
SQL 파싱과 최적화
SQL
SQL은 구조적, 집합적, 선언적 질의 언어이다. 위키피디아에서는 SQL을 아래와 같이 정의하고 있다.
SQL is designed for a specific purpose: to query data contained in a relational database. SQL is a set-based, declarative programming language, not an imperative programming language like C or BASIC.
SQL은 이름(Structured Query Language)에서도 알 수 있듯이 구조적이고, 집합적이고 선언적인 질의 언어이다. 원하는 결과 집합을 구조적, 집합적으로 선언하지만, 그 결과 집합을 만들어 내기 위해서는 절차적인 과정, 즉 프로시저가 필요하다(프로시저란 SQL에서 일련의 작업을 절차적으로 수행하고 결과 값을 반환하지 않는 일종의 프로그래밍 기능이다). 그런 프로시저를 DBMS 내부 엔진인 SQL 옵티마이저가 만들어 낸다. 즉, 옵티마이저가 프로그래밍을 대신해준다.
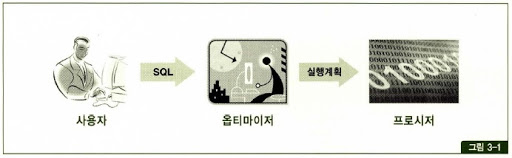
SQL 최적화
DBMS 내부에서 프로시저를 작성, 컴파일 후 실행 가능한 상태로 만드는 전 과정을 SQL 최적화라고 한다. SQL 실행 과정은 다음과 같다.
- DBMS에 SQL 전달
- SQL 파서가 파싱 트리 생성
- 문법(Syntax) 체크
- 의미(Semantic) 체크 (예를 들어, 존재하는 테이블을 사용했는지)
- SQL 최적화
- 미리 수집한 시스템 및 오브젝트 통계 정보를 이용, 다양한 실행 경로 생성
- 가장 효율적인 하나를 선택
- 선택한 실행 경로에 대해 로우 소스 생성기가 실행 가능한 코드(로우 소스) 생성
SQL 옵티마이저는 쉽게 생각하면 네비게이션 추천 경로 알고리즘이다. 후보군의 실행 계획을 모두 찾아낸 후, 통계 정보를 이용해 예상 비용(cost)을 산정한다. 그 중 최저 비용을 선택해서, 로우 소스 생성기에 넘겨준다.
Select 문을 통해 실행 계획을 미리볼 수 있고, 특정 실행 계획을 강제하도록 옵티마이저 힌트를 함께 전달할 수도 있다.
SQL 공유 및 재사용
라이브러리 캐시
위에서 설명한 SQL 실행과정을 거쳐 생성한 내부 프로시저를 반복 재사용할 수 있도록 캐싱해 두는 메모리 공간을 라이브러리 캐시(Library Cache) 라고 한다. SGA(System Global Area)는 서버 프로세스와 백그라운드 프로세스가 공통으로 액세스하는 데이터와 제어구조를 캐싱하는 메모리 공간인데, 라이브러리 캐시는 SGA의 구성 요소이다.
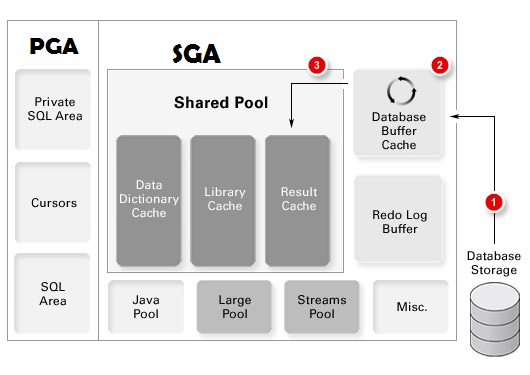
DBMS는 SQL 파싱 후에 라이브러리 캐시에 프로시저가 있는지 검사하는데, 이때 찾아서 곧바로 실행으로 넘어가는 것을 소프트 파싱(Soft Parsing), 찾는데 실패하여 최적화 과정을 새로 거치는 것을 하드 파싱(Hard Parsing)이라고 한다.
SQL 최적화 과정은 한 번 최적화를 하는데에 모든 실행 계획을 뽑아내고, 시스템 구조, 시스템 통계, 오브젝트 통계, 파라미터 등을 모두 고려하여 하나를 선택하는데, 이 과정은 결코 가벼울(Soft) 수 없다. 즉, SQL 최적화 과정은 무거우며(Hard), 이러한 과정을 거쳐 만든 프로시저를 캐싱하지 않고 바로 버린다면 효율적이지 않다.
바인드 변수의 중요성
함수, 프로시저, 패키지, 트리거 등은 각자의 이름을 가지고 있다. 그러나 실행되는 SQL 문은 이름이 없고, 전체 SQL 텍스트가 그 이름 역할을 한다. 전체 SQL 텍스트로 지어진 이름을 가지고 캐싱을 하게 된다. 그러나 SQL 텍스트 이름은 대소문자 구분을 하며, 상수값이 달라지면 다른 SQL로 취급을 하게 된다. 즉, 같은 로직을 실행하는 수많은 SQL 쿼리가 하드 파싱될 수 있다.
하드 파싱을 줄이기 위해서는 루틴이 동일한 프로시저에 대해서는 *바인드 변수를 사용한 파라미터 driven으로 SQL을 설계 해야 하며, 이는 SQL 튜닝의 기초이자 기본이다.
*바인드 변수란 SQL 문에서 특정 부분을 표시해두고, 파라미터 주입을 통해 값을 전달하는 식의 변수이다.
ex) select * from tab where id = ?
데이터 저장 구조 및 I/O 메커니즘
I/O 튜닝이 곧 SQL 튜닝이다. I/O 작업이 일어나는 동안, 프로세스는 잠을 자기 때문이다. 즉, SQL 속도를 높이기 위해서는 I/O 시간을 줄여야 한다.
데이터베이스 저장 구조
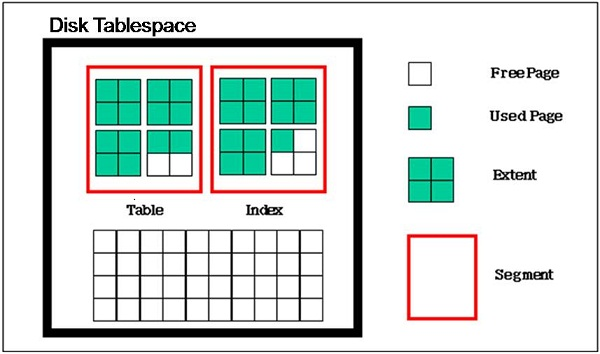
데이터베이스의 구조는 테이블 스페이스, 세그먼트, 익스텐트, 블록(페이지)으로 구성되어 있다.
- 테이블 스페이스 : 세그먼트를 담는 컨테이너
- 세그먼트 : 데이터 저장공간이 필요한 오브젝트 (ex. 테이블, 인덱스)
- 익스텐트 : 공간 부족시 공간 확장의 단위, 연속된 블록들의 집합
- 블록(페이지) : 레코드를 실제로 저장하는 공간, 하나의 테이블 독점
데이터 파일은 디스크 상의 물리적인 OS 파일이며, 익스텐트와 블록을 저장하는 파일이다. 이때 하나의 데이터 파일에는 여러 익스텐트가 들어갈 수 있으며, 각각 다른 세그먼트일 수도 있다. 즉, 하나의 세그먼트가 여러 개의 데이터 파일에 나뉘어 담길 수 있다. 세그먼트를 조회하기 위해서는 아래 쿼리를 통해 DBA_EXTENTS 뷰에서 조회할 수 있다.
SQL> select segment_type, tablespace_name, extent_id, file_id, block_id, blocks \
from dba_extents \
where owner = USER \
and segment_name = 'MY_SEGMENT' \
order by extent_id;각각의 요소들의 관계를 ERD로 표현하면 아래와 같다.
시퀀셜 액세스 vs 랜덤 액세스
I/O 의 최소 단위는 블록이다. 따라서 특정 레코드를 하나 읽고 싶어도 하나의 블록을 통째로 읽는다. 테이블 뿐만 아니라 인덱스도 블록 단위로 데이터를 읽고 쓴다.
테이블 또는 인덱스 블록을 읽는 방식으로는 시퀀셜(Sequential, 순차적) 액세스, 랜덤(Random) 액세스 두 가지 방법이 있다.
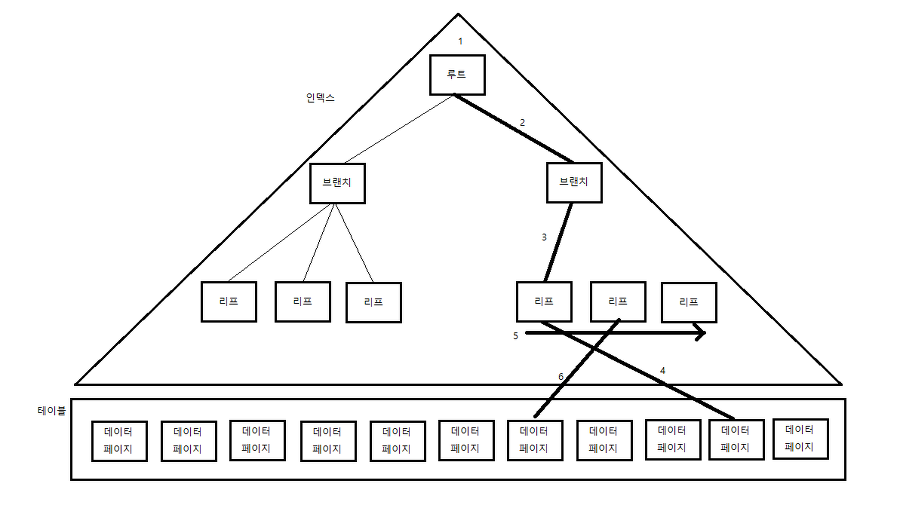
5번 화살표처럼 순차적으로 읽는 것을 시퀀셜 액세스, 나머지 1, 2, 3, 4, 6번 화살표처럼 랜덤하게 접근하는 것을 랜덤 액세스라고 한다.
오라클 기준으로, 시퀀셜 액세스를 위해서는 세그먼트 헤더에 맵(map)으로 관리되는 익스텐트 목록에서 각 익스텐트의 첫 번째 블록의 값을 찾는다. 그 찾은 블록부터 순서대로 읽으면, 그것이 곧 Full Table Scan이다.
랜덤 액세스는 논리적, 물리적 순서를 따르지 않고, 한 블록씩 접근하는 방식이다. 랜덤 액세스의 자세한 매커니즘은 뒤의 내용에서 설명.
논리적 I/O vs 물리적 I/O
위에서 살펴본 SGA에는 DB 버퍼 캐시(Database Buffer Cache)라는 공간이 있다. 위에서 말한 라이브러리 캐시가 '코드 캐시'라면, DB 버퍼 캐시는 '데이터 캐시'라고 할 수 있다. 이름에서 짐작할 수 있듯, SQL 결과의 데이터 블록을 캐싱해두고, 이후 요청에서 DB 버퍼 캐시에서 필요한 블록을 찾아 리턴한다. 이 경우 디스크에서 읽지 않으므로 성능 저하가 발생하지 않는다.
논리적 I/O는 SQL문을 처리하는 과정에서 메모리 버퍼캐시에서 발생한 총 블록 I/O를 말하며, 물리적 I/O는 디스크에서 발생한 총 블록 I/O를 말한다. 메모리 I/O는 전기적 신호인데 반해, 디스크 I/O는 물리적 작용이므로, 디스크 I/O가 메모리 I/O가 보통 10,000배쯤 느리다. 즉, 물리적 I/O 역시 논리적 I/O에 반해 그 만큼 느리다.
논리적 I/O는 즉, SQL을 수행하면서 총 읽은 I/O양이다. 이 양은 같은 실행을 몇 번을 반복해도 동일하다. 반면 물리적 I/O는 디스크에서 읽은 I/O양이다. DB 버퍼 캐시가 있기 때문에, 이 양은 실행하면 할 때마다 더 줄어든다.
버퍼 캐시 히트율(Buffer Cache Hit Ratio, BCHR) 이란 버퍼 캐시 효율을 측정하는 데 전통적으로 가장 많이 사용해 온 지표이다. 구하는 공식은 다음과 같다.
BHCR = ( 캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록 수) x 100
= ( (논리적 I/O - 물리적 I/O) / 논리적 I/O ) x 100
= ( 1- (물리적 I/O) / (논리적 I/0) ) x 100공식에서 알 수 있듯이, BCHR은 읽은 전체 블록 중에서 물리적인 디스크 I/O를 수반하지 않고 곧바로 메모리에서 찾은 비율을 나타낸다. 이 공식에서 알 수 있는 것은, 물리적 I/O가 성능을 결정하지만, 실제 SQL 성능을 향상하려면 물리적 I/O가 아닌 논리적 I/O를 줄여야 한다는 것이다. 물리적 I/O는 시스템 상황에 의해 결정되는 통제 불가능한 외생변수이지만, 논리적 I/O는 SQL을 튜닝해서 읽는 총 블록 개수를 줄임으로서 통제할 수 있는 내생변수이다. 즉, SQL을 튜닝한다는 것은 논리적 I/O를 줄임으로서 물리적 I/O를 줄이는 것이다.
이미지 출처
http://wiki.gurubee.net/pages/viewpage.action?pageId=26743025
https://www.dbacentre.com/overview-of-the-system-global-area/
http://www.gurubee.net/lecture/2163
https://cchoimin.tistory.com/entry/%ED%85%8C%EC%9D%B4%EB%B8%94-%EC%97%91%EC%84%B8%EC%8A%A4%EA%B3%BC%EC%A0%95
