
기본 개념 정리
transformer: 2017 년 구글에서 발표한 논문 “Attention is all you need”에서 나온 모델로 인코더-디코더의 구조를 따르면서 어텐션 만으로 nlp에서 우수한 성능을 보여주었다
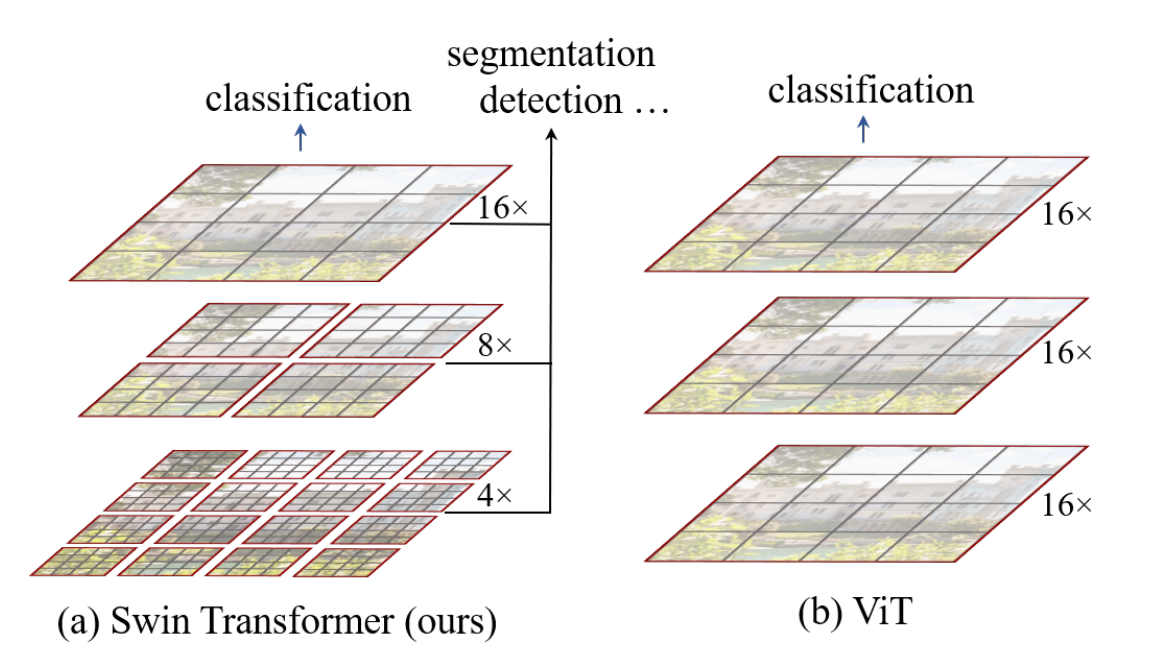
vision transformer: 자연어 처리 모델인 transformer를 이미지 처리에 적용한 모델로 cnn에 의존하지 않고 이미지 패치의 시퀀스를 입력값으로 사용하여 transformer의 Encoder를 그대로 가져와 좋은 성능을 보여주었다
swin transformer: swin은 shifted windows를 말하고 transformer를 비전 분야에 적용하여 계층적 피쳐맵과 윈도우 베이스드 셀프 어텐션이 특징이다
shifted windows: 다음 스테이지로 이동할때 로컬 윈도우가 이동하는것을 말하는데 이동한 만큼의 윈도우로 셀프 어텐션 연산을 진행해 스윈모델의 성능을 높여줬다
attention: 사람이 사물을 볼때 초점이 맞아서 보고자하는 영역에 높은 집중도를 보여 고화질을 유지하고 보지 않는 다는 것에 대해선 저화질로 낮은 집중도를 유지하는데 이를 인공신경망에서 구현을 한게 어텐션 기법이고 가중치와 달리 전체 또는 특정 영역에 입력값을 반영해 그 중에 어디에 집중해야하는지를 목표로 한다
self attention: 쿼리, 키, 밸류 3개 요소 사이의 문맥적 관계성을 추출하는 과정이다
multi-head self attention: self attention처럼 쿼리 키 밸류의 문맥적 관계성을 추출하지만 동시에 병렬적으로 구하는 방법이다
1. Transformer 구조
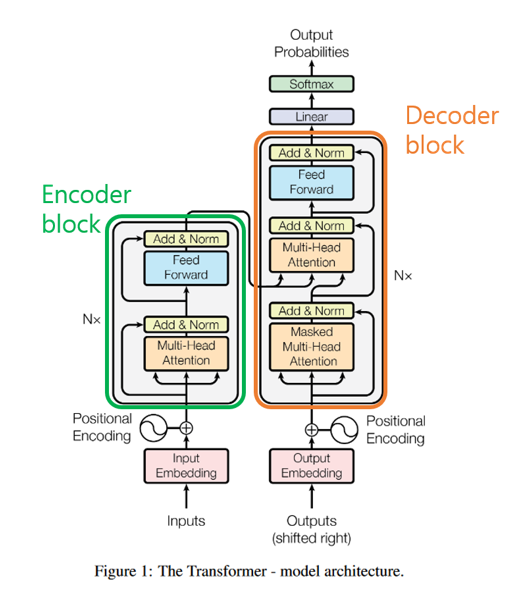
Encoder
- Encoder block에 입력은 인풋 임베딩에 위치정보(positional encoding)를 더해서 만들고 이는 nlp에서 해당 토큰이 몇 번째 위치인지 정보를 나타냄
- 트랜스포머 모델은 위 방법처럼 소스언어에 토큰 수열을 벡터 수열로 변환해 인코더 입력을 만듦(디코더 입력도 거의 비슷함)
- 인코더 입력층에서 만들어진 벡터 수열이 인코더 블록의 입력이 되고 출력 벡터 수열이 두 번째 인코더 블록의 입력이 되며 이를 Nx번 반복함
출력층
- 출력층의 입력은 Decoder 마지막 블록의 출력 벡터 시퀀스이고 출력층의 출력은 디코더 마지막 블록의 출력 수열임
- 출력층의 출력은 언어 수 만큼의 차원을 갖는 확률 벡터가 됨
⇒ 트랜스포머의 학습은 인코더와 디코더 입력이 주어졌을 때 모델 최종 출력에서 정답에 해당하는 단어의 확률값을 높이는 방식으로 수행됨
2. Self attention 연산
- 셀프 어텐션은 트랜스포머의 인코더와 디코더 블록 모두에서 수행됨
- 쿼리, 키, 밸류 3개 요소 사이의 문맥적 관계성을 추출하는 과정
- 쿼리, 키, 밸류 만들기
- 입력 벡터 수열에 쿼리, 키, 벨류를 만들어주는 행렬곱하여 각각의 행렬을 만들고 이는 태스크를 가장 잘 수행하는 방향으로 학습이 업데이트됨
- 쿼리의 셀프 어텐션 출력값 계산
- 쿼리와 키를 행렬곱한 뒤 해당 행렬의 모든 요소값을 키 차원수의 제곱근 값으로 나눠주고 이 행렬을 행 단위로 소프트맥스를 취해 스코어 행렬을 만들어줌
- 그 다음 스코어 행렬에 V를 행렬곱해줘서 셀프 어텐션 계산을 마침
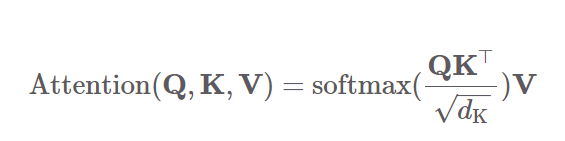
3. Swin transformer의 Motivation
Attention 방법이 인풋 값의 관계들을 고려하기 때문에 기존 cnn 모델에서 멀리 있는 픽셀간의 정보 추출이 어렵다는 한계로 비전 테스크를 트렌스포머에 적용하는 연구가 활발히 진행되었다
이미지를 self attention에 적용할 경우 이미지 내 하나의 패치가 다른 패치들 간의 관계를 계산하는건데 이미지 크기에 따라 연산량이 정해져 있어 사이즈가 크면 연산이 거의 불가능했다
이때, 논문에서는 윈도우 방법을 제시했다
4. Swin transformer 구조
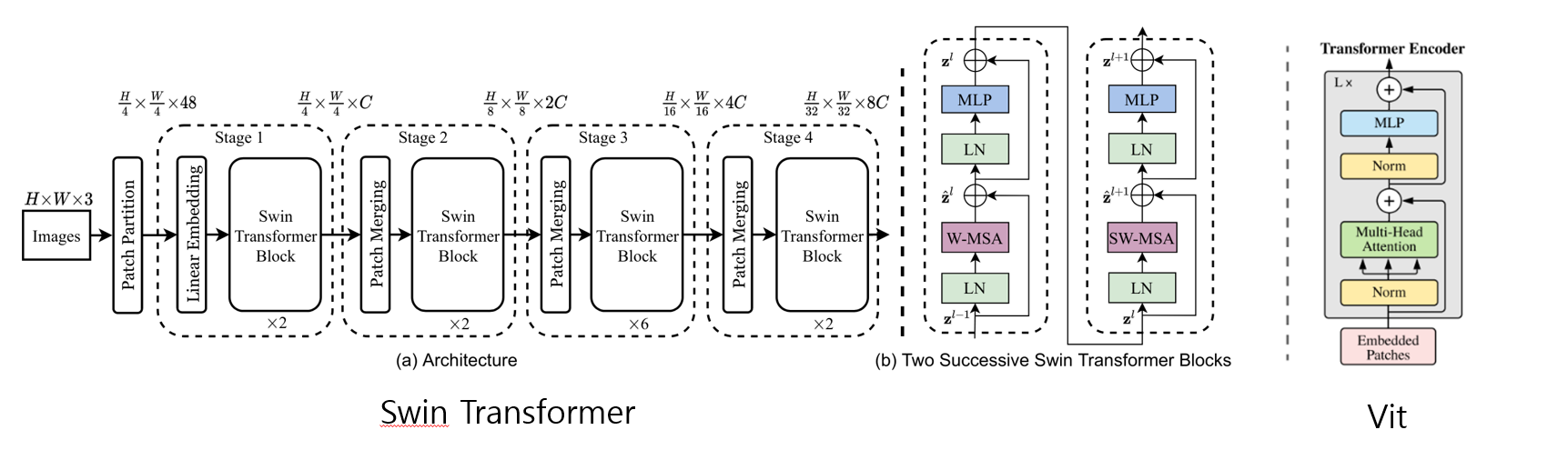
Patch partition
- rgb 이미지를 여러 패치로 나누어주는 기능(문장 기준으로 토큰)
- 위 표에서는 패치는 이미지의 높이와 폭을 4로 나눈 값이고 차원이 4(높이)4(폭)3(채널)이라서 48이 됨
- stage 1에 들어가면서 선형 임베딩 과정을 거치게 되고 그 이후에는 사용자가 정의한 채널값으로 변경해줌
Swin transformer block
- 패치는 회색선, 윈도우는 빨간선이고 윈도우 내에(빨간선 안) 존재하는 패치들만 어텐션 스코어를 계산함
- vision transformer(vit)와 비교했을때 이미지 사이즈가 크기 때문에 엄청난 계산량 증가를 보임
- vit는 멀티헤드 어텐션을 사용했고 swin은 멀티헤드 어텐션 자리에 윈도우 베이스드 셀프어텐션(W-MSA), 쉬프티드 윈도우 셀프 어텐션(SW-MSA)으로 수정하여 블록을 구성
- vit는 높은 계산량을 가진 반면 윈도우 베이스드 msa는 선형적인 계산량을 가짐
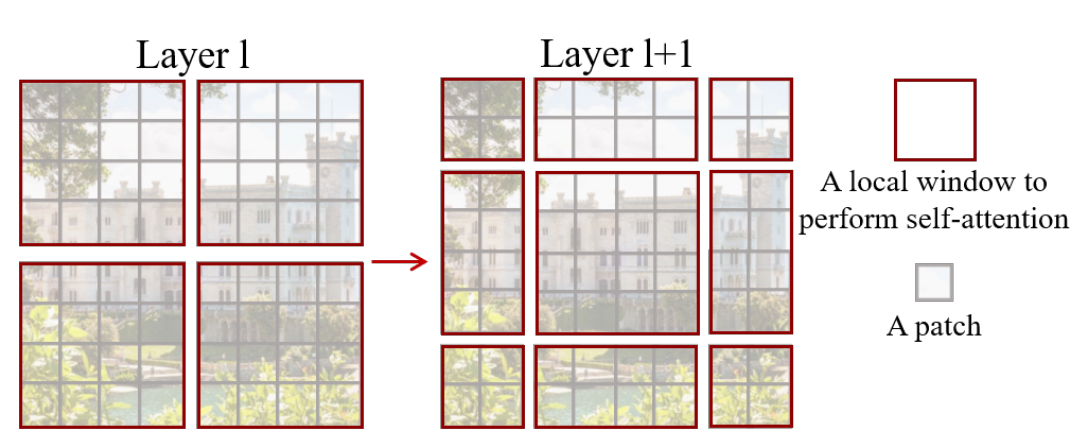
- 위의 swin이미지를 보면 레이어가 깊어질수록(다음 stage로 갈수록) 패치들이 멀지됨
W-msa와 SW-msa 설명
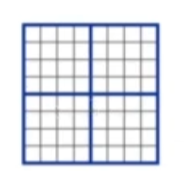
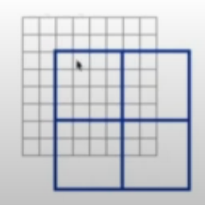
- w-msa에서 4개의 윈도우(파랑 박스)를 만들고 다음 sw-msa에서 위 이미지처럼 이동하는데 이는 매 stage마다 다른 패치들과 윈도우 사이의 연결성을 나타내기 위해서
- swin-t는 윈도우 내 패치들만 계산하기 때문에 이동한 윈도우들(오른쪽 이미지)이 정사각형태가 아니라서 연산량이 크게 증가하지 않는 방법으로 m*m형태로 만드는 방법이 필요함
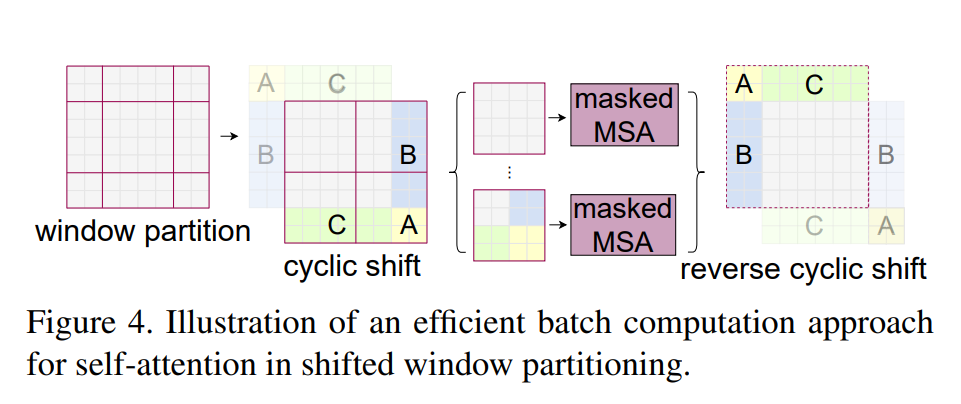
그래서, cyclic-shift라는 방법을 제안
- 기존 윈도우 크기보다 작은 서브 윈도우들을 이동시켜서 윈도우 크기에 맞도록 합친뒤 셀프 어텐션을 계산하는 방법(abc 영역을 붙여서 윈도우 크기를 유지함)
- 이때, 마스킹 기법을 이용함, 쉬프트가 된 후 여러개의 서브 윈도우로 구성된 배치 윈도우의 경우 실제 인접하지 않기 때문에 해당 윈도우 내에 셀프 어텐션을 계산할때 마스킹 기법을 사용해서 개별적인 서브 윈도우에대해 어텐션 스코어를 계산할 수 있도록 함
5. swin-t,s,b,l 베리언트

- 채널과 블럭수가 다름
Swin transformer 요약
- shifted windows를 말하며 swin transformer는 nlp분야에서 많이 쓰이는 트랜스포머를 비전 분야에 적용한 모델로 계층적 피쳐맵과 윈도우 베이스드 셀프 어텐션이 특징이다
- swin transformer는 구글에서 제안한 vision transformer의 문제점을 개선한 모델이다
- 논문에서 제안한 swin transformer 구조
- patch partition(+embedding) > swin transformer block > patch merging > swin transformer block
- 즉, 트렌스포머 블럭과 패치 머징이 반복되어지는 구조
- 장점: 최신 모델이며 정확도가 높고 업계에서 소타 모델로 분류된다. detection, segmentation에 강함, 트렌스포머 모델 기반인데 빠른편
- 단점: 코코 seg 성능이 잘 나온건 swin L + HTC 모델인데 공개 안됬고 cascaded mask r-cnn 모델만 공개, 트렌스포머 계열은 학습이 오래걸림
참고 자료
논문:https://arxiv.org/pdf/2103.14030v2.pdf
논문 한글 설명: https://sungminlee0810.github.io/paper_review/instance_segmentation/transformer/tech-post/
swin 학습과정 블로그: https://velog.io/@khjgmdwns/series/SwinTransformer-Swin-Object-Detection
