
분석하기 좋은 데이터란?
- tidy data(깔끔한 데이터)를 각 변수가 열이고 각 관측치가 행이 되도록 배열된 데이터로 정의
- 판다스는 tidy data를 만들기위해 melt라는 기능을 제공
- melt는 녹는다는 뜻을 가지고 있는데, 열에 있던 데이터를 행으로 녹인다고 생각하기
Concat
concatenation(연결의 의미)의 줄임말, 선택한 축(axis)방향으로 연결해주며 더한다, 붙인다의 의미로 생각하면됩니다.
concat 예시_인덱스가 같은 경우
import pandas as pd
#데이터 프레임 만들기
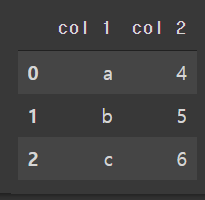
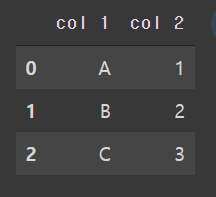
df1 = pd.DataFrame({'col 1': ['A', 'B', 'C'],
'col 2': ['1', '2', '3']})
df2 = pd.DataFrame({'col 1': ['a', 'b', 'c'],
'col 2': ['4', '5', '6']})만들어진 df1, df2 확인
#위/아래로 합치기(행기준)
pd.concat([df, df1], axis=0)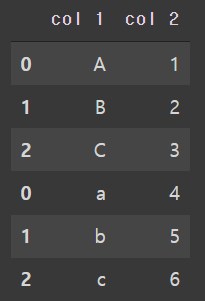
#옆으로 합치기(열기준)
pd.concat([df, df1], axis=1)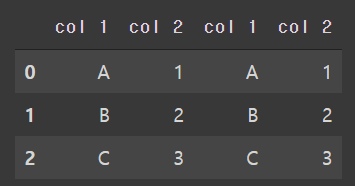
concat 예시_인덱스가 다른 경우
df2 = pd.DataFrame({'col 3': ['a', 'b', 'c'],
'col 4': ['4', '5', '6']})df2의 컬럼명을 col3, col4로 수정하여 concat함수를 적용해봤다.
#위/아래로 합치기(행기준)
pd.concat([df, df1], axis=0)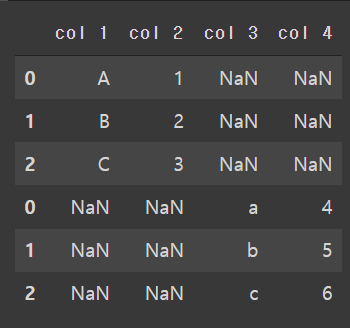
컬럼명이 달라 df1에 바로 붙지 않고 옆에 col3, col4가 컬럼으로 오고 아래로 합쳐진다. 그리고 비어있는 부분은 NaN값(결측치)값으로 채워진다.
#위/아래로 합치기(열기준)
pd.concat([df, df1], axis=1)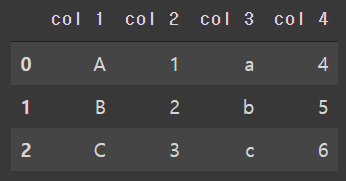
열기준으로 만들땐 이상없이 위와 동일하게 만들어지는 것으로 확인할 수 있다.
Merge
Merge는 Concat과 다르게 공통된 부분을 기반으로 합치는 용도로 사용됩니다.
방법: df.merge("붙일 내용", how = "(방법)", on ="(기준 feature)")
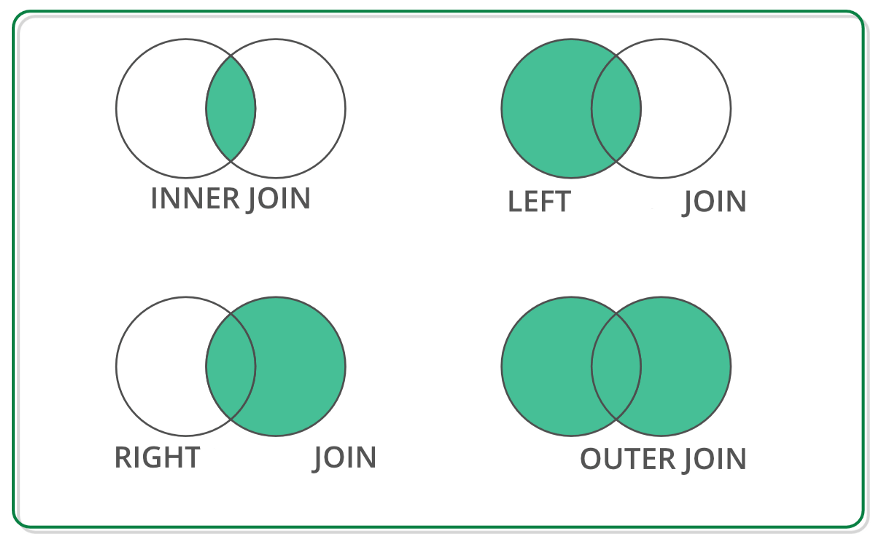 이미지 출처: https://medium.com/swlh/merging-dataframes-with-pandas-pd-merge-7764c7e2d46d
이미지 출처: https://medium.com/swlh/merging-dataframes-with-pandas-pd-merge-7764c7e2d46d
Merge 예시_data frame 만들기
#데이터프레임 만들기
df1 = pd.DataFrame({
'data1':range(6),
'key':list('aabbcc')
})
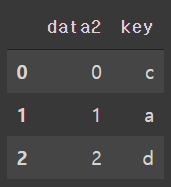
df2 = pd.DataFrame({
'data2':range(3),
'key':list('cad')
})각각의 df1,df2가 만들어졌다.
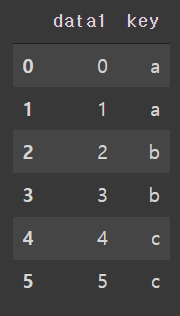
Merge innerjoin
#merge(how='inner')
pd.merge(df1, df2)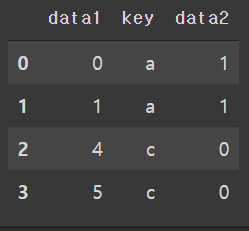
key의 공통된 부분인 a,c로 merge된것을 알수 있다.
Merge outerjoin
#merge(how='outer')
pd.merge(df1, df2, on='key', how='outer')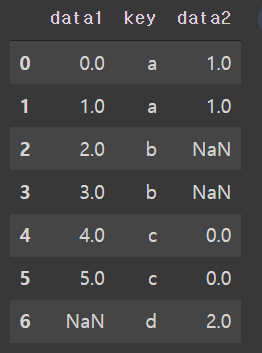
key의 a,b,c,d가 모두 들어간것을 확인할 수 있고 빈공간은 NaN으로 채워졌다.
Merge leftjoin
#merge(how='left')
pd.merge(df1, df2, on='key', how='left')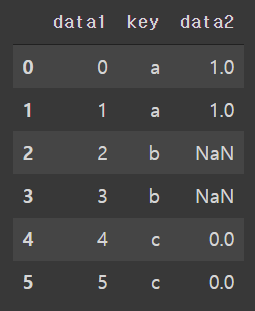
df1을 기준으로 join을 수행하고 df2의 키가 없으면 NaN으로 채워진다.
Merge rightjoin
#merge(how='right')
pd.merge(df1, df2, on='key', how='right')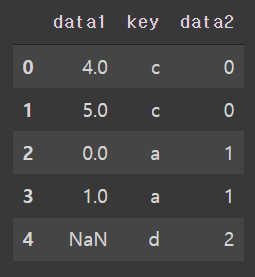
df2를 기준으로 join을 수행하고 df1의 키가 없으면 NaN으로 채워진다.
Condition_파이썬 조건문
숫자형 데이터를 conditioning
df1 = df[( (df['col'] > 0) & (df['col'] < 10))]*col이라는 컬럼에서 0보다 크고 10보다 작은 값 추출해서 df로 보여주기
범주형 데이터를 conditioning
df[df['col1'].isin(['col1에있는 특정 단어'])]
df[(df['col1'] == 'col1에있는 특정 단어')]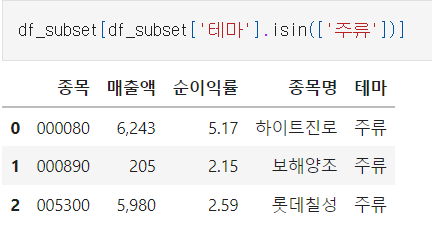
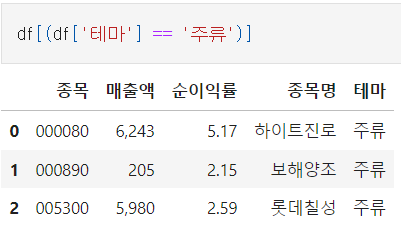
출처: 코드스테이츠 강의 노트
Tidy data
깔끔한 테이터, 전처리 시 표준화하기 위해 사용, Seaborn 라이브러리는 tidy data를 필요로함(항상 그렇진 않음)

이미지출처: https://r4ds.had.co.nz/tidy-data.html
3가지 규칙을 가짐
- 하나의 변수는 하나의 세로줄을 형성
- 하나의 관측치는 하나의 가로줄을 형성
- 하나의 변수의 종류별로 하나의 표를 형성

이미지 출처: https://hyunyulhenry.github.io/data_wrangling/tidyr%EC%9D%84-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%AA%A8%EC%96%91-%EB%B0%94%EA%BE%B8%EA%B8%B0.html
.melt()와 .pivot_table()를 사용해 tidy - wide 형태로 변환
Melt는 어떻게 데이터를 녹이는 걸까요?
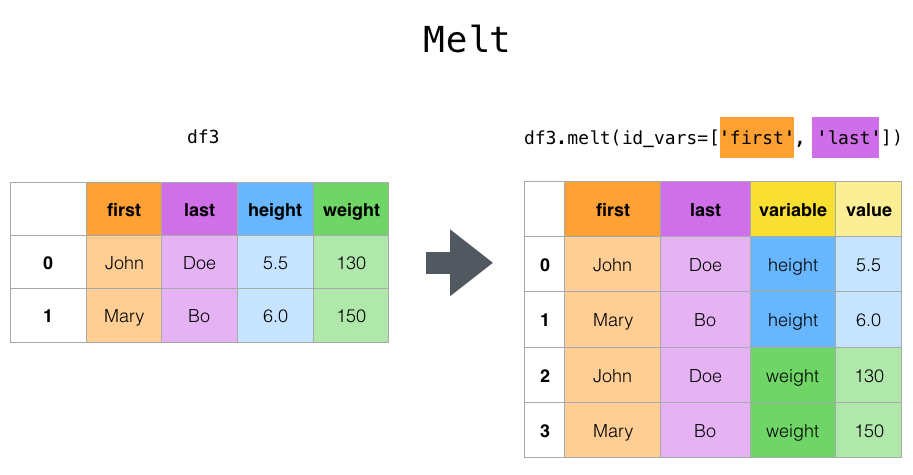 출처: 코드스테이츠 강의자료
출처: 코드스테이츠 강의자료
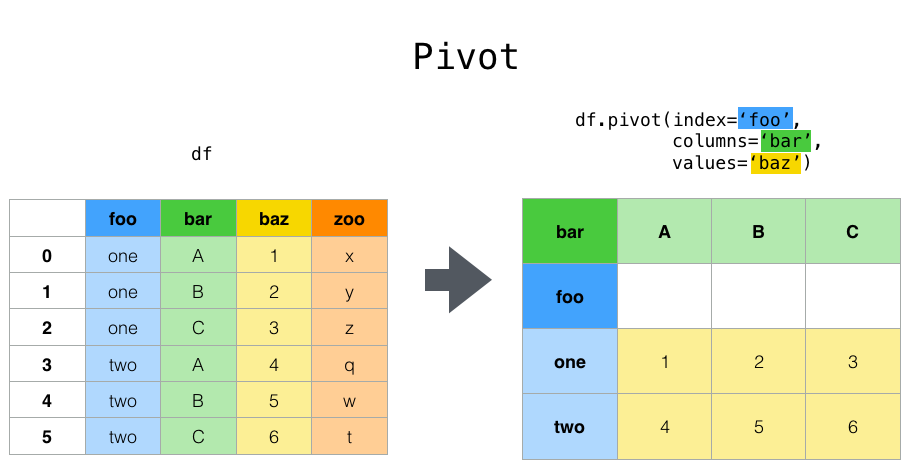
Pivot_table 함수는 melt와 반대 역할을 하는 함수
References

안녕하세요. 기억보다 기록을 믿는 레나입니다!