
1. Self RAG
가. Reference
참고 논문:
Self-RAG: Learning to Retrieve, generate, and critique through self-reflection(Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi)
https://arxiv.org/pdf/2310.11511
1) Introduction
최근 LLM의 활용이 급증하면서, 내부 지식만으로 답을 생성할 때 발생하는 factual inaccuracy 문제가 부각되고 있다.
RAG은 문서를 고정된 수만큼 미리 검색하여 부족한 정보를 보완하지만, 불필요한 정보가 포함되거나 효율이 떨어지는 한계가 있다.
Self RAG는 이 두 가지 문제를 해결하기 위해 필요할 때만 문서를 검색하고, 생성 중간중간 self‑reflection을 통해 스스로 평가 및 제어하는 end‑to‑end 프레임워크를 제안한다.
2) 핵심 아이디어
① Reflection Tokens 도입
-
Retrieve(검색 필요 여부),ISREL(관련성),ISSUP(지원 여부),ISUSE(유용성) 네 가지 토큰을 생성 과정에 삽입 -
각 토큰의 출력을 토대로, "지금 검색이 필요할까?", "생성 결과가 문서에 근거한 것인가?", "질문에 도움이 되는 답인가?" 등을 모델이 스스로 판단
② On-Demand Retrieval
-
Segment 단위로
Retrieve=Yes확률이 높은 경우에만 Retriever을 호출하여 상위 K 개의 문서를 불러옴 -
불러온 문서와 현재까지의 출력을 함께 보고, 이후 세 가지 평가 토큰(
ISREL,ISSUP,ISUSE)을 생성하여 세부 제어를 수행
③ Critic & Generator 통합 학습
-
Critic 모델을 GPT-4로 작성된 reflection 데이터로 먼저 학습하여 토큰 예측 정확도 제고
-
그 위에 Generator 모델을 원문+reflection 토큰 형태의 증강 데이터로 학습하여, 토큰 예측과 생성을 동시에 수행하도록 함
④ 세그먼트 별 Beam Search
- 검색을 수행한 세그먼트별로 후보 답안을 병렬적으로 생성하고, reflection 토큰 점수로 순위를 매겨 최적의 시퀀스를 선택.
나. Purpose
Self RAG는 Agentic RAG처럼 외부 코드가 아니라 LLM 스스로 검색 → 평가 → 생성 과정을 반복하도록 설계된 기법이다.
모델이 먼저 질문에 대한 답변 초안을 만들고, 그 답변에서 부족한 정보를 스스로 판단해 추가 검색 쿼리를 생성하며, 검색 결과를 다시 입력으로 활용해 답변을 점진적으로 개선한다.
이렇게 하면 외부 루프 제어 없이 하나의 Prompt–LLM 호출만으로 RAG 사이클 전체를 수행할 수 있고, 처음에는 놓쳤던 정보까지 포함한 고품질의 최종 응답을 얻을 수 있다.
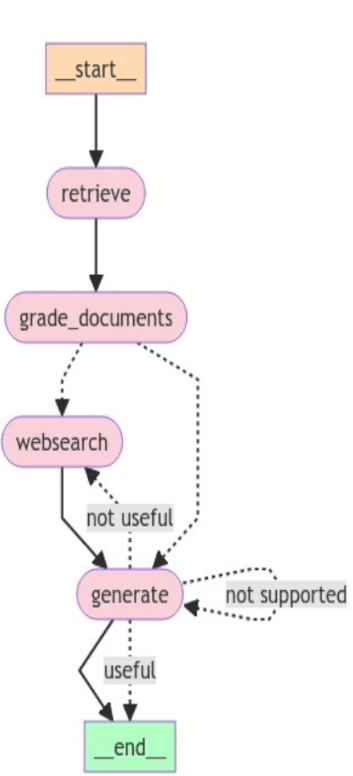
다. answer grader
본 코드는 LLM이 생성한 답변이 주어진 질문을 제대로 해결(resolve)했는지를 자동으로 평가하는 Answer Grader Chain을 정의한 것이다.
① import
# answer_grader.py
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
from langchain_core.runnables import RunnableSequence
from langchain_openai import ChatOpenAI② Pydantic 스키마 정의
# answer_grader.py
class GradeAnswer(BaseModel):
binary_score: bool = Field(
description="Answer addresses the question, 'yes' or 'no'"
)-
GradeAnswer모델은 LLM 출력이{"binary_score": true}혹은{"binary_score": false}형태의 JSON이 되도록 스키마를 지정한다. -
binary_score가true면 답변이 질문을 해결한다는 뜻이다.
③ LLM 인스턴스 및 구조화된 출력 래퍼
# answer_grader.py
llm = ChatOpenAI(temperature=0)
structured_llm_grader = llm.with_structured_output(GradeAnswer)ChatOpenAI(temperature=0)로 결정론적 출력을 설정하고,.with_structured_output(GradeAnswer)로 LLM이GradeAnswer모델에 맞는 JSON을 반환하도록 강제한다.
④ Prompt Template
# answer_grader.py
system = """You are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
]
)-
System 메시지: 답변이 질문을 해결했는지 ‘yes’/‘no’로 평가하라는 지시 포함
-
Human 메시지: 실제
question과 LLM의 생성 결과인generation을 Placeholder로 삽입하여, 평가 대상 정보를 제공
⑤ Chain 결합
# answer_grader.py
answer_grader: RunnableSequence = answer_prompt | structured_llm_graderChatPromptTemplate와structured_llm_grader를 파이프로 연결하여, 프롬프트에 값을 채워 LLM에 보내고 JSON 형태로GradeAnswer를 반환받는 RunnableSequence Chain을 완성한다.
라. hallucination grader
본 코드는 LLM이 생성한 답변이 실제로 제공된 사실 집합(facts)에 근거하고 있는지, 즉, 허구(hallucination)에 빠지지 않았는지를 자동으로 평가하는 Hallucination Grader Chain을 정의한 코드이다.
① import
# hallucination_grader.py
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
from langchain_core.runnables import RunnableSequence
from langchain_openai import ChatOpenAI② Pydantic 스키마 정의
# hallucination_grader.py
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: bool = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)-
GradeHallucinations모델은 LLM 출력이 반드시{ "binary_score": true }또는{ "binary_score": false }형태의 JSON이 되도록 스키마를 지정 -
binary_score가true일 때 답변이 제공된 사실 집합에 근거한다는 뜻이다.
③ LLM 인스턴스 및 구조화된 출력 래퍼
# hallucination_grader.py
llm = ChatOpenAI(temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)④ Prompt Template
# hallucination_grader.py
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)-
System 메시지: “제공된 사실 집합” 기반 여부를 yes/no로 평가하라는 역할을 지시
-
Human 메시지: 실제 평가 대상인
{documents}(사실 집합)와{generation}(LLM 생성 결과)을 Placeholder로 삽입한다.
⑤ Chain 결합
# hallucination_grader.py
hallucination_grader: RunnableSequence = hallucination_prompt | structured_llm_grader2. Adaptive RAG
가. Reference
참고 논문:
Adaptive-RAG: Learning to Adapt Retrieval-Augmented LLMs through Question Complexity(Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, Jong C. Park)
https://arxiv.org/pdf/2403.14403
RAG 시스템의 문제점을 Self RAG가 세그먼트별로 Retrieve, ISREL, ISSUP, ISUSE 같은 self‑reflection 토큰을 쓰며 반복적 검색·생성·평가를 통해 해결했지만, 여러 단계를 거치느라 추론 시간이 길어질 수 있다는 단점이 있었다.
Adaptive‑RAG는 질문의 복잡도에 따라 세 가지 전략(A: LLM 단독, B: 한 번만 검색, C: 다중 단계 검색)으로 분류(Classification)하고, 그 예측 결과에 맞춰 필요한 흐름만 수행하여 효율성과 정확도를 동시에 잡습니다.
구체적으로, 먼저 소형 LLM 기반의 질문 복잡도 분류기가 입력을 A/B/C 세 클래스로 나누고, 분류 결과가 “A”라면 추가 검색 없이 LLM만으로 답변을 생성하며, “B”라면 한 번의 검색을 거친 뒤 답변을, “C”라면 반복적 검색·생성 과정을 통해 다중‑hop 질문에도 대응할 수 있도록 설계되었다.
이 전체 과정을 end‑to‑end로 학습하기 위해, 분류기에는 silver data와 단일‑hop vs. 다중‑hop 데이터셋의 편향을 결합한 라벨을 사용하고, RAG 모델에는 복잡도 토큰을 삽입한 증강 데이터를 활용한다.
이어지는 코드에 등장한 RouteQuery Pydantic 모델과 structured LLM Router Chain은, 본 논문에서 제안하는 질문 복잡도 분류기(Classifier) 역할과 맥을 같이 한다.
Adaptive-RAG 분류기가 A/B/C 중 하나를 예측하여 그에 맞는 전략을 필요에 따라 선택하는 것처럼, 이어지는 코드는 vectorstore로 보낼지, websearch로 보낼지를 물어본다. 이렇게 불필요한 단계는 건너뛰고, 필요한 검색만 수행할 수 있도록 한 점이 두 접근의 공통점이다.
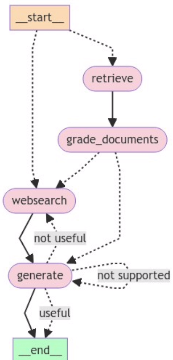
나. Code Implementation
① import
# router.py
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI② RouteQuery Pydantic 모델 정의
# router.py
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["vectorstore", "websearch"] = Field(
...,
description="Given a user question choose to route it to web search or a vectorstore.",
)-
datasource필드에"vectorstore"또는"websearch"를 지정 -
이 모델을 통해 LLM이 반환해야 할 구조화된 응답(
“vectorstore”혹은“websearch”)을 타입으로 명시
③ LLM 인스턴스화 및 구조화된 출력 래퍼 생성
# router.py
llm = ChatOpenAI(temperature=0)
structured_llm_router = llm.with_structured_output(RouteQuery)④ System Prompt 설계
# router.py
system = """You are an expert at routing a user question to a vectorstore or web search.
The vectorstore contains documents related to agents, prompt engineering, and adversarial attacks.
Use the vectorstore for questions on these topics. For all else, use web-search."""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)- 시스템 메시지에서 “
vectorstore로 보낼지,websearch로 보낼지” 결정 기준을 명시
⑤ Prompt와 LLM 래퍼 연결
# router.py
question_router = route_prompt | structured_llm_router<참고 자료>
https://www.udemy.com/course/langgraph/?couponCode=KEEPLEARNING
https://github.com/emarco177/langgraph-course/commit/5400fb70faa11817c1ef807d3bbe4efd76c55ae7#diff-5bd893559de2235ffe0cda697dde5fcfbdc1da070756a24692ec0ea6ba0780a3
https://github.com/emarco177/langgraph-course/commit/034e53ff2ea283e07ab52c9106c48459a9fdc78f
