0. 크롤링 코드에 s3에 저장하는 코드 추가하기
python에서 boto3을 import해서 s3에 파일을 저장하는 코드를 작성했다.
자세한건 깃허브 링크 참고
람다에 크롤링 코드 올리는 법은 블로그 글 참고
크롤링 코드 작성 방법은 불로그 참고
import boto3
# S3 설정
s3 = boto3.client('s3')
bucket_name = 'crawling-data-save' # S3 버킷 이름
file_name = f'dc/{today}_{target_time}.json' # S3에 저장될 파일 이름
def handler(event=None, context=None):
--크롤링 코드 생략--
# JSON 데이터를 S3에 저장
s3.put_object(
Bucket=bucket_name,
Key=file_name,
Body=json.dumps(result_data, ensure_ascii=False),
ContentType='application/json'
)
# 정상 작동 시 lambda에 200 전달
return {
"statusCode": 200,
"body": json.dumps({
"message": f"Crawling completed at {today+ ' ' + target_time + ':00'}",
"s3_file_name": file_name
}, ensure_ascii=False),}
# try로 크롤링 중이나 s3저장 중 에러 발생 시 lambda에 500 전달
except Exception as e:
driver.quit()
return {
"statusCode": 500,
"body": json.dumps({
"message": f"Crawling Failed at {today+ ' ' + target_time + ':00'}",
"error": str(e),
}),
}
if __name__ == '__main__':
handler()
1. s3 bucket 만들기 + 권한 설정
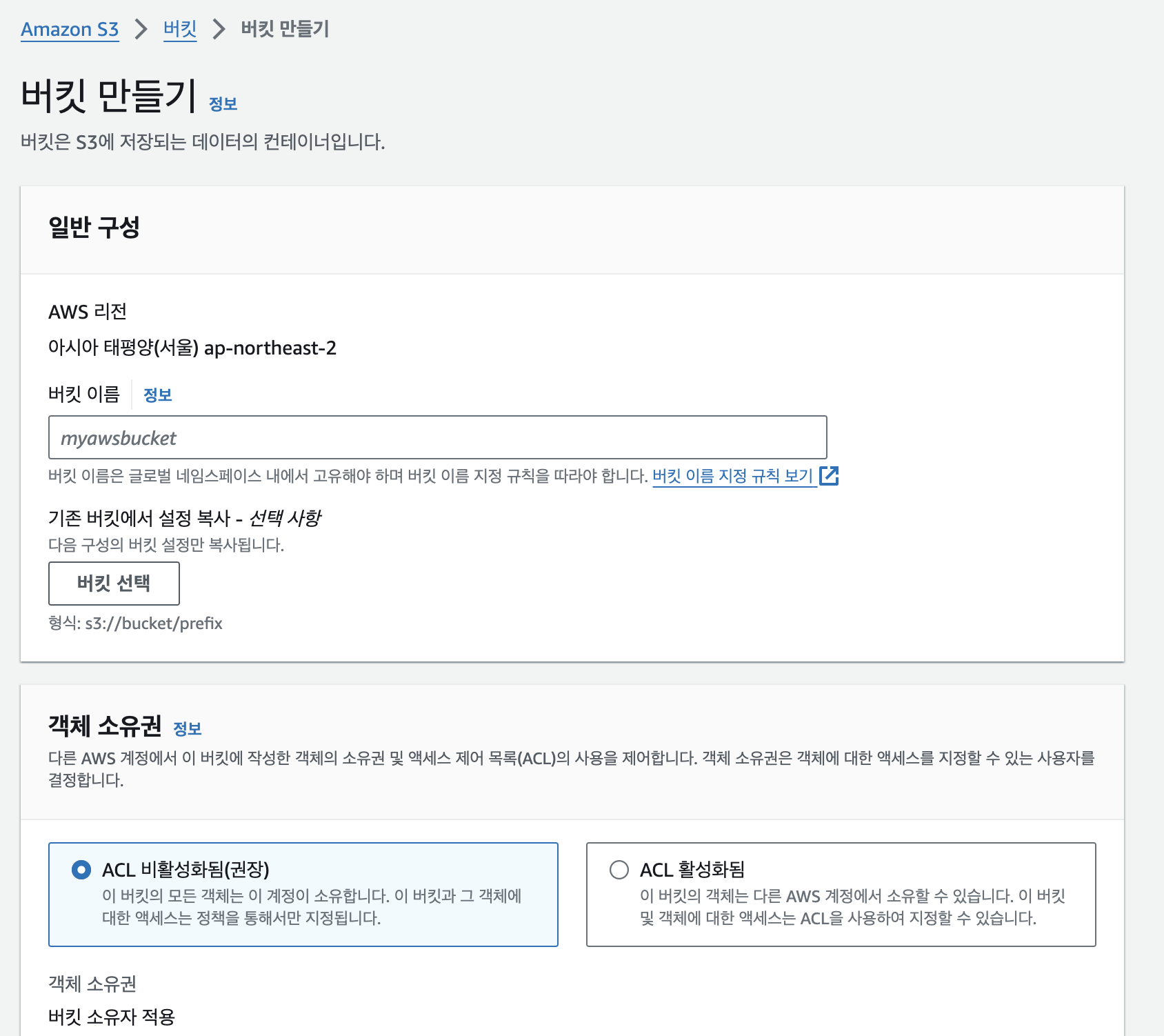
크롤링 한 데이터를 저장할 bucket을 하나 생성하고 lamda에서 접근 할 수 있도록
권한을 설정해야한다.
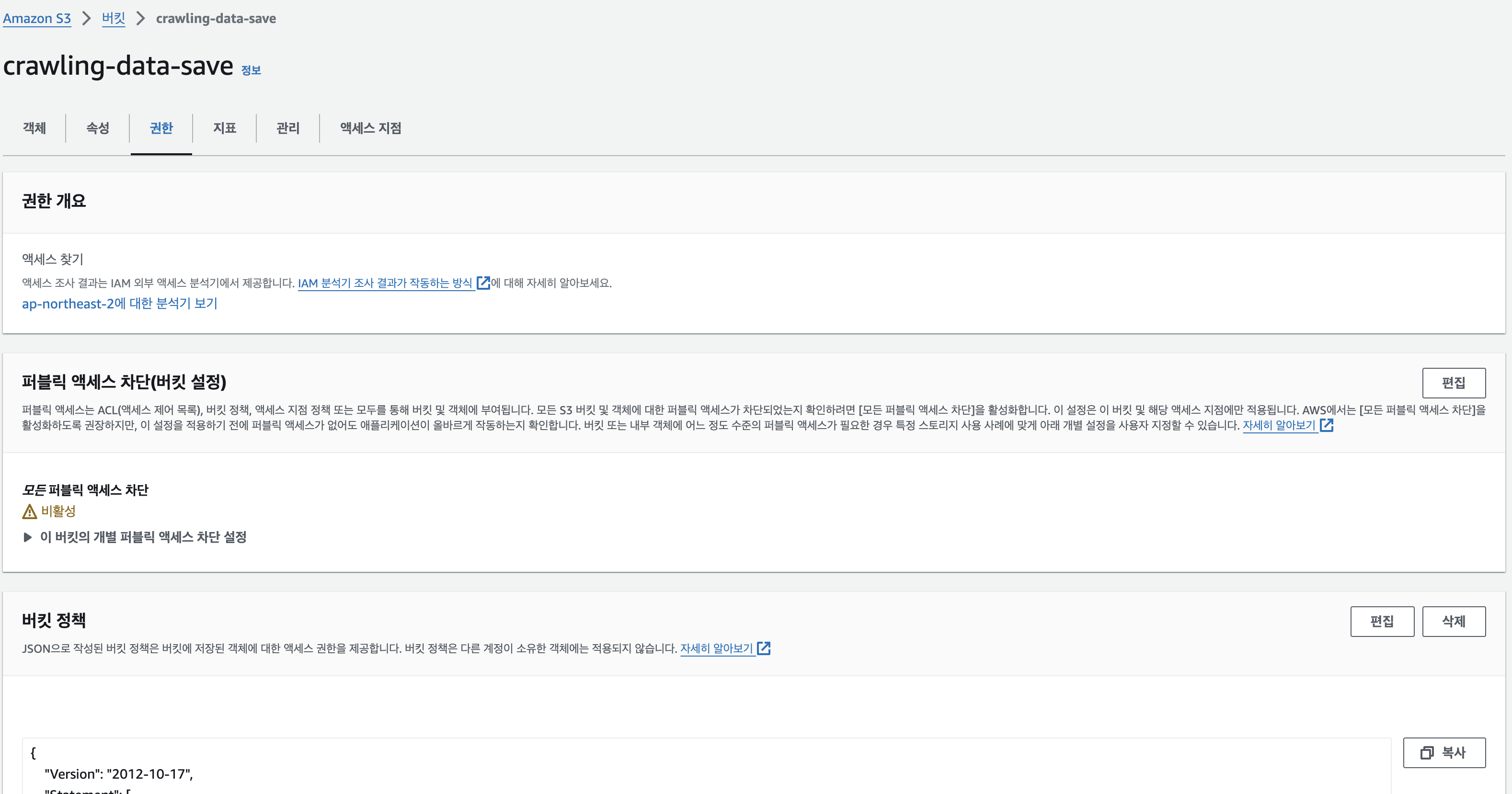
bucket 정책으로 들어가서 아래와 같이 전부 허용해 주었다.
(아래와 같이 설정 시 보안 상으로 취약하기 때문에 향후 필요한 액션에 대해서만 허락하도록 수정해야함)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:*",
"Resource": "arn:aws:s3:::crawling-data-save/*"
}
]
}2. lambda 권한 설정
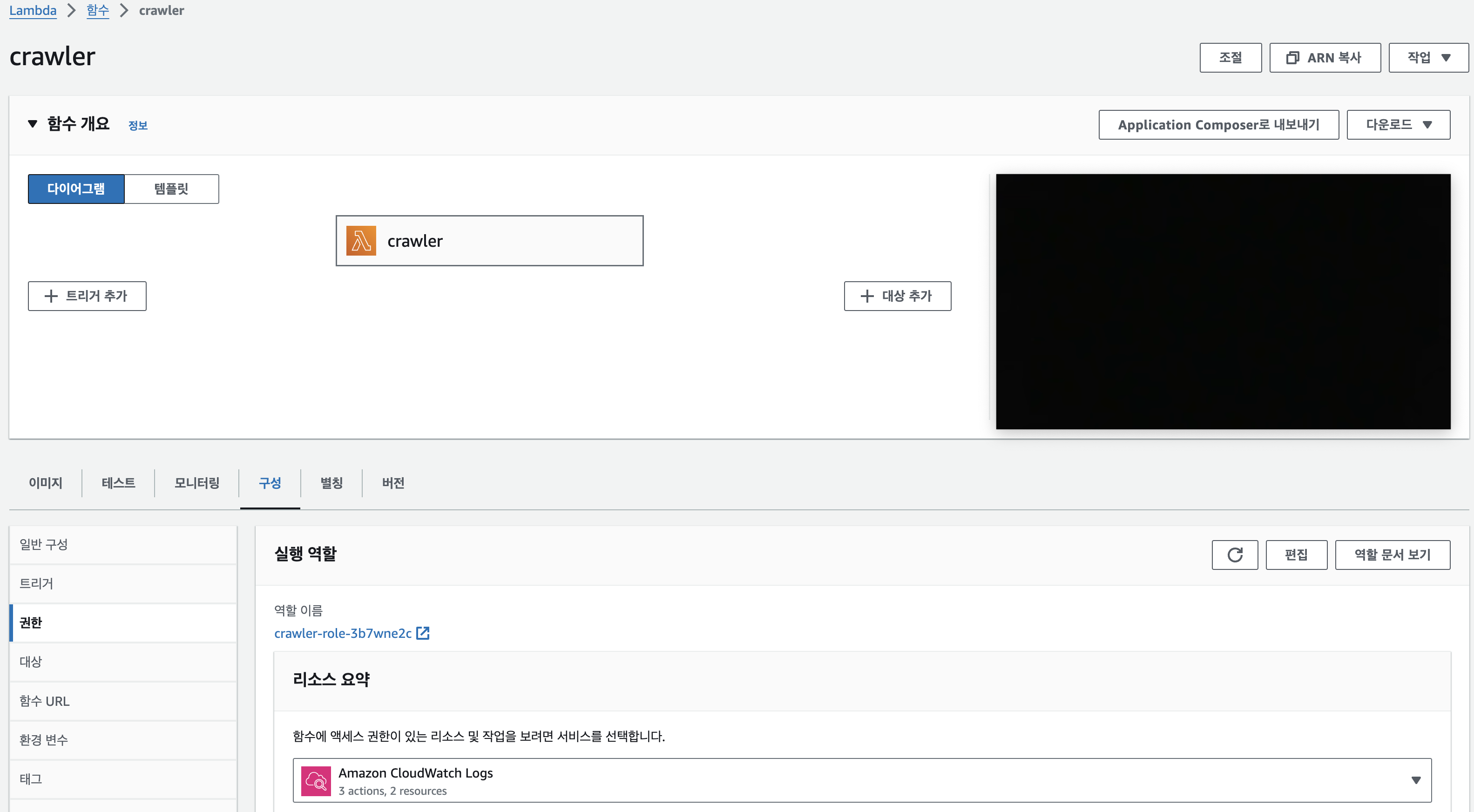
권한 창으로 들어가 설정된 역할 이름을 확인 후 aws lam에서 람다에 부여된 역할을 수정해준다.
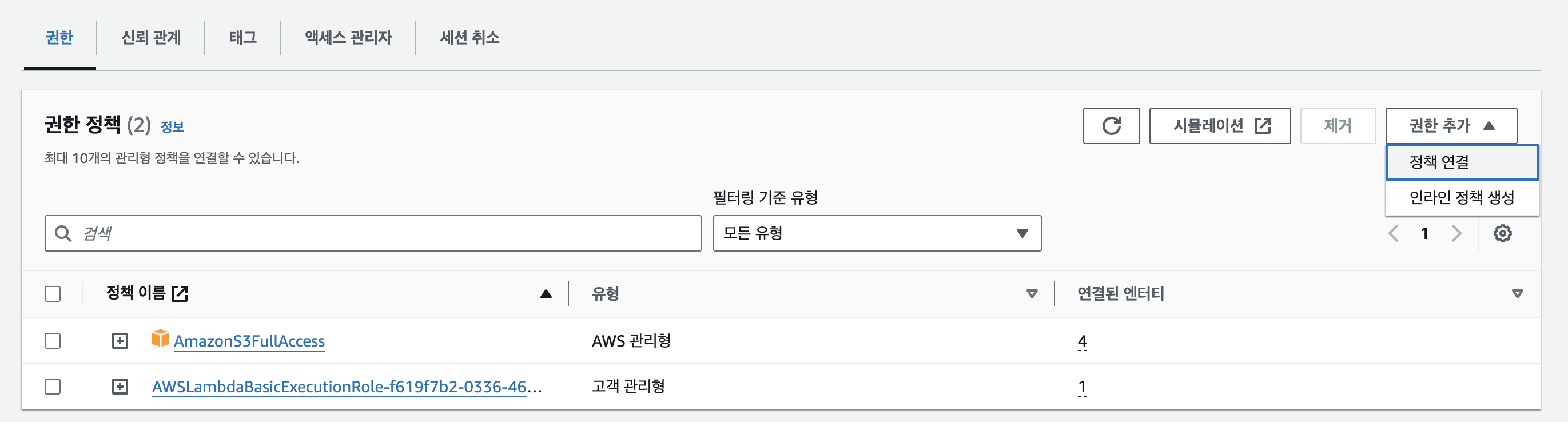
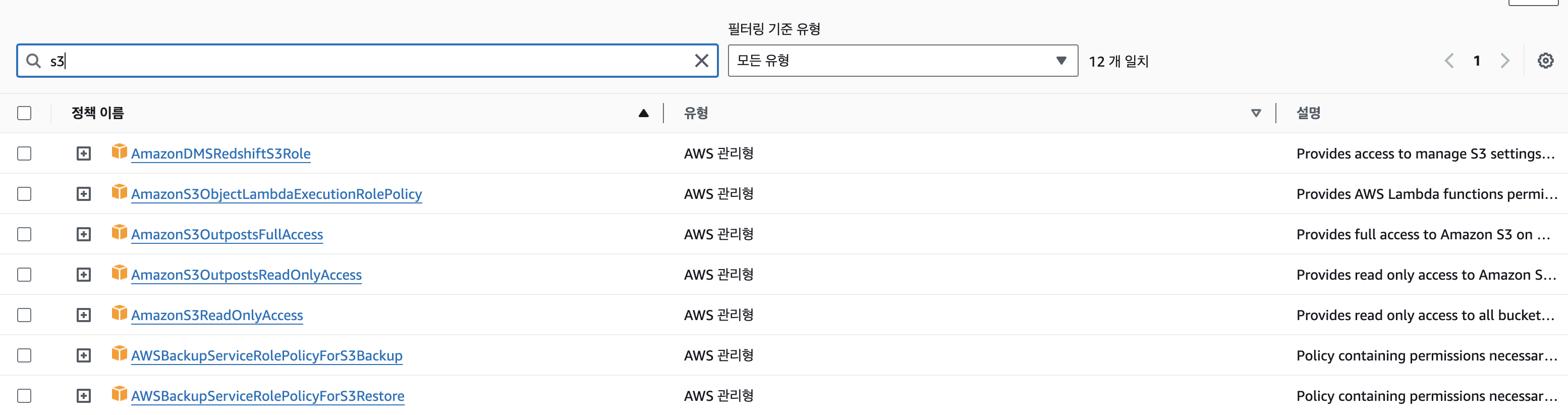
권한 추가 > 정책 연결을 선택해서 s3 정책 중 AmazonS3OutpostsFullAccess을 추가하거나 AmazonS3FullAccess을 추가하면 된다.
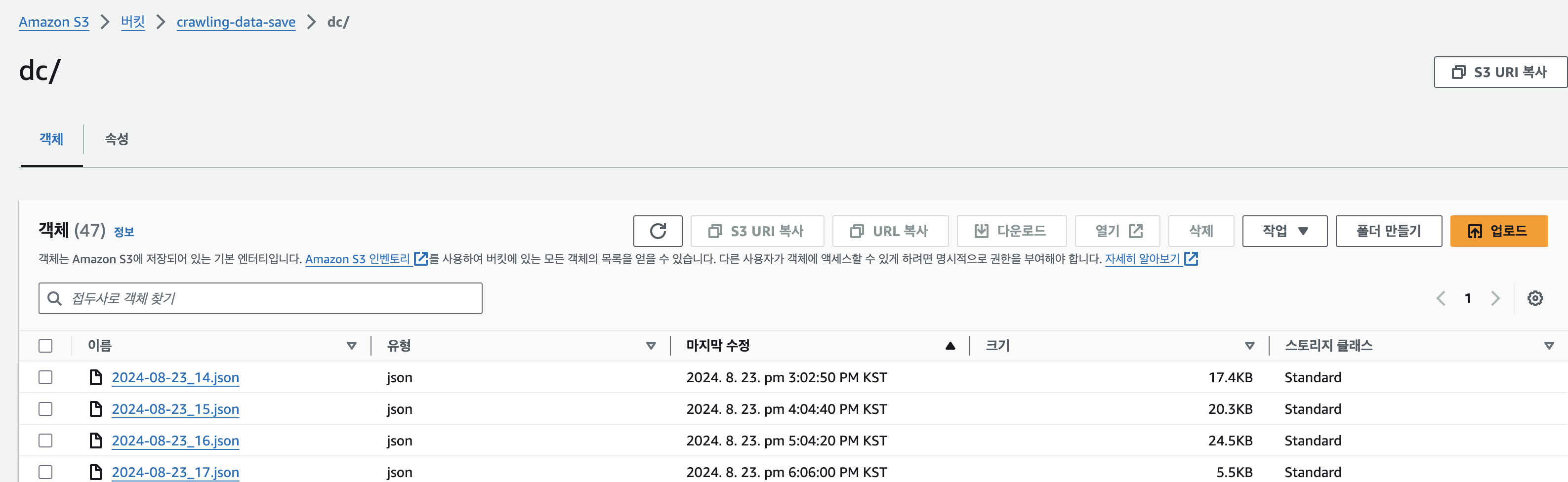
다시 람다로 돌아가 테스트 시 s3에 파일이 잘 저장되는 지 확인하면 끝!

성장하고 싶은 백엔드 주니어 개발자