▣ 예제30. RAC 환경에서 time base 불완전 복구 하기
면접 질문 : 완전 복구와 불완전 복구의 차이가 무엇인지 대답해주실 수 있나요 ?
답변 : 완전 복구는 장애가 나기 직전에 마지막으로 commit 된 시점으로 db 를 복구하는 것
불완전 복구는 과거의 특정 시간으로 db 를 복구하는 것을 말합니다.
사람의 실수나 application 의 잘못으로 데이터가 지워지는 일이 발생하면 복구를 해야 합니다.
면접 질문 : 테이블의 데이터가 지워지고 commit 되었다면 복구하는 방법이 무엇이 있습니까 ?
답변 : 1. flashback table 기술로 과거의 특정 시간으로 복구하는 기술
2. time base 불완전 복구로 복구하는 기술
3. export 받은 dump 나 pump 로 복구하는 기술
■ 실습
#0. fullbackup 을 받는다.
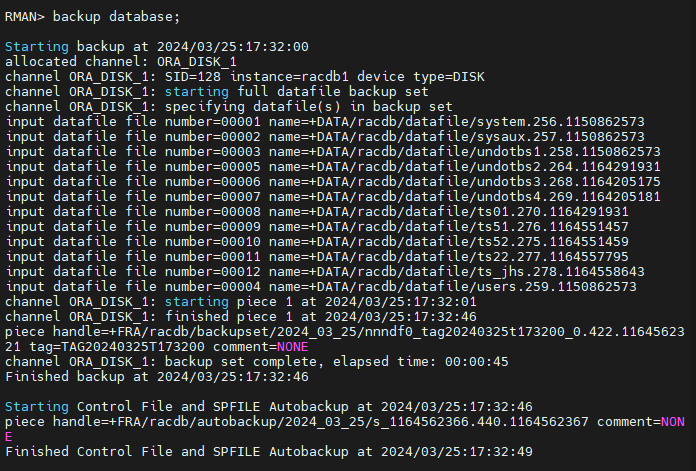
#1. .bash_profile 에 시간을 설정하는 파라미터를 추가해야합니다.
NLS_LANG=american_america.we8iso8859p15
NLS_DATE_FORMAT='RRRR/MM/DD:HH24:MI:SS'
export NLS_LANG
export NLS_DATE_FORMAT
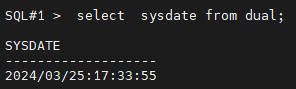
#2. 현재 시간을 확인합니다.
SQL#1> select sysdate from dual;
#3. 로그 스위치를 2번 정도 일으킵니다.
SQL#1> alter system switch logfile;
SQL#1> alter system switch logfile;
#4. scott 유져를 drop 합니다.
SQL#1> drop user scott cascade;
#5. 양쪽 인스턴스를 모두 shutdown immediate 로 내립니다.
SQL#1> shutdown immediate
SQL#2> shutdown immediate
#6. 한쪽 인스턴스만 mount 로 올립니다.
SQL#1> startup mount
#7. rman 으로 접속해서 time base 불완전 복구를 시도합니다.
#8. scott 유져로 접속이 잘 되는지 확인합니다.
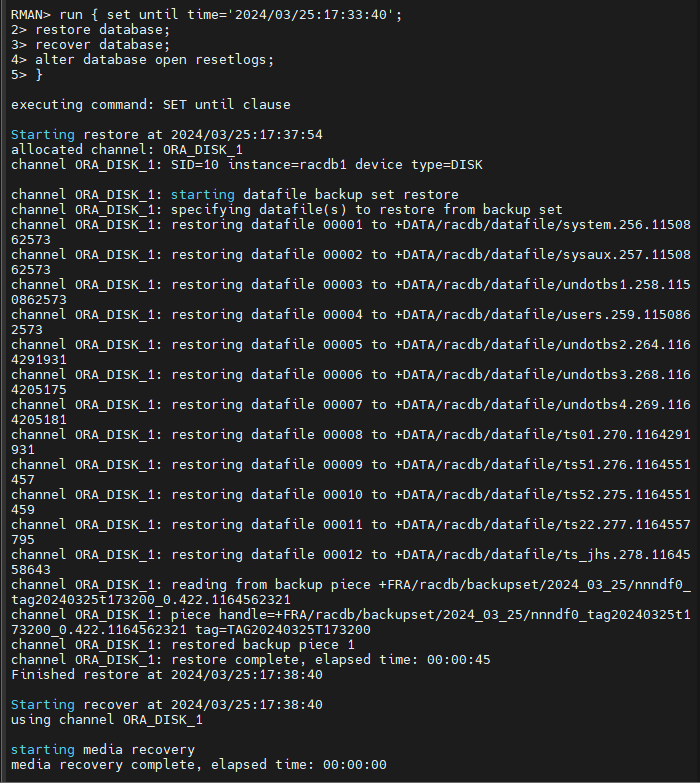
RMAN > run { set until time='2024/03/25:17:33:40';
restore database;
recover database;
alter database open resetlogs;
}
#9. full backup 을 수행합니다.
RMAN > backup database;
RMAN > report obsolete;
RMAN > delete obsolete;
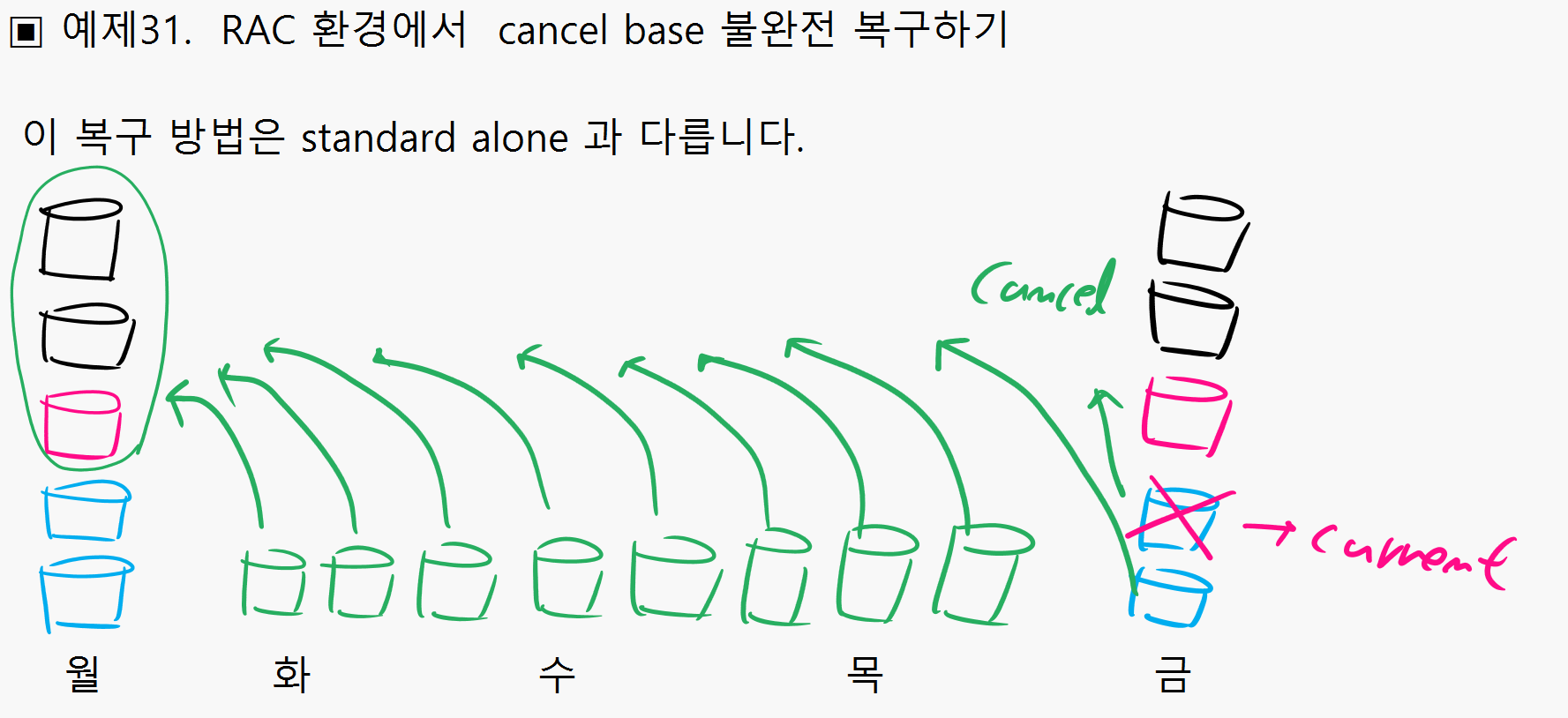
▣ 예제31. RAC 환경에서 cancel base 불완전 복구하기
■ 실습
#1. RMAN 으로 full backup 을 먼저 수행합니다.
#2. 로그 스위치를 2번 일으킵니다.
#3. 체크 포인트를 일으킵니다.
#4. current 리두 로그 그룹이 뭔지 확인합니다.
#5. 1번 인스턴스용 리두 로그 그룹을 하나 추가합니다.
#6. 2번 인스턴스용 리두 로그 그룹을 하나 추가합니다.
#7. 각각의 노드에서 로그 스위치를 2번 일으킵니다.
#8. 체크 포인트를 수행합니다.
#9. 리두 로그 그룹의 상태를 확인합니다.
#10. controlfile 을 생성하는 스크립트를 생성합니다.
#11. 1번 인스턴스의 current redo log 그룹이 뭔지 확인합니다.
#12. current redo log group 의 멤버가 뭔지 확인합니다.
#13. 양쪽 인스턴스를 shutdown immediate 로 내립니다.
#14. amscmd 로 접속해서 current 리두 로그 그룹의 멤버를 모두 삭제합니다.
#15. 1번 인스턴스를 startup 합니다.
#16. rman 으로 접속합니다.
#17. cancel base 불완전 복구를 시도합니다.
#18. 다른 인스턴스를 startup 시킵니다.
#19. 기존 rman 을 빠져나왔다가 다시 접속해서 full backup 을 수행합니다.
구현:
#1. RMAN 으로 full backup 을 먼저 수행합니다.
#2. 로그 스위치를 2번 일으킵니다.
SQL#1> alter system switch logfile;
SQL#1> alter system switch logfile;
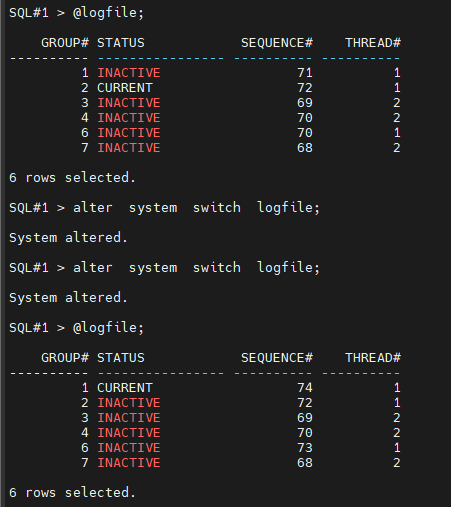
#3. 체크 포인트를 일으킵니다.
SQL#1> alter system checkpoint;
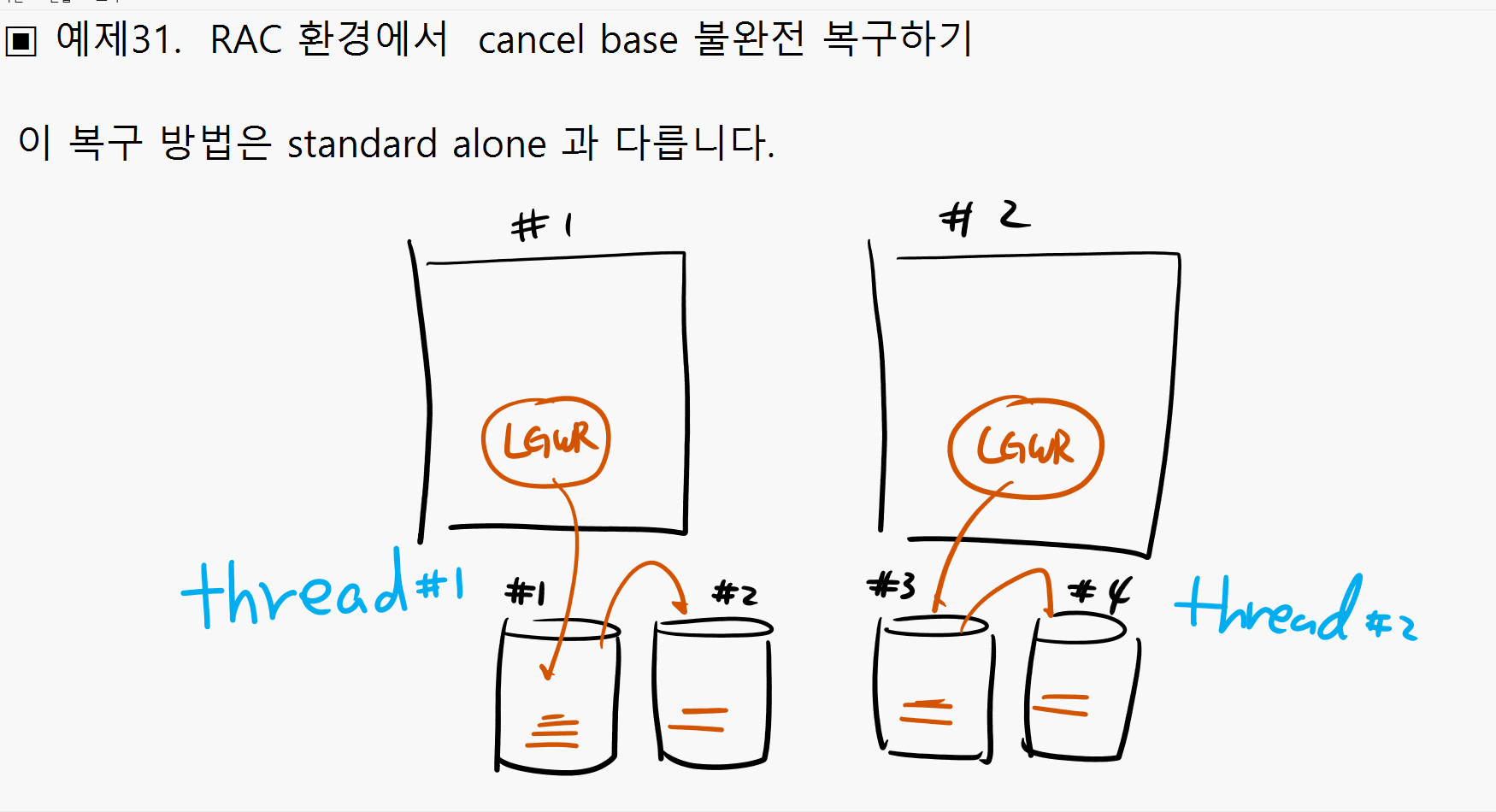
#4. current 리두 로그 그룹이 뭔지 확인합니다.
SQL#1> select group#, sequence#, status, thread#
from v$log;
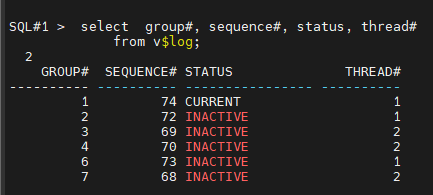
※ thread# 이 무엇인가? 어느 인스턴스의 리두 로그 그룹인지를 나타내기 위한 숫자
#5. 1번 인스턴스용 리두 로그 그룹을 하나 추가합니다.
SQL#1> alter database add logfile thread 1 group 8;

#6. 2번 인스턴스용 리두 로그 그룹을 하나 추가합니다.
SQL#2> alter database add logfile thread 2 group 9;

#7. 각각의 노드에서 로그 스위치를 2번 일으킵니다.
SQL#1> alter system switch logfile;
SQL#1> alter system switch logfile;
SQL#2> alter system switch logfile;
SQL#2> alter system switch logfile;
#8. 두 노드에서 각각 체크 포인트를 수행합니다.
SQL#1> alter system checkpoint;
SQL#2> alter system checkpoint;
#9. 리두 로그 그룹의 상태를 확인합니다.
SQL#1> select group#, status, sequence#, thread#
from v$log;
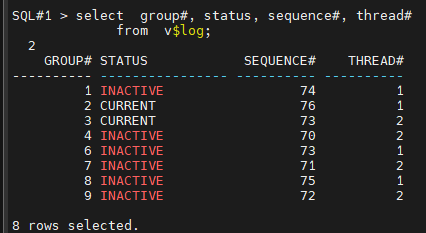
#10. controlfile 을 생성하는 스크립트를 생성합니다.
SQL#1> alter database backup controfile to trace as '/home/oracle/c9.sql';

#11. 1번 인스턴스의 current redo log 그룹이 뭔지 확인합니다.
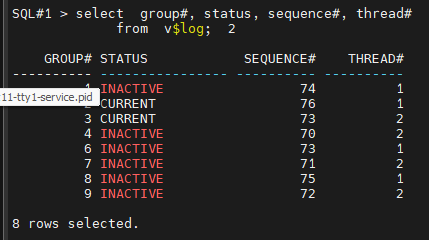
SQL#1> select group#, status, sequence#, thread#
from v$log;
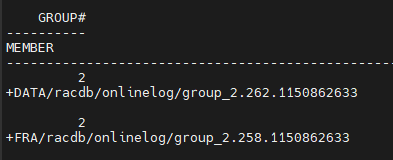
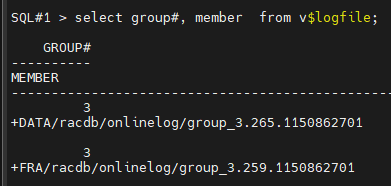
#12. current redo log group 의 멤버가 뭔지 확인합니다.
SQL#1> select group#, member from v$logfile;
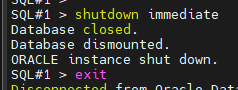
#13. 양쪽 인스턴스를 shutdown immediate 로 내립니다.
SQL#1> shutdown immediate
SQL#2> shutdown immediate
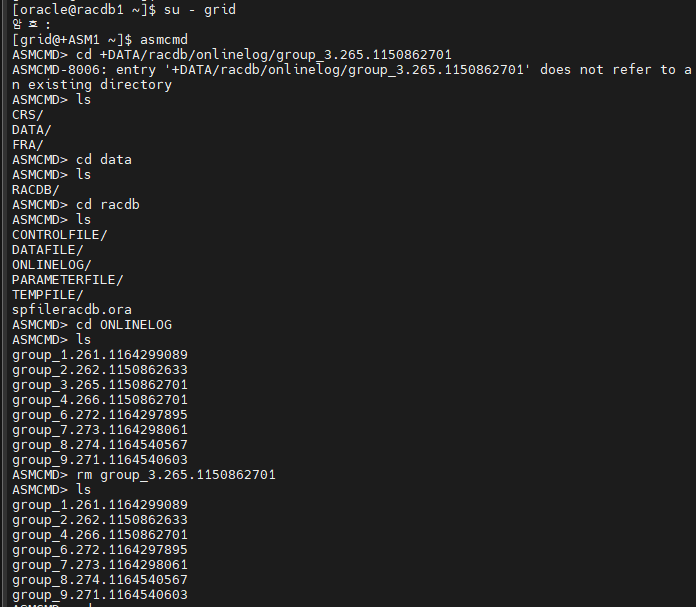
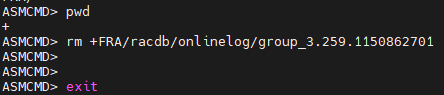
#14. amscmd 로 접속해서 current 리두 로그 그룹의 멤버를 모두 삭제합니다.
$ su - grid
$ asmcmd
ASMCMD >
아래의 위치로 가서 둘다 rm 으로 지웁니다.
+DATA/racdb/onlinelog/group_3.265.1150862701
+FRA/racdb/onlinelog/group_3.259.1150862701
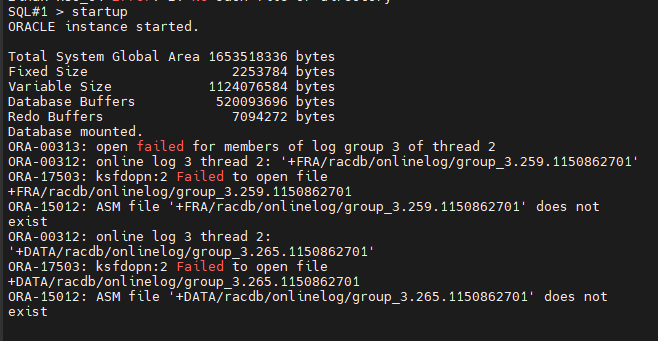
#15. 1번 인스턴스를 startup 합니다.
SQL#1> startup
#16. rman 으로 접속합니다.
RMAN > list incarnation;
현재 incarnation 번호를 확인해야 합니다
불완전 복구를 여러번 했기 때문에 예전에 불완전 복구 하기 전 db 인지 아니면 현재 db 인지 구분해주기 위한 번호가 incarnation 번호 입니다.
status 가 current 인 것의 incarnation 번호
RMAN> list incarnation;
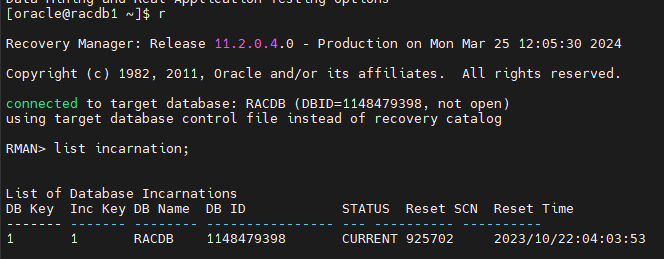
RMAN > reset database to incarnation 1;

#17. cancel base 불완전 복구를 시도합니다.
RMAN> run { set until sequence 71 thread 1;
restore database;
recover database;
}
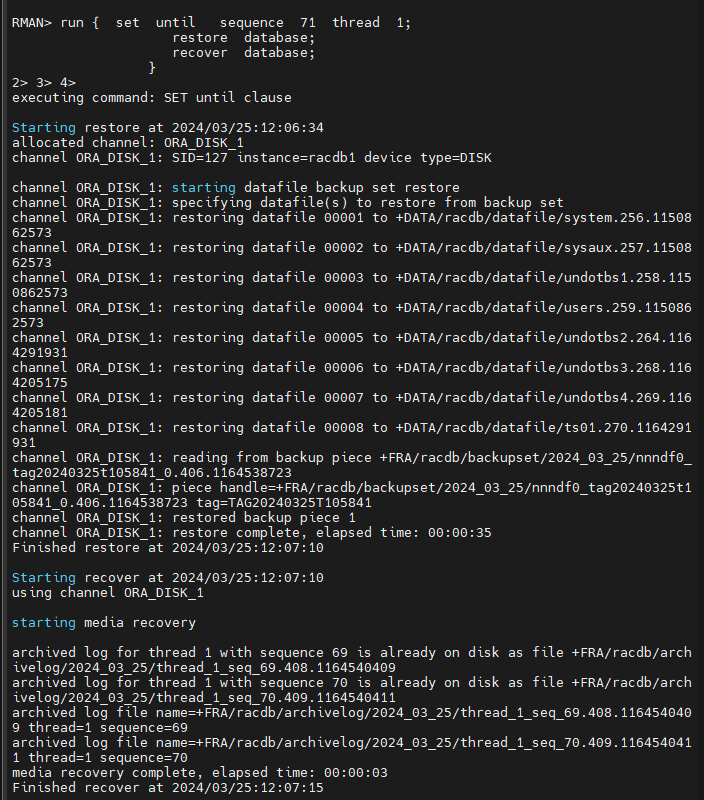
RMAN> alter database open resetlogs;

#18. 다른 인스턴스를 startup 시킵니다.
SQL#2> startup
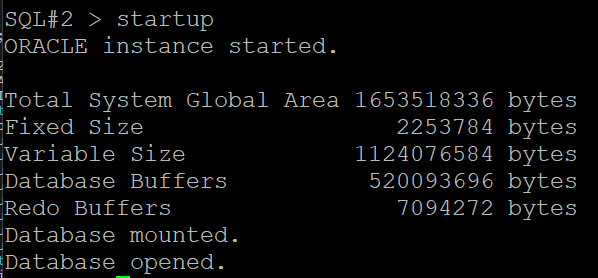
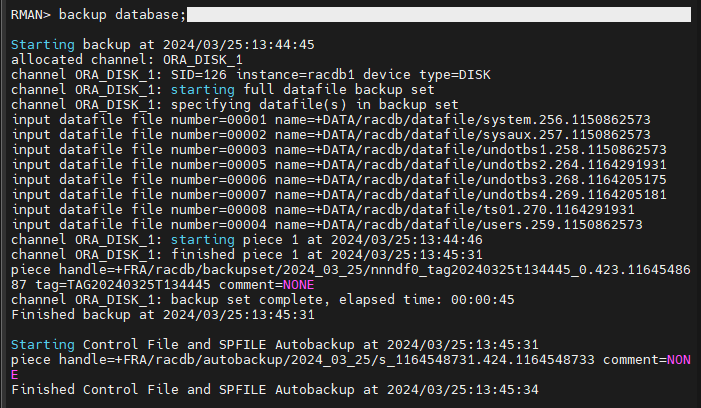
#19. 기존 rman 을 빠져나왔다가 다시 접속해서 full backup 을 수행합니다.
RMAN> backup database;
▣ 예제32. RAC 환경에서 백업본이 없는 datafile 이 깨졌을 때 복구 방법
아카이브 모드이기만 하면 백업본이 없어도 복구를 할 수 있습니다.
#1. ts51 테이블 스페이스를 생성합니다.
SQL#1> create tablespace ts51 datafile '+data' size 10m;
SQL#1> select tablespace_name, file_name from dba_data_files;
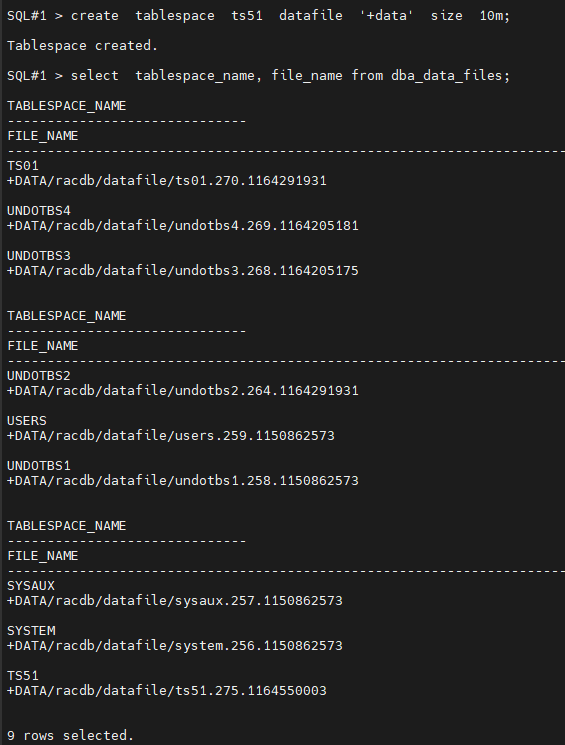
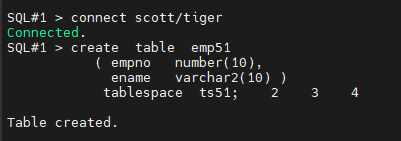
#2. ts51 테이블 스페이스에 emp51 테이블을 scott 유져에서 생성합니다.
SQL#1> connect scott/tiger
SQL#> create table emp51
( empno number(10),
ename varchar2(10) )
tablespace ts51;
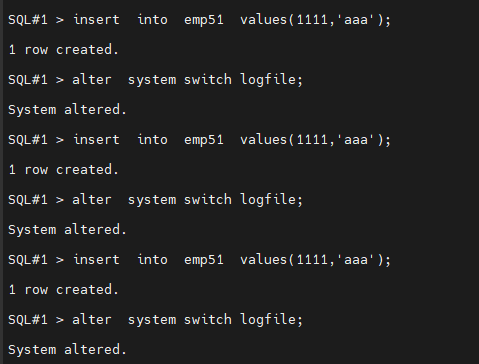
#3. 데이터를 emp51 테이블에 입력하고 로그 스위치를 일으킵니다.(3번반복)
SQL#1> insert into emp51 values(1111,'aaa');
SQL#1> alter system switch logfile;
SQL#1> insert into emp51 values(1111,'aaa');
SQL#1> alter system switch logfile;
SQL#1> insert into emp51 values(1111,'aaa');
SQL#1> alter system switch logfile;
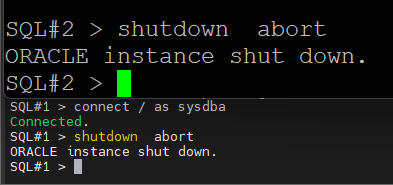
#4. 양쪽 노드를 둘다 shutdown abort
#5. asmcmd 로 가서 ts51 테이블 스페이스의 datafile 을 rm 으로 삭제
$ su - grid
$ asmcmd
ASMCMD>
+DATA/racdb/datafile/ts51.274.1164549315
#6. 한쪽 노드만 startup
$ su - oracle
SQL#1> startup
#7. 복구해야할 파일이 뭔지 조회를 합니다.
SQL#1> select *
from v$recover_file;
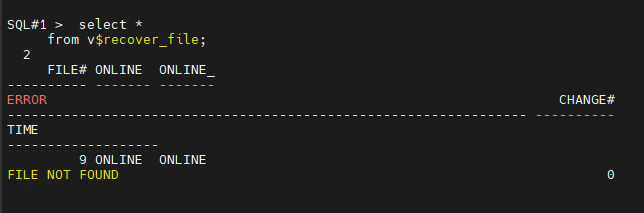
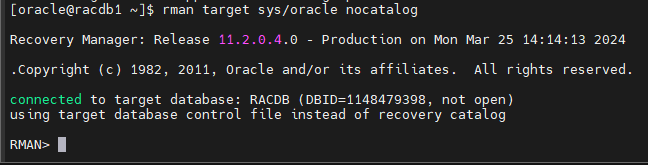
#8. 알맨으로 접속합니다.
rman target sys/oracle nocatalog
#9. 문제가 되는 datafile 을 복원합니다.
RMAN> restore datafile 9;
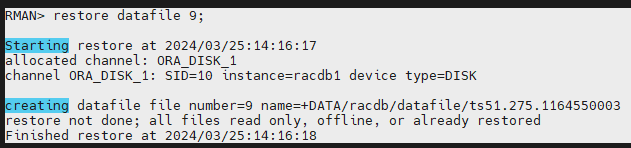
creating datafile file number=9 name=+DATA/racdb/datafile/TS51.275.1164550003 --> 실제로 백업본이 없기때문에 빈 파일을 생성을 합니다.
#10. 문제가 되는 datafile 을 복구 합니다.
RMAN> recover datafile 9;
RMAN> alter database open;
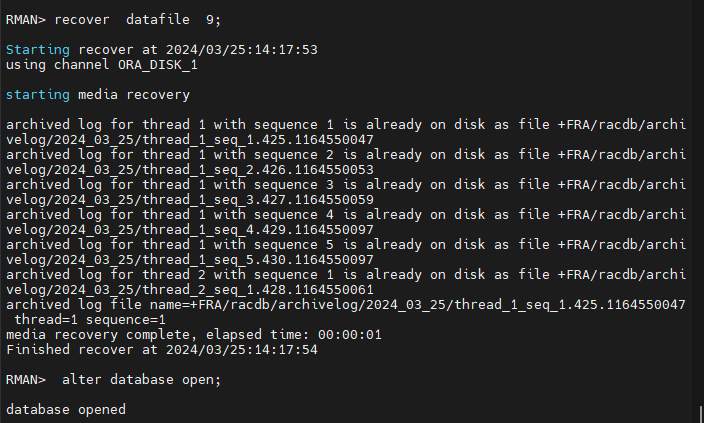
#11. emp51 테이블이 잘 조회되는지 확인합니다.
$ sqlplus scott/tiger
SQL#1> select * from emp51;
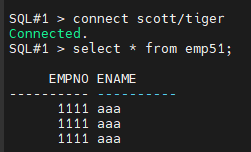
#12. 나머지 인스턴스를 startup 시킵니다.
▣ 예제33. RAC 환경에서 flashback database 로 불완전 복구하기
면접질문: flashback 과 복구의 차이가 무엇입니까 ?
답변: 복구는 과거에 백업받았던 파일을 복원해와서 복구하는것이고
flashback 은 그동안 작업했던 작업을 받대로 수행해서 과거로
되돌리는것입니다.
복구를 하던 flashback 을 하던 RAC 환경에서 작업할 때는
cluster_database 파라미터를 false 로 해놓고 작업하기를 권장합니다.
복구할때 다른 노드가 올라와 버리면 복구가 실패하기 때문입니다.
면접질문: RAC 환경에서 복구할 때 특별히 주의사항이 무엇입니까?
답변: cluster_database 파라미터를 false 로 해놓고 한쪽 인스턴스만 올려서
복구를 하는게 주의사항입니다.
■ 실습
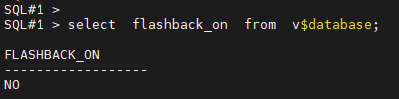
#1. flashback database 기능이 활성화 되어져있는지 확인합니다.
SQL#1 > select flashback_on from v$database;
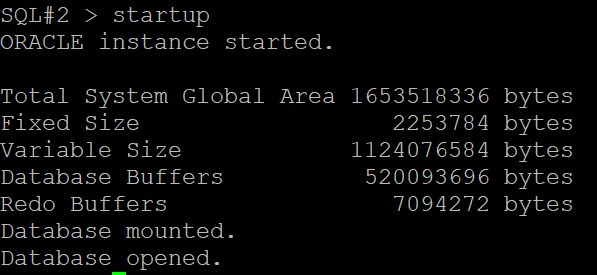
#2. 모든 인스턴스를 shutdown immediate 를 하고 한쪽 인스턴스만 mount 로 올립니다.
SQL#1 > shutdown immediate
SQL#2 > shutdown immediate
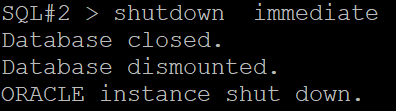
SQL#1 > startup mount
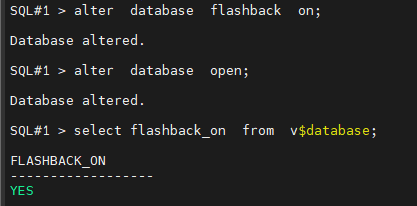
#3. flashback database 기능을 활성화 시킵니다.
SQL#1 > alter database flashback on;
#4. db 를 open 시키고 flashback database 기능이 활성화 되었는지 확인합니다.
SQL#1 > alter database open;
SQL#1 > select flashback_on from v$database;
2번 인스턴스를 올린다.
SQL#2 > startup
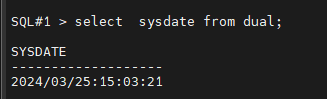
#5. 현재 시간을 확인합니다.
SQL#1 > select sysdate from dual;
2024/03/25:15:03:21
#6. 현재 scn 번호를 확인합니다.( system change number의 약자)
SQL#1 > select current_scn from v$database;
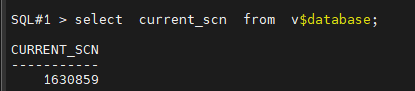
CURRENT_SCN 1630859#7. scott 유져를 drop 합니다.
SQL#1 > drop user scott cascade;

#8. (복구) cluster_database 를 false 로 변경합니다.
SQL#1 > alter system set cluster_database=false scope=spfile sid='*';

#9. (복구) shutdown immediate 로 양쪽 인스턴스를 모두 를 내립니다.
SQL#1 > shutdown immediate
SQL#2 > shutdown immediate
#10. (복구) 한쪽 인스턴스만 startup mount 를 합니다.
SQL#1 > startup mount
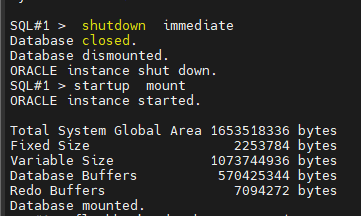
#11. (복구) scott 유져 drop 되기 전으로 flashback database 를 수행합니다.
SQL#1 > flashback database to timestamp
to_timestamp('2024/03/25:15:03:00','RRRR/MM/DD:HH24:MI:SS');
또는
SQL#1 > flashback database to scn 1630859;

#12. (복구) resetlogs 로 db를 올립니다.
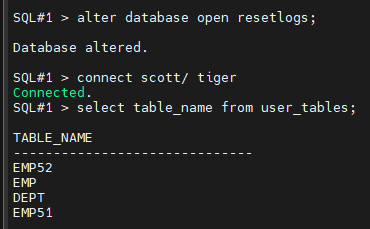
SQL#1 > alter database open resetlogs;
SQL#1 > connect scott/ tiger
select count(*) from emp;
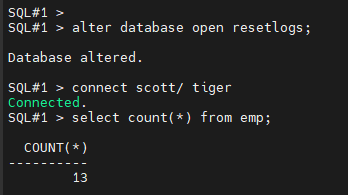
#13. (복구) cluster_database 를 true 로 변경
SQL#1 > alter system set cluster_database=true scope=spfile sid='*';

#14. (복구) 양쪽 인스턴스를 내렸다 올립니다.
SQL#1 > shutdown immediate
SQL#1 > startup
SQL#2 > startup

#15. rman 으로 전체 full backup 을 수행합니다.
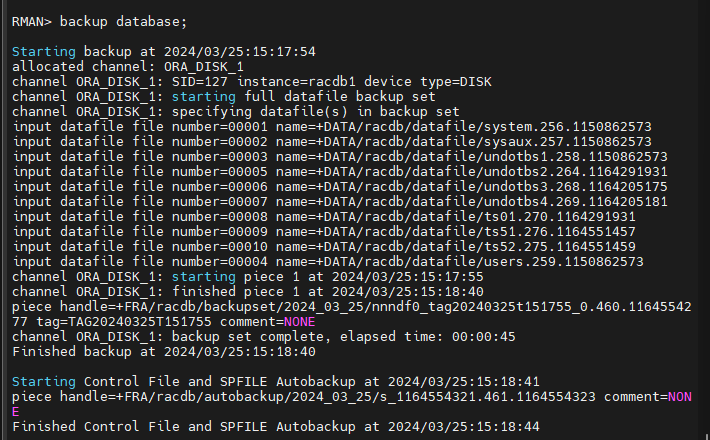
문제1. 다음과 같이 scott 유져로 접속해서 scott 유져가 가지고 있는 모든 테이블들을
전부 drop 하고 drop 되지 전으로 flashbackup database 하시오 !@
SQL#1 > @logsw
SQL#1 > alter system checkpoint;
SQL#1 > select sysdate from dual;
SYSDATE
-------------------
2024/03/25:15:21:24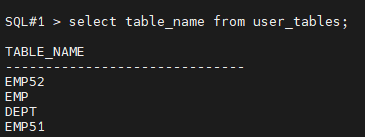
SQL#1 > connect scott/tiger
Connected.
SQL#1 > select table_name from user_tables;
TABLE_NAME
------------------------------
EMP52
EMP
DEPT
EMP51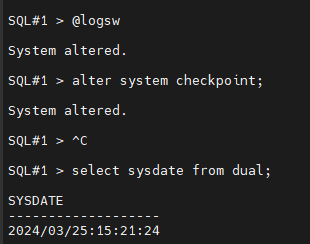
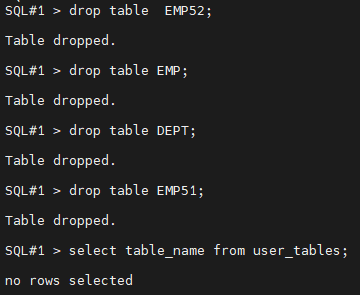
SQL#1 >
drop table EMP52;
drop table EMP;
drop table DEPT;
drop table EMP51;
#1. (복구) cluster_database 를 false 로 변경합니다.
SQL#1 > alter system set cluster_database=false scope=spfile sid='*';

#2. (복구) shutdown immediate 로 양쪽 인스턴스를 모두 를 내립니다.
SQL#1 > shutdown immediate
SQL#2 > shutdown immediate
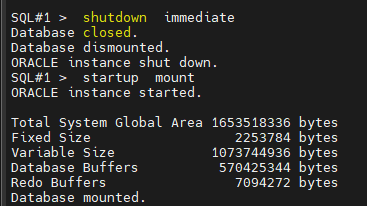
#3 (복구) 한쪽 인스턴스만 startup mount 를 합니다.
SQL#1 > startup mount
#4 (복구) 모든 테이블 drop 되기 전으로 flashback database 를 수행합니다.
SQL#1 > flashback database to timestamp
to_timestamp('2024/03/25:15:21:20','RRRR/MM/DD:HH24:MI:SS');

#5. (복구) resetlogs 로 db를 올립니다.
SQL#1 > alter database open resetlogs;
SQL#1 > connect scott/ tiger
SQL#1 > select table_name from user_tables;
#6. (복구) cluster_database 를 true 로 변경
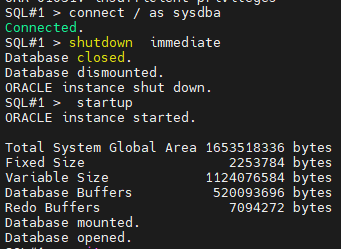
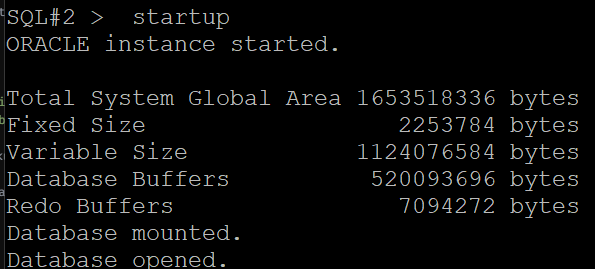
SQL#1 > alter system set cluster_database=true scope=spfile sid='*';

#7. (복구) 양쪽 인스턴스를 내렸다 올립니다.
SQL#1 > shutdown immediate
SQL#1 > startup
SQL#2 > startup
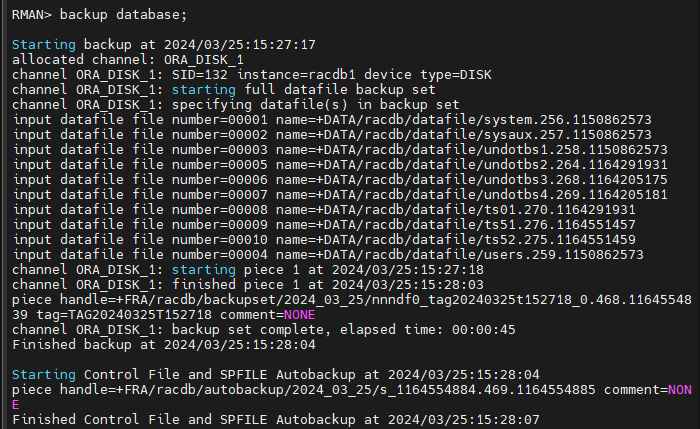
#8. rman 으로 전체 full backup 을 수행합니다.
rman target sys/oracle nocatalog
backup database
문제 2. flashback database 기능을 끄세요.
SQL#1 > alter database flashback off;

▣ 예제34. RAC 환경에서 실수로 테이블스페이스를 drop 했을 때 복구 방법.
실수로 테이블 스페이스를 drop 하게 되면 time base 불완전 복구를 해야합니다. time base 불완전 복구를 할 때 먼저 테이블 스페이스가 drop 되기 전의 controlfile 백업본을 먼저 복원하고 복구를 해야 합니다.
■ 실습
#1. ts22 테이블 스페이스를 생성합니다.
SQL#1> create tablespace ts22 datafile size 10m;
#2. 컨트롤 파일을 생성하는 스크립트 생성
SQL#1> alter database backup controlfile to trace as '/home/oracle/c22.sql';

#3. RMAN 으로 전체 백업
$ rman target sys/oracle nocatalog
RMAN > show all;
RMAN > CONFIGURE CONTROLFILE AUTOBACKUP ON;
RMAN > backup database include current controlfile;
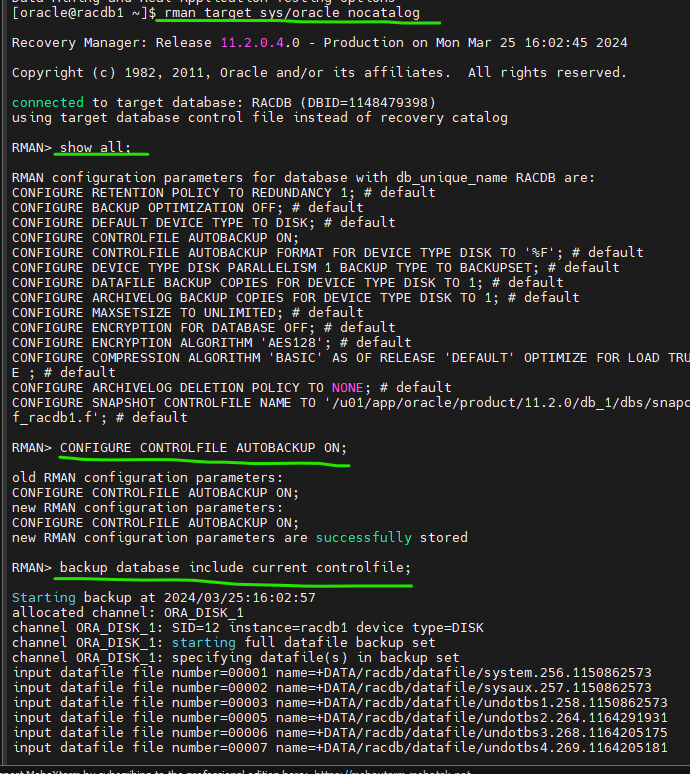
piece handle=+FRA/racdb/autobackup/2024_03_25/s_1164557025.442.1164557025 comment=NONE
Finished Control File and SPFILE Autobackup at 2024/03/25:16:03:48

#4. 로그 스위치를 5번 정도 수행합니다.
SQL#1> @logsw
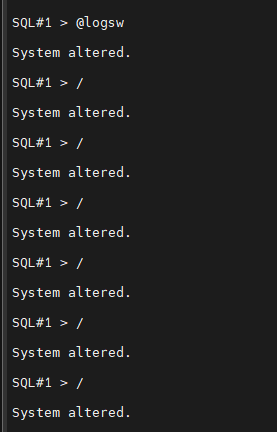
#5. ts22 테이블 스페이스를 drop 합니다.
SQL#1> drop tablespace ts22 including contents and datafiles;
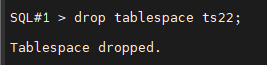
#6. (복구) alert log file 을 열어서 drop 된 시간을 확인합니다.
#7. (복구) 양쪽 인스턴스를 shutdown immediate 로 내립니다.
shutdown immediate
shutdown immediate
#8. (복구) 한쪽 인스턴스만 startup nomount 를 합니다.
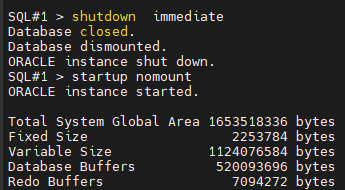
#9. (복구) ts22 테이블 스페이스를 인식하고 있는 옛날 controlfile 을 복원합니다.
$ rman target sys/oracle nocatalog
RMAN > restore controlfile from '+FRA/racdb/autobackup/2024_03_25/s_1164557025.442.1164557025';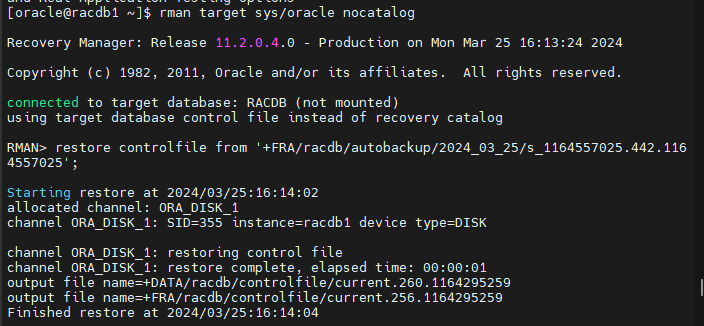
#10.(복구) alter database mount 로 한쪽 인스턴스를 mount 로 올립니다.
RMAN > alter database mount
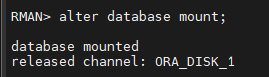
#11.(복구) ts22 테이블 스페이스가 drop 되기전 10초전으로 불완전 복구를 시도합니다.
16:08:16
RMAN> run { set until time='2024/03/25:16:08:16';
2> restore database;
3> recover database; }
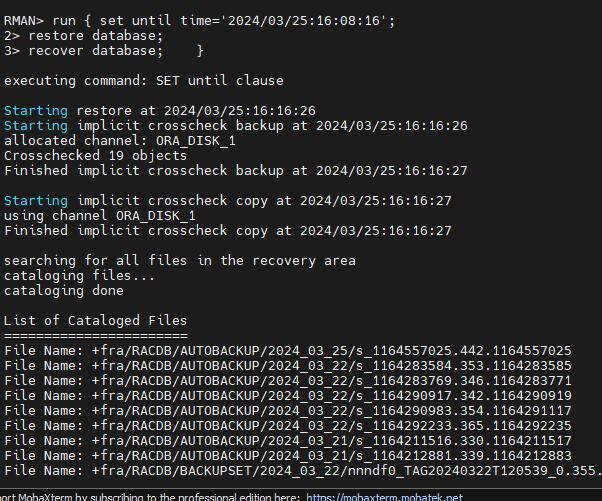
#12.(복구) resetlogs 옵션을 써서 db 를 올립니다.
RMAN > alter database open resetlogs;
#13.(복구) ts22 테이블 스페이스가 복구되었는지 확인합니다.
SQL#1 > select tablespace_name , file_name from dba_data_files;
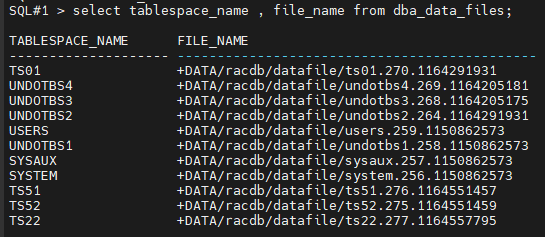
#14.(복구) 다른 인스턴스를 올리면 됩니다.
SQL#2 > startup
RMAN > backup database;
이수자 평가 3번 문제 !
영문 이니셜로 테이블 스페이스를 생성하고 drop 한 다음에 위와 같이 복구하고 마지막 복구 된 화면을 캡쳐해서 제출하시오 !
#1.
create tablespace ts_jhs datafile size 10m;

#2. 컨트롤 파일을 생성하는 스크립트 생성
SQL#1> alter database backup controlfile to trace as '/home/oracle/c_jhs.sql';

#3. RMAN 으로 전체 백업
$ rman target sys/oracle nocatalog
RMAN > show all;
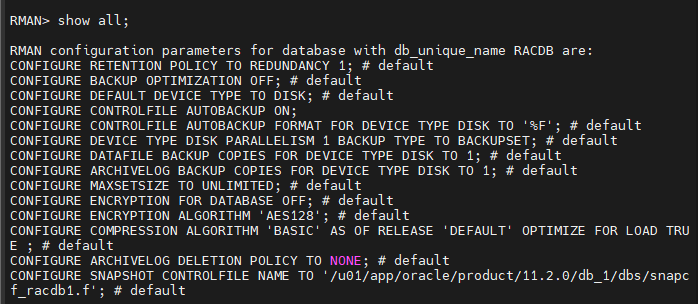
RMAN > CONFIGURE CONTROLFILE AUTOBACKUP ON;
RMAN > backup database include current controlfile;
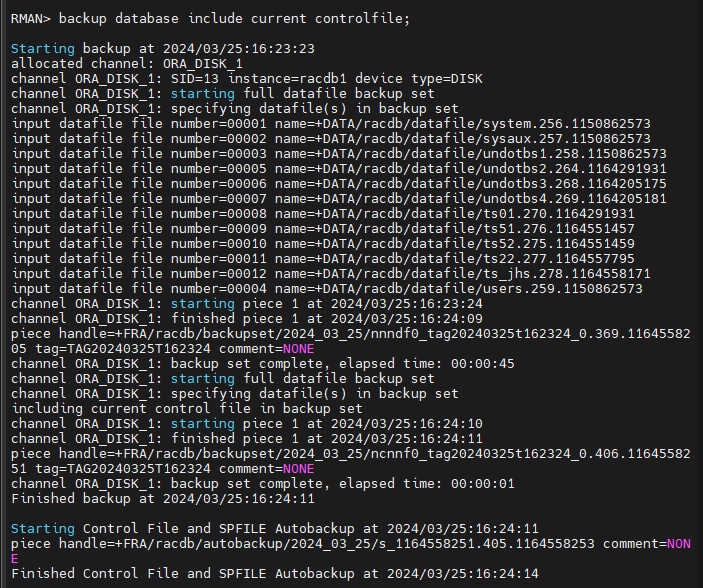
+FRA/racdb/autobackup/2024_03_25/s_1164558251.405.1164558253

#4. 로그 스위치를 5번 정도 수행합니다.
SQL#1> @logsw
#5. 이니셜 테이블 스페이스를 drop 합니다.
SQL#1> drop tablespace ts_jhs including contents and datafiles;

#6. (복구) alert log file 을 열어서 drop 된 시간을 확인합니다.

#7. (복구) 양쪽 인스턴스를 shutdown immediate 로 내립니다.
SQL#1> shutdown immediate
SQL#2>shutdown immediate
#8. (복구) 한쪽 인스턴스만 startup nomount 를 합니다.
SQL#1> startup nomount

#9. (복구) ts22 테이블 스페이스를 인식하고 있는 옛날 controlfile 을 복원합니다.
$ rman target sys/oracle nocatalog
RMAN > restore controlfile from '+FRA/racdb/autobackup/2024_03_25/s_1164558251.405.1164558253';
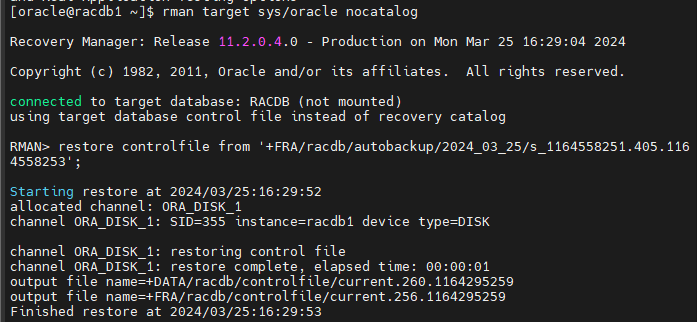
#10.(복구) alter database mount 로 한쪽 인스턴스를 mount 로 올립니다.
RMAN > alter database mount
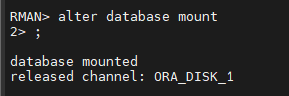
#11.(복구) ts22 테이블 스페이스가 drop 되기전 10초전으로 불완전 복구를 시도합니다.
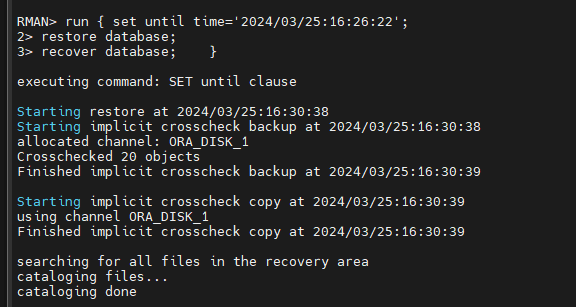
16:08:16
RMAN> run { set until time='2024/03/25:16:26:22';
restore database;
recover database; }
#12.(복구) resetlogs 옵션을 써서 db 를 올립니다.
RMAN > alter database open resetlogs;
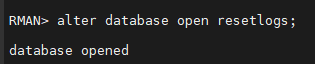
RMAN > backup database;
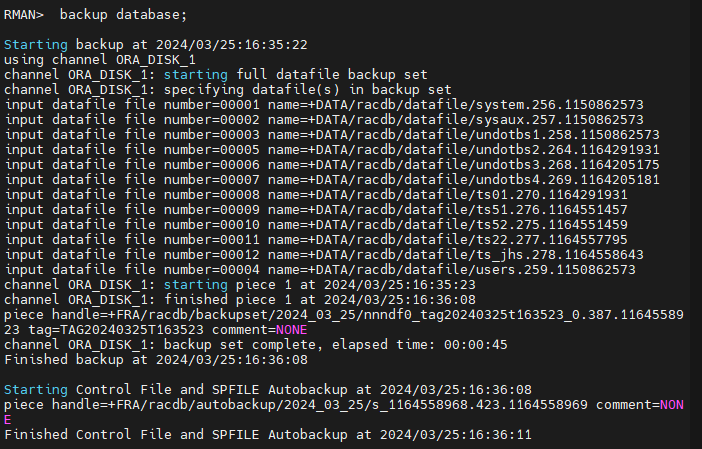
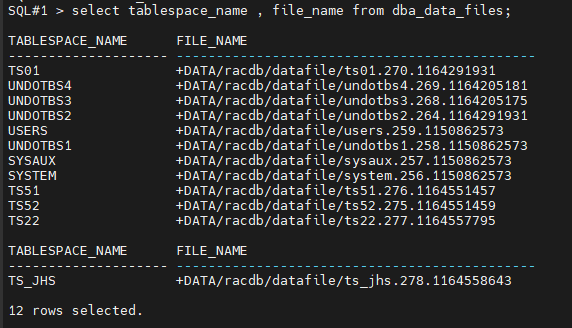
#13.(복구) 이니셜 테이블 스페이스가 복구되었는지 확인합니다.
select tablespace_name , file_name from dba_data_files;
#14.(복구) 다른 인스턴스를 올리면 됩니다.
startup