2019-04-08 17:00 작성된 포스트
개요
데이터 통신 수업에서 UDP 패킷 분석에 관한 과제를 받았다. 과제 내용은 pingplotter 혹은 traceroute로 UDP 패킷을 요청한 내용을 Wireshark로 캡쳐한 후 질문에 답해야 하는 것이다.
풀어야할 문제는 다음과 같다.
- Select the first ICMP Echo Request message sent by your computer, and expand
the Internet Protocol part of the packet in the packet details window. What is the IP address of your computer? - Within the IP packet header, what is the value in the upper layer protocol field?
- How many bytes are in the IP header? How many bytes are in the payload of the
IP datagram? Explain how you determined the number of payload bytes. - Has this IP datagram been fragmented? Explain how you determined whether or
not the datagram has been fragmented. - Which fields in the IP datagram always change from one datagram to the next
within this series of ICMP messages sent by your computer? - Which fields stay constant? Which of the fields must stay constant? Which fields
must change? Why? - Describe the pattern you see in the values in the Identification field of the IP
datagram. - What is the value in the Identification field and the TTL field?
- Do these values remain unchanged for all of the ICMP TTL-exceeded replies sent
to your computer by the nearest (first hop) router? Why? - Find the first ICMP Echo Request message that was sent by your computer after
you changed the Packet Size in pingplotter to be 2000. Has that message been
fragmented across more than one IP datagram? - Print out the first fragment of the fragmented IP datagram. What information in
the IP header indicates that the datagram been fragmented? What information in
the IP header indicates whether this is the first fragment versus a latter fragment?
How long is this IP datagram? - Print out the second fragment of the fragmented IP datagram. What information in
the IP header indicates that this is not the first datagram fragment? Are the more
fragments? How can you tell? - What fields change in the IP header between the first and second fragment?
- How many fragments were created from the original datagram?
- What fields change in the IP header among the fragments?
실습 과정
현재 테스트 환경은 윈도우가 아닌 리눅스이므로, pingplotter가 아닌 traceroute로 실습을 진행하였다. 아래 그림과 같이 와이어샤크 캡처를 시작한 상태에서, traceroute 명령어를 수행하였다.
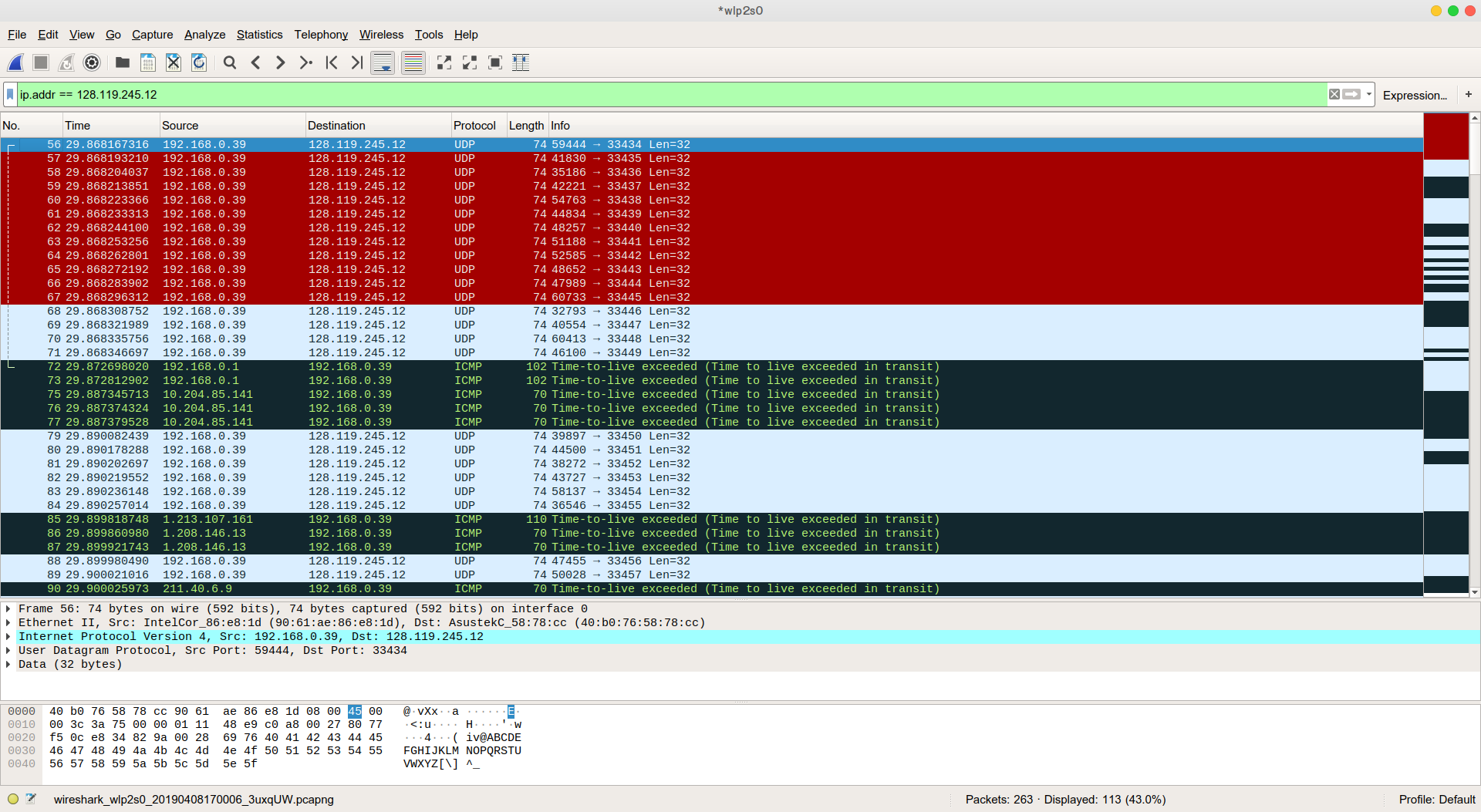
-> 와이어샤크 캡쳐화면
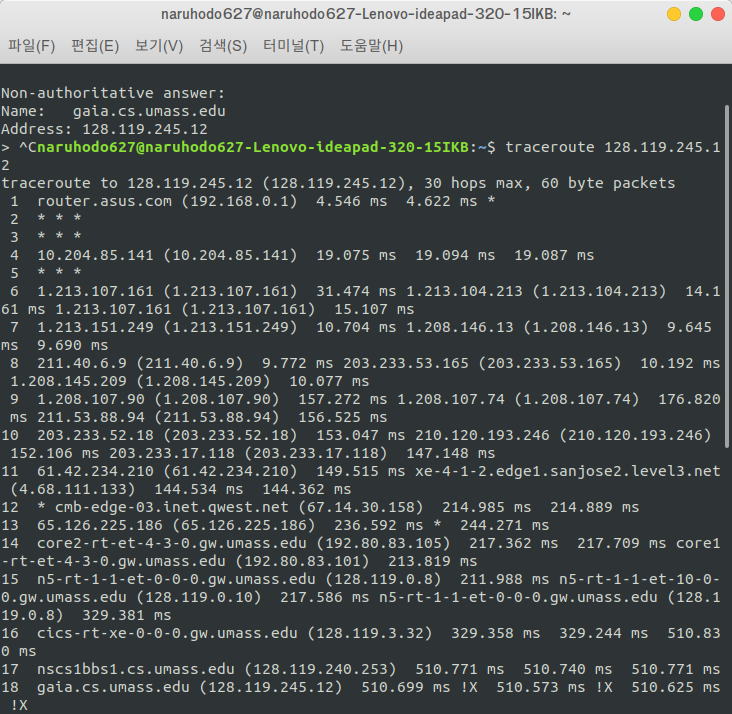
-> traceroute 실행 캡쳐화면
문제 풀이
1. Select the first ICMP Echo Request message sent by your computer, and expand the Internet Protocol part of the packet in the packet details window. What is the IP address of your computer? (자신의 컴퓨터에서 보내진 첫 번째 ICMP Echo 요청을 선택 후 패킷 상세보기 창에서 패킷의 IP 부분을 확장해 보라. 어떤 부분이 자신의 IP인가?)
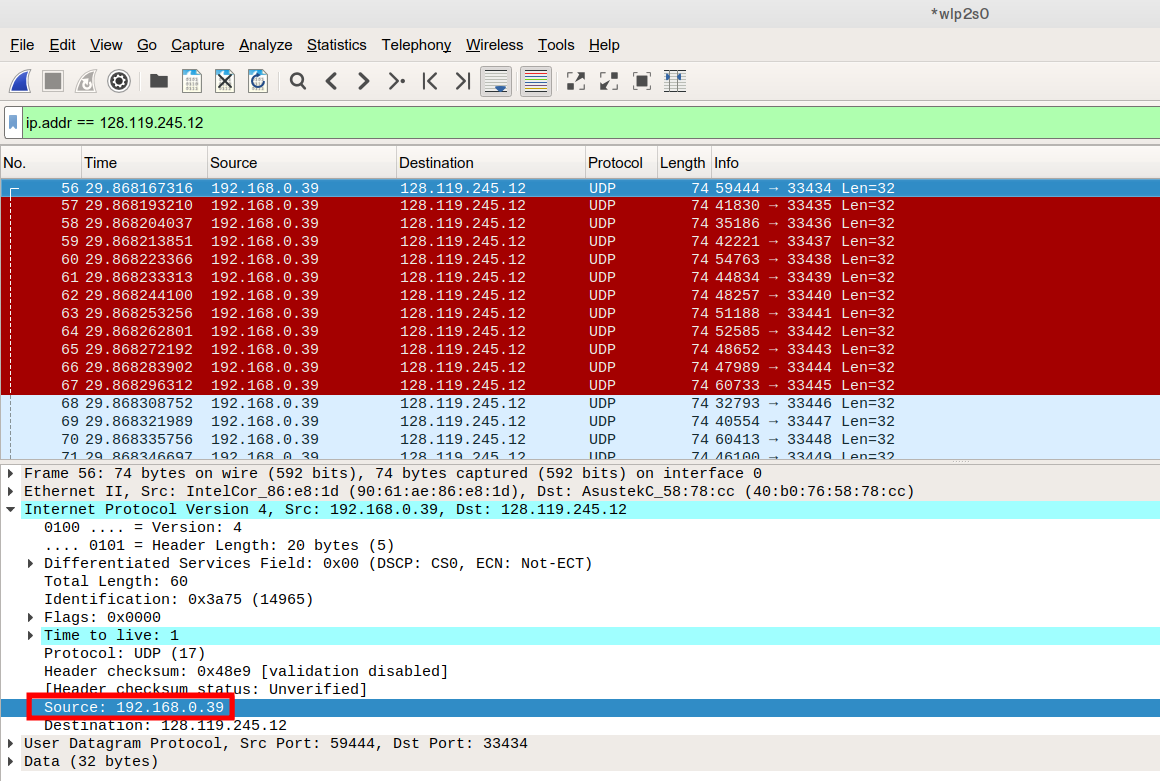
pingplotter로 테스트를 했었다면 ICMP 패킷이 제일 먼저 찍혔을 테지만, 필자는 traceroute를 사용했기 때문에 ICMP 패킷이 아닌 UDP 패킷이 찍혔다. 이 패킷의 IP 헤더 안의 source 필드가 출발지 주소, 즉 현재 내 자신의 IP를 알려주고 있다.
2. Within the IP packet header, what is the value in the upper layer protocol field? (IP 패킷 헤더 안에서, 상위 계층 프로토콜 필드 값은 무엇인가?)
먼저, IP 패킷 헤더의 구조를 보자
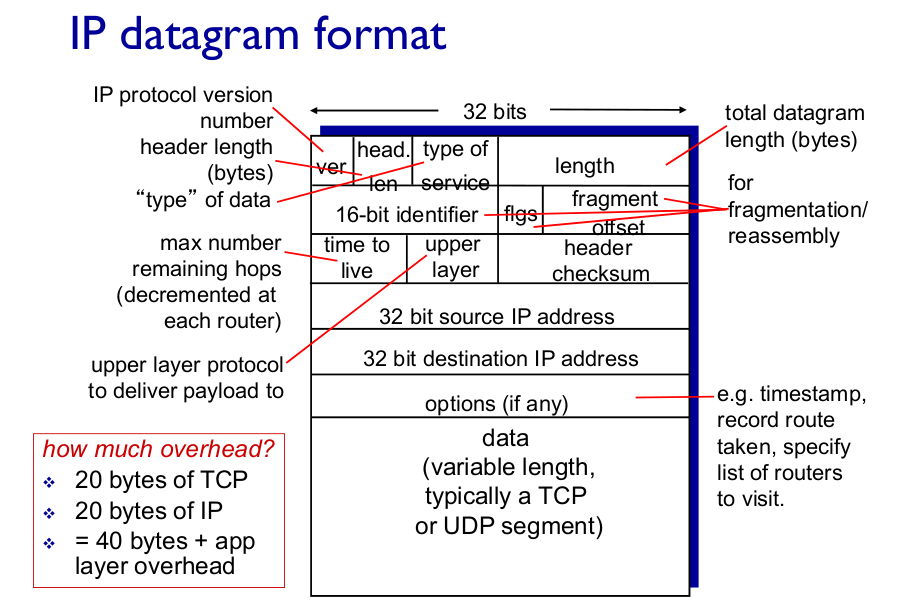
위 그림에 따르면, upper layer protocol, 즉 상위 계층 프로토콜 필드 값은 IP 데이터그램 시작 지점에서 10바이트 지점에서 위치하고 있으며, TTL 필드와 header checksum 필드 사이에서 찾을 수 있다.
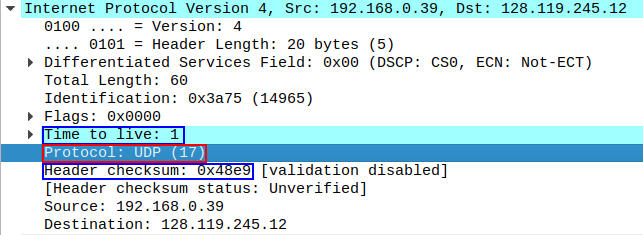
위 그림에서 파란 색으로 표시된 TTL 필드와 header checksum 필드 사이에서 상위 계층 프로토콜 필드 값이 UDP 임을 확인할 수 있다.
3. How many bytes are in the IP header? How many bytes are in the payload of the IP datagram? Explain how you determined the number of payload bytes.(IP 헤더는 몇 바이트로 되어있나? IP 데이터그램의 payload는 몇 바이트인가? payload 바이트가 몇 바이트인지 어떻게 찾았는지 설명하시오.)
질문 참 많다..
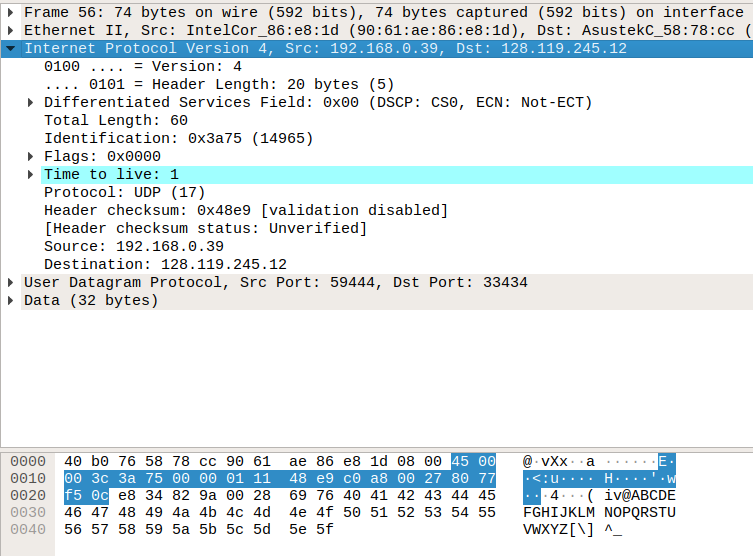
와이어샤크에서 IP 헤더를 선택했을 때, 위 그림처럼 하단에 바이너리 데이터 역시 선택 되는 것을 볼 수가 있다. 이 바이너리 데이터는 16진수로 표현됬기 때문에, 띄어쓰기 단위로 1바이트씩 나누어져 있다. 선택된 범위가 IP 헤더니까, 이 범위 안의 바이트 수를 세면 IP 헤더의 바이트 수는 20바이트라는 것을 알 수 있다.
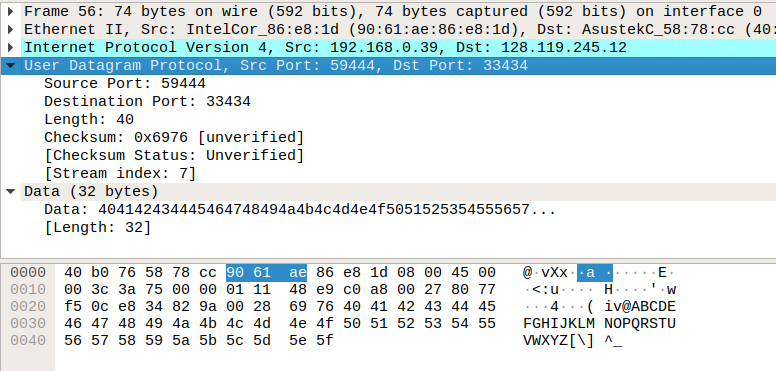
IP 데이터그램에서, 32비트 목적지 주소 아래로는 모두 payload로 되어있다(payload라 함은 직역하면 화물, 즉 운송하는 data이다). 다시 말해, IP 헤더 아래의 바이트는 모두 payload의 바이트임을 의미한다. 내용을 좀 더 자세히 보면, UDP 헤더와 Data로 나뉘어져 있는데, 이걸로 payload는 UDP datagram임을 알 수 있다. 위와 같이 바이트 수를 세면 payload의 바이트 수를 구할 수도 있지만, 친절하게도 Data는 32바이트라고 알려주고 있고, 그림에서 선택된 UDP 프로토콜 헤더의 바이트는 3바이트이므로 payload의 바이트 수는 35바이트임을 알 수 있다.
4. Has this IP datagram been fragmented? Explain how you determined whether or not the datagram has been fragmented. (이 IP 데이터그램이 단편화 되었는가? 데이터그램이 단편화 됬는지 아닌지 확인할 방법을 설명하시오.)
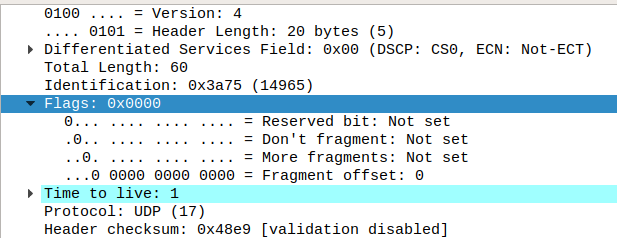
위 그림의 Flags값이 0인 것을 보아, 단편화가 발생하지 않았음을 짐작할 수 있다. Flags필드를 자세히 보았을 때, More fragments flag가 세팅되지 않았음을 보아 이 데이터는 단편화가 발생하지 않았다.
5. Which fields in the IP datagram always change from one datagram to the next within this series of ICMP messages sent by your computer? (자신의 컴퓨터에서 전송된 ICMP 메세지들의 하나의 데이터그램에서 다른 데이터그램으로 넘어갈 때 IP 데이터그램의 어떤 필드가 항상 변경되는가?)
연속된 두 패킷을 순서대로 캡쳐해 보았다.
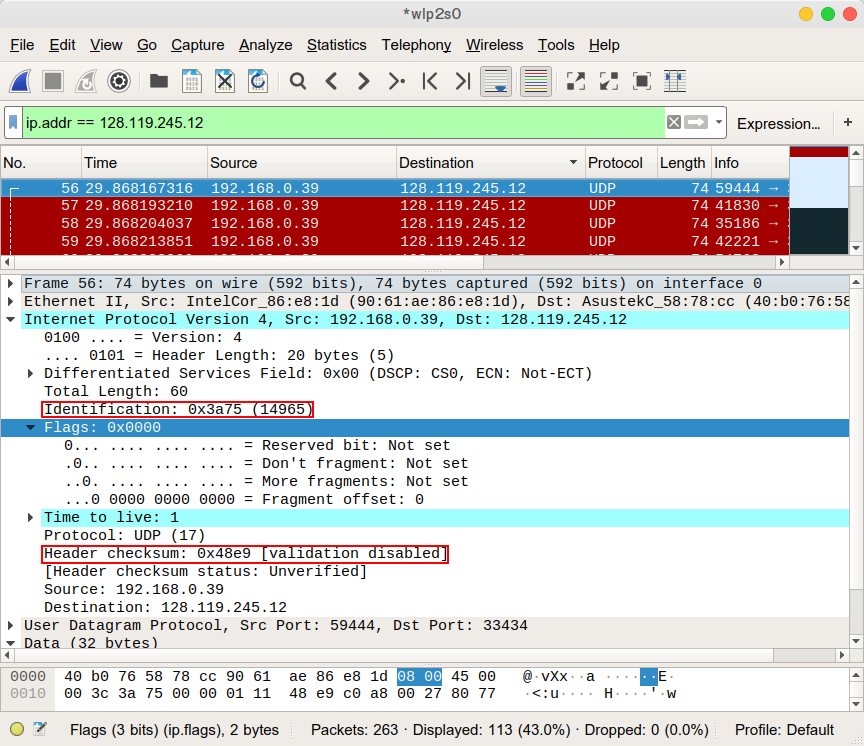
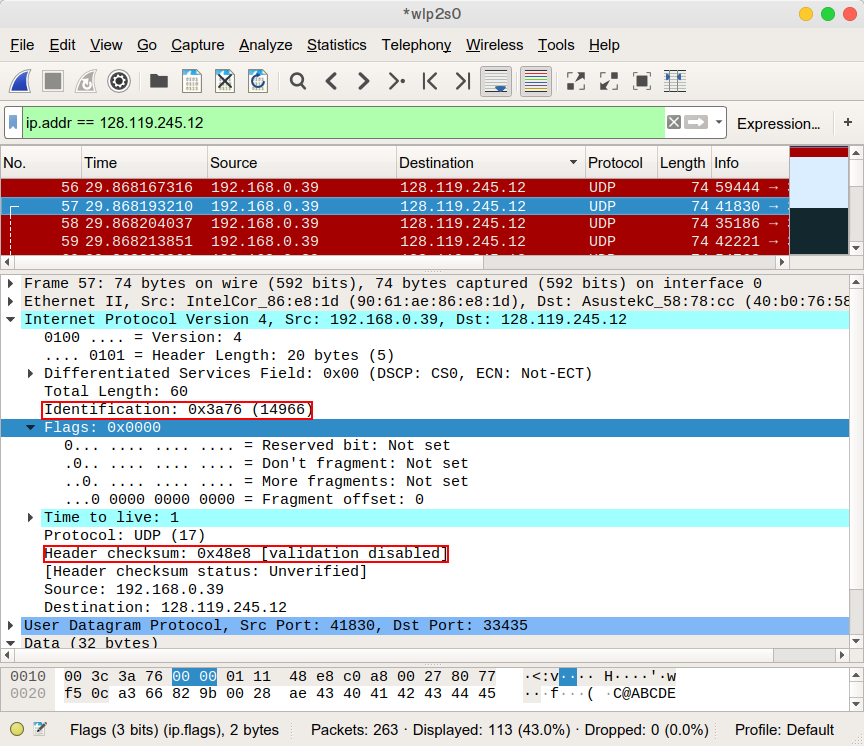
두 패킷들의 차이를 보면 Identification 필드와 Header checksum 필드 값의 차이가 있는 것을 확인할 수 있다. Identification 값은 그 패킷의 인식 값이며, 1씩 증가하는 것으로 보인다. Header checksum은 헤더의 모든 데이터를 검증하는 값이기에, 그 값 자체가 변하는게 아니라 헤더의 값, 즉 Identification이 변경되면서 같이 변경되는 것으로 보인다.
6. Which fields stay constant? Which of the fields must stay constant? Which fields must change? Why? (어떤 필드가 고정되었는가? 어떤 필드는 반드시 고정되어야 하는가? 어떤 필드는 반드시 변경되는가? 이유는?)
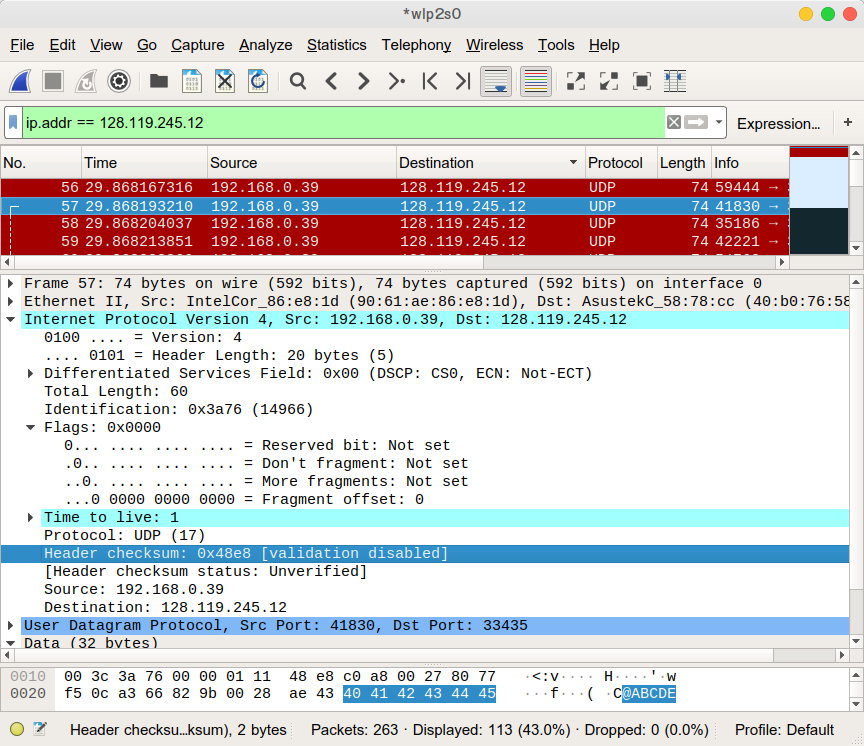
캡처된 여러 패킷을 돌아보면서, 헤더의 필드 각각을 표로 정리하였다.
| 필드명 | 역할 | 변경 / 고정 | 이유 |
|---|---|---|---|
| Version | IP의 버전을 나타낸다 | 고정 | IP 버전은 4로 고정 (IPv4) |
| Header Length | 헤더의 크기를 나타낸다 | 변경 가능 | timestamp 등 추가적인 IP헤더의 정보가 들어갈 수 있음 |
| Type of Service | 데이터의 타입을 나타낸다 | 변경 가능 | 어떤 종류의 데이터인지 나타내는 필드 |
| Total Length | payload의 크기를 나타낸다 | 변경 가능 | payload 크기에 따라 변경됨 |
| Identification | 헤더의 식별 번호를 나타낸다 | 변경 | 헤더를 구분할 식별자 |
| Flags | 단편화 여부를 나타내는 flags | 변경 가능 | 단편화 발생 시 flag로 표시 |
| Time to live | TTL값을 나타낸다 (TTL : 패킷이 네트워크 안에서 생존할 수 있는 시간) | 변경 가능 | 요청에 따라 상이 (traceroute의 경우 호스트에 도달할 때 까지 1씩 증가) |
| Upper layer protocol | 상위 계층의 프로토콜을 나타낸다 | 변경 가능 | 패킷마다 프로토콜이 상이 |
| Header checksum | 헤더가 올바른지 확인한다 | 변경 | 헤더 각각의 checksum 값이 다르기 때문 |
| Source | IP 출발 주소를 나타낸다 | 변경 가능 | 패킷마다 주소가 상이 |
| Destination | IP 도착 주소를 나타낸다 | 변경 가능 | 패킷마다 주소가 상이 |
7. Describe the pattern you see in the values in the Identification field of the IP datagram.(IP 데이터그램의 Identification 필드 값에서 보이는 패턴을 설명하시오.)
5번 문항에서 1씩 증가함을 확인할 수 있었다.
8. What is the value in the Identification field and the TTL field?(Identification 필드의 값과 TTL 필드 값은 무엇인가?)
(주: 이 문제는 ICMP TTL-exceeded 응답 패킷에 대한 문제이다)
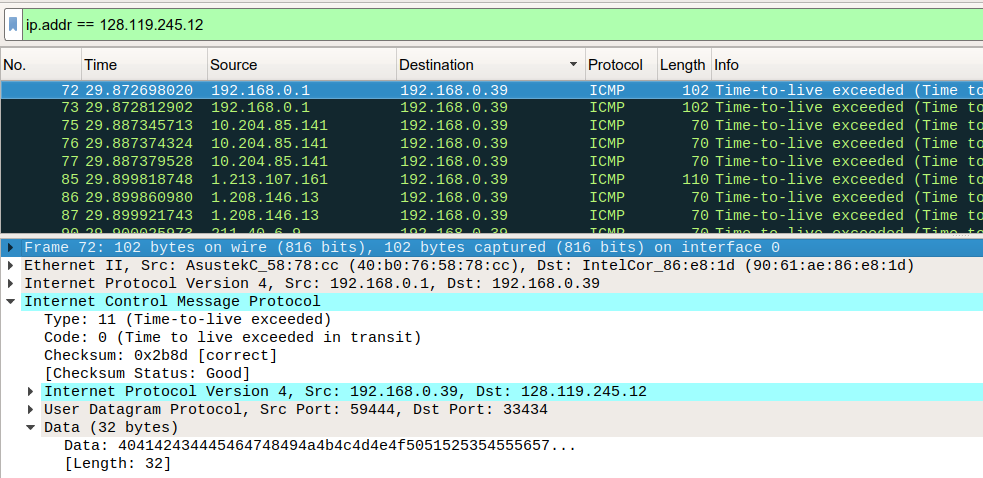
위의 표에서 찾을 수 있듯이, Identification 필드는 헤더의 식별 번호를 나타내며, TTL 필드는 패킷이 네트워크 안에서 생존할 수 있는 시간을 나타낸다. 이때 시간이라는 표현을 쓰긴 했지만 사실 라우터간 경유 횟수, 즉 홉(Hop)당 TTL이 1씩 감소한다. TTL 값이 0이 된다면 라우터에서 TTL-exceeded 응답을 돌려준다.
패킷 그림을 자세히 보면, checksum 필드 아래로는 기존 IP 헤더와 동일한 것을 확인할 수 있다. 열어서 Identification, TTL 필드를 확인해보면, ICMP 패킷 안에 기존 요청의 IP헤더의 정보가 담겨있다는 것을 알 수 있다.
9. Do these values remain unchanged for all of the ICMP TTL-exceeded replies sent to your computer by the nearest (first hop) router? Why? (이 값들이 가장 가까운 (first hop) 라우터에서 본인의 컴퓨터로 전송된 모든 ICMP TTL-초과 응답들에 대해 변경되지 않은채로 유지되는가? 이유는?)
ICMP 헤더안의 IP 헤더 Identification 필드는 기존 요청 IP 헤더의 Identification필드 값을 그대로 가지고 있다. 헤더의 식별 번호이기 때문에, 이 값은 계속 변한다. 가장 가까운 라우터에서 TTL이 0이 되어 ICMP TTL-exceeded 응답이 온 것이므로, ICMP 헤더의 IP 헤더의 TTL 값은 1로 고정되어 있음을 알 수 있다.
10. Find the first ICMP Echo Request message that was sent by your computer after you changed the Packet Size in pingplotter to be 2000. Has that message been fragmented across more than one IP datagram? (Pingplotter에서 패킷 크기를 2000으로 변경한 후 본인의 컴퓨터에서 전송된 ICMP Echo 요청 메세지를 찾아라. 그 메세지가 하나의 IP 데이터그램 이상 단편화 되었는가?)
필자는 traceroute로 실습을 진행했기 때문에, traceroute 명령어에서 다음과 같이 패킷의 크기를 2000바이트로 정해준 후 실행하였다.
traceroute gaia.cs.umass.edu 2000
패킷 확인 결과 More framents flag가 셋팅되었고, 단편화가 발생한 것을 확인할 수 있다.
11, 12번 답에 출력 결과가 나와있다.
11. Print out the first fragment of the fragmented IP datagram. What information in the IP header indicates that the datagram been fragmented? What information in the IP header indicates whether this is the first fragment versus a latter fragment? How long is this IP datagram? (단편화된 IP 데이터그램의 첫 번째 단편을 출력하라. IP 헤더의 어떤 정보가 데이터그램이 단편화 되었는지 알려주는가? IP 헤더의 어떤 정보가 그것이 첫 번째 단편인지 마지막 단편인지 알려주는가? 이 IP 데이터그램의 길이는?)
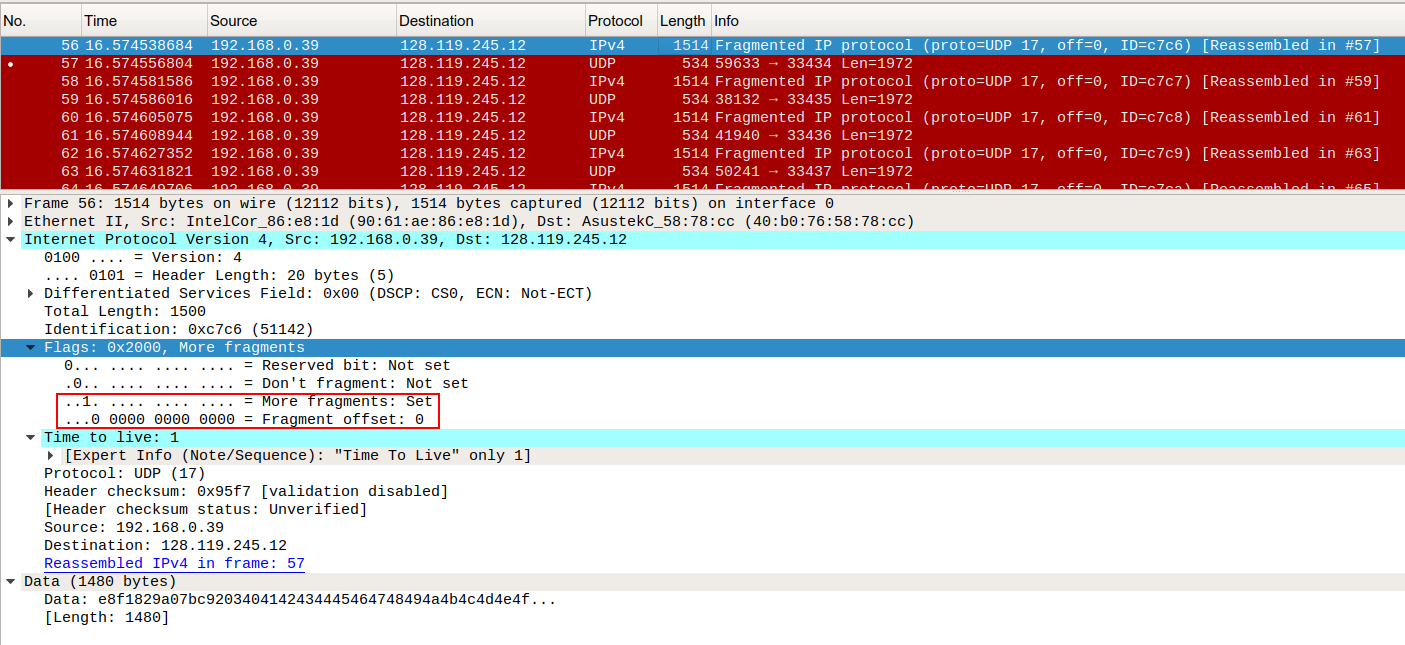
More framents flag가 셋팅되어 단편화 되었음을 알려준다. 또한, Fragment offset 값이 0이므로 이 단편이 첫 번째 단편임을 알려주고 있다. IP 헤더의 Total Length 필드의 값을 보아 이 데이터그램의 길이는 1500바이트이다. (헤더 20바이트 + payload 1480바이트)
12. Print out the second fragment of the fragmented IP datagram. What information in the IP header indicates that this is not the first datagram fragment? Are the more fragments? How can you tell?(단편화된 IP 데이터그램의 두 번째 단편을 출력하라. IP 헤더의 어떤 정보가 이 데이터그램이 첫 번째가 아님을 알려주는가? 추가적인 단편이 있는가? 어떻게 아는가?)
드럽게 많이 물어보네..
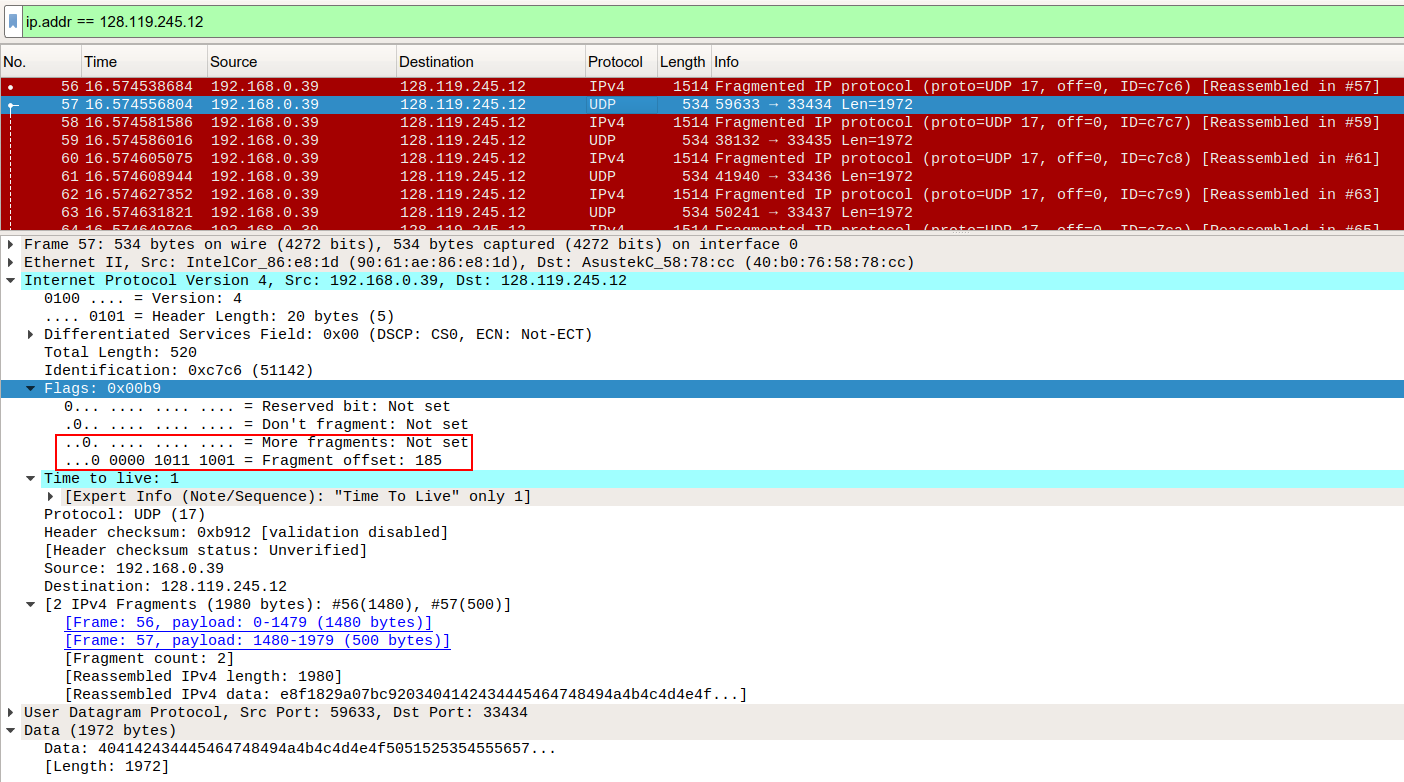
Fragment offset 값이 185인 것이 이 데이터그램이 두 번째임을 알려준다(offset은 바이트/8 값으로, 바이트로 환산하면 185 x 8 = 1480바이트다). More fragments flag가 세팅되지 않은걸로 보아 추가적인 단편이 발생하지 않았다.
13. What fields change in the IP header between the first and second fragment?(IP 헤더의 어떤 필드가 첫 번째와 두 번째 단편 사이에 변경되었는가?)
More fragments 필드와 Fragment offset 필드가 변경되었다. 그러나 이 단편들은 기본적으로 같은 패킷이기에, Identification 필드 값은 변경되지 않았다.
14. How many fragments were created from the original datagram? (원본 데이터그램에서 얼마나 많은 단편들이 생성되었는가?)
패킷 사이즈를 3500으로 변경 후 다시 캡쳐하였다.
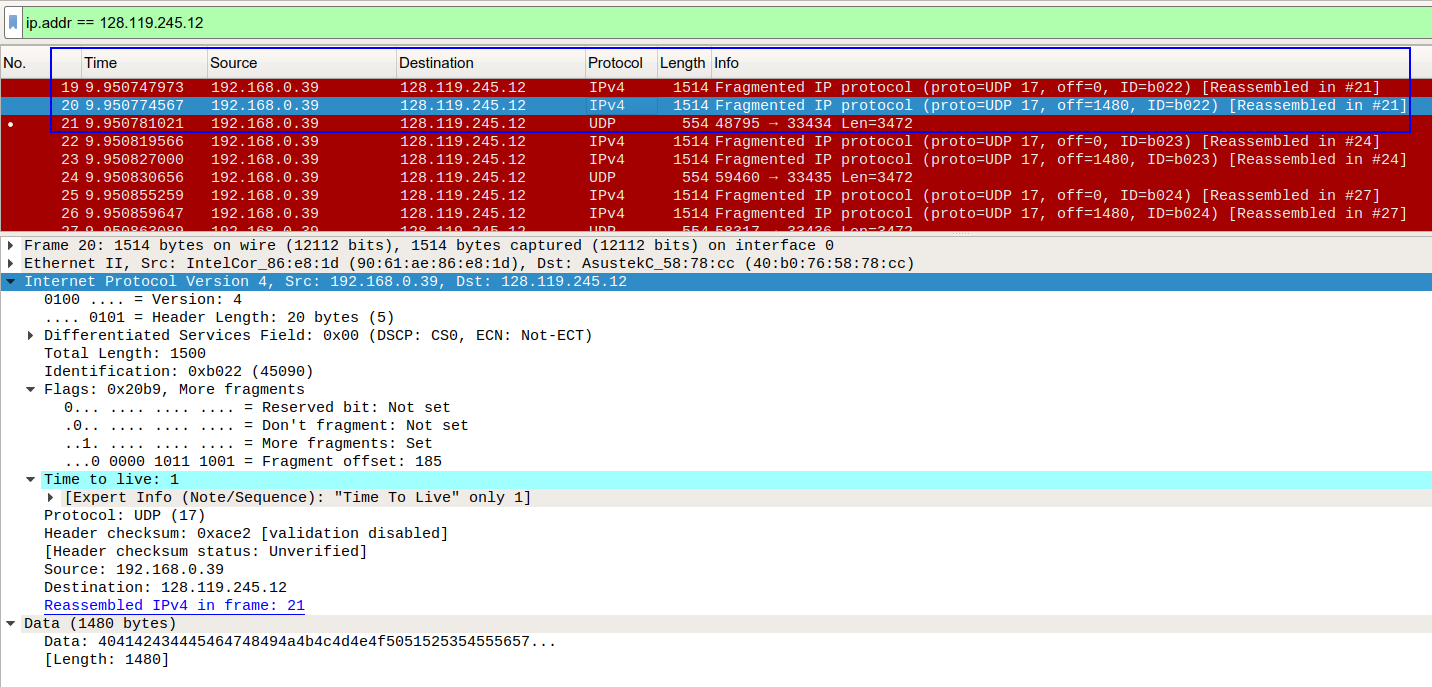
패킷 당 3개의 단편이 발생하였음을 확인할 수 있었다.
15. What fields change in the IP header among the fragments?(단편 중에서 IP 헤더의 어떤 필드가 변경되었는가?)
13번 답과 마찬가지로, More fragments 필드와 Fragment offset 필드가 변경되었다.
느낀 점
이번 실습을 통해 UDP 패킷의 구조에 대한 이해도를 높일 수 있어서 좋다고 생각했다. 또한, 단편화의 개념을 잡는데 많은 도움이 되었다. 처음 생각에는 패킷 전송 시 무조건 하나로 묶어서 보낸다고 생각했다. 그러나 만약 큰 payload를 단편화 시키지 않고 무조건 묶어서 보낸다면, 매우 큰 파일을 전송 시 성능 상에서 많은 문제가 발생할 것이다. 단편화에 대해 실습하면서, 평소에도 어떠한 방식 혹은 알고리즘에 대해 어떤 문제가 발생할 수 있는지 생각하는 습관을 갖는게 좋겠다는 생각이 들었다. 그렇게 함으로서 그 방식 혹은 알고리즘에 대해 셀프 피드백이 가능해지고, 그걸 한층 더 향상하는데 도움이 될 것이다.
주관적인 생각이 많이 들어간 포스트입니다. 지적은 언제나 환영입니다!
출처 : http://www-net.cs.umass.edu/wireshark-labs/Wireshark_UDP_v7.0.pdf
