
알고리즘, 데이터구조 with Nico 시리즈에서 알고리즘, 데이터구조를 공부할 때 = 애플리케이션 개발 및 배포 후 오류가 없지만 애플리케이션 구동 속도가 느릴 때 라고 한다.
사실 회사에서 속도가 느려질 정도로 큰 프로젝트를 하진 않았지만 면접을 보러 다니면서 알고리즘적인 질문을 몇 개 받다보니 코딩테스트를 위한 알고리즘 공부보다는 이론적인 내용이 궁금해져서 유투브에서 이 시리즈를 찾아 보게 되었다!
알고리즘과 데이터구조
알고리즘
알고리즘은 결국 여러 개의 지시사항이다. 즉 어떠한 액션을 수행하기 위해서 컴퓨터가 수행해야 하는 것들로, 목적을 달성하기 위한 여러 행동들을 의미한다. 이러한 알고리즘은 동일한 수행 결과를 산출한다.
효율적인 알고리즘을 찾은 후부터는 그 알고리즘을 반복적으로 사용할 수 있다.
데이터구조
수많은 데이터를 정리하는 것을 의미한다.
있어보이게(?) 정리하는 것을 의미하는 것이 아니라, 데이터는 속도에 영향을 주므로 속도를 개선하기 위해 데이터를 정리하는 것을 말한다.
어떠한 작업에 어떠한 데이터 구조를 언제 어떻게 쓰는지 아닌 것이 해당 애플리케이션의 속도를 결정하게 된다.
Array
시간 복잡도 (Time Complexity)
데이터 구조의 오퍼레이션 혹은 알고리즘이 얼마나 빠르고 느린지 측정하는 방법이다.
실제 시간을 측정하는 것이 아닌, 얼마나 많은 단계(steps)가 있는지를 측정한다.
메모리
휘발성 메모리 (volatile memory)
컴퓨터를 껐다 키면 남아있지 않은 RAM(Random Access Memory) 속 데이터처럼 유지되지 않는 메모리를 의미한다.
프로그램을 실행하고 변수를 생성할 때, 모두 RAM에 저장된다.
RAM은 데이터 접속을 랜덤으로 할 수 있기 때문에, RAM 속 데이터를 읽는 것이 하드 드라이브 속 데이터를 읽는 것보다 빠르다.
즉, RAM 속 데이터가 박스 형태로 저장되어 있다고 생각한다면 "Memory Address 5번, Memory Address 2번 속 데이터를 가져와!" 라고 명령을 했을 때 1,2,...5번 식으로 순차적으로 메모리에 접근하는 것이 아닌 5번이면 5번, 2번이면 2번으로 바로 랜덤하게 접근할 수 있다.
비휘발성 메모리 (non-volatile memory)
컴퓨터를 껐다 켜도 하드 드라이브 속 데이터가 그대로 남아있듯이 그대로 남아있는 메모리를 의미한다.
배열
프로그램에서 배열을 생성할 때, RAM에게 배열의 길이를 알려줘야 몇 칸의 박스를 지정할지 판단하여 해당 메모리를 저장할 수 있다.
Javascript를 사용하는 나에겐 '배열의 길이를 알려줘야한다'라는 의미가 와닿지 않는데, Python과 Javascript는 내부적으로 배열 길이를 할당해주고 있는 것이라고 한다.
(이건 양날의 검... 내가 모르는 사이 내부에서 처리하는 과정 중에 프로그램이 느려질 수 있는 것! 뭐든 직접 핸들링해야 하는 C는 내가 직접 처리해야 하므로 느려지지 않을 수 있지만 오히려 잘못 하면 더 느려질 수 있는...)
Reading (읽기)
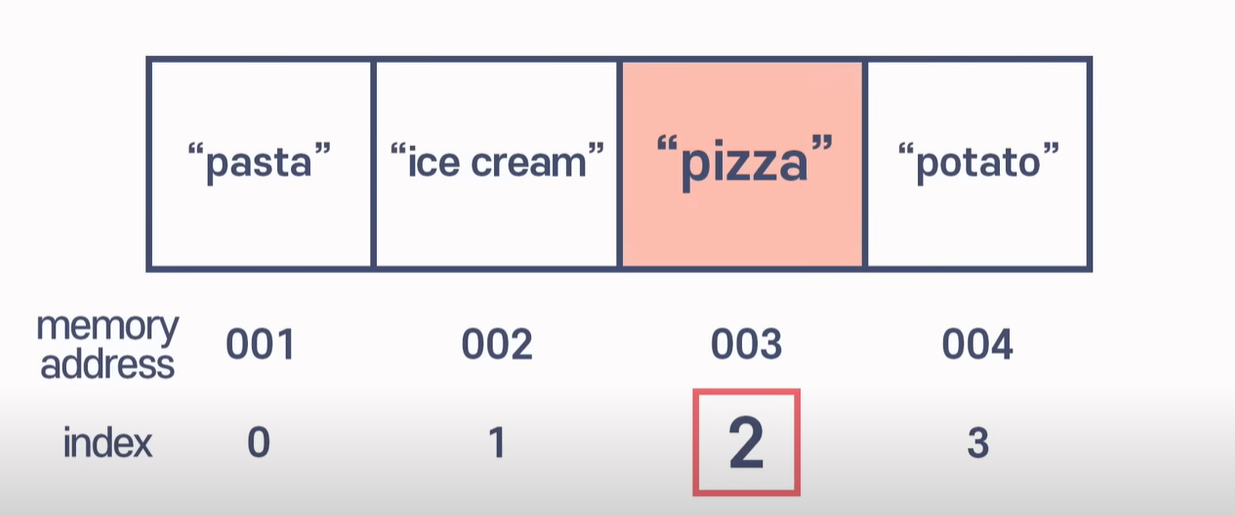
알고 있다시피 배열은 0부터 시작하며, 길이가 4인 배열이 있을 때 pizza에 접근하고 싶으면 컴퓨터에게 인덱스 2번의 값을 달라고 하면 된다.
따라서 컴퓨터는 배열이 어디서 시작하는지 알고 있고 인덱스에서 요소를 읽어내는 속도는 동일하기 때문에, 배열에서 데이터를 읽는 속도는 매우 빠르다.
이러한 이유로 많은 자료를 읽어야 할 경우엔 배열이 가장 적절하다. (Random Access 덕분!)
Searching (검색)
해당 값이 배열에 있는지 없는지 있다면 어디에 있는지 알 수 없다. 하나하나 찾는 검색 과정을 거쳐야 해당 값이 있는지, 있다면 어디에 있는지 알 수 있다. 따라서 검색은 읽기보다 시간이 더 걸린다.

박스형태로 돼있는 배열의 주소는 바로 알 수 있지만, 해당 주소에 어떤 값이 들어가 있는지는 해당 박스를 열어야 알 수 있다.
즉, random access로 해당 박스에 쉽게 접근은 할 수 있지만 그 박스 안의 값은 모르는 상황이므로 주소에 하나하나 엑세스해서 값을 읽고 그 값이 내가 찾는 값인지 확인을 해야하기 때문에 시간이 오래 걸린다.
원하는 값을 찾기 위해 순서대로 처음부터 원하는 값이 나올 때까지 엑세스 해서 찾는 것을 '선형 검색 (Linear Search)'이라고 한다.
선형 검색 외에도 빠른 검색을 하는 방법이 존재한다. (이 방법은 다음에...)
Insert(Add) (쓰기)
배열을 만들 땐 배열의 공간을 미리 확보해야 하며, 해당 배열의 길이를 알려줘야한다.
공간이 남아있는 경우
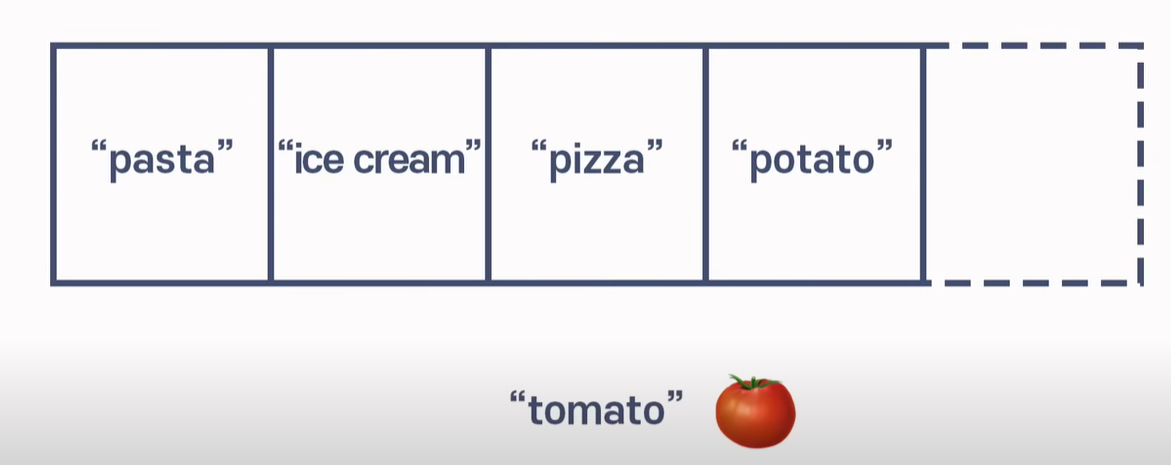
배열의 길이를 5라고 알려준 후, 네 개의 데이터가 들어가 있는 상황에서 하나의 데이터를 추가하고 싶을 때 미리 공간을 확보해뒀기 때문에 공간 걱정을 하지 않아도 된다.
이 상황에서는 데이터를 "어디에" 추가할 것인가를 생각해야 한다.
최고의 시나리오는 컴퓨터가 배열이 어디서 시작하고 얼마나 긴지 기억하기 때문에 배열의 가장 끝에 추가하는 것이다.
보통의 시나리오는 배열의 중간에 추가하는 것이고, 최악의 시나리오는 데이터를 배열의 맨 앞에 추가하는 것이다. 데이터를 배열의 맨 앞에 추가할 경우 배열의 모든 아이템들을 뒤로 옮겨줘야하기 때문이다.
공간이 남아있지 않은 경우
배열은 미리 공간을 확보하고 길이를 알고 있기 때문에 5개의 데이터를 넣는 길이가 5인 배열에 6개 혹은 7개의 공간을 써야 한다면, 이전 배열을 복사한 후 새로운 배열을 추가해서 옮기는 과정이 필요하다.
따라서 기존 배열의 공간보다 많은 데이터를 넣어야 하는 경우가 가장 최악의 시나리오라고 할 수 있다.
Delete (삭제)
삭제는 배열에 데이터를 추가하는 것과 비슷하다.
최고의 시나리오는 배열의 가장 마지막 요소를 삭제하는 경우이다. 마지막 주소를 찾아가서 마지막만 삭제하면 되므로 속도가 빠르다.
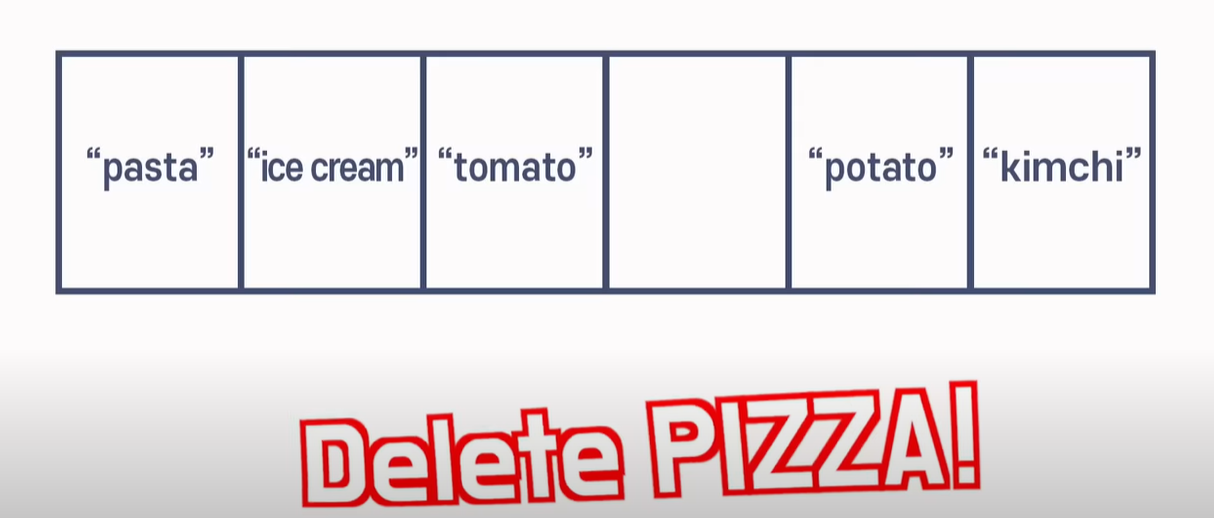
보통의 시나리오는 배열의 중간을 삭제하는 경우이다. 중간 주소를 찾아가서 삭제를 한 후 공백이 생기는데 해당 공백을 막기 위해 뒷 주소의 데이터들이 움직여야한다.
최악의 시나리오는 배열의 첫 번째 데이터를 삭제하는 경우이다. 첫 번째 데이터를 삭제한 경우 해당 공백을 막기 위해 그 다음 데이터부터 전체가 움직여야 한다.
