
검색
- 특정 노드를 추가하거나 삭제를 위해서는 검색이 우선이 되어야함
- 다양한 알고리즘을 활용하는 경우, 최적 알고리즘 경로를 측정하는데 쓰임
- 검색하는 컬렉션이 무작위이고 정렬되지 않은 경우, 선형검색이 기본적인 검색 방법
재귀
- 재귀 호출은 스택의 개념이 적용되며, 함수의 내부는 스택처럼 관리됨(후입선출=LIFO)
- 단점: 재귀를 사용하면 함수를 반복적으로 호출된느 상황이 벌어져 메모리를 더 많이 사용하게됨
그래서, 수학적으로 개념이 복잡할 때 시간과 공간(메모리) 복잡도 측면에서 효율이 안좋더라도
재귀를 사용해 문제를 해결하는 것이 좋음
재귀로 문제 해결 방법
- 하위 문제를 쉽게 해결할 수 있을때까지 문제를 더 작은 하위 문제로 나누는 것을 의미
- 분할 정복법: 하나의 문제를 분할하면서 해결하고 해결 후 하나로 합치는 방법
- 재귀는 해결을 위한 특정 기능을 재호출, 분할정복은 문제를 분할하고 해결하는 구체적인 방법론
재귀의 조건
- base case(기본 케이스 또는 조건)가 있어야함
알고리즘은 특성상 반복을 중지할 수 있음
- 추가 조건과 기본 케이스의 차이를 확인
- 반드시 자기 자신(함수)를 호출해야 한다
트리
루트: 가장 위쪽에 있는 노드, 트리별 하나만 있음
(루트와 부모는 다름, 부모노드는 자식노드가 1개 이상 있는 경우에만 존재할 수 있음)
서브트리: 자식노드이면서 부모노드 역할을 하는 노드가 있는 트리
차수: 노드가 갖고 있는 최대 자식노드 수
리프: 레벨별로 가장 마지막에 있는 노드, 단말노드, 외부노드라고도 함
레벨: 루트노드에서 얼마나 멀리 떨어져 있는지 각각 나타낸다. 아래로 내려갈때마다 1씩 증가
높이: 루트에서 가장 멀리 떨어진 리프노드까지의 거리, 리프 레벨의 최대값을 높이라고 함
siblings노드: 부모가 같은 두 개의 노드
바이너리 트리(이진 트리)
- 이진트리는 노드별로 최대 2개의 서브노드를 가질수 있다
- 이진트리는 여러 트리종류 중에서 가장 기본이 되면서 많이 활용되는 트리
- 이진트리는 두가지 조건으로 구성되어 있음
->루트노드를 중심으로 두 개의 서브 트리로 나눠짐
->나눠진 두 서브트리도 모두 두 개의 서브트리를 가짐
--> 서브트리의 노드가 반드시 값을 가지고 있을 필요는 없음
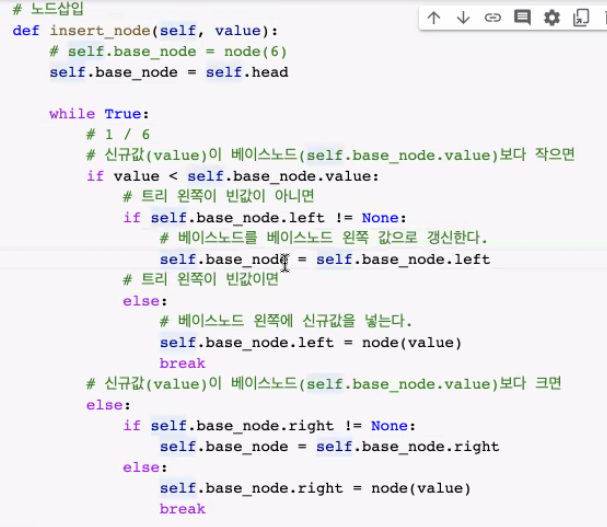
이진 검색 트리(Binary search trees)
- 노드를 정확하게 정렬해야하는 특정 유형의 이진트리
- 단순 이진트리보다 빠른 노드탐색이 목적, insert node에서 중복처리가 아닌 '값 크기 조건'에 맞게 값을 넣어주는 것
- 만약 '값 크기 조건'을 지키지 않고 값을 삽입하는 경우 '이진탐색트리'의 로직이 아닌 '단순이진트리'의
로직으로 '탐색'이 진행되므로 더 느린 탐색이 진행됨
-> 값 크기 조건
= 오른쪽 서브노드의 값>루트(부모)노드의 값>왼쪽 서브노드의 값
== 중복값을 갖고 있는 노드가 없어야함
== 왼쪽 서브트리노드들의 값은 루트(부모)노드값보다 작아야함
== 오른쪽 서브트리노드들의 값은 루트(부모)노드 값보다 커야함
-> 위의 규칙이 정해진 이유는 왼쪽부터 오른쪽으로 검색을 하는 구조이기때문에(연결리스트를 참조해 만들어진 개념이기 때문에)
->특징
= 구조가 단순, (base node, 검색할 노드, 자식노드 존재여부에 따라)검색되는 노드 순서가 달라짐
= 검색이 일반 이진트리보다 빠르기 때문에 노드를 삽입하기 쉬움

안녕하세요. 기억보다 기록을 믿는 레나입니다!