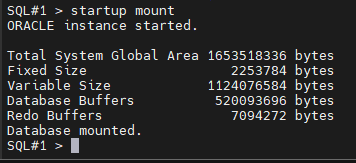
#4. 노아카이브모드로 변환

#5. 오픈상태로 올립니다
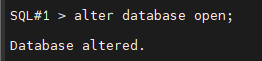
#6. 다른 인스턴스를 startup
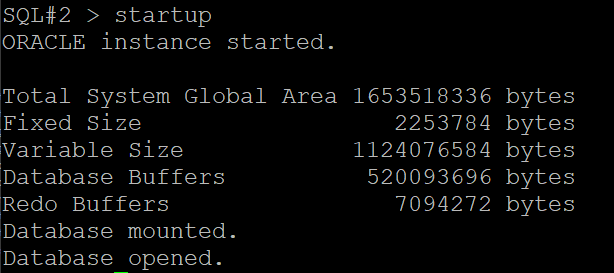
#7. 데이터베이스 모드를 확인
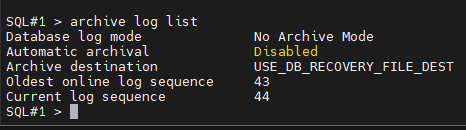
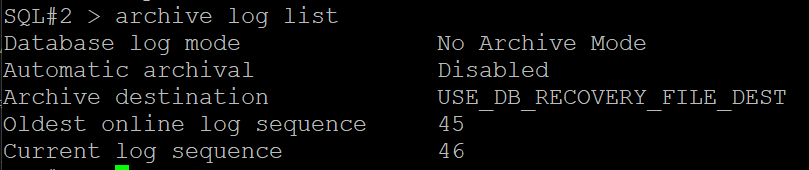
no archive 모드가 되었다 !
■ 실습. RAC 환경에서 노아카이브 모드 - > 아카이브 모드 변경
#1. 현재 데이터베이스 모드가 무엇인지 확인합니다.
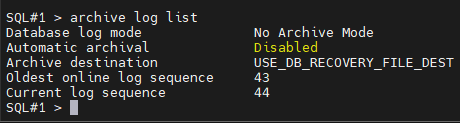
#2. 양쪽 인스턴스를 둘 다 shutdown immediate 로 내립니다.

#3. 한쪽 인스턴스만 mount 로 올립니다.
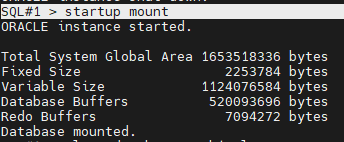
#4. 아카이브모드로 변환

#5. 오픈상태로 올립니다
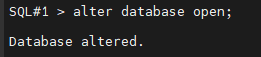
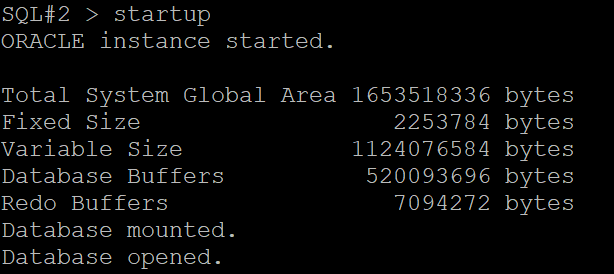
#6. 2번 노드 인스턴스를 startup
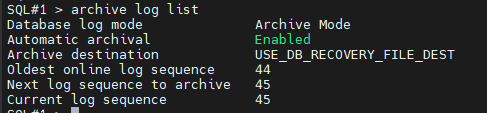
#7. 데이터베이스 모드를 확인
▣ 예제25. RAC 환경에서는 archive log file 이 어디에 생성이 되는가 ?
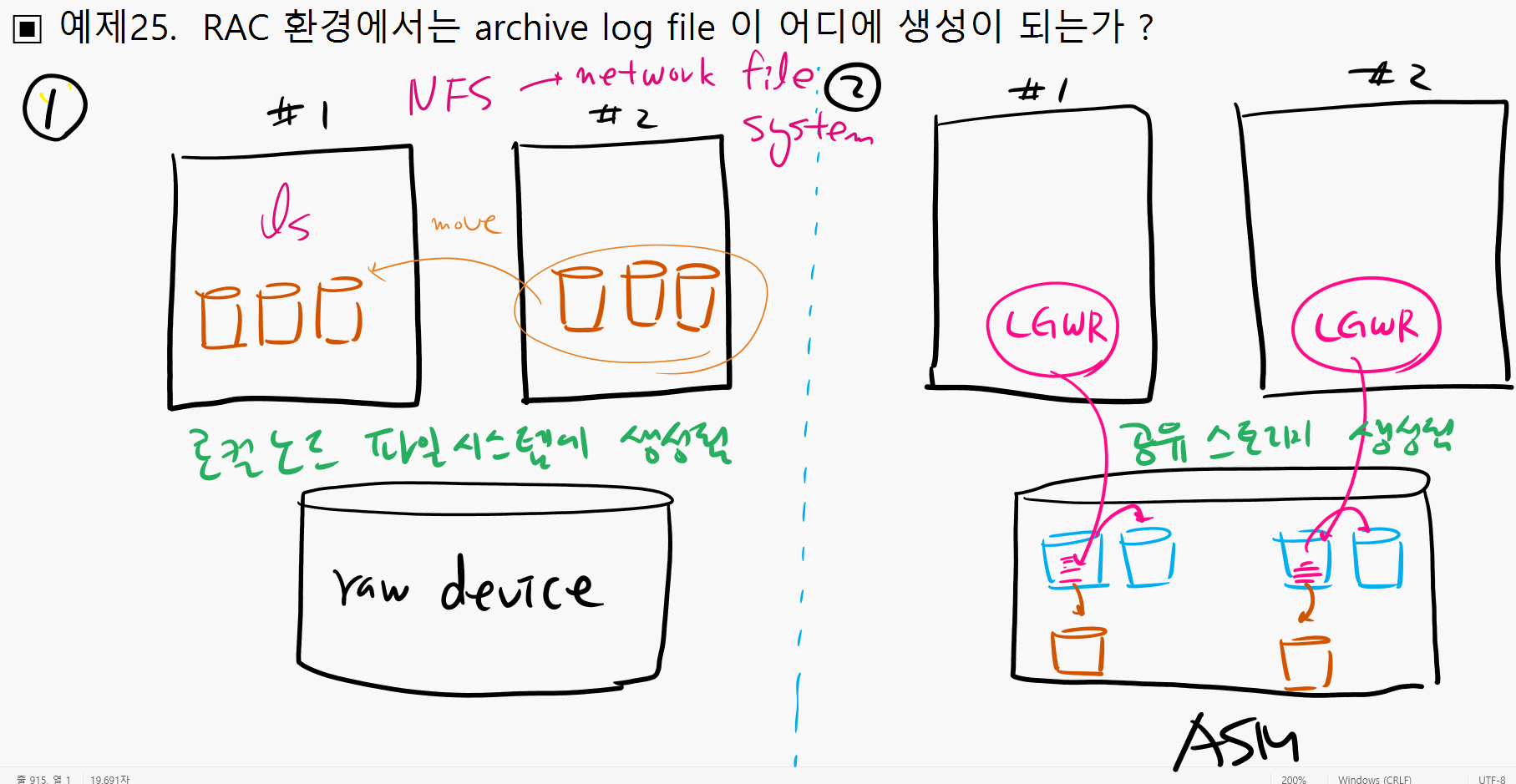
NFS : network file system
만약에 공유 스토리지가 raw device 면 아카이브 로그 파일은 로컬노드에 파일 시스템에 생성된다.
나중에 복구할 때 한쪽 노드로 아카이브 로그파일을 모아줘야 한다, 아니면 NFS 를 구축해야한다.
그런데 공유 스토리지가 ASM 이면 아카이브 로그 파일은 공유 스토리지 쪽에 생성이 됩니다. 그리고 나중에 복구할 때 한쪽 노드로 모을 필요없이 그냥 그대로 사용하면 됩니다.
■ 실습
#1. 1번 노드에서 아카이브 로그 파일이 생성되는 위치를 확인합니다.
select name from v$archived_log;
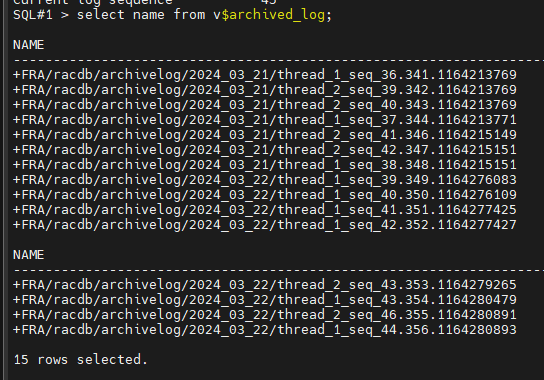
/thread1 : 1번 인스턴스용 아카이브 로그 파일
/thread2 : 2번 인스턴스용 아카이브 로그 파일
둘 다 FRA 디스크 그룹에 있다.
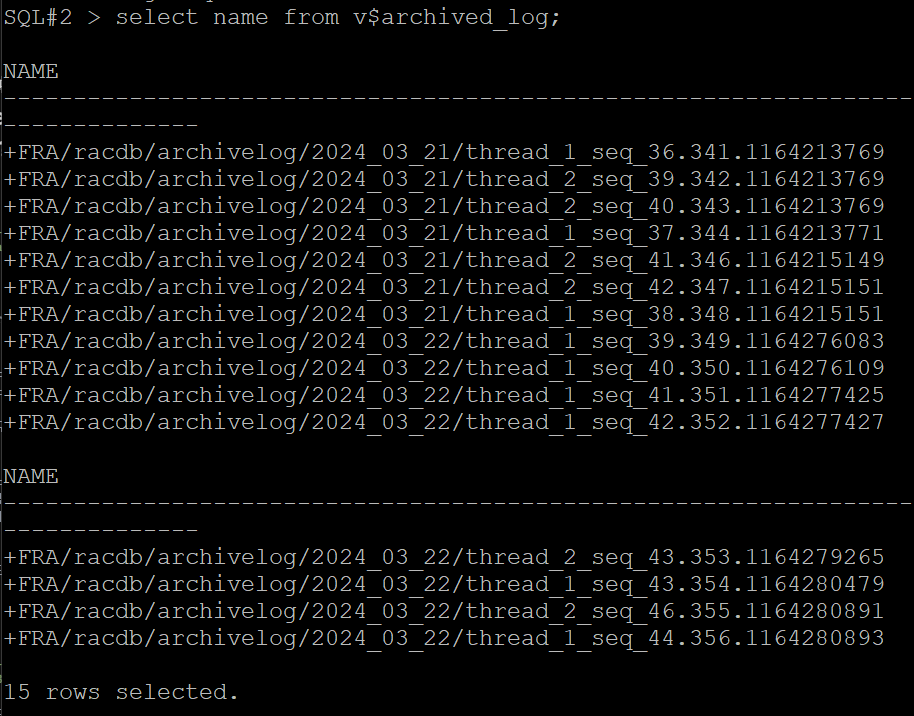
#2. 2번 노드에서 아카이브 로그 파일이 생성되는 위치를 확인합니다.
select name from v$archived_log;
#3. 1번노드에서 로그 스위치를 일으킵니다.
SQL#1> @logsw
#4. 아카이브 로그 파일이 생성되었는지 확인합니다.
SQL#1> select name from v$archived_log;
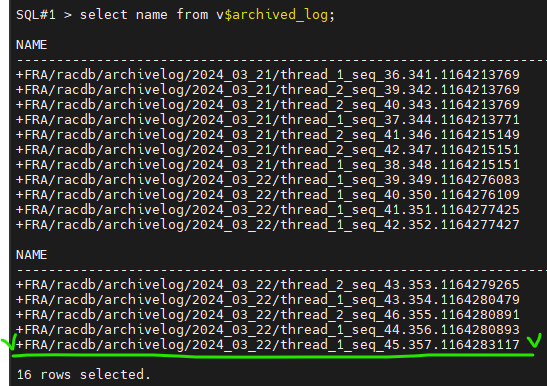
문제1. 아카이브 로그 파일이 생성되는 FRA 디스크 그룹의 여유 공간이 얼마나 있는지 확인
col "disk group" for a10
select
dg.name as "disk group",
dg.state as "state",
total_mb/1024 as "total gb",
(total_mb - free_mb)/1024 as "used gb",
free_mb/1024 as "free gb",
round((1- (free_mb / total_mb)) * 100, 2) as "used percent"
from v$asm_diskgroup dg
order by "used percent" desc;
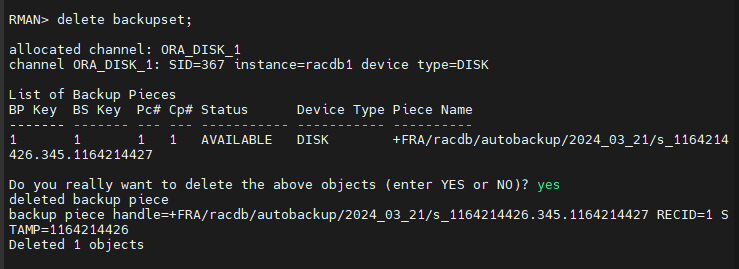
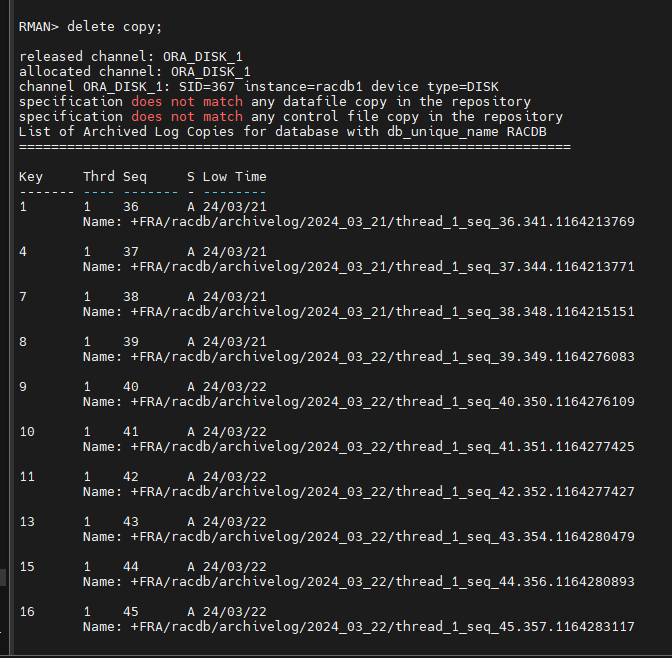
문제2. RMAN 으로 접속해서 기존 백업파일 지우기
▣ 예제26. RAC 환경에서 hot backup 하기
hot backup 이란 db 운영중에 백업하는 것을 말합니다.
양쪽 노드 둘다 내리지 않고 그냥 백업을 하는것입니다.
아카이브 모드여야지만 hot backup 이 가능합니다.
■ 실습
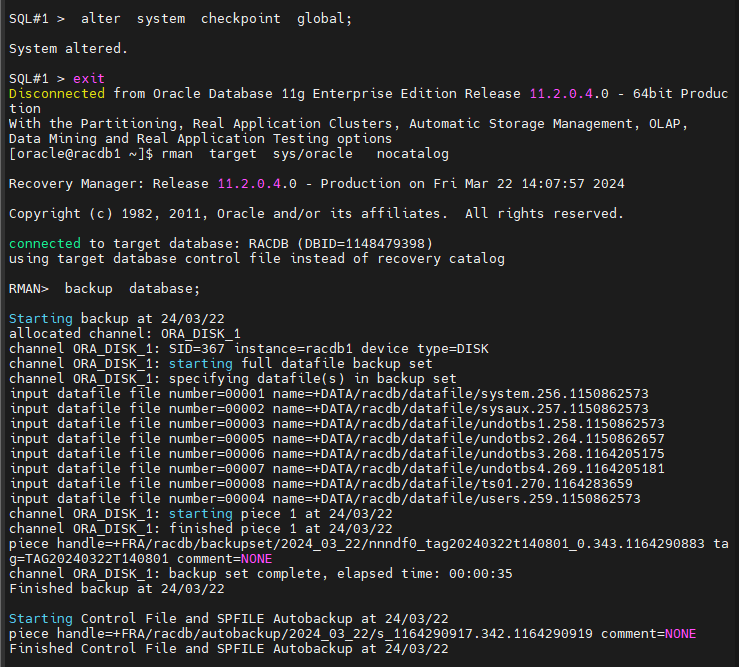
#1. checkpoint 를 global 하게 발생 시킵니다.
SQL#1> alter system checkpoint global;
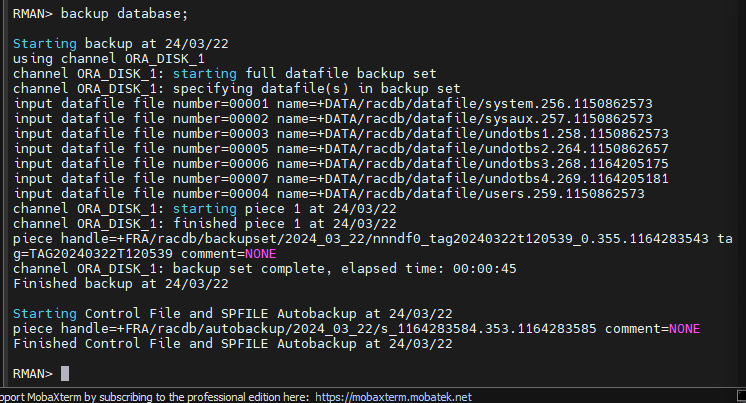
#2. RMAN 으로 hot backup 을 수행합니다.
$ rman target sys/oracle nocatalog
RMAN> backup database;
▣ 예제27. RAC 환경에서 cold backup 수행하기
RAC 환경에서 cold backup 은 모든 노드의 인스턴스를 다 내리고
하나의 인스턴스만 mount 로 올려서 백업하는것 입니다.
■ 실습
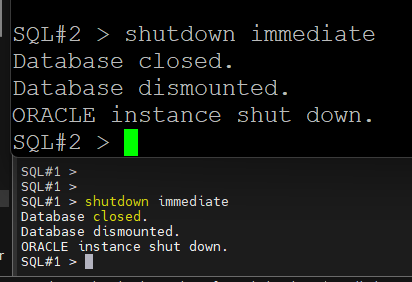
#1. 양쪽 노드를 둘다 shutdown immediate 를 합니다.
SQL#1> shutdown immediate
SQL#2> shutdown immediate
#2. 1번 인스턴스를 startup mount 를 합니다.
SQL#1> startup mount
#3. 1번 인스턴스에서 알맨으로 접속해서 전체 백업을 합니다.
$ rman target sys/oracle nocatalog
RMAN> backup database;
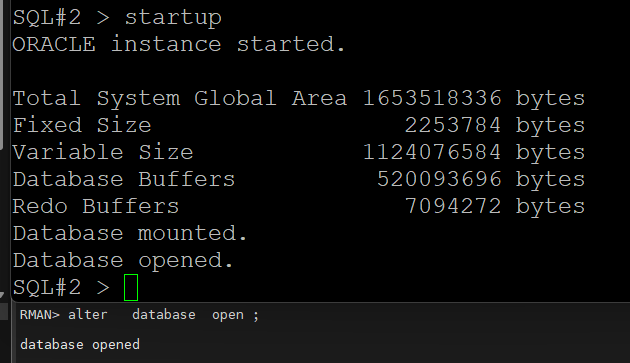
#4. 1번 인스턴스를 open 시킵니다.
RMAN> alter database open ;
#5. 2번 인스턴스를 startup 합니다.
SQL#2> startup
▣ 예제27. RAC 환경에서 data file 이 손상되었을 때 복구 방법
RAC 환경에서 복구는 한쪽노드에서만 진행해야 합니다.
다른 노드들은 전부 셧다운 되어져 있어야합니다.
■ 실습
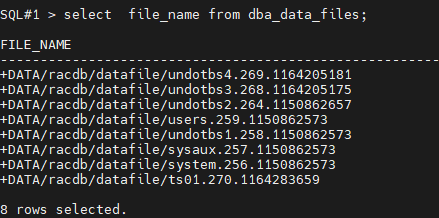
#1. 데이터 파일이 뭐가 있는지 조회합니다.
#2. 양쪽 인스턴스를 둘다 shutdown abort 합니다.
SQL#1> shutdown abort
SQL#2> shutdown abort
#3. asmcmd 로 접속해서 ts01 데이터 파일을 삭제합니다.
[oracle@racdb1 ~]$ ps -ef | grep pmon
[oracle@racdb1 ~]$ su - grid
암 호 : oracle
[grid@+ASM1 ~]$ . oraenv
ORACLE_SID = [+ASM1] ? +ASM1
[grid@+ASM1 ~]$ asmcmd
ASMCMD>
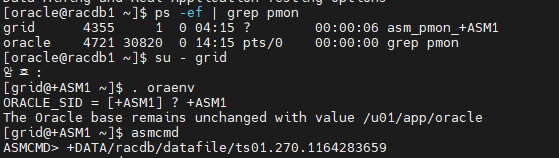
+DATA/racdb/datafile/ts01.270.1164283659 <-- 이 파일이 있는곳으로 이동합니다.
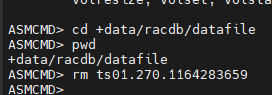
ASMCMD> pwd
+data/racdb/datafile
ASMCMD> rm TS01.270.1164283653
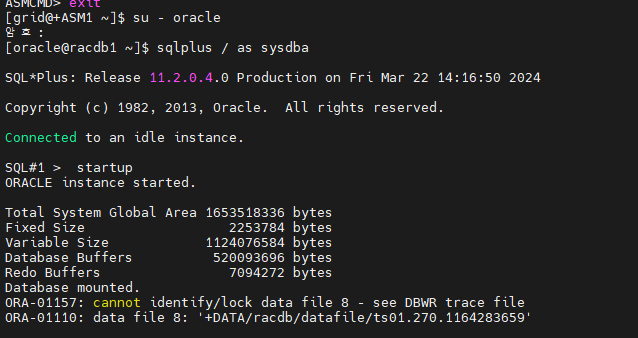
#4. 1번 인스턴스를 startup 합니다.
[grid@+ASM1 ~]$ su - oracle
암호:
[oracle@racdb1 ~]$ sqlplus / as sysdba
SQL#1> startup
ORA-01110: data file 8: '+DATA/racdb/datafile/ts01.270.1164283653'
.
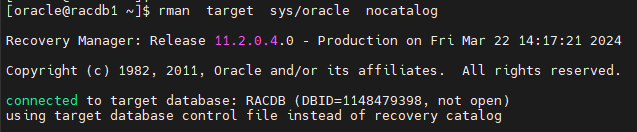
#5. RMAN 으로 접속합니다.
$ rman target sys/oracle nocatalog
#6. 손상된 데이터 파일을 복원합니다.
RMAN> restore datafile 8;
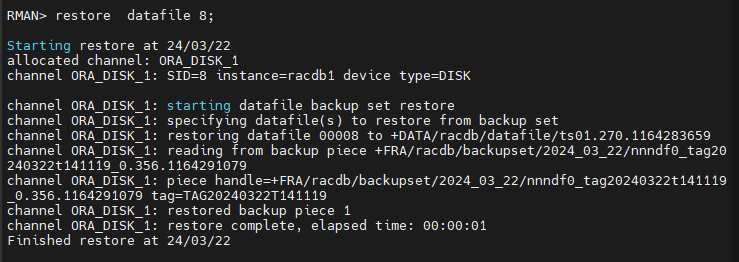
#7. 손상된 데이터 파일을 복구합니다.
RMAN> recover datafile 8;
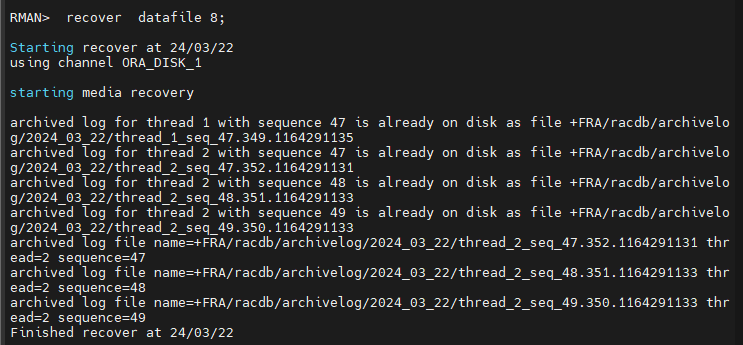
#8. 1번 인스턴스를 OPEN 으로 올립니다.
RMAN> alter database open;
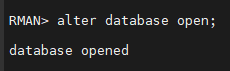
#9. 2번 인스턴스를 startup 합니다.
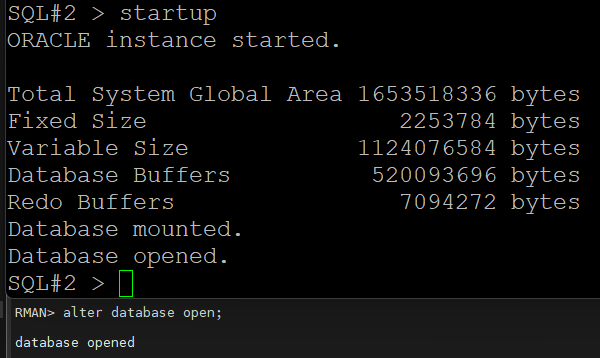
문제 1. 위의 실습을 다시 수행하는데 이번에는 data file 을 2개 깨트리고 복구 하시오
SQL#1> select file_name from dba_data_files;
FILE_NAME
--------------------------------------------------------------------------------
+DATA/racdb/datafile/undotbs4.269.1164205181
+DATA/racdb/datafile/undotbs3.268.1164205175
+DATA/racdb/datafile/undotbs2.264.1150862657
+DATA/racdb/datafile/users.259.1150862573
+DATA/racdb/datafile/undotbs1.258.1150862573
+DATA/racdb/datafile/sysaux.257.1150862573
+DATA/racdb/datafile/system.256.1150862573
+DATA/racdb/datafile/ts01.270.1164291457select * from v$recover_file; <--- 복구해야할 파일 리스트 조회
#2. 양쪽 인스턴스를 둘다 shutdown abort 합니다.
SQL#1> shutdown abort
SQL#2> shutdown abort
#3. asmcmd 로 접속해서 ts01 데이터 파일을 삭제합니다.
[oracle@racdb1 ~]$ ps -ef | grep pmon
[oracle@racdb1 ~]$ su - grid
암 호 : oracle
[grid@+ASM1 ~]$ . oraenv
ORACLE_SID = [+ASM1] ? +ASM1
[grid@+ASM1 ~]$ asmcmd
ASMCMD>
+DATA/racdb/datafile/ts01.270.1164283659 <-- 이 파일이 있는곳으로 이동합니다.
ASMCMD> pwd
+data/racdb/datafile
ASMCMD> rm TS01.270.1164291457
ASMCMD> rm UNDOTBS2.264.1150862657
#4. 1번 인스턴스를 startup 합니다.
[grid@+ASM1 ~]$ su - oracle
암호:
[oracle@racdb1 ~]$ sqlplus / as sysdba
SQL#1> startup
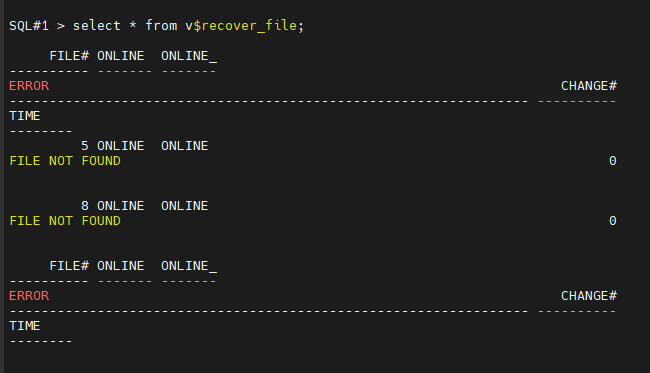
#5. RMAN 으로 접속합니다.
$ rman target sys/oracle nocatalog
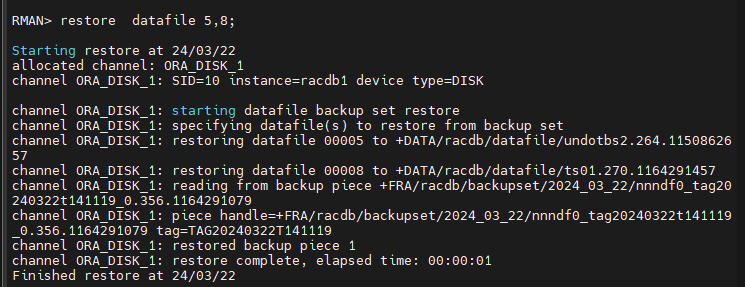
#6. 손상된 데이터 파일을 복원합니다.
RMAN> restore datafile 5,8;
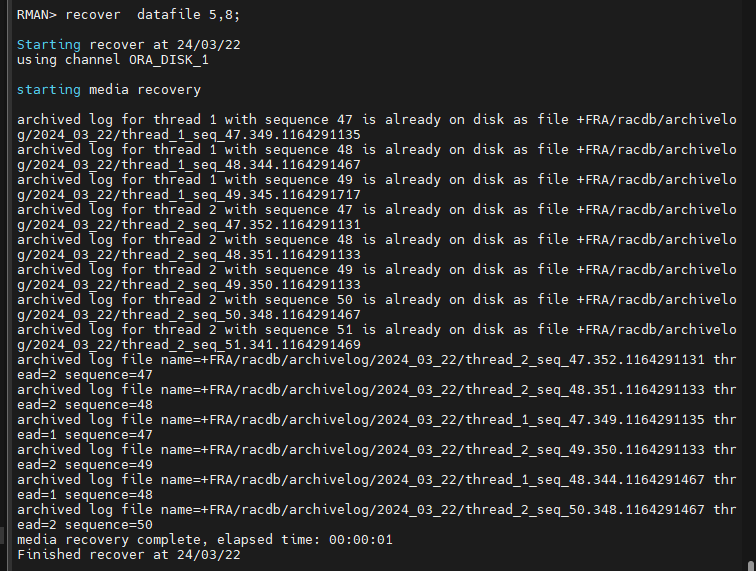
#7. 손상된 데이터 파일을 복구합니다.
RMAN> recover datafile 5,8;
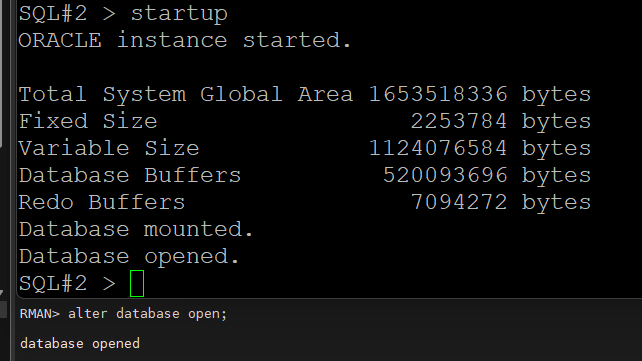
#8. 1번 인스턴스를 OPEN 으로 올립니다.
RMAN> alter database open;
#9. 2번 인스턴스를 startup 합니다.
SQL#2> startup
▣ 예제28. RAC 환경에서 control file 이 깨졌을 때 복구 방법
일단 수행하기 전에 백업을 걸고 시작
- control file 을 생성하는 스크립트를 생성합니다.
SQL#1 > alter database backup controlfile to trace as '/home/oracle/cre_con2.sql';

- RMAN 에서 backup database include current controlfile;
$ rman~
RMAN > configure controlfile autobackup on;
RMAN > backup database;
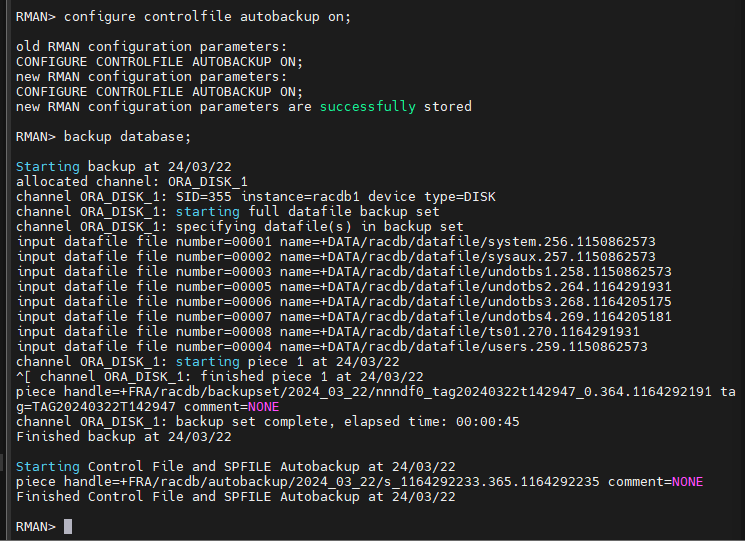
RAC 환경에서 controlfile 을 복구하려면 반드시 cluster_database 파라미터를 false 로
해놓고 모든 인스턴스를 내리고 한쪽 인스턴스에 접속해서 복구를 해야합니다.
■ 실습
#1. control file 을 생성하는 스크립트를 생성합니다.
SQL#1 > alter database backup controlfile to trace as '/home/oracle/cre_con3.sql';
vi cre_con3.sql
:set nu
:37, 113 w c3.sql
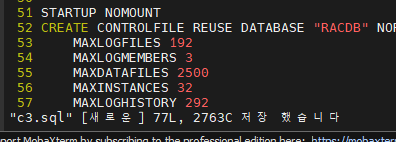
vi c3.sql
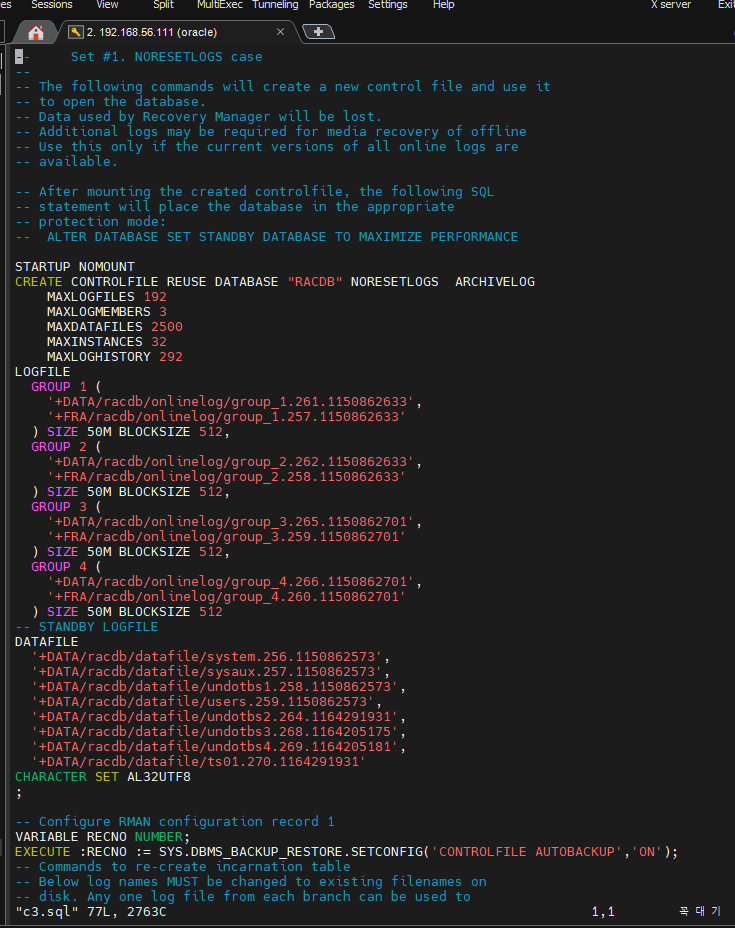
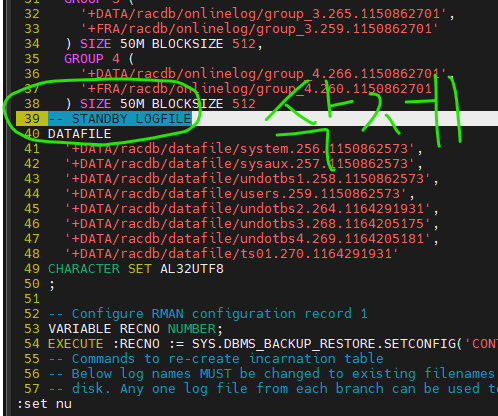
#2. 편집
#3. db id 가 어떻게 되는지 확인합니다.
select dbid from v$database;
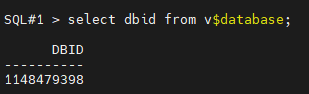
SQL#1 > select dbid from v$database;
DBID
----------
1148479398
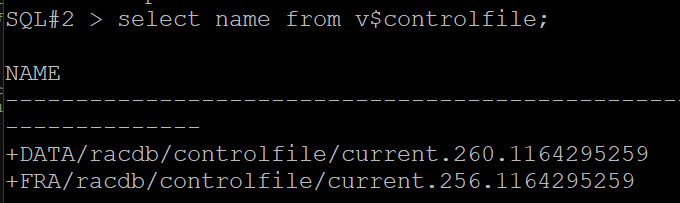
#4. controlfile 의 위치를 확인합니다.
select name from v$controlfile;
NAME
--------------------------------------------------------------------------------
+DATA/racdb/controlfile/current.260.1150862631
+FRA/racdb/controlfile/current.256.1150862631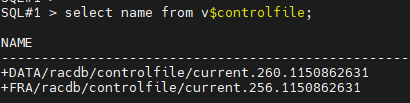
#4. 양쪽 인스턴스를 모두 shutdown immediate 를 합니다.
SQL#1> shutdown immediate
SQL#2> shutdown immediate
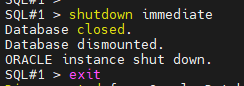
#5. grid 유져로 접속해서 asmcmd 로 접속합니다.
[oracle@racdb1 ~]$ su - grid
암 호 : oracle
[grid@+ASM1 ~]$ . oraenv
ORACLE_SID = [+ASM1] ? +ASM1
[grid@+ASM1 ~]$ asmcmd
ASMCMD>
#6. controlfile 이 있는 곳으로 가서 controlfile 을 모두 삭제 합니다.
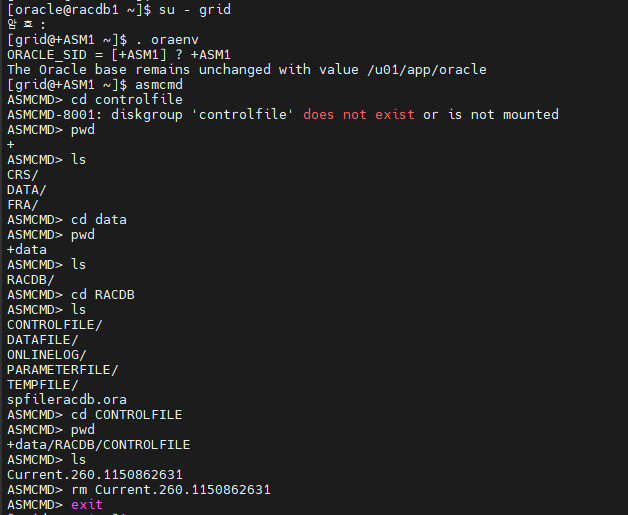
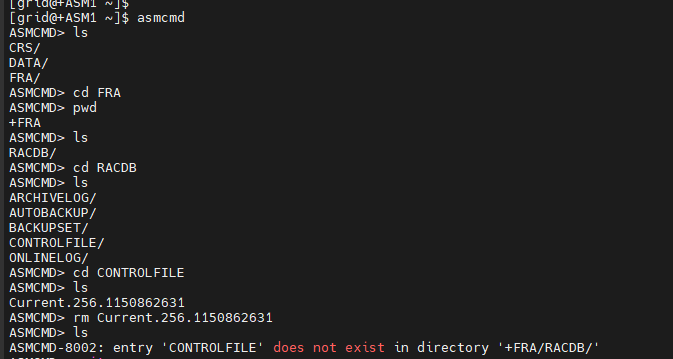
#7. 다시 oracle 유져로 접속해서 startup 을 합니다.
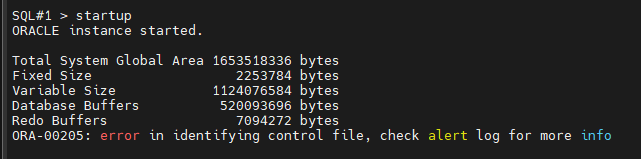
#8. 다시 oracle 유져로 접속해서 startup 을 합니다.
#9. cluster_database 를 false 로 지정합니다.
SQL#1> show parameter cluster_database

SQL#1> alter system set cluster_database=false scope=spfile sid='*';

#10. 접속한 인스턴스를 shutdown abort 를 내립니다.
shutdown abort
#11. sys 유져로 접속해서 controlfile 생성하는 스크립트를 수행합니다.
SQL#1> @c3.sql
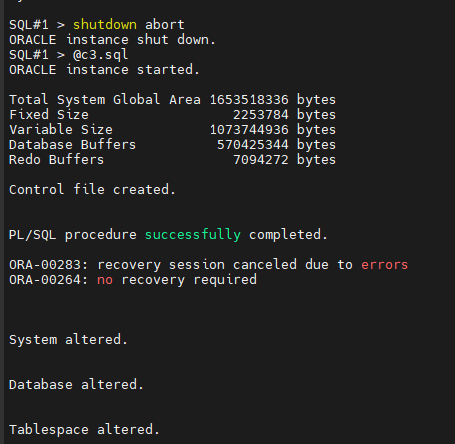
#12. cluster_database 를 true 로 변경합니다.
SQL#1> alter system set cluster_database=true scope=spfile sid='*';

#13. 접속한 인스턴스를 shutdown immediate 합니다.
SQL#1> shutdown immediate
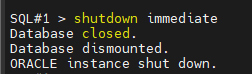
#14. 양쪽 인스턴스를 startup 합니다.
SQL#1> startup
SQL#2> startup
▣ 예제29. RAC 환경에서 inactive 상태의 redo log file 이 손상되었을 때 복구 방법 !
inactive 상태의 redo log file : 깨져도 디비가 내려가지는 않음.
리두 로그 파일의 상태 4가지 ?
- current : 현재 LGWR 가 쓰고 있는 상태 ------> 불완전 복구
- active : 다 썼는데 checkpoint 가 완료 안된 상태 ---> 불완전 복구
- inactive : 다 썼고 checkpoint 도 완료된 상태 ---> 완전 복구
- unused : 한번도 사용한적이 없는 상태 ---> 완전 복구
■ 실습
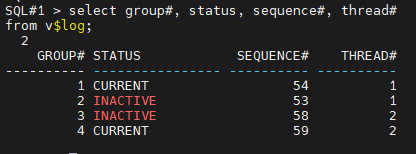
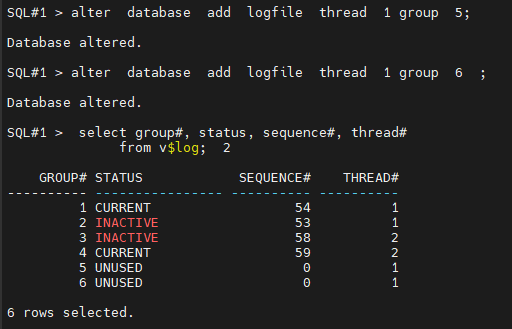
#1. 1번 인스턴스용 리두 로그 그룹을 4개로 만듭니다.
select group#, status, sequence#, thread#
from v$log;
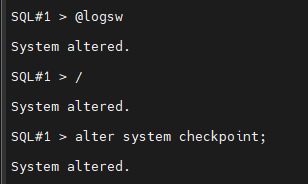
#2. 1번 인스턴스에서 로그 스위치를 2번 일으키고 체크포인트를 일으킵니다.
@logsw
@logsw
alter system checkpoint;
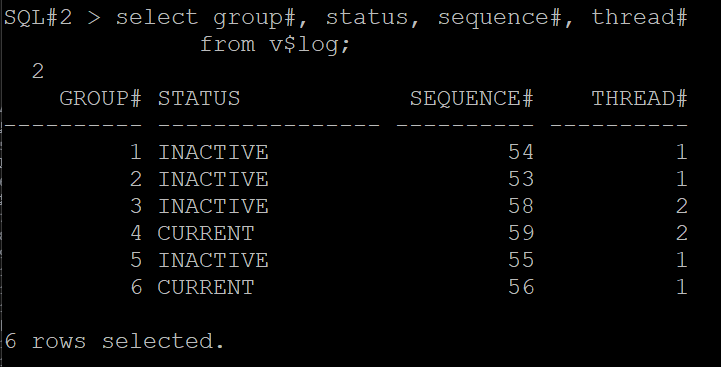
#3. 2번 인스턴스용 리두 로그 그룹을 4개로 만듭니다.
SQL#2> select group#, status, sequence#, thread#
from v$log;
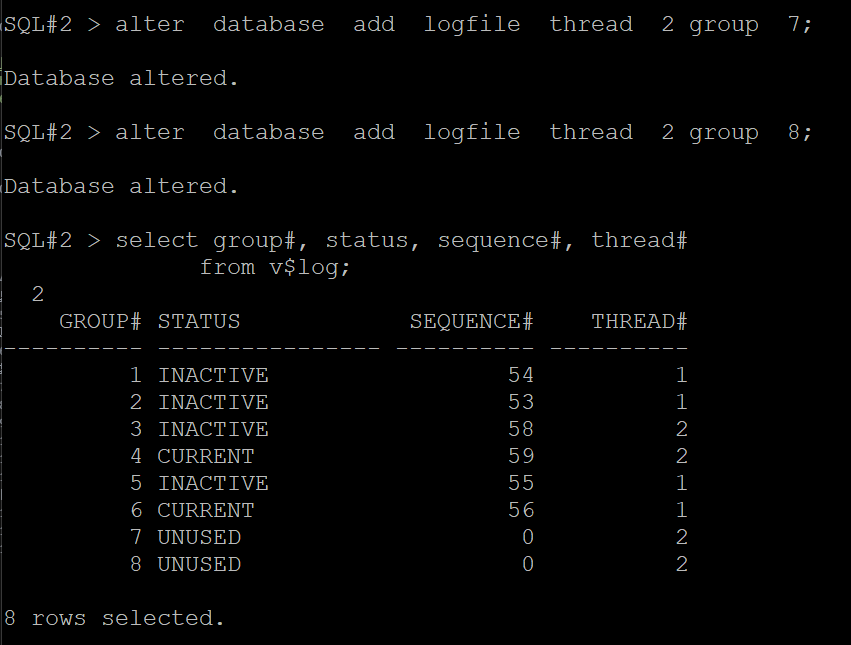
SQL#2> alter database add logfile thread 2 group 7;
SQL#2> alter database add logfile thread 2 group 8;
SQL#2> select group#, status, sequence#, thread#
from v$log;
#4. 2번 인스턴스에서 로그 스위치를 2번 일으키고 체크포인트를 일으킵니다.
@logsw
@logsw
alter system checkpoint;
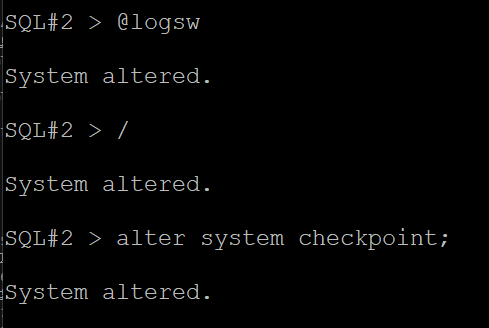
#5. 1번 인스턴스용 리두 로그 그룹중에 inactive 상태의 리두 로그 그룹번호를 알아냅니다.
SQL#1> select group#, status, sequence#, thread#
from v$log;
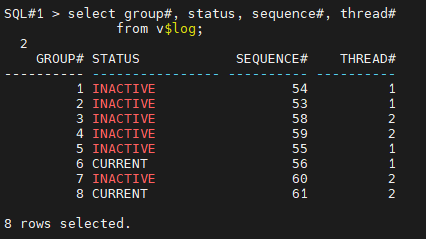
1번이 inactive 임을 확인.
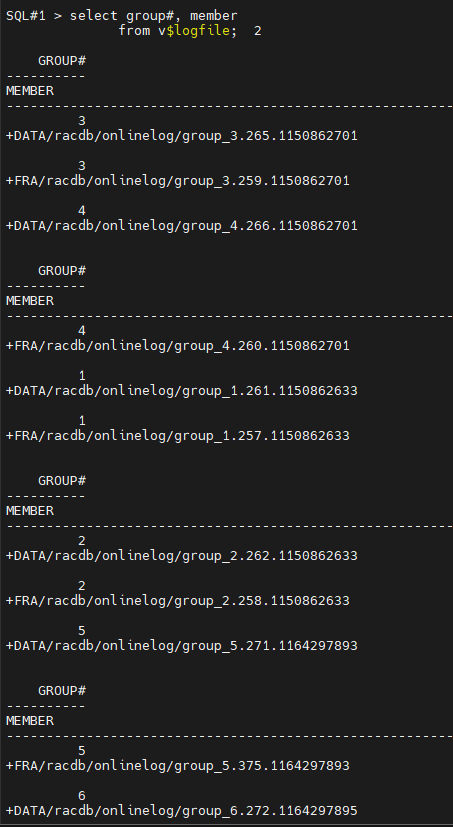
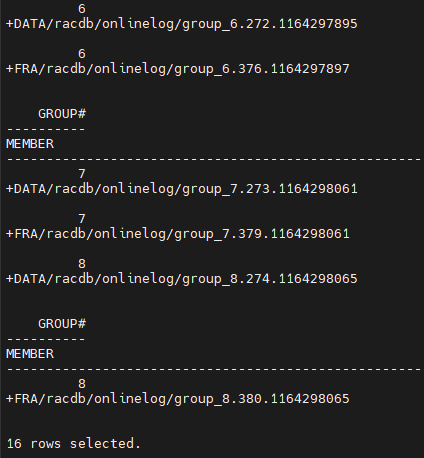
#6. 5번에서 확인한 inactive 상태의 리두 로그 파일의 멤버를 알아냅니다.
SQL#1> select group#, member
from v$logfile;
#7. 양쪽 인스턴스를 shutdown abort 를 내립니다.
SQL#1> shutdown abort
SQL#2> shutdown abort
#8. grid 유져로 접속해서 asmcmd 모드로 접속합니다.

#9. inactive 상태의 리두 로그 그룹의 멤버를 모두 삭제합니다.
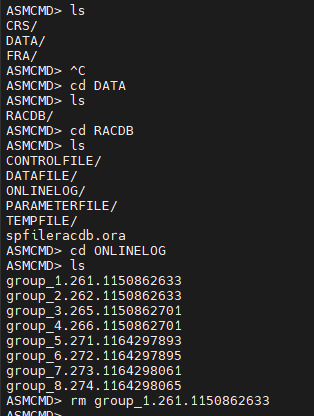
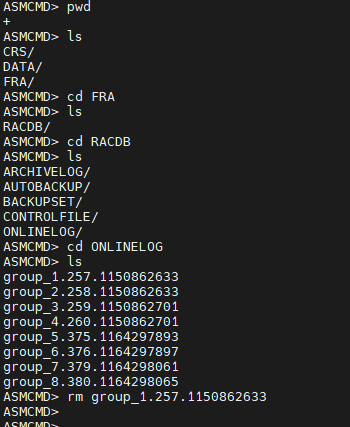
#10. oracle 유져로 로그인해서 startup 을 합니다.
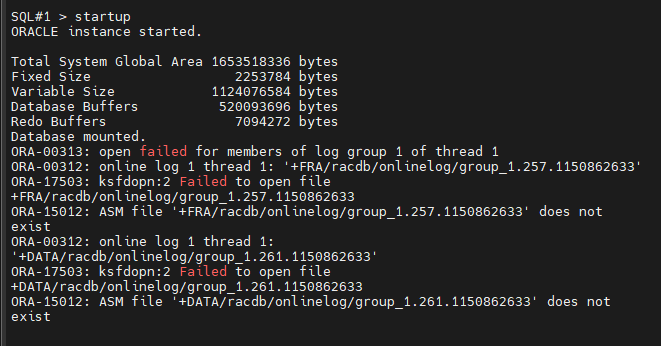
#11. 손상된 리두 로그 그룹의 상태를 확인합니다.
SQL#1> select group#, status, sequence#, thread#
from v$log;
#12. 손상된 그룹이 inactive 상태이면 그 그룹번호를 controlfile 에서 지워버립니다.
SQL#1> alter database drop logfile group 1;
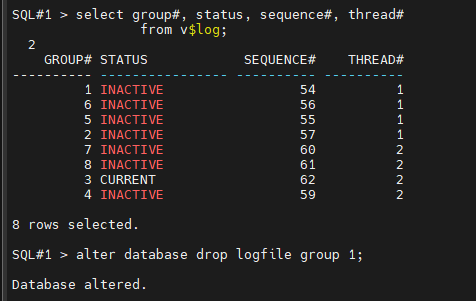
#13. db 를 open 시킵니다.
SQL#1> alter database open;
#14. 새롭게 리두 로그그룹을 추가합니다.
SQL#1> alter database add logfile group 1;

alter database clear unarchived logfile group 1;
을 했다면 추가할 필요 없음.
#15. 2번 인스턴스를 startup 합니다.
SQL#2> startup
오늘의 마지막 문제
RAC 이수자 평가 2번 문제
리두 로그 그룹의 상태를 다음과 같이 1번 3개, 2번 3개로 구성해 놓으시오 !
그리고 화면 캡쳐 해서
SQL#1> select group#, status, sequence#, thread#
from v$log;
로그스위치, 체크포인트 해볼 것.
아침에 한거 복습할 것.
쓰레드를 드랍하면 되네
5번 삭제하고 8번 삭제하고
드랍하기 전에 inactive 여야 함 !!!
alter database drop logfile group 5;
alter database drop logfile group 8;
SQL#1 > alter database drop logfile thread 1 group 5;
alter system checkpoint;

