Topics covered
- Availability and reliability
- Reliability requirements
- Programming for reliability
Software reliability
- In general, software customers expect all software to be dependable.
- However, for non-critical applications, they may be willing to accept some system failures.
- Some applications (critical systems) have very high reliability requirements and special software engineering techniques may be used to achieve this.
- Medical systems
- Telecommunications and power systems
- Aerospace systems
소프트웨어 신뢰성
- 대체로, 사용자들은 소프트웨어가 믿을 수 있고 신뢰할 수 있기를 기대합니다.
- 그러나, 비임계적인 애플리케이션의 경우, 사용자들은 일부 시스템 결함을 받아들일 수도 있습니다.
- 일부 애플리케이션(임계 시스템)은 매우 높은 신뢰성 요구 사항이 있으며, 이를 달성하기 위해 특수한 소프트웨어 공학 기법을 사용할 수 있습니다.
- 의료 시스템
- 통신 및 전력 시스템
- 항공우주 시스템
Faults, errors and failures
| Term | Description |
|---|---|
| Human error or mistake | Human behavior that results in the introduction of faults into a system. |
| System fault | A characteristic of a software system that can lead to a system error. |
| System error | An erroneous system state that can lead to system behavior that is unexpected by system users. |
| System failure | An event that occurs at some point in time when the system does not deliver a service as expected by its users. |
결함, 오류, 실패
- 인간의 실수나 오류로 인해 시스템 내 결함이 발생할 수 있습니다.
- 시스템 결함은 시스템 오류로 이어질 수 있는 소프트웨어 시스템의 특성입니다.
- 시스템 오류는 시스템 사용자에게 예상치 못한 동작을 초래할 수 있는 잘못된 시스템 상태입니다.
- 시스템 실패는 시스템이 사용자의 기대에 따라 서비스를 제공하지 못하는 시점에 발생하는 사건입니다.
Faults and failures
- Failures are a usually a result of system errors that are derived from faults in the system
- However, faults do not necessarily result in system errors.
- The erroneous system state resulting from the fault may be transient and ‘corrected’ before an error arises.
- The faulty code may never be executed.
- Errors do not necessarily lead to system failures.
- The error can be corrected by built-in error detection and recovery
- The failure can be protected against by built-in protection facilities.
결함과 실패
- 실패는 대개 시스템 내 결함에서 유래한 시스템 오류의 결과입니다.
- 그러나 결함이 반드시 시스템 오류로 이어지지는 않습니다.
- 결함으로 인한 오류 상태가 일시적이거나 오류가 발생하기 전에 '수정'될 수 있습니다.
- 결함이 있는 코드가 실행되지 않을 수 있습니다.
- 오류가 반드시 시스템 실패로 이어지지 않습니다.
- 내장 오류 감지 및 복구 기능을 통해 오류를 수정할 수 있습니다.
- 내장 보호 시설을 통해 실패를 막을 수 있습니다.
Fault management and Reliability Achievement
- Fault avoidance
- The system is developed in such a way that human error is avoided and thus system faults are minimised.
- The development process is organised so that faults in the system are detected and repaired before delivery to the customer.
- Fault detection
- Verification and validation techniques are used to discover and remove faults in a system before it is deployed.
- Fault tolerance
- The system is designed so that faults in the delivered software do not result in system failure.
결함 관리와 신뢰성 달성
- 결함 회피
- 시스템이 인간의 오류를 피할 수 있도록 개발되어 결함이 최소화됩니다.
- 개발 과정이 조직화되어 시스템 내의 결함이 고객에게 전달되기 전에 감지되고 수정됩니다.
- 결함 탐지
- 검증 및 확인 기술을 사용하여 시스템 내의 결함을 발견하고 배포 전에 제거합니다.
- 결함 허용
- 시스템이 설계되어 배포된 소프트웨어 내의 결함이 시스템 실패로 이어지지 않습니다.
결함 회피, 결함 탐지, 그리고 결함 허용은 신뢰성 엔지니어링의 주요 요소로, 소프트웨어 시스템의 신뢰성을 높이기 위해 사용됩니다. 이들 기법은 개발 과정에서의 인간의 실수와 결함을 줄이거나, 이미 발생한 결함을 찾아내고 수정하거나, 결함이 발생했을 때 시스템이 안정적으로 작동할 수 있도록 보장하는 데 도움이 됩니다. 이러한 접근 방식을 사용하면, 소프트웨어가 더 안정적이고 사용자의 기대에 부응하는 서비스를 제공할 수 있습니다.
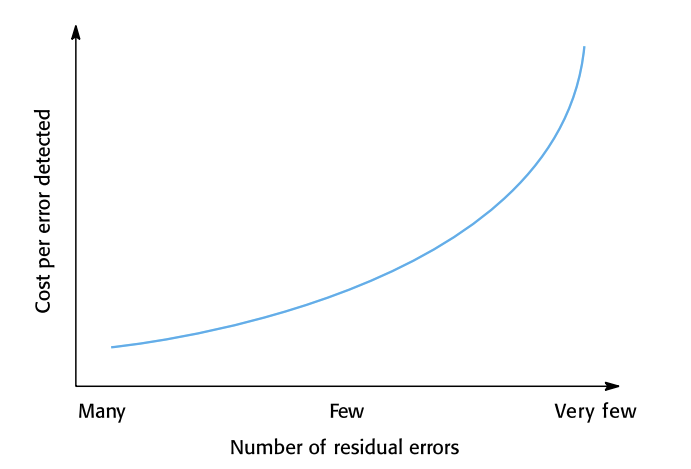
The increasing costs of residual fault removal
Availability and reliability
Availability and reliability
- Reliability
- The probability of failure-free system operation over a specified time in a given environment for a given purpose.
- Availability
- The probability that a system, at a point in time, will be operational and able to deliver the requested services
- Both of these attributes can be expressed quantitatively.
- e.g.) Availability of 0.999 means that the system is up and running for 99.9% of the time.
가용성과 신뢰성
- 신뢰성
- 주어진 환경에서 특정 목적을 위해 지정된 시간 동안 시스템이 결함 없이 작동할 확률입니다.
- 가용성
- 특정 시점에 시스템이 작동 중이고 요청된 서비스를 제공할 수 있는 확률입니다.
- 이 두 속성은 양적으로 표현될 수 있습니다.
- 예를 들어, 가용성이 0.999라는 것은 시스템이 99.9%의 시간 동안 가동되고 있다는 것을 의미합니다.
Reliability and specifications
- Reliability can only be defined formally with respect to a system specification.
- i.e.) a failure is a deviation from a specification.
- However, many specifications are incomplete or incorrect – hence, a system that conforms to its specification may ‘fail’ from the perspective of system users.
- Furthermore, users don’t read specifications so don’t know how the system is supposed to behave.
- Therefore perceived reliability is more important in practice.
신뢰성과 사양
- 신뢰성은 시스템 사양에 대한 공식적인 정의와 관련이 있습니다.
- 즉, 실패란 사양에서 벗어난 것입니다.
- 그러나 많은 사양이 불완전하거나 잘못될 수 있으므로, 사양을 준수하는 시스템이 사용자 관점에서 '실패'할 수 있습니다.
- 게다가 사용자들은 사양서를 읽지 않아 시스템이 어떻게 동작해야 하는지 모릅니다.
- 따라서 인식된 신뢰성이 실제로 더 중요합니다.
Perceptions of reliability
- The formal definition of reliability does not always reflect the user’s perception of a system’s reliability.
- The assumptions that are made about the environment where a system will be used may be incorrect.
- Usage of a system in crowded transportation provides quite different environment compared to use the same system at home.
- The consequences of system failures affects the perception of reliability.
- Failures that have serious consequences (such as an engine breakdown in a car) are given greater weight by users than failures that are inconvenient.
신뢰성 인식
- 신뢰성의 공식적인 정의는 항상 사용자의 시스템 신뢰성 인식과 일치하지 않습니다.
- 시스템이 사용될 환경에 대한 가정이 잘못될 수 있습니다.
- 혼잡한 교통 환경에서 시스템을 사용하는 것은 집에서 동일한 시스템을 사용하는 것과는 매우 다른 환경을 제공합니다.
- 시스템 실패의 결과가 신뢰성 인식에 영향을 줍니다.
- 심각한 결과를 초래하는 실패(예: 자동차 엔진 고장)는 불편한 실패보다 사용자에게 더 큰 무게를 줍니다.
Availability perception
- Availability is usually expressed as a percentage of the time that the system is available to deliver services. e.g., 99.95%.
- However, this does not take into account two factors:
- The number of users affected by the service outage: Loss of service in the middle of the night is less important for many systems than loss of service during peak usage periods.
- The length of the outage: The longer the outage, the more the disruption. Several short outages are less likely to be disruptive than 1 long outage. Long repair times are a particular problem.
가용성 인식
- 가용성은 일반적으로 시스템이 서비스를 제공할 수 있는 시간의 백분율로 표현됩니다. 예를 들어 99.95%.
- 그러나 이것은 다음 두 가지 요소를 고려하지 않습니다.
- 서비스 중단으로 인해 영향을 받는 사용자 수: 많은 시스템에서 밤 중간의 서비스 손실은 사용자가 많은 시간 동안 서비스를 사용하지 않기 때문에 사용자가 많은 시간 동안 서비스 손실보다 중요하지 않습니다.
- 중단 시간의 길이: 중단 시간이 길수록 방해가 더 커집니다. 여러 차례 짧은 중단보다 한 번의 긴 중단이 방해가 될 가능성이 높습니다. 긴 수리 시간은 특히 문제가 됩니다.
Reliability in use
- Removing X% of the faults in a system will not necessarily improve the reliability by X%.
- Program defects may be in rarely executed sections of the code so may never be encountered by users.
- Removing these does not affect the perceived reliability.
- Users adapt their behaviour to avoid system features that may fail for them.
- A program with known faults may therefore still be perceived as reliable by its users.
사용 중인 신뢰성
- 시스템에서 X%의 결함을 제거하면 신뢰성이 반드시 X% 향상되는 것은 아닙니다.
- 프로그램 결함은 코드의 실행 빈도가 낮은 부분에 있을 수 있으므로 사용자에게 발견되지 않을 수 있습니다.
- 이러한 결함을 제거하면 인식된 신뢰성에 영향을 주지 않습니다.
- 사용자는 시스템에서 실패할 수 있는 기능을 피하기 위해 행동을 조정합니다.
- 알려진 결함이 있는 프로그램도 사용자에게 신뢰할 수 있다고 인식될 수 있습니다.
결론적으로, 가용성과 신뢰성은 소프트웨어 시스템에서 중요한 측면입니다. 사용자의 인식된 가용성과 신뢰성은 실제로 양적으로 측정된 가용성과 신뢰성보다 더 중요한 경우가 많습니다. 이를 고려하여 소프트웨어를 개발하고 유지 관리하면 사용자에게 더 나은 경험을 제공할 수 있습니다.
Reliability requirements
System reliability requirements
- Functional reliability requirements define system and software functions that avoid, detect or tolerate faults in the software and so ensure that these faults do not lead to system failure.
- Software reliability requirements may also be included to cope with hardware failure or operator error.
- Reliability is a measurable system attribute so non-functional reliability requirements may be specified quantitatively.
- These define the number of failures that are acceptable during normal use of the system or the time in which the system must be available.
시스템 신뢰성 요구사항
- 기능적 신뢰성 요구사항은 시스템 및 소프트웨어 기능을 정의하여 소프트웨어 결함을 피하거나, 감지하거나, 허용함으로써 이러한 결함이 시스템 실패로 이어지지 않게 합니다.
- 소프트웨어 신뢰성 요구사항은 하드웨어 실패나 운영자 오류에 대처하기 위해 포함될 수도 있습니다.
- 신뢰성은 측정 가능한 시스템 속성이므로 비기능적 신뢰성 요구사항은 정량적으로 지정될 수 있습니다.
- 이러한 요구사항은 시스템이 정상적으로 사용될 때 허용되는 실패 횟수 또는 시스템이 사용 가능해야 하는 시간을 정의합니다.
Reliability metrics
- Reliability metrics are units of measurement of system reliability.
- System reliability is measured by counting the number of operational failures and, where appropriate, relating these to the demands made on the system and the time that the system has been operational.
- A long-term measurement program is required to assess the reliability of critical systems.
- Metrics
- Probability of failure on demand
- Rate of occurrence of failures/Mean time to failure
- Availability
신뢰성 지표
- 신뢰성 지표는 시스템 신뢰성의 측정 단위입니다.
- 시스템 신뢰성은 운영 실패 횟수를 세어 측정하며, 필요한 경우 시스템에 대한 요구와 시스템이 작동한 시간과 관련하여 이를 고려합니다.
- 중요한 시스템의 신뢰성을 평가하기 위해서는 장기적인 측정 프로그램이 필요합니다.
- 지표
- 요구 시 실패 확률
- 실패 발생률/평균 고장 시간
- 가용성
Probability of failure on demand
POFOD
- This is the probability that the system will fail when a service request is made.
- Useful when demands for service are intermittent and relatively infrequent.
- Appropriate for protection systems where services are demanded occasionally and where there are serious consequence if the service is not delivered.
- Relevant for many safety-critical systems with exception management components
- Emergency shutdown system in a chemical plant.
요구 시 실패 확률
POFOD
- 서비스 요청이 이루어질 때 시스템이 실패할 확률입니다.
- 서비스 요청이 간헐적이고 비교적 드문 경우에 유용합니다.
- 서비스가 가끔 요청되고 서비스가 제공되지 않을 경우 심각한 결과가 발생하는 보호 시스템에 적합합니다.
- 예외 관리 컴포넌트가 있는 많은 안전 중심 시스템에 관련이 있습니다.
- 화학 공장의 긴급 정지 시스템.
Rate of occurrence of failures
ROCOF
- Reflects the rate of occurrence of failure in the system.
- ROCOF of 0.002 means 2 failures are likely in each 1000 operational time units e.g. 2 failures per 1000 hours of operation.
- Relevant for systems where the system has to process a large number of similar requests in a short time.
- Credit card processing system, airline booking system.
- Reciprocal of ROCOF is Mean time to Failure (MTTF)
- Relevant for systems with long transactions, i.e., where system processing takes a long time (e.g. CAD systems).
- MTTF should be longer than expected transaction length.
실패 발생률
ROCOF
- 시스템에서 실패가 발생하는 비율을 반영합니다.
- ROCOF가 0.002인 경우 1000개의 운영 시간 단위마다 2회의 실패가 발생할 가능성이 있습니다 (예: 운영 1000시간당 2회의 실패).
- 시스템이 짧은 시간 내에 많은 유사한 요청을 처리해야 하는 경우와 관련이 있습니다.
- 신용카드 처리 시스템, 항공 예약 시스템.
- ROCOF의 역수는 평균 고장 시간(MTTF)입니다.
- 시스템 처리 시간이 오래 걸리는 긴 거래와 관련이 있습니다 (예: CAD 시스템).
- MTTF는 예상 거래 기간보다 길어야 합니다.
Availability
AVAIL
- Measure of the fraction of the time that the system is available for use.
- Takes repair and restart time into account
- Availability of 0.998 means software is available for 998 out of 1000 time units.
- Relevant for non-stop, continuously running systems.
- telephone switching systems, railway signaling systems.
가용성
AVAIL
- 시스템이 사용 가능한 시간의 일부분을 측정하는 지표입니다.
- 수리 및 재시작 시간을 고려합니다.
- 가용성이 0.998인 경우, 소프트웨어는 1000개의 시간 단위 중 998개에서 사용 가능합니다.
- 끊임없이 지속적으로 실행되는 시스템과 관련이 있습니다.
- 전화 교환 시스템, 철도 신호 시스템.
Non-functional reliability requirements
- Non-functional reliability requirements are specifications of the required reliability and availability of a system using one of the reliability metrics (POFOD, ROCOF or AVAIL).
- Quantitative reliability and availability specification has been used for many years in safety-critical systems,
- but is uncommon for business critical systems.
- However, as more and more companies demand 24/7 service from their systems,
- it makes sense for them to be precise about their reliability and availability expectations.
비기능적 신뢰성 요구사항
- 비기능적 신뢰성 요구사항은 신뢰성 지표(POFOD, ROCOF 또는 AVAIL) 중 하나를 사용하여 시스템의 필요한 신뢰성과 가용성을 명시합니다.
- 정량적인 신뢰성 및 가용성 명세는 수년간 안전 중심 시스템에서 사용되어 왔습니다.
- 그러나 비즈니스 중심 시스템에서는 드물게 사용됩니다.
- 그러나 점점 더 많은 회사들이 시스템에서 24/7 서비스를 요구함에 따라,
- 신뢰성 및 가용성 기대치에 대해 정확하게 명시하는 것이 바람직합니다.
Benefits of reliability specification
- The process of deciding the required level of the reliability helps to clarify what stakeholders really need.
- It provides a basis for assessing when to stop testing a system.
- You stop when the system has reached its required reliability level.
- It is a means of assessing different design strategies intended to improve the reliability of a system.
- If a regulator has to approve a system (e.g. all systems that are critical to flight safety on an aircraft are regulated), then evidence that a required reliability target has been met is important for system certification.
신뢰성 명세의 이점
- 필요한 신뢰성 수준을 결정하는 과정은 이해당사자들이 실제로 필요한 것을 명확하게 하는 데 도움이 됩니다.
- 시스템 테스트를 언제 중단할지 결정하는 기준을 제공합니다.
- 시스템이 필요한 신뢰성 수준에 도달했을 때 중단합니다.
- 시스템의 신뢰성을 개선하려는 다양한 설계 전략을 평가하는 수단이 됩니다.
- 규제기관이 시스템을 승인해야 하는 경우(예: 항공기의 비행 안전에 대한 모든 시스템은 규제됩니다), 필요한 신뢰성 목표가 충족되었다는 증거가 시스템 인증에 중요합니다.
Specifying reliability requirements
- Specify the availability and reliability requirements for different types of failure.
- There should be a lower probability of high-cost failures than failures that don’t have serious consequences.
- Specify the availability and reliability requirements for different types of system service.
- Critical system services should have the highest reliability but you may be willing to tolerate more failures in less critical services.
- Think about whether a high level of reliability is really required.
- Other mechanisms can be used to provide reliable system service.
신뢰성 요구사항 지정하기
- 다양한 종류의 실패에 대한 가용성 및 신뢰성 요구사항을 명시합니다.
- 심각한 결과를 초래하지 않는 실패보다 고비용 실패의 확률이 낮아야 합니다.
- 시스템 서비스의 다양한 유형에 대한 가용성 및 신뢰성 요구사항을 명시합니다.
- 중요한 시스템 서비스는 가장 높은 신뢰성을 가져야 하지만, 덜 중요한 서비스에서는 더 많은 실패를 감수할 수 있습니다.
- 높은 수준의 신뢰성이 실제로 필요한지 여부를 고려합니다.
- 신뢰할 수 있는 시스템 서비스를 제공하는 데 다른 메커니즘이 사용될 수 있습니다.
Functional reliability requirements
- Checking requirements that identify checks to ensure that incorrect data is detected before it leads to a failure.
- Recovery requirements that are geared to help the system recover after a failure has occurred.
- Redundancy requirements that specify redundant features of the system to be included.
- Process requirements for reliability which specify the development process to be used may also be included.
기능적 신뢰성 요구사항
- 잘못된 데이터가 실패로 이어지기 전에 감지되도록 하는 확인 요구사항을 포함합니다.
- 실패가 발생한 후 시스템이 복구되도록 하는 복구 요구사항을 포함합니다.
- 시스템의 중복 기능을 명시하는 중복 요구사항을 포함합니다.
- 신뢰성을 위한 프로세스 요구사항도 포함될 수 있으며, 이는 사용될 개발 프로세스를 명시합니다.
Programming for reliability
Dependable programming
- Good programming practices can be adopted that help reduce the incidence of program faults.
- These programming practices support
- Fault avoidance
- Fault detection
- Fault tolerance
신뢰할 수 있는 프로그래밍
- 프로그램 결함 발생률을 줄이는데 도움이 되는 좋은 프로그래밍 관행을 채택할 수 있습니다.
- 이러한 프로그래밍 관행은 다음을 지원합니다.
- 결함 회피
- 결함 탐지
- 결함 허용
Good practice guidelines for dependable programming
- Dependable programming guidelines
- 1.Limit the visibility of information in a program.
- 2.Check all inputs for validity.
- 3.Provide a handler for all exceptions.
- 4.Minimize the use of error-prone constructs.
- 5.Provide restart capabilities.
- 6.Check array bounds.
- 7.Include timeouts when calling external components.
- 8.Name all constants that represent real-world values.
신뢰할 수 있는 프로그래밍을 위한 좋은 관행 가이드라인
- 신뢰할 수 있는 프로그래밍 지침
- 프로그램에서 정보의 가시성을 제한하십시오.
- 모든 입력의 유효성을 확인하십시오.
- 모든 예외에 대한 처리기를 제공하십시오.
- 오류가 발생하기 쉬운 구조의 사용을 최소화하십시오.
- 재시작 기능을 제공하십시오.
- 배열 경계를 확인하십시오.
- 외부 구성 요소를 호출할 때 시간 제한을 포함하십시오.
- 실세계 값에 해당하는 모든 상수에 이름을 지정하십시오.
1. Limit the visibility of information in a program
- Program components should only be allowed access to data that they need for their implementation.
- This means that accidental corruption of parts of the program state by these components is impossible.
- You can control visibility by using abstract data types where the data representation is private and you only allow access to the data through predefined operations such as get() and put().
1.프로그램에서 정보의 가시성을 제한하십시오
- 프로그램 구성 요소는 구현에 필요한 데이터에만 액세스할 수 있어야 합니다.
- 이는 해당 구성 요소로 인해 프로그램 상태의 일부가 실수로 손상되는 것이 불가능하다는 것을 의미합니다.
- 추상 데이터 유형을 사용하여 데이터 표현이 비공개이고 데이터에 대한 액세스를 get() 및 put()과 같은 미리 정의된 작업을 통해서만 허용함으로써 가시성을 제어할 수 있습니다.
2. Check all inputs for validity
- All program take inputs from their environment and make assumptions about these inputs.
- However, program specifications rarely define what to do if an input is not consistent with these assumptions.
- Consequently, many programs behave unpredictably when presented with unusual inputs and, sometimes, these are threats to the security of the system.
- Consequently, you should always check inputs before processing against the assumptions made about these inputs.
2.모든 입력의 유효성을 확인하십시오
- 모든 프로그램은 환경으로부터 입력을 받고 이러한 입력에 대해 가정을 합니다.
- 그러나 프로그램 명세는 입력이 이러한 가정과 일치하지 않는 경우 무엇을 해야 하는지 정의하지 않습니다.
- 따라서 많은 프로그램은 특이한 입력이 제공될 때 예측할 수 없는 방식으로 작동하며, 때로는 이러한 것들이 시스템의 보안에 위협이 됩니다.
- 결과적으로 이러한 입력에 대한 가정을 처리하기 전에 항상 입력을 확인해야 합니다.
3. Provide a handler for all exceptions
- A program exception is an error or some unexpected event such as a power failure.
- Exception handling constructs allow for such events to be handled without the need for continual status checking to detect exceptions.
- Using normal control constructs to detect exceptions needs many additional statements to be added to the program.
- This adds a significant overhead and is potentially error-prone.
- Exception handling is a mechanism to provide some fault tolerance.
3.모든 예외에 대한 처리기를 제공하십시오
- 프로그램 예외는 오류 또는 예기치 않은 이벤트(예: 전원 고장)와 같은 것입니다.
- 예외 처리 구조를 사용하면 예외를 감지하기 위해 지속적인 상태 검사가 필요하지 않고 이러한 이벤트를 처리할 수 있습니다.
- 예외를 감지하기 위해 일반 제어 구조를 사용하면 프로그램에 많은 추가 문장을 추가해야 합니다.
- 이는 상당한 오버헤드를 추가하며 잠재적으로 오류가 발생할 수 있습니다.
- 예외 처리는 결함 허용성을 제공하는 메커니즘입니다.
4. Minimize the use of error-prone constructs
- Program faults are usually a consequence of human error,
- because programmers lose track of the relationships between the different parts of the system.
- This is exacerbated by error-prone constructs in programming languages that are
- inherently complex or that don’t check for mistakes when they could do so.
- e.g.) goto, FP numbers, Pointers, Dynamic Memory Allocation, etc.
- Therefore, when programming, you should try to avoid or at least minimize the use of these error-prone constructs.
4.오류가 발생하기 쉬운 구조의 사용을 최소화하십시오
- 프로그램 결함은 대개 인간의 오류로 인해 발생합니다.
- 프로그래머들이 시스템의 다른 부분과의 관계를 파악하지 못하기 때문입니다.
- 프로그래밍 언어의 오류가 발생하기 쉬운 구조는 본질적으로 복잡하거나 실수를 확인하지 않을 때 이를 확인할 - 수 있는데 사용하지 않습니다.
- 예: goto, 부동 소수점 숫자, 포인터, 동적 메모리 할당 등
- 따라서 프로그래밍할 때 오류가 발생하기 쉬운 이러한 구조를 피하거나 적어도 사용을 최소화해야 합니다.
5. Provide restart capabilities
- For systems that involve long transactions or user interactions,
- you should always provide a restart capability that allows the system to restart after failure,
- without users having to redo everything that they have done.
- Restart depends on the type of system
- Keep copies of forms so that users don’t have to fill them in again if there is a problem.
- Save state periodically and restart from the saved state.
5.재시작 기능을 제공하십시오
- 긴 트랜잭션이나 사용자 상호 작용이 포함된 시스템의 경우,
- 실패 후 시스템이 사용자가 다시 모든 작업을 수행할 필요 없이 재시작할 수 있도록 재시작 기능을 항상 제공해야 합니다.
- 재시작은 시스템 유형에 따라 다릅니다.
- 문제가 발생한 경우 사용자가 다시 작성할 필요가 없도록 양식 사본을 보관합니다.
- 주기적으로 상태를 저장하고 저장된 상태에서 재시작합니다.
6. Check array bounds
- In some programming languages, such as C, it is possible to address a memory location outside of the range allowed for in an array declaration.
- This leads to the well-known ‘bounded buffer’ vulnerability,
- where attackers write executable code into memory by deliberately writing beyond the top element in an array.
- If your language does not include bound checking,
- you should therefore always check that an array access is within the bounds of the array.
6.배열 경계를 확인하십시오
- C와 같은 일부 프로그래밍 언어에서는 배열 선언에 허용된 범위를 벗어난 메모리 위치에 액세스할 수 있습니다.
- 이로 인해 '경계가 지정된 버퍼' 취약점이 발생하며,
- 공격자가 배열의 최상위 요소를 넘어서 의도적으로 메모리에 실행 가능한 코드를 작성합니다.
- 언어가 경계 검사를 포함하지 않는 경우 배열 액세스가 배열의 경계 내에 있는지 항상 확인해야 합니다.
7. Include timeouts when calling external components
- In a distributed system, failure of a remote computer can be ‘silent’,
- so that programs expecting a service from that computer may never receive that service or any indication that there has been a failure.
- To avoid this, you should always include timeouts on all calls to external components.
- After a defined time period has elapsed without a response,
- your system should then assume failure and take whatever actions are required to recover from this.
7.외부 구성 요소를 호출할 때 시간 제한을 포함하십시오
- 분산 시스템에서 원격 컴퓨터의 실패는 '침묵의 실패'일 수 있습니다.
- 즉, 해당 컴퓨터로부터 서비스를 기대하는 프로그램이 서비스를 받지 못하거나 실패에 대한 어떠한 표시도 받지 못할 수 있습니다.
- 이를 방지하기 위해 외부 구성 요소에 대한 모든 호출에 시간 제한을 포함해야 합니다.
- 응답 없이 정의된 시간이 경과한 후에 시스템은 실패를 가정하고 이로부터 회복하기 위해 필요한 조치를 취해야 합니다.
8. Name all constants that represent real-world values
- Always give constants that reflect real-world values (such as tax rates) names rather than using their numeric values and always refer to them by name.
- e.g.) public static final PI = 3.14159;
- You are less likely to make mistakes and type the wrong value when you are using a name rather than a value.
- This means that when these ‘constants’ change (for sure, they are not really constant),
- then you only have to make the change in one place in your program.
8.실세계 값에 해당하는 모든 상수에 이름을 지정하십시오
- 실세계 값(예: 세금율)을 반영하는 상수에 항상 이름을 지정하고 숫자 값을 사용하는 대신 이름을 사용하여 항상 참조하십시오.
- 예: public static final PI = 3.14159;
- 이름을 사용할 때 값보다 실수로 잘못 입력할 가능성이 적습니다.
- 이는 이러한 '상수'가 변경될 때(실제로는 상수가 아님) 프로그램에서 한 곳에서만 변경을 수행해야 함을 의미합니다.
