Moore's Law
Integrated circuits의 transistor의 수는 2년에 2배씩 증가
high clock speed을 만들기 어려운 이유
- power consumption
- heat generation
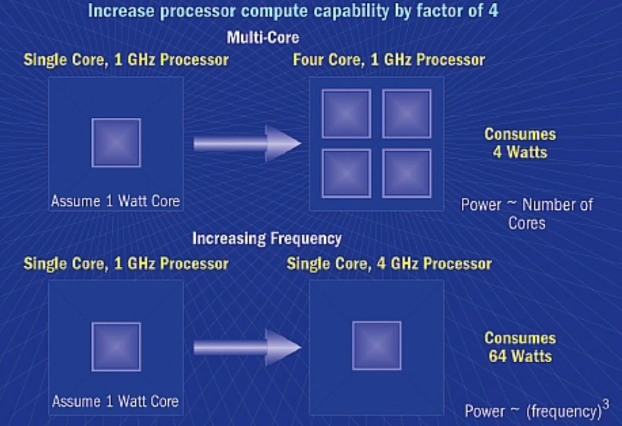
위 사진을 보면 하나의 core을 사용했을 때 power consumption은 1 Watt에서 64 Watt로 늘어난 반면 4개의 core을 사용했을 때는 1 Watt에서 4 Watt로 늘어남
Parallelism
Task Parallelism
- 여러 processor 또는 thread에 서로 다른 작업을 분산함
- 병렬화의 양은 독립된 task의 수에 비례
- CPU에 맞춤
Data parallelism
- 동일한 data의 부분집합에 동일한 task가 수행됨
- 병렬화의 양은 입력 data에 비례
- GPU에 맞춤
SIMT
Single Instruction, Multiple Threads
GPU의 구조는 SIMT에 기반되어 있다.
- 같은 연산을 여러 thread로 실행
- thread의 그룹은 control unit에 의해 다뤄짐
- 32 threads (=warp)
- group 내 thread들 간에 서로 다른 workflow을 가진다.
- 이때, work serialization에 의해 약간의 성능 저하가 있을 수도 있음
- GPU에는 서로 다른 여러 Streaming Multiprocessor(SM)가 있지만 각 SM은 32개의 thread들로 구성되어 있음.
- 이때, 각 thread에는 자체 program counter, register가 있음
Processor : Multicore vs Many-core
Multicore direction (CPU) : 2~8 cores
- general purpose 연산을 주로 다룸
- sequential program의 연산속도를 높임
- ex. Intel i7 has 4 cores
Many-core direction (GPU) : 100~3000 cores
- parallel의 실행 throughput에 집중
- 순서대로 signle instruction
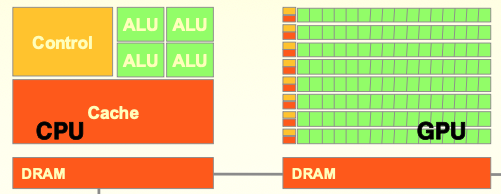
CPU vs GPU
CPU
- sequential code 성능에 최적화
- 큰 cache memory
- instruction이나 data access의 지연시간 단축
- 강력한 ALU
- 연산 지연 시간 단축
GPU
- multiple threads의 처리량에 최적화
- 작은 cache memory
- 메모리 처리량 향상
- 에너지 효율적인 ALU