그리디 알고리즘
- 그리디 알고리즘(탐욕법)은
현재 상황에서 지금 당장 좋은 것만 고르는 방법을 의미 - 일반적인 그리디 알고리즘은 문제를 풀기 위한 최소한의 아이디어를 떠올릴 수 있는 능력을 요구
- 그리디 해법은 그 정당성 분석이 중요
- 단순히 가장 좋아 보이는 것을 반복적으로 선택해도 최적의 해를 구할 수 있는지 검토
[문제 상황] 루트노드부터 시작하여 거쳐가는 노드 값의 합을 최대로 만들고 싶습니다.
- 최적의 방법은 무엇인가요?
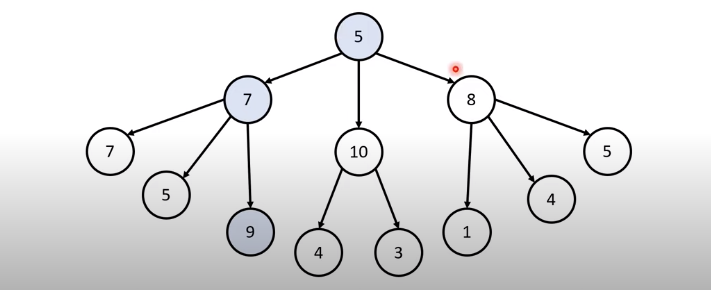
5 ->7->9 정답 : 21
- 만약 단순히 매 상황에서 가장 큰 값만 고른다면?
5->10->14, 합: 19
결국 일반적인 상황에서 그리디 알고리즘은 100%정답이라고 보장 할 수 없습니다.
하지만 코테에서는 대부분의 그리디 문제는 탐욕법으로 얻은 해가 최적의 해가 되는 상황에서, 이를 추론할 수 있어야 풀리도록 출제되요.
<문제> 거스름돈

<문제> 거스름돈: 문제 해결 아이디어
- 최적의 해를 빠르게 구하기 위해서는
가장 큰 화폐 단위부터돈을 거슬러 줍니다. - N원을 거슬러 줘야 할 때, 가장 먼저 500원으로 거슬러 줄 수 있을 만큼 거슬러 줍니다.
- 이후 100원, 50원, 10원짜리 동전을 차례대로 거슬러 줄 수 있을 만큼 거슬러 주면 됩니다.
- N = 1,260일 떄의 예시를 확인해 봅시다.
<문제> 거스름돈: 정당성 분석
- 가장 큰 화폐 단위부터 돈을 거슬러 주는 것이 최적의 해를 보장하는 이유는 무엇인가요?
- 가지고 있는 동전 중에서
큰 단위가 항상 작은 단위의 배수이므로 작은 단위의 동전들을 종합해 다른 해가 나올 수 없기 때문
- 가지고 있는 동전 중에서
- 만약 800원을 거슬러 주어야 하는데 화폐단위가 500, 400, 100이라면 어떻게 될까?
- 그리디의 경우 500원 1개, 100원 3개해서 총 4개가 되지만 사실 400원 2개만 하면 정답이됨.
- 500원은 800의 배수가 되지 못하므로 400원이 800원의 배수가됨. 이에 따라 400원으로 거슬러 줘야하는 논리가 성립됨
- 그리디 알고리즘 문제에서는 이처럼 문제 풀이를 위한 최소한의 아이디어를 떠올리고 이것이 정당한지 검토할 수 있어야함.
<문제> 거스름돈: 파이썬
n =1260e10000
count =0
array=[500,100,50,10]
for coin in array:
count += n//coin # 해당 화폐로 거슬러 줄수 있는 동전의 개수 세기
n %= coin
print(count)
주의사항
하나. 내림차순으로 정렬되어 있어야 위 문제에서 설계된 정답을 낼수 있습니다. 만약 오름차순으로 된다면 126개의 동전을 거슬러주는 알고리즘이 되어버립니다.
다시 말해 가장 동전을 많이 거슬러줄 수 있는 방법이 되버립니다.
<문제> 거스름돈 : 시간 복잡도 분석
- 화폐의 종류가 K라고 할 때, 소스코드의 시간복잡도는 입니다.
- 이 알고리즘의 시간 복잡도는 거슬러줘야하는 금액과는 무관하며,
동전의 총 종류에만 영향을 받습니다.
<문제> 1이될때까지: 문제 설명

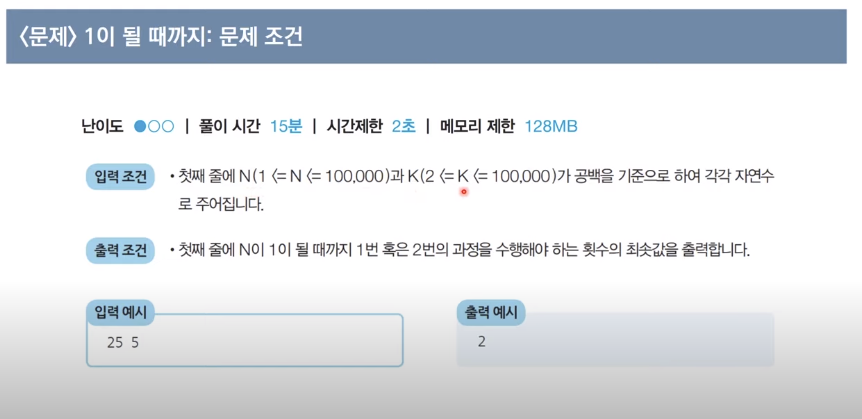
<문제> 1이될때까지: 문제 해결 아이디어
- 주어진 N에 대하여 최대한 많이 나누기를 수행
- N의 값을 줄일 때 2 이상의 수로 나누는 작업이 1을 빼는 작업보다 수를 훨씬 많이 줄일 수 있습니다.
- 예를 들어 N = 25, K=3일 떄는 아래와 같아요.
| 단계 | 과정 | N의값 |
|---|---|---|
| 0단계 | N = 25 | |
| 1단계 | N에서 1빼기 | N = 24 |
| 2단계 | N을 K로 나누기 | N = 8 |
| 3단계 | N에서 1빼기 | N = 7 |
| 4단계 | N에서 1빼기 | N = 6 |
| 5단계 | N을 K로 나누기 | N = 2 |
| 6단계 | N에서 1빼기 | N = 1 |
입력값 = 25, 3
25-1 = 24
24//3 = 8
8-1 = 7
7-1 = 6
6//3= 2 # 여기서 나머지가 0이 된다고 끝나는게 아니라 몫을 받아와서 연산하는 것이므로 주의해야함
2-1=1
<문제> 1이될때까지: 정당성 분석
- 가능하면 최대한 많이 나누는 작업이 최적의 해를 항상 보장 할 수 있을까?
- N이 아무리 큰 수여도, K로 계속 나눈다면 기하급수적으로 빠르게 줄일수 있습니다.
- 즉, K가 2이상이기만 하면, K로 나누는것이 1을 빼는 것보다 항상 빠르게 줄일 수 있습니다.
- 또한 N은 항상 1에 도달하게 됩니다.
<문제> 1이될때까지: 파이썬 코드
n, k = map(int, input().split())
result = 0
while True:
#N이 K로 나누어 떨어지는 수가 될 때까지 빼기
target = (n//k) * k
result += (n-target) # 0 + (25-24) -> 1
n = target # 25 = 24 -> 24
# N이 K보다 작을 때 (더 이상 나눌 수 없을 때) 반복문 탈출
if n < k:
break
# k로 나누기
result += 1
n //= k
# 마지막으로 남은 수에 대하여 1씩 빼기
result +=(n - 1)
print(result)target = (n//k) * k 이 부분은 만약 n이k로 나누어 떨어지지 않는다고 해도 가장 가까운 k로 나누어 떨어지는 어떤 수를 찾을 수 있어요.
즉, n에서 1을 빼는 과정을 몇번 반복해서 target이라는 값까지 만들 수 있고 target이라는 값은 k로 나누어 떨어지는 수가 되요.
result += (n-target) 부분은 우리가 총 연산을 수행하는 횟수를 의미해요.
if n < k: while문을 벗어나고, 그렇지않다면 남은 연산을 수행하게되요.
상기 알고리즘 방법은 반복횟수에 따라서 기하급수적으로 n이 빠르게 줄어들게되요.
즉, 시간 복잡도가 시간 복잡도가 나올수 있게되요. 그래서 이 알고리즘은 어느정도 테크닉이 가미된 부분이에요.
<문제> 곱하기 혹은 더하기:문제 설명
n이 100억 1000억이 넘는 큰 수라고 하더라도 시간 복잡도로 빠르게 해결 할 수 있어요.

<문제> 곱하기 혹은 더하기: 문제 해결 아이디어
- 대부분의 경우 + 보다 *가 더 값을 크게 만듭니다.
- 그러나 두 수중에 0 또는 1인경우 곱하기 보다는 더하기를 수행하는 것이 더 효율적입니다.
- 따라서 두수에 대하여 연산을 수행할 때, 하나라도 1이한인 경우에는 더하며, 두 수가 모두 2이상인 경우에는 곱하면 정답
import sys
data = sys.stdin.readline().rstrip()
# 처음 문자를 숫자로 변경하여 대입
result = int(data[0])
for i in range(1, len(data)):
# 두 수중 하나라도 0 혹은 1인 경우, 더하기 수행
num = int(data[i])
if num <= 1 or result <= 1:
result += num
else:
result *= num
print(result)
주의 사항
- range()함수에서 처음 시작을 1로 잡지 않고 일반적으로 0으로 넘겨버리면 인덱스가 마지막에 넘어가 오류가 발생함.
- 조건문에서 0번째 인덱스 뿐만 아니라 1번째 인덱스 역시 1이하인지 아닌지 판단이 필요함.
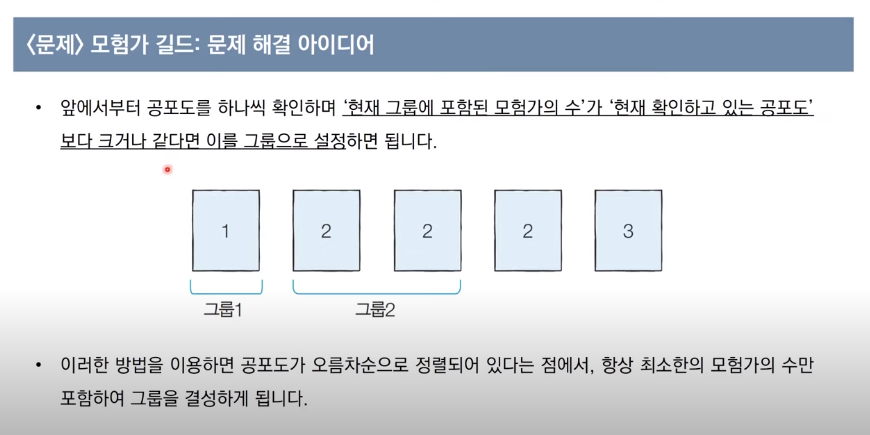
<문제> 모험가 길드: 문제 설명

<문제> 모험가 길드: 문제 설명
- 예를 들어 N = 5이고, 각 모험가의 공포도가 다음과 같다고 가정하겠습니다.
2,3,1,2,2
- 이 경우 그룹 1에 공포도가 1,2,3인 모험가를 한 명씩 넣고, 그룹 2에 공포도가 2인 남은 두명을 넣게 되면 총 2개의 그룹을 만들 수 있습니다.
- 또한 몇 명의 모험가는 마을에 그대로 남아 있어도 되기 때문에, 모든 모험가를 특정한 그룹에 넣을 필요는 없습니다.
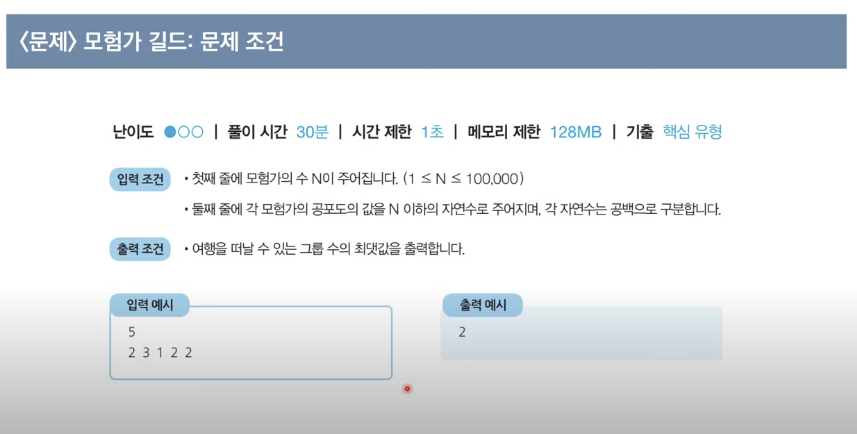

import sys
data = list(map(int, sys.stdin.readline().rstrip().split()))
data.sort()
groups = 0 # 총 그룹의 수
group_member = 0 # 현재 그룹에 포함된 모험가의 수
for volatility_index in data: # 공포도를 낮은 것부터 하나씩 확인하며
group_member +=1 # 현재 그룹에 해당 모험가를 포함시키기
if group_member >= volatility_index: # 현재 그룹에 포함된 모험가의 수가 현재 공포도 이상이라면, 그룹 결성
groups += 1 # 총 그룹의 수 증가 시키기
group_member = 0 # 현재 그룹에 포함된 모험가의 수 초기화
print(groups)
입력 조건을 통해서 그룹은 최소 1명이상은 된다는거에요.
정렬된 리스트 변수 data에서 예) [1,2,2,2,3]에서 지역 변수 i에 대입해서 루프가 돌아가요.
count는 그룹에 모험가를 포함시킨다고 했으니깐.
공포도가 1인 모험가는 조건문에 진입하기전 포함됩니다.
조건문에서는 count(그룹에 포함된 모험가<공포도1> 인원 수) 가 i보다 이상이면 분기가 정상적으로 돌아가도록 했는데요.
여기서 i는 공포도입니다.
다시 한번 더 count는 현재 그룹에 포함된 모험가의 수 V.S. 현재 모험가의 공포도를 비교합니다.
A >= B와 같은 구조적 상황이면 당근 분기문안으로 빠져 들어갑니다.
들어간다고 치면 result가 1이 증가하는데요. 여기서 result변수는 몇개 그룹인지 수를 알려줘요.
그런데 다음이 count=0으로 하네요? 중요한건 공포도와 그룹 형성의 상관관계입니다.
즉, 최대 많은 그룹을 만들어야하고 공포도가 작은 인원이 그룹을 만들기에 매우 좋다는 사실! 공포도가 1이면 그룹1개 만들어서 그냥 사냥하러 나가면 된다는 겁니다. 이런 구조적 상황을 더 설명하면 공포도가 100이면 그룹인원이 100명이 되어야 사냥하러 갈 수 있다는 말이 됩니다. 해당 그룹에 참여한 파티원 한명의 공포도 <= 현재 그룹인원수 헷갈리조?
만약 처음 공포도가 1인 사람이 나오고 두번째 인원이 100이라고 가정한다면 다음 인원은 100 이상이어야 합니다. 그래야 문제를 풀 수 있어요. 오름차순으로 정렬되어 있지 않으면 의도한 결과나 나타나지 않아요.
만약 정렬이 안되고 루프가 돌아간다면 예) 5,4,3,2,1의 경우 결과가 2가 나와요
논리적으로는 공포도가 5인 녀석은 반드시 5명이상만 꾸릴수 있고.
4인 녀석도 인원이 4명 이상만 가능하고
3도, 2도, 1도. 동일합니다. 그래서 논리적으로는 팀은 1개팀만 가능해요. (5,4,3,2,1) 또는 (4,3,2,1), 또는 (3,2,1) 또는 (2,1) 또는 (1,) 그런데 막상 오름차순으로 정렬하지 않고 내림차순으로 하게되면 팀이 2개가 됩니다.
구현


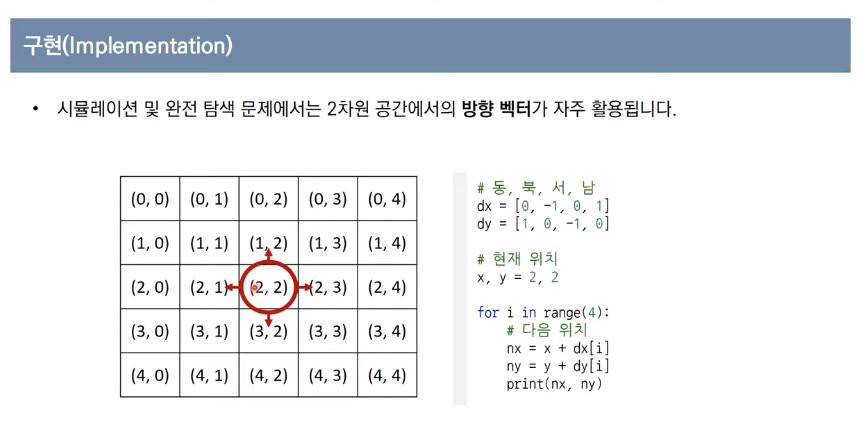
<문제> 상하좌우 :문제설명

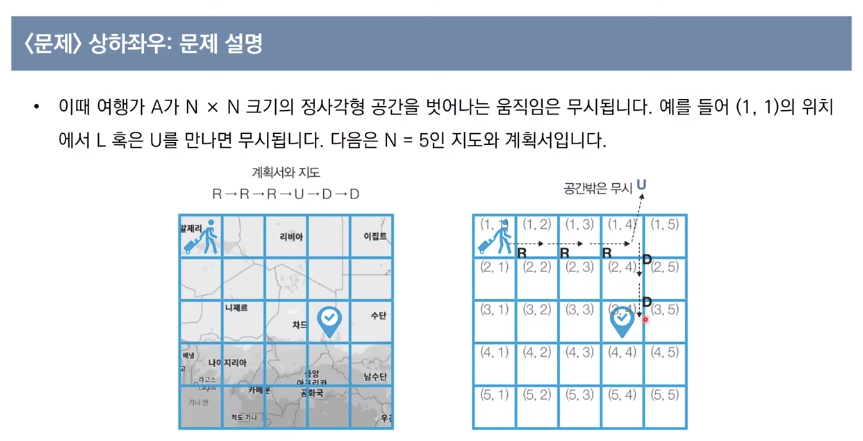
<문제> 상하좌우 :문제 해결 아이디어

<문제> 상하좌우 : 정답
n = int(input())
x, y = 1, 1 # 첫 출발 좌표
plans = input().split()
# L, R, U, D에 따른 이동 방향
dx = [0,0,-1,1]
dy = [-1,1,0,0]
move_types = ['L', 'R', 'U', 'D']
# 이동 계획을 하나씩 확인
for plan in plans:
# 이동후 좌표 구하기
for i in range(len(move_types)):
if plan == move_types[i]:
nx = x + dx[i]
ny = y + dy[i]
# 공간을 벗어나는 경우 무시
if nx <1 or ny < 1 or nx > n or ny > n:
continue
# 이동 수행
x, y = nx, ny
print(x, y)시각 : 문제 설명

시각 : 문제 조건
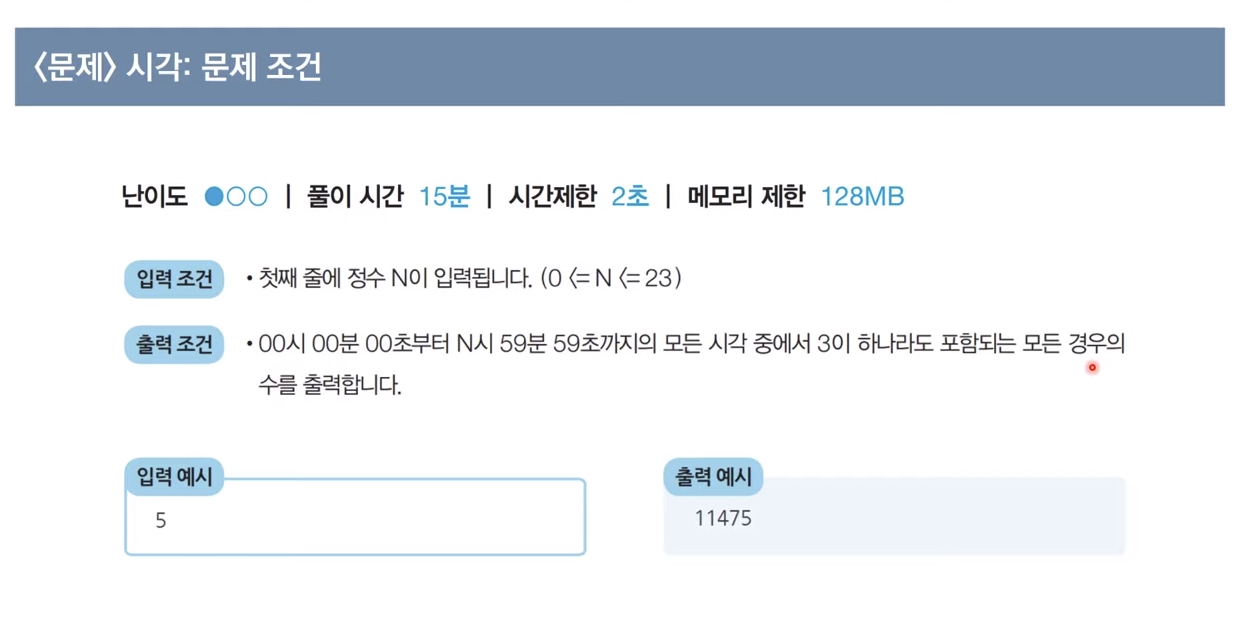
# H 입력 받기
h = int(input())
count = 0
for i in range(h+1): 시간을 의미함
for j in range(60):
for k in range(60):
# 매 시각 안에 '3'이 포함되어 있다면 카운트 증가
if '3' in str(i)+str(j)+str(k):
count+=1
print(count)
왕실의 나이트 : 문제 설명


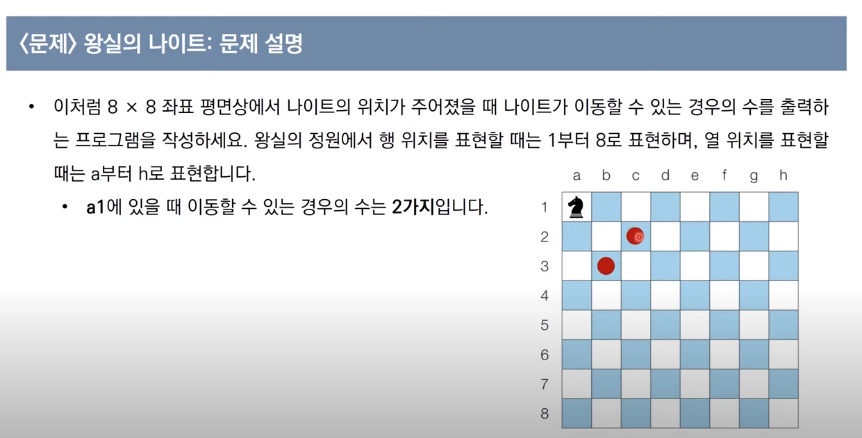
왕실의 나이트 :문제 조건
왕실의 나이트 : 문제 해결 아이디어
참고로 벡터란? (화살표로 그려지는)벡터에는 크기(화살표의 길이)와 방향(화살표가 가리키는 방향)이 있습니다.


참고로 벡터란? (화살표로 그려지는)벡터에는 크기(화살표의 길이)와 방향(화살표가 가리키는 방향)이 있습니다.
왕실의 나이트 : 파이썬 답안
input_data = input() # ex 'a1'
row= int(input_data[1]) # 'a1' -> '1' -> 1 현재 나이트의 로우 위치 문자를 정수로 바꿈
column= ord(input_data[0]) - ord('a') + 1 #
# input_data[0]은 'a' 알파벳인 컬럼을 의미
# 그 알파벳이 ord() 메서드를 통해서 유니코드 문자를 대표하는 정수를 반환함
# 예 'a' -> 97 반환
# 정리하면 문자 a를 유니코드함수에 집어 넣으면 정수 97을 반환함.
# 이후 97- 고정된 문자'a'의 유니코드 반환 정수를 빼면 당근 97-97 이므로 0이된다.
# 그런데 뒤에 1을 넣었으므로 결과적으로 문자를 입력한 'a1'은 정수 1로 컬럼위치를 확인 할 수 있게 된다.
# 즉 a~h로 문자로 표기된 것을 십진수 숫자로 최종적으로 계산하기 위한 방법임.
# 나이트가 이동할 수 있는 8가지 방향 정의
# 만약 'a1'을 입력하면 -> (1,1)
steps=[
(-2, -1),
(-1, -2),
(1, -2),
(2, -1),
(2, 1),
(1, 2),
(-1, 2),
(-2, 1),
]
# 8가지 방향에 대하여 각 위치로 이동이 가능한지 확인
result = 0
for step in steps:
# 이동하고자 하는 위치 확인
next_row = row + step[0]
next_column = column + step[1]
# 해당 위치로 이동이 가능하다면 카운트 증가
if next_row >= 1 and next_row <=8 and next_column >=1 and next_column <=8:
result += 1
print(result)
왕실의 나이트 키포인트
- 하나, 나이트가 이동하는 상대 좌표를 이해해야함
> (x,y) == (row, column)으로 표기한다는 기본 전제- 말의 현재 위치는 (x,y)
- 8번 : 왼쪽 2칸, x축에서 왼쪽으로 2칸, 말의 위치는
(x-2,y)가 됨 더불어!! 위로 1칸 올라가면 결론적으로 ->(x-2, y+1)변화되는 값을 보면 결국(-2, +1) - 7번 : x축에서 왼쪽으로 1칸, 말의 위치는
(x-1,y)가 됨 더불어!! 아래로 1칸 내려 가면 결론적으로 ->(x-2, y+1)변화되는 값을 보면 결국(-2, -1) - 6번 :
(-1, -2) - 5번 :
(1, -2) - 4번 :
(2, -1) - 3번 :
(2, 1) - 2번 :
(1, 2) - 1번 :
(-1, 2)
이렇게 상대적으로 말이 움직일 수 좌표의 가능성이 됩니다.
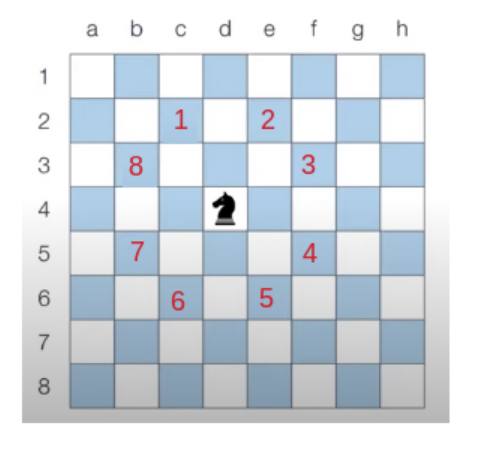
하지만 그 가능성도 실제적인 8*8 이라는 공간에서 제한을 받조?
- 둘, 행렬 좌표를 여기서는 1~8, a~8의 좌표로 8*8의 평면위에 나타나 있고 문자로 표기된 열을 아예 정수로 바꿀수 있도록 해야한다는점. 여기서는 유니코드를 정수로 반환하는 ord()메서드를 사용하였다는 점!
<문제> 문자열 재정렬 : 문제 설명

문자열 재정렬 : 문제 조건
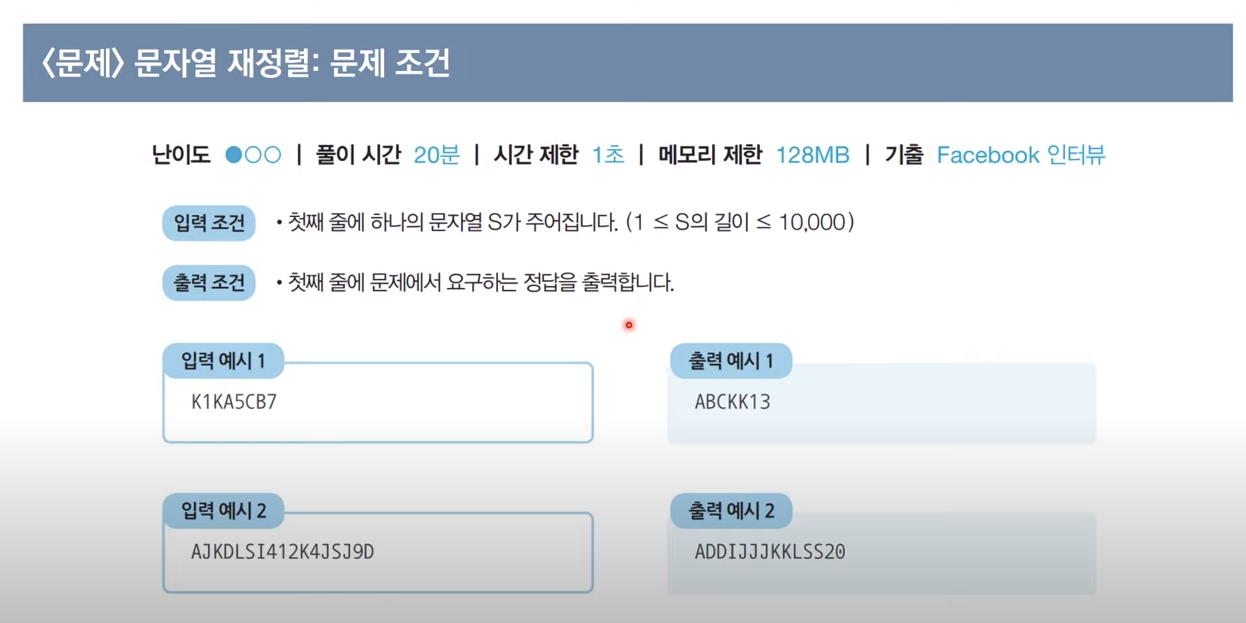
문자열 재정렬 : 문제 해결 아이디어

data = input()
result = [] # 알파벳을 담을 리스트 변수
value = 0 # 숫자를 총 합산해서 반환 할 변수
# 문자를 하나씩 확인
for x in data:
# 알파벳인 경우 결과 리스트에 삽입
if x.isalpha():
result.append(x)
# 숫자는 따로 더함
else:
value += int(x)
# 알파벳을 오름차순으로 정렬
result.sort()
# 숫자가 하나라도 존재하는 경우 가장 뒤에 삽입
if value !=0
result.append(str(value))
# 최종 결과 출력(리스트를 문자열로 변환하여 출력)
print(''.join(resut))
