
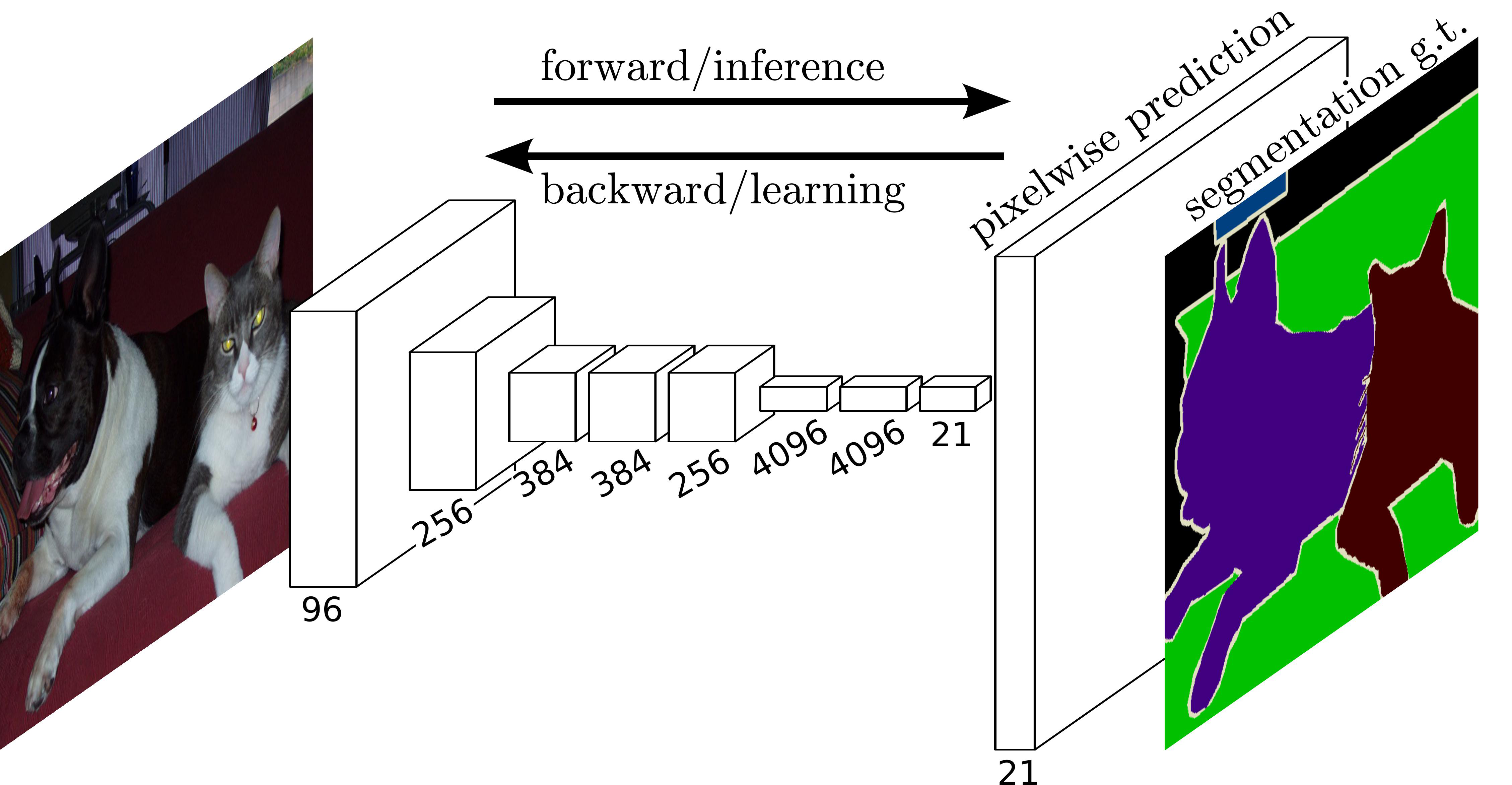
21이란 숫자는?
분류 클래스 수
Segmentation
- 하나의 이미지에서 같은 의미를 가지고 있는 부분을 구분해내는 task
예) 의료 이미지, 자율주행, 위성 및 항공 사진 - 이미지 분류엣는 이미지를 하나의 단위로 레이블을 에측했다면 segmentation은 더 낮은 단위로 분류
- 동일한 의미(사람, 자동차, 도로, 인도, 자연물등)마다 해당되는 픽셀이 모두 레이블링 되어 있는 데이터셋을 픽셀단위에서 레이블을 예측하게 됨
1. Semantic Segmentation
- 의미적 분할
- 의미적으로 사람으로 분류되는 개체에 대해 동일하게 라벨링을 해줌
- 이미지 내에서 물체들을 의미있는 단위로 분할
segmentic model
- FCN(Fully Convloutional Networks)
- cnn의 분류기 부분(=완전 연결 신경망)을 합성곱 층으로 대체한 모델
- (기존문제) segmentation은 픽셀 단위로 분류가 이루어지기 때문에 픽셀의 위치 정보를 끝까지 보존해줘야하는데 기존 CNN에서 사용하였던 완전 연결 신경망은 위치정보를 무시한다는 단점을 가짐
그래서, fcn에서는 이를"합성곱층으로 모두 대체함"으로써 문제를 해결함 - segmentation은 픽셀별로 분류를 진행하기 때문에 원래이미지와 비슷하게 크기를 키워주는 upsampling을 해주어야함
2. Instance segmentation
- 개체까지 분할
- 여러명의 사람이 있지만 각각은 다른 레이블로 분류됨
- 개체를 하나씩 구분해서 분류
Upsampling
우선, 다운샘플링부터
- Downsampling: Cnn에서 사용되는 것처럼 convolution과 pooling을 사용하여 이미지의 특징을 추출하는 과정
- upsampling은 transpose convolution이 적용됨
- transpose convolution에서는 각 픽셀에 커널을 곱한 값에 stride를 주어 나태냄으로써 이미지 크기를 키워 나감
- 겹치는 부분은 어떻게 계산할건지?=더해줌
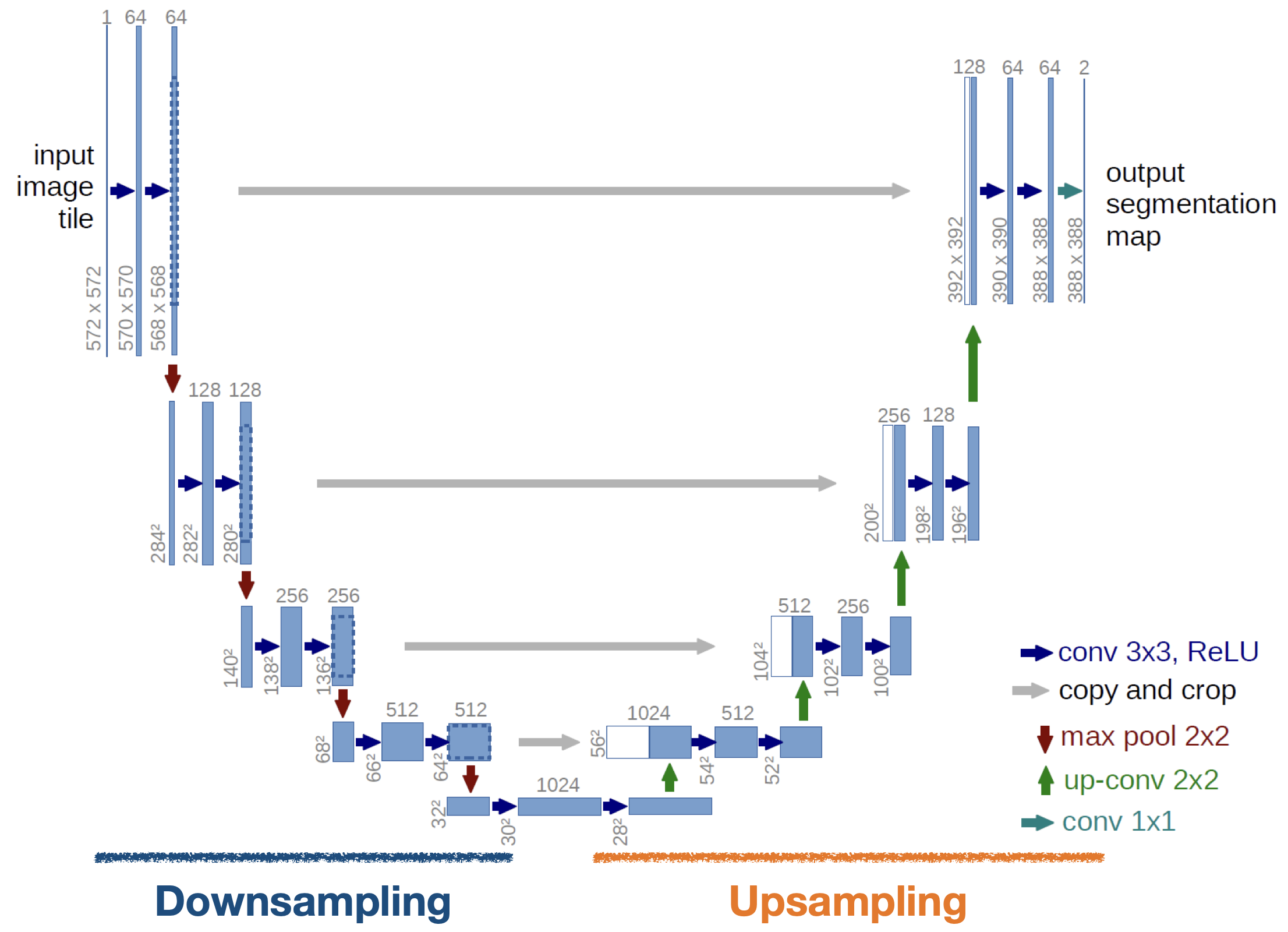
Unet
- 유넷 역시 다운샘플링과 업샘플링으로 나뉘고 다운샘플링에서는 컨볼류션과 맥스풀링을 거치면서 이미지의 특징을 추출하게 됨
- 업샘플링에서는 컨볼류션과 트랜포즈 컨볼류션을 거치면서 원본 이미지와 비슷한 크기로 복원
- 업샘플링에서 다운샘플링 출력으로 나왔던 핏쳐맵을 적당한 크기로 잘라서 붙여준 뒤 추가 데이터로 사용
- 핏쳐 맵을 업샘플링에 붙여 추가적인 데이터로 사용
출처: 코드스테이츠
왜 크기가 2씩 줄어들까?
유넷은 제로 패딩을 사용하지 않고 미러링 패딩을 사용하는데 그것은 이미지 크기를 보존해주지 않음
output segmentation map에서 마지막 숫자가 2인데 왜?
배경이랑 물제가 2개 밖에없다는 소리, 즉 클래스가 2개임
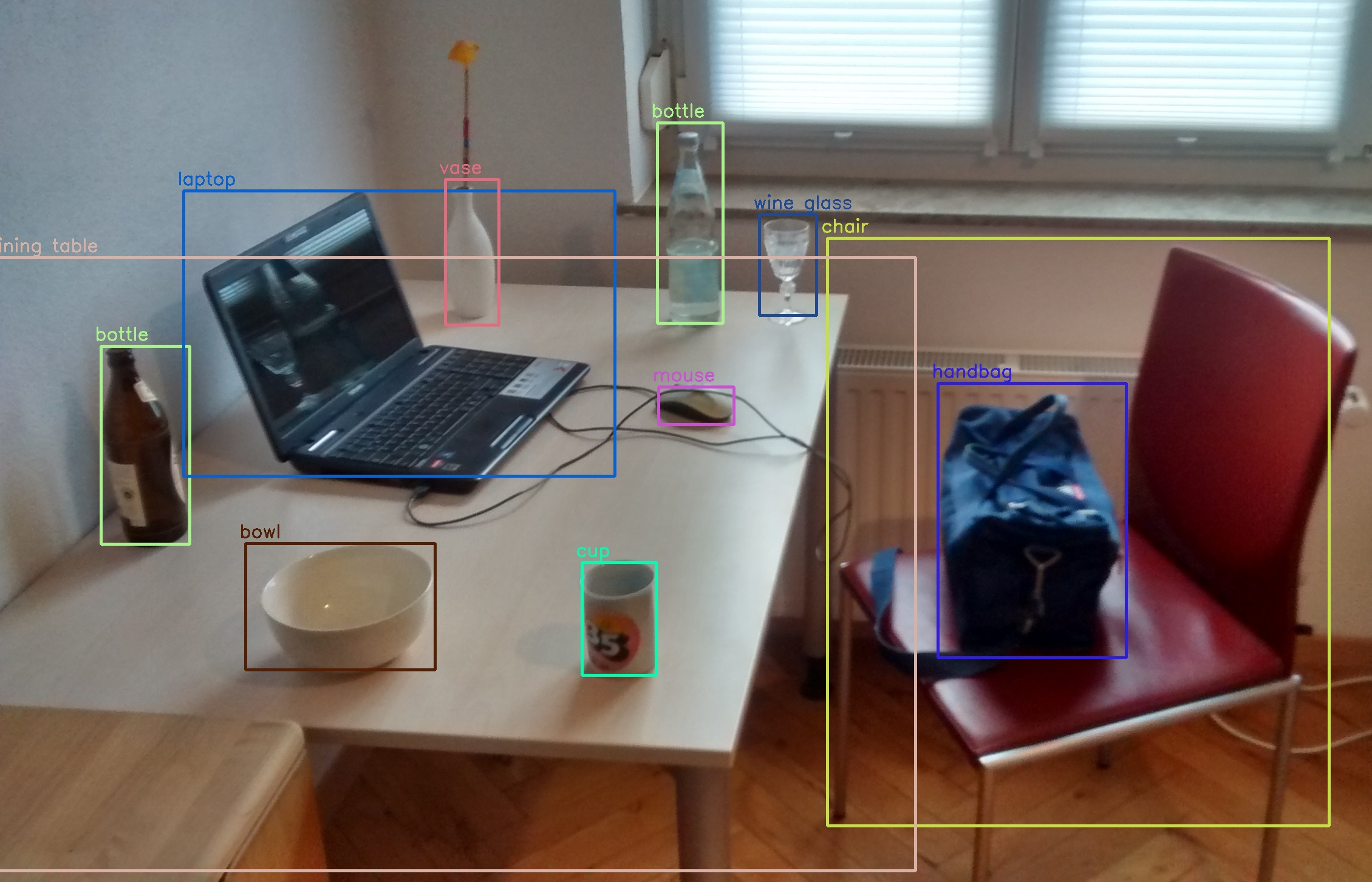
object detection/Recognition(객체 탐지/인식)
- 객체 탐지 인식은 전체 이미지에서 테이블에 맞는 객체를 찾아내는 테스크
출처: 코드 스테이츠
박스의 이름은? bounding box
즉, 바운딩 박스내에서 클래스가 무엇인지 찾아 내는 것
IOU(Intersection over union)
- Iou를 사용하면 객체가 포함되어 있지만 너무 큰 범위를 잡는 문제를 해결 할 수 있음
- Iou가 높을 수록 좋은 것
two stage detector
- 정확도가 상대적으로 좋음
- 일련의 알고리즘을 통해 객체가 있을 만한 곳을 추천받은 뒤에 추천받은 region 즉 rol(region of interest)에 대해 분류를 수행하는 방식
- RCNN, fast-r-cnn, faster-r-cnn
one stage detector
- 특정지역을 추천받지 않고 입력이미지를 grid등의 같은 작은 공간으로 나눈뒤 해당공간을 탐색하며 분류를 수행하는 방식
- ssd, yolo(you only look once)

안녕하세요. 기억보다 기록을 믿는 레나입니다!