동시성, 병렬성
동시성
우리는 그동안 단일 프로그램을 사용했습니다.(위에서 아래로) 하나의 루틴, 하나의 흐름을 가지고 프로그램 시작과 종료가 동일했어요.
하지만 동시성은 A라는 작업, B라는 작업, C라는 작업들이 서로상호적으로 데이터를 전달 받거나 또는 받지 않으면서 여러가지를 동시에 처리 할 수 있다는 거에요.
쓰레드, 하나의 쓰레드 안에서 일어나는 또는 분기를 처리하여 효율을 극대화 할 수 있어요.
병렬성
1부터 1억을 더하게 되는데, 1부터 2천5백만까지 더하고 2천5백만부터 5천만까지 더하는 그렇게해서 4개로 쪼개는 하나의 계산을 CPU나 이런 것들로 병렬처리 하는데요. (주로 딥러닝에서 활용하거나, 그래픽카드를 여러개 활용하고, 비트코인 채굴에도 여러개의 GPU가 필요해요)
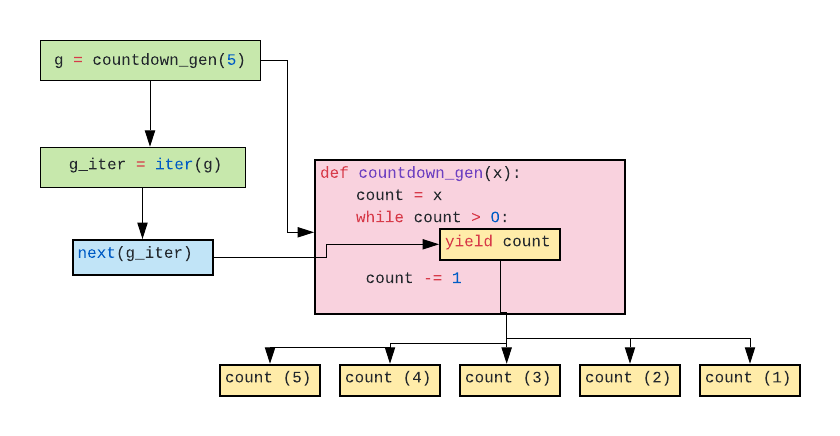
Python Generator
- 파이썬 반복형 종류
- iter, next 함수
- Generator 장점
- Generator 활용
- Generator 내장 함수 활용
흐름제어, 병행처리(Concurrency)
파이썬 반복형 종류
- for
- collection
- text file
- List
- Dict
- Set
- Tuple
- unpacking
- *args
학습사항 : 반복형 객체는 내부적으로 iter 함수를 사용. 제네레이터 동작원리, yield from
반복 가능한 이유? -> 파이썬 인터프리터 엔진이 iter 함수를 호출 하기에 사용가능함
t = 'ABCDEF'
# FOR 사용
for c in t:
print('ex1-1', c)
# while 사용
w = iter(t)
while True:
try:
print('ex1-2', next(w))
except StopIteration:
break # 브레이크 없으면 무한 반복됨
# 추상 클래스
from collections import abc
# 반복형 확인
print('ex1-3 -', hasattr(t, '__iter__'))
# has attr? 속성을 가지고 있니? 즉, 첫번째 인자가 두번째 속성을 가지고 있으면 True 없으면 False
print('ex1-4', isinstance(t, abc.Iterable))
# t인스턴스가 abc.Iterable과 같은 인스턴스인지 확인하는데요. True, False를 반환해요.
# 즉여기서는 True가 나왔으니 순회가 가능하다는 거조.
class WordSplitIter:
def __init__(self, text):
self._idx = 0
self._text = text.split(' ')
def __next__(self):
print('called __next__')
try:
word = self._text[self._idx]
except IndexError:
raise StopIteration('Stop! Stop!')
self._idx += 1
return word
def __iter__(self): # 클래스의 인스턴스를 반복가능하게 하기위해 선언
print('Called __iter__')
return self
def __repr__(self):
return 'WordSplit(%s)' %(self._text)위코드에서 중요한것은 next와 iter를 클래스안에 구현해주었다는 점이에요.
그렇게되면 파이썬 씨퀀스 프로토콜에서 '어! 너는 iterable한 객체구나!'라고 알아서 해줘요.
아니면 명시적으로 Sequence를 상속받아서 해도 되지만 그럴경우 코드 작성을 더해야하는 번거로움도 생기기에 파이썬 엔진에게 위임하여 알아서 동작하는 방법을 진행했어요.
코드 작성 이어갈게요.
wi = WordSplitIter('Who says the nigths are for sleeping')
print(wi)
# 출력결과: WordSplit(['Who', 'says', 'the', 'nigths', 'are', 'for', 'sleeping'])init메서드가 작동하여 입력한 문자열이 띄어쓰기를 기준으로 리스트에 담겨 있는것이 보입니다.
또한 print() 메서드에 wi객체를 넣어 출력되서 확인 할 수 있는것도 매직메소드 repr을 구현하여 self._text를 반환하였기에 가능하다는점! 만약 repr 구현하지 않으면 객체 주소값만 보여줘요
<__main__.WordSplitIter object at 0x000001FCF5C29130> 이렇게 말이조
print('ex2-1',wi)
print('ex2-2',next(wi))
print('ex2-2',next(wi))
print('ex2-2',next(wi))
print('ex2-2',next(wi))
print('ex2-2',next(wi))
print('ex2-2',next(wi))
print('ex2-2',next(wi))
print('ex2-2',next(wi))next()로 wi객체를 계속 호출해볼게요. 그러면 아래와 같은 결과가 나와요.
ex2-1 WordSplit(['Who', 'says', 'the', 'nigths', 'are', 'for', 'sleeping'])
called __next__
ex2-2 Who
called __next__
ex2-2 says
called __next__
ex2-2 the
called __next__
ex2-2 nigths
called __next__
ex2-2 are
called __next__
ex2-2 for
called __next__
ex2-2 sleeping
line 54, in __next__ raise StopIteration('Stop! Stop!')
StopIteration: Stop! Stop!
Indexerror가 나타나면 우리가 정의한 StopIteration 메소드가 에러를 불러온게 보이조?
next()를 실행하면 딱! 한개의 요소 값을 보여줍니다. 다음 next()를 실행하기 전까지는 말이조.
그래서 generator입니다.
Generator 패턴
지능형 리스트, 딕셔너리, 집합 -> 데이터 셋이 증가 될 경우 메모리 사용량 증가 -> 제너레이터 완화
단위 실행이 가능한 코루틴(Coroutine) 구현에 아주 중요.
딕셔너리, 리스트는한 번 호출 할 때마다 하나의값만 리턴하는데요. -> 아주 작은 메모리 양을 필요로함.
기존에 가지고 있던 next()함수는 지워버립니다.
class WordSplitGenerator:
def __init__(self, text):
self._text = text.split(' ')
def __iter__(self): # 클래스의 인스턴스를 반복가능하게 하기위해 선언
for word in self._text:
yield word # 이게 바로 generator에요.
return
def __repr__(self):
return 'WordSplit(%s)' %(self._text)
wg = WordSplitGenerator('Who says the nigths are for sleeping')
wt = iter(wg) WordSplitGenerator 클래스 안에는 __next__메서드가 없기 때문에 iter메서드를 한번 호출해서 wt 객체를 생성해줘야 itrable 해져요.
print('ex3-1',wt)
print('ex3-2',next(wt))
print('ex3-3',next(wt))
print('ex3-4',next(wt))
print('ex3-5',next(wt))
print('ex3-6',next(wt))
print('ex3-7',next(wt))
print('ex3-8',next(wt))
print('ex3-9',next(wt))이를 통해서 파악 할 수 있는 것은 yield가 나오기 전에는 class 안에 아래와 같이 next 매직메소드로yield와 같은 기능을 구현 했다는 점이에요.
def __next__(self):
print('called __next__')
try:
word = self._text[self._idx]
except IndexError:
raise StopIteration('Stop! Stop!')
self._idx += 1
return word심지어 index범위를 넘기더라도 파이썬 내부적으로 StopIteration실행시킵니다.
만약 wg = WordSplitGenerator('Who says the nigths are for sleeping')에 인자로 천만개의 단어가 있다면 엄청나겠조?
쉽게 영어 사전의 모든 단어를 리스트로 한다면? 기하급수적입니다. 그것을 하나의 리스트로 담는 다는 것은 결국 메모리의 사용량의 증가를 의미해요.
다시한번 더 정리하지만 next()를 호출 할 때마다 그 값을 하나씩! 하나씩! 가져오조?
메모리에서 하나씩 하나씩만 가져오고 그 위치만 기억해요. 즉 넥스트로 호출하지 않으면 두 번째를 만들지 않아요~! next()가 호출되어야 그제야 객체를 만들게되요.
Generator 예제1
def generator_ex1():
print('start')
yield 'AAA'
print('continue')
yield 'BBB'
print('end')
temp = iter(generator_ex1())
# print('ex4-1', next(temp))
# print('ex4-2', next(temp))
# print('ex4-3', next(temp))
# 출력결과:
# start
# ex4-1 AAA
# continue
# ex4-2 BBB
# ex4-3 print('ex4-3', next(temp)) StopIteration 라는 오류가 발생해요.
# 사실 생각해보면 이렇게 next로 한건씩 출력하는 경우는 없어요.
# 주로 반복문에서 generator를 사용하게되요.
for v in generator_ex1():
pass
print('ex4-3', v)
# 출력결과:
# start
# ex4-3 AAA
# continue
# ex4-3 BBB
# end
# Generator 예제2
temp2 = [x * 3 for x in generator_ex1()]
temp3 = (x * 3 for x in generator_ex1())
# 소괄호로 만들게 되면 Generator가 생성된다는거! 즉 지능형 제네레이터가 되요.
print('ex5-1', temp2)
# temp2는 이미 메모리에 만들어서 올린 경우에요.
print('ex5-2', temp3)
# ex5-2 <generator object <genexpr> at 0x0000026174278740>
# ex5-2의 경우, next() 메소드로 만들기 전까지는 메모리에 만들지 않아요.
# 그럼 위 temp3를 나오게 하려면 for문을 사용하면 되겠지요?
for i in temp2:
print('ex5-3', i)
# 출력결과:
# ex5-3 AAAAAAAAA
# ex5-3 BBBBBBBBB
for i in temp3:
print('ex5-4', i) # 5-4는 generator로 호출된거 보이조?
# 출력결과:
# start
# ex5-4 AAAAAAAAA
# continue
# ex5-4 BBBBBBBBB
# end
# 하둡, 파이스파크의 소스코드를 들여다보면 generator로 많이 만들어진 모습을 확인 할 수 있어요.
#그만큼 메모리 사용량을 현격히 줄일수 있다는 거조.
print()
print()
# Generator 예제3(자주 사용하는 함수)
import itertools # 말그대로 iterable한 기능이 있어요.
gen1 = itertools.count(1, 2.5)
# generator의 기능을 종합적으로 가진것.
# 1부터 2.5씩 증가하면서 무한대로 만들어주는 객체생성시 count함수 사용
print('ex6-1', next(gen1))
print('ex6-2', next(gen1))
print('ex6-3', next(gen1))
print('ex6-4', next(gen1))
# 만약 아래와 같은 코드를 사용하면 무한히 1부터 2.5씩 증가하는 loop가 돌게되요
#for v in gen1:
# print(v)
조건
이 itertools는 takewhile함수와 같이 사용하면 엄청 좋아요.
gen2 = itertools.takewhile(lambda n: n<1000, itertools.count(1,2.5)) # 종류값을 원하는 함수를 받아요
# 위 함수를 모르면 그냥 노가다를 하는거겠조?
# 정말 최적화된 패키지를 사용하면 간편하고 편리하니 애용하세요.
for v in gen2:
print('ex6-1',v)
필터 반대
위 기능과 반대되는 함수가 있어요.
gen3 = itertools.filterfalse(lambda n : n < 3, [1,2,3,4,5])
# 3보다 작은 조건은 1,2입니다.
for v in gen3:
print('ex6-6',v)
# 출력결과:
# 3, 4,5가 나오는데요. 이로써 해당 함수는 조건이 false값만 출력하는 filterfalse라는걸 확인 했어요.누적합계
accumulate 보이조? 1,2,3,4,5,6..... 나열된 값들을 다 더하여 누적해서 보여주게되는 메소드에요.
gen4 = itertools.accumulate([x for x in range(1,101)])
for v in gen4:
print('ex6-7', v)연결1
gen5 = itertools.chain('ABCDE', range(1,11,2))
print('ex6-8', list(gen5))
# 출력결과: ex6-8 ['A', 'B', 'C', 'D', 'E', 1, 3, 5, 7, 9] 반복 가능한 것들(인자1 + 인자2)을 하나로 합쳐줌연결2
응용하였을 경우
gen6 = itertools.chain(enumerate('ABCDE'))
print('ex6-9', list(gen6))
# 결과: ex6-9 [(0, 'A'), (1, 'B'), (2, 'C'), (3, 'D'), (4, 'E')] 인덱스를 앞에 적어주는게 보이조?
gen6 = itertools.chain(enumerate('ABCDE'))
print('ex6-9-1', dict(gen6))
# ex6-9-1 {0: 'A', 1: 'B', 2: 'C', 3: 'D', 4: 'E'} 딕셔너리로 생성할 수 있네요.개별
gen7 = itertools.product('ABCDE')
print('EX6-10', list(gen7))
# 결과: EX6-10 [('A',), ('B',), ('C',), ('D',), ('E',)] 문자열의 1개 요소를 튜플로 쪼개주는걸 확인 할 수 있어요.연산(경우의 수)
gen8 = itertools.product('ABCDE', repeat=2)
print('EX6-11', list(gen8))output
결과: EX6-11 [('A', 'A'), ('A', 'B'), ('A', 'C'), ('A', 'D'), ('A', 'E'), ('B', 'A'), ('B', 'B'), ('B', 'C'), ('B', 'D'), ('B', 'E'), ('C', 'A'), ('C', 'B'), ('C', 'C'), ('C', 'D'), ('C', 'E'), ('D', 'A'), ('D', 'B'), ('D', 'C'), ('D', 'D'), ('D', 'E'), ('E', 'A'), ('E', 'B'), ('E', 'C'), ('E', 'D'), ('E', 'E')]그룹화
gen9 = itertools.groupby('AAABBCCCDDEEE')
# print('EX6-12', list(gen9))
for chr, group in gen9:
print('ex6-12',chr,':', list(group))output
결과: 고유한 값은 chr에 찍혀서 나오고 반복되는 값들은 list(group)로 출력되네요.
주로 형태소 검사, 단어의 중요도를 문서로 요약하거나 유사도간의 집합을 만들때도 사용되기도해요.
ex6-12 A : ['A', 'A', 'A']
ex6-12 B : ['B', 'B']
ex6-12 C : ['C', 'C', 'C']
ex6-12 D : ['D', 'D']
ex6-12 E : ['E', 'E', 'E']
