Java Virtual Machine 은 가상 머신이라는 이름에 맞게, 운영체제와는 독립적으로 작동이 가능하다.
그 원리에 대해서 알아보자.
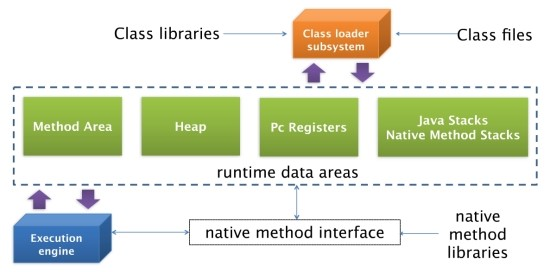
JVM의 구조에는 크게 Class Loader, Runtime data areas, Execution Engine, GC 으로 나누어져 있다. (GC는 이후에 따로 다루도록 하겠다. TODO)
Class Loader는 클래스 파일을 Runtime Data Area의 메서드 영역으로 불러오는 역할을 한다.
Execution Engine은 .class파일과 같은 ByteCode를 실행 가능하도록 해석한다.
Runtime Data Area 는 런타임시 클래스 데이터와 같은 메타 데이터와 실제 데이터가 저장되는 곳이다.
Runtime Data Area 에는 또 다시 Method Area, Heap, PC Registers, Java Stacks 그리고 Native Method Stacks 로 나누어진다.
ClassLoader
자바 컴파일러가 .java 파일을 컴파일하면 .class 파일(바이트 코드)가 생성된다. 이렇게 생성된 클래스 파일들을 엮어 Runtime Data Area 에 적재하는 역할을 한다.
동적인 클래스 로딩
자바는 동적으로 클래스를 읽어온다. 모든 클래스는 그 클래스가 참조되는 순간 동적으로 JVM에 링크되며, 메모리에 로딩된다.
JVM이 시작되면, 부트스트랩 클래스로 클래스로더를 생성하고, 가장 첫 번째 클래스인 Object를 시스템에 읽어온다.
동적 로딩에는 로드타임 동적 로딩(load-time dynamic loading)과 런타임 동적 로딩(run-time dynamic loading) 두 가지가 있다.
로드타임 동적 로딩
public class HelloWorld {
public static void main(String[] args) {
System.out.println("안녕하세요!");
}
}이런 코드가 있다고 가정했을 때, HelloWorld 클래스를 실행한다고 하면 과정은 이렇다.
- 부트스트랩 클래스 로더가 생성된다.
- 클래스로더가 Object 클래스를 읽어온다.
- 클래스로더는가 HelloWorld 클래스를 읽어오기 위해, HelloWorld.class 파일을 읽는다.
- 이때 HelloWorld 클래스를 읽기 위해, String과 System 클래스가 필요한다. 이 두 클래스를 읽어온다.
String과 System 클래스는 HelloWorld 클래스를 읽어오는 과정에서, 즉 로드타임에 로딩된다. 이처럼 하나의 클래스를 로딩하는 과정에서 동적으로 클래스를 로딩하는 것을 로드타임 동적로딩이라고 한다.
런타임 동적 로딩
public class HelloWorld implements Runnable {
public void run() {
System.out.println("안녕하세요!");
}
}Runnable 인터페이스를 구현한 간단한 클래스 예제에서, 아래와 같이 호출한다고 했을 때,
// 편의상 HelloWorld와 같은 패키지라고 생각하자.
public class RuntimeLoading {
public static void main(String[] args) {
try {
Class klass = Class.forName("HelloWorld");
Object obj = klass.newInstance();
Runnable r = (Runnable) obj;
r.run();
} catch(Exception ex) {
ex.printStackTrace();
}
}
}Class.forName 호출하는 순간, HelloWorld의 클래스가 로딩될 것이다. 그러나 그 전까지는 HelloWorld의 클래스가 로딩되는지 알 방법이 없다. RuntimeLoading 클래스가 로딩되더라도, HelloWorld클래스는 아직 로딩되지 않는다. 이렇게 클래스를 로딩하는 순간이 아닌 코드를 실행하는 순간에 클래스를 로딩하는 것을 런타임 동적 로딩이라고 한다.
Instance 생성시 일어나는 과정
- JVM이 Heap에 해당 Class Object가 있는지 확인한다.
- 없다면 Class Object를 Heap에 생성하고,, 해당 Class에 대한 Data (Class Data)를 Method Area에 저장한다.
- 이후 JVM은 해당 클래스의 새로운 Instance를 Heap 영역에 생성하고, Method Area의 Class Data를 Reference 한다.
- 만약 해당 클래스 Object의 새로운 Instance가 생성된다면 Heap과 Method Area에 이미 해당 Class Object와 Class Data가 생성되어있기에, Heap에 새로운 Instance를 생성하고, Method Area의 Class Data를 Reference하면 된다.
Execution Engine
Execution Engine 은 Class Loader를 통해 JVM 내의 Runtime Data Areas에 배치된 바이트코드를 실행한다. Execution Engine은 자바 바이트코드를 명령어 단위로 읽어서 실행한다. 정확히는 바이트 코드를 JVM이 실행할 수 있는 형태로 변경한다. 그 방식에는 Interpreter 방식과 JIT(Just In Time) 컴파일러 방식이 있다. 기본적으로 JVM은 모든 코드를 JIT Compiler 방식으로 실행하지 않고 Interpreter 방식을 사용하다 일정한 기준(?)이 넘어가면 JIT Compiler 방식으로 실행한다.
Runtime Data Area
PC Registers
Java는 CPU 레지스터로 직접 구동되는 방식이 아니라 스택 기반으로 작동한다.
JVM은 CPU에 직접 지시를 내리지 않고 Stack에서 연산자를 뽑아내어 별도의 메모리 공간에 저장하여 연산한다.
스레드가 시작할 때마다 하나씩 생성되어 Native Pointer와 Return Address를 가지고 있다.
현재 수행되고 있는 Instruction의 주소를 포함하고 있다. 이 Instruction의 주소는 Native Pointer 일 수도 있고 Method Bytecode의 시작 offset일 수도 있다.
(보완 필요)
Method Area
런타임 중 클래스가 사용되면 Class Loader 가 해당 클래스의 .class 파일을 읽어 분석하여, 유효하다면 클래스의 인스턴스 변수, 메소드 코드 등을 Method Area에 저장한다. 클래스 변수 또한 이 영역에 함께 생성된다.
객체 생성 후 메서드를 실행하게 되면 해당 클래스 메타데이터를 Method Area에 저장하게 된다. 저장되는 내역은 다음과 같다.
MetaInfo
타입의 이름, 상위 클래스 혹은 인터페이스, 현재 클래스가 Class인지 Interface인지 정보, Modifier 등.
이 정보는 Class Object를 통해 접근이 가능하다. 즉, Class Object는 내부적으로 MethodArea에 저장된 Class Data를 사용한다.
Reference to Class Object
실제 할당된 객체와 서로 양방향 접근을 하기 위해 Class Object에 대한 참조 주소값을 가진다.
클래스가 로드 될 때 클래스로더는 Heap에 Class 가 로드되어있는지 체크하는데, 이때 MethodArea에 Class Data가 있는지 체크하여 존재한다면 이 참조값으로 해당 Class Object를 찾는다.
Field Info
클래스의 필드 정보
Runtime Constant Pool
Constant Pool의 Runtime 버전
Literals과 같은 상수를 저장
Symbolic References를 저장
Method Info
메서드 이름, 리턴타입, 파라미터의 개수와 타입, Modifiers, Method byte code
Method Table
Instance methods를 저장하는 공간 (static method가 아님)
각각의 Reference는 기본적으로 해당 Method Info의 Bytecode를 가르킨다
클래스 객체에서 Method를 실행시키면 Method table에서 해당 Method를 실행하기 위해 검색한다. Super 클래스에서 상속받은 Method에 대한 Reference 역시 저장한다.
JVM Stacks
Thread의 수행정보를 기억하는 Frame을 저장하는 메모리 영역
Thread 마다 하나씩 존재, 시작시 생성, 다른 Thread에서 데이터 접근 불가
JVM 은 JVM Stack에 StackFrame을 push, pop 하는 작업만 수행한다.
Method하나를 수행할떄마다 JVM은 Stack Frame을 하나씩 생성하여 Stack에 Push한다. 이때 새로 들어간 StackFrame이 Current Frame (현재 프레임) 이 된다. 이 Method가 수행을 마치게되면 Pop되어 이전 StackFrame이 Current Frame이 된다.
StackFrame
StackFrame은 Thread가 수행하고 있는 응용 프로그램을 메서드 단위로 기록하는 곳이다. 즉 StackFrame = Method 실행
StackFrame은 Method 실행 시 Class의 메타 정보를 이용하여 적절한 크기로 생성된다. 가변은 아니고 Compile Time에 이미 결정된다.
JVM은 생성된 StackFrame을 JVM Stack에 Push후 Method를 수행한다.
StackFrame은Local Variable Section, Operand Stack, Frame Data 세 가지 영역으로 나뉜다.
Local Variable Section
Local Variable Section에는 메서드의 매개변수와 지역변수를 저장한다. Local Variable Section에는 0부터 시작하는 인덱스를 가진 Array로 구성되어 있고, 이 Array의 인덱스를 통해 데이터에 접근하게 된다. 메서드 파라미터는 선언된 순서로 인덱스가 할당되며 로컬 변수는 Compiler가 알아서 인덱스를 할당한다.
자료형마다 다른듯 → 추가 조사
Operand Stack
Operand Stack을 한 마디로 정의하면 JVM의 작업 공간 → 연산을 위해 사용되는 데이터와 결과를 Operand Stack에 집어놓고 처리하기 때문 (레지스터랑 비슷한가?)
Operand Stack도 역시 Array로 구성되어 있으나, 인덱스로 처리하지 않고 Push, Pop작업을 통해 필요할 때마다 공간을 할당한다.
class JvmInternal {
public void operandStack() {
int a, b, c,;
a = 5;
b = 6;
c = a + b;
}
}public void operandStack();
Code :
0: iconst_5
1: istore_1
2: bipush 6
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: istore_3
8: return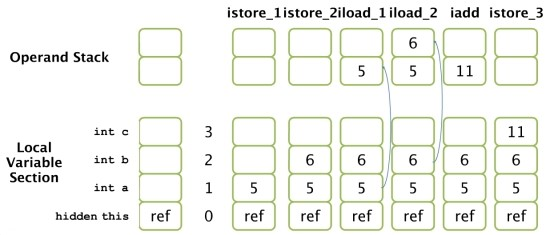
Frame Data
Frame Data에는 Constant Pool Resolution 정보와 메서드가 정상 종료했을 떄의 정보들, 그리고 비정상 종료했을 시에 발생하는 예외 관련 정보들을 저장하고 있다.
Resolution이란 Symbolic Reference로 표현된 Entry를 찾아 Direct Reference로 변경하는 과정을 말한다. Class의 모든 Symbolic Reference는 메서드 영역의 Constant Pool이라는 곳에 저장되기 때문에 Resolution을 Constant Pool Resolution으로 부르는 것이다. (쉽게 말해 상징적 참조를 직접적 참조로 치환한다는 의미인 듯)
즉, Constant Pool Resolution 정보는 Constant Pool의 포인터 정보이다. 이 포인터 주소를 보고 Constant Pool을 찾아가는 것이다.
Java의 모든 Reference는 Symbolic Reference 이기 때문에, 클래스나 메서드, 변수나 상수에 접근할 때도 이러한 Resolution이 수행된다. 특정 객체의 의존관계를 살펴볼때도 Constant Pool의 Entry를 참조한다.
Frame data에는 자신을 호출한 Stack Frame(즉, 이전 프레임)의 Instruction Pointer가 들어가 있다. Method가 종료되면 JVM은 이 정보를 PC Register에 설정하고 Stack Frame을 빠져나간다(현재 실행중인 Instruction을 변경한다). 만약 이 Method가 반환 값이 있다면 이 반환 값을 다음 번 Current Frame, 즉 자신을 호출한 Method의 Stack Frame의 Operand Stack에 Push하는 작업도 병행한다(값을 할당하는 거니까!).
만약 예외가 발생했다면 Frame Data 내부의 Exception Table의 Reference를 참조하여, catch절에 해당하는 Bytecode로 점프하게 된다. (그럼 기존의 스택은 어케 되는겨)
Native Method Stacks
Java는 Java외의 언어로 작성된 프로그램, API 툴킷 등과의 통합을 쉽게 하기 위해 JNI(Java Native Interface)라는 표준 규약을 제공하고 있다. 즉 Native Code로 되어있는 함수의 호출을 Java 프로그램 상에서 수행할 수 있고, 리턴값 또한 받아올 수 있다.
JVM Stack 상에서 Native Method를 만나 수행하게 된다면 Native Method Stack에 Native Function을 만들어 호출하게 된다. Native Function이 끝나면 JVM Stack으로 다시 돌아오는데, 이때 호출한 Stack Frame으로 돌아가는게 아니라 새로운 StackFrame을 하나 더 생성하여 다시 작업을 수행한다 (why?)
최신버전 JVM은 JVM Stack과 Native Method Stack 두 영역을 나누어 쓰지 않고 통합하여 쓰고있다. 다만 Java Method인지 Native Method인지에 따라 StackFrame이냐 Native Stack Frame이냐를 구분한다.
출처
아직 정리가 덜 됬는데, 차차 알아듣기 쉽게 정리해야겠다.
그림같은 것도 퍼온 것이 많은데, 따로 그려서 다시 정리해보는 편이 좋겠다.
https://velog.io/@litien/JVM-%EA%B5%AC%EC%A1%B0
https://m.blog.naver.com/2000yujin/130156226754
https://mia-dahae.tistory.com/101
https://javacan.tistory.com/entry/1
https://sehun-kim.github.io/sehun/JVM/
