
EDA란? => 탐색적 데이터 분석
정의: 수집한 데이터가 들어왔을때, 이를 다양한 각도에서 관찰하고 이해하는 과정
HOW TO?
- 시각화같은 도구를 통해 패턴을 발견하기
- 데이터의 특이성을 확인
- 통계와 그래픽(or시각적표현)을 통해서 가설을 검정하는 과정
방법은?
- Graphic: 차트, 그림등을 이용해서
- Non Graphic: Summary Statistics를 통해서
데이터 오류를 찾아보자
1. Missing values
-결측치 데이터 삭제
# 결측값 행 전체 삭제 df.dropna(axis=0) # 결측값 열 전체 삭제 df.dropna(axis=0)-수동으로 입력
-전역변수(global constance='Unknown')
-결측값대체(imputation)
2. Noisy data
:잡음(noise)이란 측정된 변수에 무작위 오류(random error)또는 분산(variance)가 존재하는 것을 말함
-구간화(binning): 구간 평균 또는 평활화 방법을 통한 bucket을 적용
-단순 혹은 복합 회귀값을 적용
-군집화(clustering): 유사한 값들을 하나의 그룹으로 처리(이상치 발견하는데 이용됨)
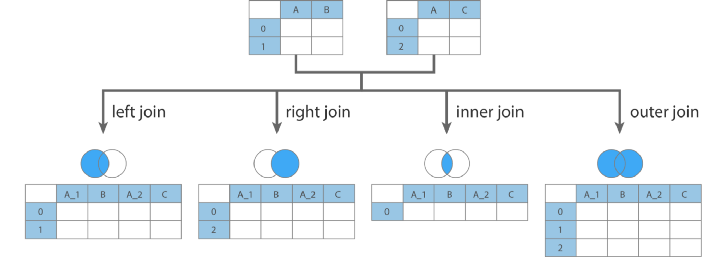
3. Integration
:여러개로 나누어져 있는 데이터들을 분석하기 편하게 하나로 합치는 과정
-merge
import pandas as pd DataFrame.merge(self, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)출처:https://ichi.pro/ko/python-pandas-dataframe-join-byeonghab-mich-yeongyeol-145789916147576
4. Transformation
:데이터의 형태를 변환
-정규화(normalize): scale을 일정하게 맞추어 overfitting을 방지import sklearn from sklearn.preprocessing import data=StandardScaler().fit_transform(data) print(data)데이터 분석을 할때 보면 두개의 컬럼이 각기 다른 규격으로 되어있을때 모델에 넣기 애매해질때가 있는데 그때 해당 컬럼들 0~1사의 값을 가질 수 있게 수정해서 사용한다
추가로, 이미지 데이터 정규화는 255로 나눠주면되는데 이는 색상 범위가 0~255로 구성 되어있기 때문!
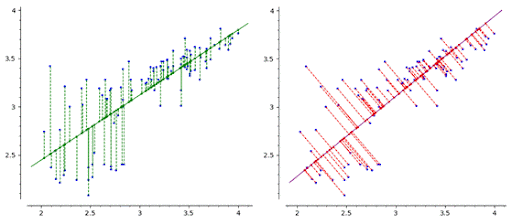
5. Reduction
-주성분분석(pca)
출처:http://matrix.skku.ac.kr/math4ai-intro/W12/
References
데이터 저장소
https://archive.ics.uci.edu/ml/index.php
추가 정리
- histogram(히스토그램), 분포와 중심경향을 알 수 있다
- Scatter plot(산점도) 두 연속형 변수의 관계를 알아볼 때 사용한다
- pie graph(원그래프) 집단별 표본을 그룹화하여 기술통계량을 확인할 때 유용하다
로컬파일 데이터셋 불러오기(CSV)
colab은 google drives를 파일 시스템으로 사용해서 파일 경로를 직접 사용할 수 없음
구글 코랩 파일 업로드 패키지 사용하면 간편하게 파일을 코렙으로 가져올 수 있다.
from google.colab import files uploaded = files.upload()
