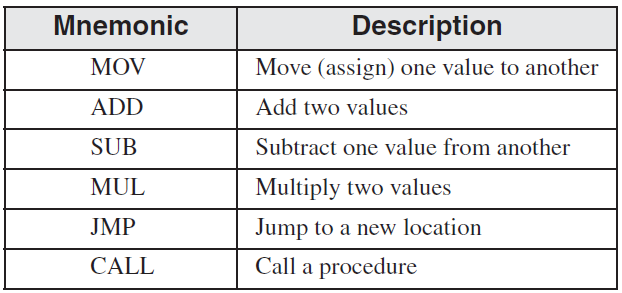
Basic Language Elements
1. First Assembly Language Program
AddTwo program : 간단한 어셈블리어로 짠 프로그램.

각 라인넘버는 프로그램의 파트가 아니다.
위 코드는 간단한 어셈블리어 코드로, Windows API 함수를 호출하여 프로그램을 종료하는 기능을 수행합니다.
해당 코드를 분석해보면:
- main proc 라인은 프로시저 선언을 나타냅니다. main 이라는 이름의 프로시저가 정의되고 있으며, proc 키워드를 사용하여 선언합니다.
- mov eax, 5 라인은 5를 EAX 레지스터에 저장합니다. EAX 레지스터는 일반적으로 값을 계산하거나 함수의 반환값을 저장하는 데 사용됩니다.
- add eax, 6 라인은 EAX 레지스터에 6을 더합니다. 따라서 EAX 레지스터에는 5+6=11이 저장됩니다.
- INVOKE ExitProcess, 0 라인은 Windows API 함수 중 하나인 ExitProcess 함수를 호출합니다. 이 함수는 프로그램을 종료하며, 0을 인수로 전달하여 정상 종료를 나타냅니다.
- 5.main ENDP 라인은 프로시저의 끝을 나타냅니다. ENDP 키워드를 사용하여 프로시저의 끝을 선언합니다.
따라서, 위 코드는 EAX 레지스터에 5와 6을 더한 결과를 구하고, 그 결과값을 출력하지 않고 프로그램을 종료하는 코드입니다.
CPU의 eax에 5를 저장하고, 6을 더하니 eax가 11이 된다.
윈도우가 제공하는 ExitProcess를 사용하여, 프로그램을 종료한다. ,0은 argument라 생각하면 된다. (return 0 같은 느낌이다.)
main ENDP는 메인 함수의 종료를 의미한다.
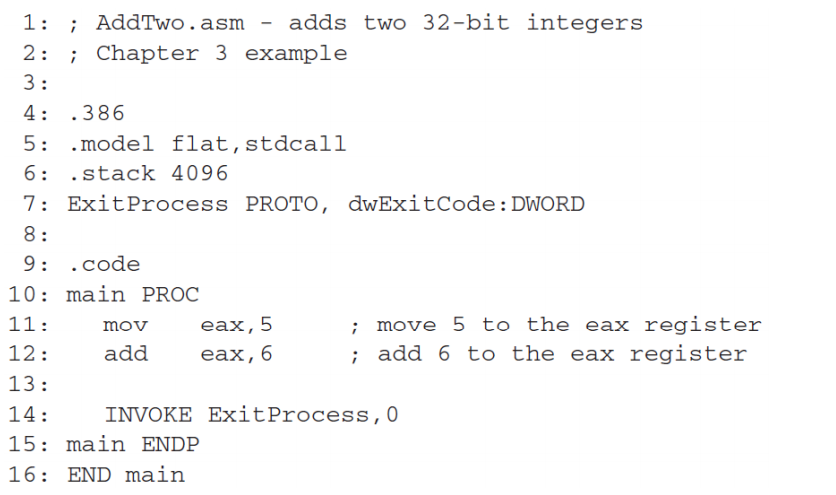
Adding a Variable
Saves the results of our addition in a variable named sum

해당 코드는 어셈블리어로 작성된 코드로, 간단한 변수 선언과 값을 할당하고 프로그램을 종료하는 기능을 수행합니다.
해당 코드를 분석해보면:
- .data 섹션에서 sum 이라는 이름의 DWORD 변수를 0으로 초기화합니다. 이 변수는 이후에 프로그램에서 사용될 수 있습니다.
- .code 섹션에서 main 프로시저가 정의됩니다. 프로시저는 PROC 키워드로 시작하여 ENDP 키워드로 끝나는 코드 블록입니다.
- mov eax, 5 라인은 5를 EAX 레지스터에 저장합니다.
- mov eax, 6 라인은 6을 EAX 레지스터에 저장합니다. 이전에 EAX 레지스터에 저장된 5는 더 이상 사용되지 않습니다.
- mov sum, eax 라인은 EAX 레지스터에 저장된 값을 sum 변수에 저장합니다.
- INVOKE ExitProcess, 0 라인은 Windows API 함수 중 하나인 ExitProcess 함수를 호출합니다. 이 함수는 프로그램을 종료하며, 0을 인수로 전달하여 정상 종료를 나타냅니다.
따라서, 위 코드는 sum 변수에 6을 저장하고 프로그램을 종료하는 코드입니다.
– [Line 2] the sum variable is declared
» We give it a size of 32 bits, using the DWORD size keyword
» Size keyworks only specify a size
– The code segment and the data segment
– Literals, identifiers, directives, instructions, …
sum DWORD은 데이터 세그멘트에 0을 저장
code segment가 이것저것 되어 있는 것이다.
| MEM |
|---|
| 0 |
△ 4칸 전부 sum이다 (4byte)
그런데, 다음으로 진행되면 0이 지워지고 아래와 같이 된다.
| MEM |
|---|
| 11 |
△ 4칸 전부 sum이다 (4byte)
2. Integer Literals
An integer literal is made up of an optional leading sign, one or more digits, and an optional radix
character that indicates the number’s base
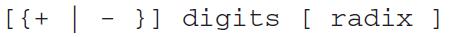
△
앞의 대괄호는 선택적으로 올 수 있다. (부호)
가운데 숫자는 무조건 나와야 한다.
뒤의 대괄호 radix(기수)도 선택적이다. 없으면 10진수를 나타난다.

– A hexadecimal literal beginning with a letter must have a leading zero
△ 16진수 수를 쓸 때는 0으로 시작하고 radix에 h를 쓴다.

3. Constant Integer Expressions
표현식의 결과가 정수인데 항상 상수로 고정되는 것
– A mathematical expression involving integer literals and arithmetic operators
– Each expression must evaluate to an integer, which can be stored in 32 bits (0 through FFFFFFFFh)
– They can only be evaluated at assembly time
– Arithmetic operators
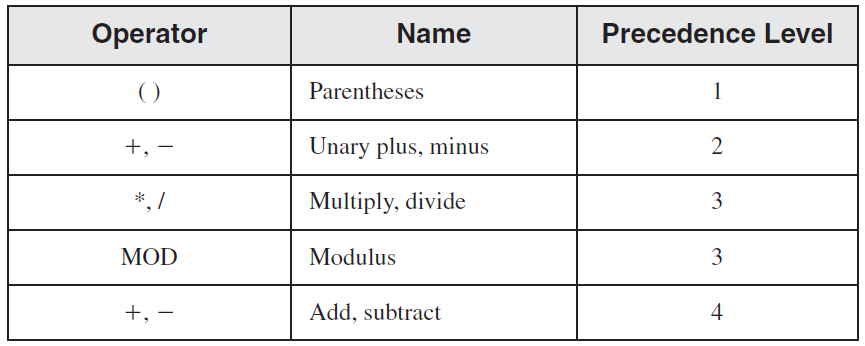

16/5를 하면, 계산이 runtime에 이루지는 게 아니라, 어셈블 타임(컴파일 할 때) 이루어진다.
그리고, 계산 된 결과는 32비트로 저장된다.
4. Real Number Literals (a.k.a. floating-point literals)
Represented as either decimal reals or encoded (hexadecimal) reals
Decimal real

Encoded real

2^23이면... 유효숫자가 80만? 정도밖에 표현을 못한다...
과학이나 수학 같이 큰 범위나 정밀한 결과를 원하면... 64비트를 써야 한다.
1 11 52비트로 나눠진다.
Decimal real은 일반적인 십진법 방식으로 나타낸 실수입니다. 즉, 소수점 이하 자릿수를 가진 수를 표현할 때 사용됩니다. 예를 들어, 0.5, 1.234, 3.141592 등은 모두 십진법 방식으로 표현된 decimal real입니다.
Encoded real은 컴퓨터에서 실수를 표현하기 위해 사용되는 방식 중 하나입니다. 실수를 표현할 때는 부호 비트, 지수 비트, 가수 비트 등으로 구성된 이진 형식을 사용합니다. 이진 형식에서는 소수점 이하 자릿수를 이진법으로 표현하여 저장합니다. Encoded real은 이러한 이진 형식으로 표현된 실수를 의미합니다.
Encoded real은 IEEE 754 표준과 같은 표준에 따라 표현됩니다. 이 표준은 32비트와 64비트 형태의 이진 부동소수점 표현을 제공하며, 부호 비트, 지수 비트, 가수 비트 등으로 이루어져 있습니다. 이진 형식을 사용하므로, decimal real과는 다르게 소수점 이하 자릿수가 정확히 표현되지 않을 수 있습니다.
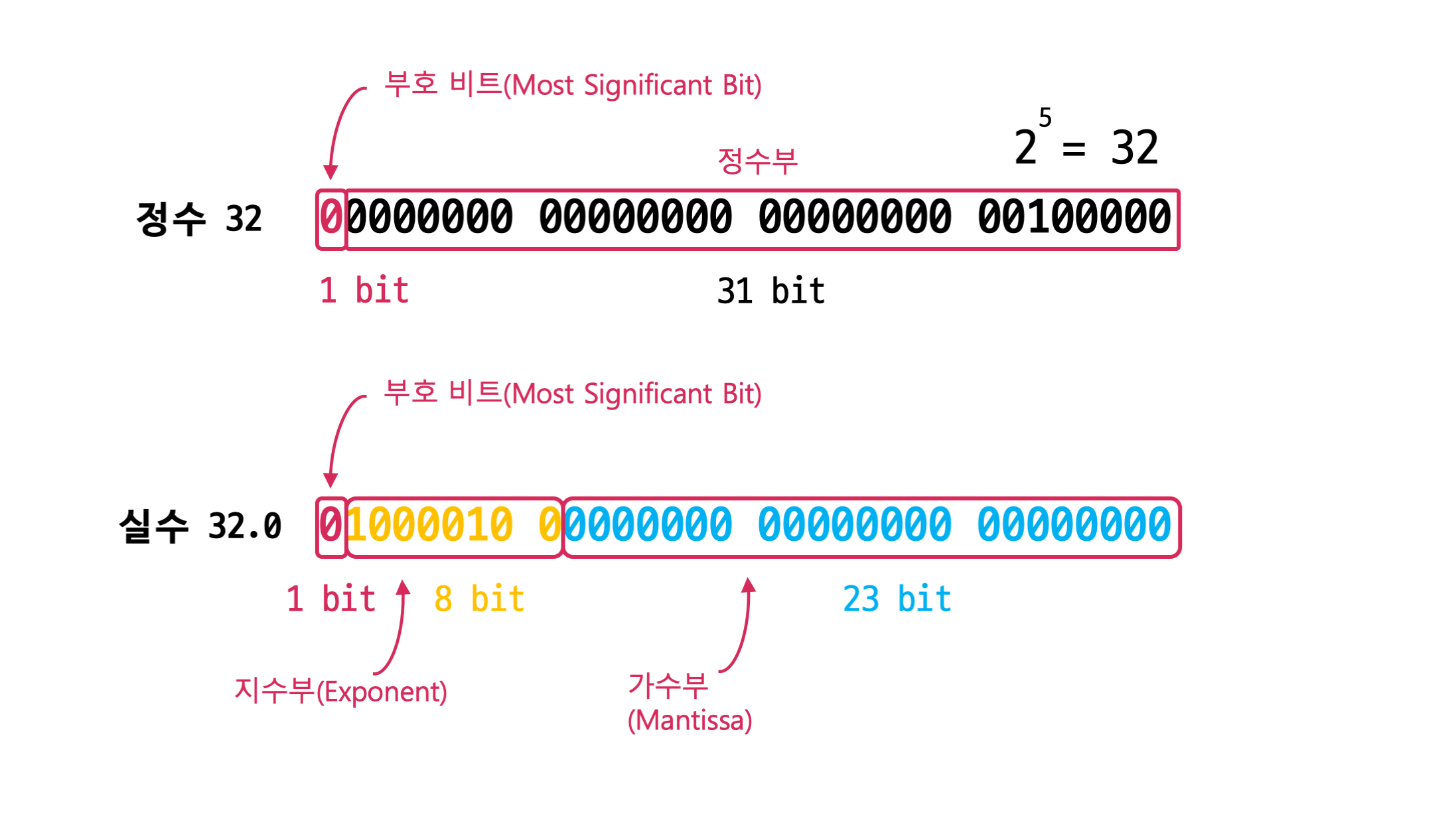
△ 컴퓨터의 수 표현 하는 방법
Decimal Real 예시
예시를 들어 100000.01을 저장해 보자.
100000.01 => 1.000001 x 2^4 이므로,
0 00000100 100000100.... 이 된다
즉, 가운데 8비트는 2의 4승을 나타내고, 1.000001은 23비트에 저장된다.
여기다가, 2의 4승에서 나온 4에 127을 더해서 131이 되고,
1.000001에서 1을 생략해서 0.000001이 된다.
0 10000011 00000100....
최종적으로 위와 같이 정의된다.
예시2로 10.을 저장해보자.
10 => 1.0 x 2^1
0 10000000 000....이 된다.
Encoded Real 예시
40000000r 같이 뒤에 r이 붙으면 Encoded real이다.
1.0 => 1.0 x 2^0
5. Character Literals
문자 하나로 정의 된 상수를 말한다.
- A single character enclosed in single or double quotes
- The assembler stores the value in memory as the character’s binary ASCII code
• E.g.) ‘A’: the number 65 (or 41 hex) is stored in memory
즉, 코드에는 대문자A 대신 그에 해당하는 아스키 코드가 들어간다.
6. String Literals
-
A sequence of characters (including spaces) enclosed in single or double quotes

-
String literals are stored in memory as sequences of integer byte values
• E.g.) the string literal “ABCD” contains the four bytes 41h, 42h, 43h, and 44h
7. Reversed Words
예약어
(ADD 같은 것은 변수이름으로 쓸 수 없다.)
- Have special meaning and can only be used in their correct context
- Not case-sensitive
- Several types of reserved words
Instruction mnemonics, such as MOV, ADD, and MUL
• Register names
• Directives, which tell the assembler how to assemble programs
• Attributes, which provide size and usage information for variables and operands
– E.g.) BYTE, WORD, …
• Operators, used in constant expressions
• Predefined symbols, such as @data, which return constant integer values at assembly time
8. Identifiers (식별자)
- A programmer-chosen name
- It might identify a variable, a constant, a procedure, or a code label
- Rules on how they can be formed
• They may contain between 1 and 247 characters
• They are not case sensitive
• The first character must be a letter (A..Z, a..z), underscore (_), @ , ?, or $
– Subsequent characters may also be digits
• An identifier cannot be the same as an assembler reserved word

9. Directives
지시어, 어셈블리어에 의해서 인식되어 동작한다.
CPU가 메모리에서 Fetch(레지스터에서 옮겨오는...)해오는게 아니라 runtime에 실행되지 않는다.
변수, 함수 같은것을 정의하는 역할을 해준다.
memory segment에 이름을 정해줄 수 있다. (메모리 구획에..)
즉 A는 100번지라는 주소를 의미한다.
변수를 만드는 행위는 CPU가 하는 일이 이나디.
| MEM (100번지) |
|---|
| 3 |
메모리 4바이트 만큼, int A = 3이라 하면 위의 4칸에 3이라는 A변수가 저장된다.
하지만 B= A + 10; 이것은 CPU에서 실행되므로 Runtime에서 실행된다.
A를 불러올 때,
A command embedded in the source code that is recognized and acted upon by the assembler
- Directives do not execute at runtime, but they let you define variables, macros, and procedures
- They can assign names to memory segments and perform many other housekeeping tasks related
to the assembler - Not case sensitive
- An example that shows the difference between directives and instructions

(첫 줄은 CPU가 하는 일이 아니라, 어셈블러가 하는 일이므로 런타임 실행 아니고 어셈블이 됬을 때 실행된다.
두번째 줄은 eax레지스터에 myVar를 가져오는 것인데, CPU가 하는 일이다.)
- All assemblers for Intel processors share the same instruction set, but they usually have different sets of directives

10. Instruction (명령어)
어셈블리어의 핵심.
프로그램이 어셈블이 되면은(컴파일 되서 기계어로 번역되었다.) CPU
(단 Directives는 어셈블이 되지 않는다.)
- A statement that becomes executable when a program is assembled
- Translated by the assembler into machine language bytes, which are loaded and executed by the CPU at runtime
- An instruction contains four basic parts
• Label (optional)
• Instruction mnemonic (required) 기억하기 쉬운 짧은 영어 단어...
• Operand(s) (usually required) 피연산자
• Comment (optional) 주석
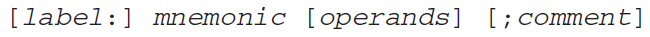
Label
명령어나 메모리의 데이터에 꼬리표(이름표)를 붙이는 것이다.
이 것은 명령어나 변수에 붙일 수 있다.
코드에 대한 레이블과 데이터에 대한 레이블이있다.
• An identifier that acts as a place marker for instructions and data
• There are two types of labels: Data labels and Code labels
– A label placed just before an instruction implies the instruction’s address
– A label placed just before a variable implies the variable’s address
• A data label identifies the location of a variable, providing a convenient way to reference the variable in code
- count DWORD 100
>> Defines a variable named count
- The assembler assigns a numeric address to each label
- You can define multiple data items following a label
>> array DWORD 1024, 2048
DWORD 4096, 8192
| MEM |
|---|
| 1024 |
| - |
| 2048 |
연속해서 나오면, 메모리 안에서 인접해서 위치하므로 1024의 주소를 토대로 2048의 주소를 알 수 있으므로 2048의 이름을 지정하지 않아도 된다.
• A label in the code area of a program must end with a colon (:) character
• Code labels (코드 레이블)are used as targets of jumping and looping instructions
•
target:
mov ax, bx
...
jmp targetjmp 타겟은, target으로 점프하게 한다.
JMP instruction transfers control to the location marked by the label named target, creating a loop
• A code label can share the same line with an instruction, or it can be on a line by itself
- L1: mov ax, bx
L2
Label names follow the same rules we described for identifiers
• You can use the same code label more than once in a program as long as each label is unique within its enclosing procedure
변수나 레이블은, 중복해서 생성이 불가능하다.
(하나의 프로시저 안에서 중복 생성 불가능. 다른 프로시저는 가능한데... 다음에 다룰 것이다)
Instruction Mnemonic
짧은 영어로 된 명령어...
• A short word that identifies an instruction
• Assembly language instruction mnemonics such as mov, add, and sub provide hints about the type of operation they perform
Operands (피연산자)
피연산자는 보통 하나나 두개를 쓰지만, 경우에 따라 세 개도 가능하다
피연산자는 방향이 있는데, 뒤에서 앞으로 이다. (destination source)


imul eax, ebx, 5 는 ebx에 5를 곱해서 eax에 저장
Comments
완전 선택사항.. 그냥 주석달기용임.

Single-line comments: 한 줄 주석
Block comments: 블럭 주석
The NOP (No Operation) Instruction
특이한 인스트럭션인 NOP에 대해 알아본다.
아무일도 하지 않는 연산자이다.
교재에서 말하길 가장 안전한 명령어이자 쓸모없는 명령어이다.
정확하게, 1바이트를 차지한다.

| MEM |
|---|
| .... |
| 0000 0000 0110 0110 |
| 0000 0000 1000 0000 |
| 0000 0000 1100 0011 |
| 0000 0000 1001 0000 nop |
| - |
| 0000 0004 1000 1011 |
| 0000 0004 0110 0001 |
| .... |
nop을 쓰는 이유는, 4바이트만큼 명령어를 끊어서 읽어 오는데, nop이 없으면
mov edx, ecx를 할 때 명령어가 갈린다. (밑에 000 0004부분이 nop으로 올라오면... 갈리는 것을 볼 수 있다.)
따라서 nop을 삽입해서 명령어가 안갈리게 만들어준다.
만약 명령어가 갈린다면 mov edx, ecx같은 경우엔 불필요하게 2번 읽어야지 수행 가능하게 된다.
그리하여, 효율적으로 동작이 가능하게 만든다.
Example: Adding and Subtractong Integers
1. The AddTwo Program






△ 플랫한 모델을 쓰고, Function call에대한 convention이 저장되 있다... 정도로 알아두자
또한, 4킬로바이트 만큼 스택을 위해 공간을 할당 했다.

△

△ 윈도우에서 해당 실습을 돌리는 방법

△ 폴도 경로는 사람마다 다르다.

Assembling, Linking, and Running Programs
어셈블리어는 컴파일하고 링킹을 해야지 실행이 가능하다.
즉, 컴파일러와 링커는 나눠서 수행되어 진다.
어셈블링 하면 오브젝트 파일들을 링커로 하나로 합쳐서 실행..?

시스템 프로그래밍에서, 프로그램을 작성하고 실행하는 과정에는 주로 세 단계가 있습니다: Assembling, Linking, Running Programs. 아래에 각 단계에 대해 설명하겠습니다.
1.Assembling (어셈블링)
어셈블리 언어로 작성된 소스 프로그램은 바로 실행할 수 없습니다. 이를 실행 가능한 코드로 변환해야 하는데, 이 과정을 어셈블링이라고 합니다. 어셈블러는 컴파일러와 매우 유사한 역할을 수행합니다. 어셈블리 언어의 명령을 기계어 코드로 번역하여 실행 가능한 형태로 만드는 것이 주된 목표입니다.
2.Linking (링킹)
어셈블러를 통해 생성된 파일은 오브젝트 파일이라고 하며, 이 파일은 기계어로 작성되어 있습니다. 그러나 이 오브젝트 파일은 아직 실행할 준비가 되지 않았습니다. 왜냐하면, 다른 라이브러리나 모듈과 연결되어야 하기 때문입니다. 이러한 작업을 수행하는 프로그램을 링커라고 합니다. 링커는 오브젝트 파일과 다른 필요한 라이브러리를 결합하여 실행 가능한 파일을 생성합니다.
3.Running Programs (프로그램 실행)
링커를 통해 생성된 실행 가능한 파일은 이제 운영 체제에서 실행할 수 있습니다. 운영 체제는 실행 파일을 메모리에 로드하고, 프로그램의 시작 지점으로부터 명령을 실행하기 시작합니다. 프로그램이 완료되면, 결과가 반환되고, 운영 체제는 프로그램을 종료하게 됩니다.
요약하자면, 시스템 프로그래밍에서 프로그램을 실행하는 과정은 어셈블링, 링킹, 실행 프로그램의 세 단계로 이루어집니다. 어셈블러와 링커를 사용하여 소스 코드를 실행 가능한 형태로 변환하고, 이를 실행하는 과정을 거칩니다.
1. The Assemble-Link-Execute Cycle
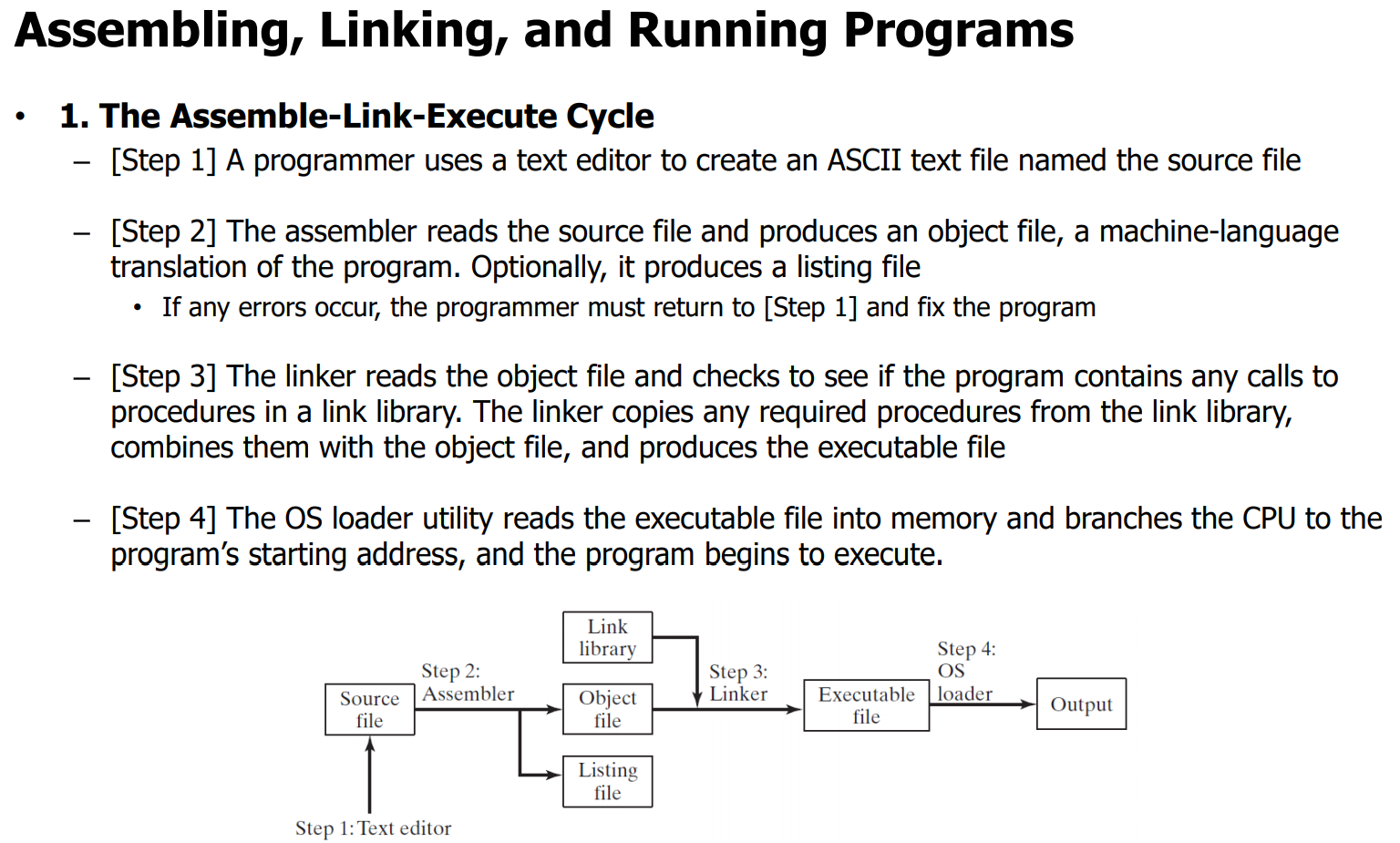
- 텍스트를 쳐서 코드를 짠다.
- 어셈블러가 코드를 읽어서 기계어로 번역... 이것이 어셈블링
- 어셈블러로 만든 오브젝트 파일을
- 링커가 실행 파일을 연결해줌
- 실행
(리스팅 파일은 옵셔널 한 것이다)
Assemble-Link-Execute Cycle은 프로그램을 작성하고 실행하는 과정을 단계별로 나타낸 것입니다. 이 과정은 다음과 같은 4단계로 이루어집니다:
-
소스 파일 작성
프로그래머는 텍스트 에디터를 사용하여 소스 파일이라고 하는 ASCII 텍스트 파일을 생성합니다. 이 파일에는 주로 어셈블리 언어로 작성된 코드가 포함되어 있습니다. -
어셈블
어셈블러는 소스 파일을 읽어 기계어로 번역된 오브젝트 파일을 생성합니다. 선택적으로, 리스팅 파일도 생성할 수 있습니다. 만약 에러가 발생하면, 프로그래머는 [단계 1]로 돌아가 프로그램을 수정해야 합니다. -
링킹
링커는 오브젝트 파일을 읽고 프로그램이 링크 라이브러리의 프로시저 호출을 포함하는지 확인합니다. 필요한 프로시저가 있다면, 링커는 링크 라이브러리에서 해당 프로시저를 복사하여 오브젝트 파일과 결합하고, 실행 가능한 파일을 생성합니다. -
프로그램 실행
운영 체제의 로더 유틸리티는 실행 가능한 파일을 메모리에 읽어들이고, CPU가 프로그램의 시작 주소로 분기합니다. 그러면 프로그램이 실행되기 시작합니다.
Assemble-Link-Execute Cycle은 프로그램을 작성하고 실행하는 기본적인 프로세스입니다. 프로그래머가 소스 파일을 작성한 후, 어셈블러와 링커를 통해 실행 가능한 파일을 만들어낸 다음, 운영 체제에서 프로그램이 실행되는 것이 이 사이클의 전체 과정입니다.
2. Listing File

△ 9~17번 줄에 보면 우리가 눈으로 볼 수 있는 번역한 언어가 있는데..
이것이 바로 리스팅 파일이다.
(공부하는 용으로 사용 가능하다... 그러니까 옵셔널 하다. 없어도 안돌아가는 건 아니니)
변수 명과, 그녀석의 테이블에 대한 것을 쭉 출력해준다.



Defining Data
1. Intrinsic Data Types
- Describe types in terms of their size (byte, word, doubleword, and so on), whether they are signed, and whether they are integers or reals
- There’s a fair amount of overlap in these types
- E.g.) the DWORD type is interchangeable with the SDWORD type
- The assembler only evaluates the sizes of operands
- E.g.) you can only assign variables of type DWORD, SDWORD, or REAL4 to a 32-bit integer
| Type | Usage |
|---|---|
| Byte | 8-bit unsigned integer. B stands for byte |
| SBYTE | 8-bit signed integer. S stands for signed |
| WORD | 16-bit unsigned integer |
| SWORD | 16-bit signed integer |
| DWORD | 32-bit integer. D stands for double |
| SDWORD | 32-bit signed integer. SD stands for signed double |
| FWORD | 48-bit integer (Far pointer in protected mode) |
| QWORD | 64-bit integer. Q stands for quad |
| TBYTE | 80-bit(10-byte) integer. T stands for Ten-byte |
| REAL4 | 32-bit (4-byte) IEEE short real |
| REAL8 | 64-bit (8-byte) IEEE long real |
| REAL10 | 80-bit (10-byte) IEEE extended real |
- 내장 데이터 유형
- 데이터 유형을 크기(바이트, 워드, 더블워드 등), 부호, 정수 또는 실수 여부에 따라 설명합니다.
- 이러한 유형 간에는 상당한 중복이 있습니다.
- 예를 들어, DWORD 유형은 SDWORD 유형과 교환 가능합니다.
- 어셈블러는 피연산자의 크기만 평가합니다.
- 예를 들어, 32비트 정수에는 DWORD, SDWORD, REAL4 유형의 변수만 할당할 수 있습니다.
| Type | Usage |
|---|---|
| Byte | 8비트 부호 없는 정수. B는 바이트를 의미 |
| SBYTE | 8비트 부호 있는 정수. S는 부호 있는(sign)을 의미 |
| WORD | 16비트 부호 없는 정수 |
| SWORD | 16비트 부호 있는 정수 |
| DWORD | 32비트 정수. D는 더블(double)을 의미 |
| SDWORD | 32비트 부호 있는 정수. SD는 부호 있는 더블(signed double)을 의미 |
| FWORD | 48비트 정수 (보호 모드에서의 far 포인터) |
| QWORD | 64비트 정수. Q는 쿼드(quad)를 의미 |
| TBYTE | 80비트(10바이트) 정수. T는 텐 바이트(Ten-byte)를 의미 |
| REAL4 | 32비트 (4바이트) IEEE 단정밀도 실수 |
| REAL8 | 64비트 (8바이트) IEEE 배정밀도 실수 |
| REAL10 | 80비트 (10바이트) IEEE 확장 실수 |
2. Data Definition Statement
- Sets aside storage in memory for a variable, with an optional name
- Creates variables based on intrinsic data types
- The syntax: [name] directive initializer [,initializer]...
- An example: count DWORD 12345
- Name
- The optional name assigned to a variable must conform to the rules for identifiers
- Directive
- The directive in a data definition statement can be BYTE, WORD, DWORD, SBYTE, SWORD, or any of the types
- In addition, it can be any of the legacy data definition directives
- Initializer
- At least one initializer is required in a data definition, even if it is zero
- Additional initializers, if any, are separated by commas
- For integer data types, initializer is an integer literal or integer expression matching the size of the variable’s type, such as BYTE or WORD
- If you prefer to leave the variable uninitialized, the ? symbol can be used as the initializer
- All initializers, regardless of their format, are converted to binary data by the assembler
| Directive | Usage |
|---|---|
| DB | 8-bit integer |
| DW | 16-bit integer |
| DD | 32-bit integer or real |
| DQ | 64-bit integer or real |
| DT | define 80-bit (10-byte) integer |
데이터 정의 문
- 변수에 대한 메모리 저장소를 선택적인 이름과 함께 확보합니다.
- 내장 데이터 유형을 기반으로 변수를 생성합니다.
- 구문: [name] directive initializer [,initializer]...
- 예시: count DWORD 12345
- 이름
- 변수에 할당된 선택적 이름은 식별자 규칙을 따라야 합니다.
- 지시문
- 데이터 정의 문의 지시문은 BYTE, WORD, DWORD, SBYTE, SWORD 또는 그 외 유형 중 하나일 수 있습니다.
- 또한 이전 버전의 데이터 정의 지시문도 사용할 수 있습니다.
- 초기화 값
- 데이터 정의에는 최소한 하나의 초기화 값이 필요하며, 0일 수도 있습니다.
- 추가 초기화 값(있는 경우)은 쉼표로 구분됩니다.
- 정수 표현식이 초기화 값으로 사용됩니다. 예를 들어 BYTE 또는 WORD와 같은 크기의 변수에 맞춰집니다.
- 변수를 초기화하지 않고 남겨두려면 ? 기호를 초기화 값으로 사용할 수 있습니다.
- 초기화 값의 형식과 관계없이 어셈블러에 의해 모든 초기화 값은 이진 데이터로 변환됩니다.
| Directive | Usage |
|---|---|
| DB | 8비트 정수 |
| DW | 16비트 정수 |
| DD | 32비트 정수 또는 실수 |
| DQ | 64비트 정수 또는 실수 |
| DT | 80비트 (10바이트) 정수 정의 |
데이터 정의 문은 변수를 생성할 때 사용되며, 내장 데이터 유형에 따라 메모리 공간을 할당합니다. 이름은 선택 사항이지만 변수를 식별하고 참조하는 데 도움이 됩니다. 지시문은 어떤 유형의 변수를 생성할지 결정하며, 초기화 값은 변수에 할당되는 초기 값입니다. 초기화 값은 변수의 유형에 맞는 정수 리터럴이나 정수 표현식이어야 하며, 여러 초기화 값이 있는 경우 쉼표로 구분됩니다. 또한, 변수를 초기화하지 않기를 원하면 ? 기호를 사용할 수 있습니다. 이러한 초기화 값은 어셈블러에 의해 이진 데이터로 변환되어 저장됩니다.
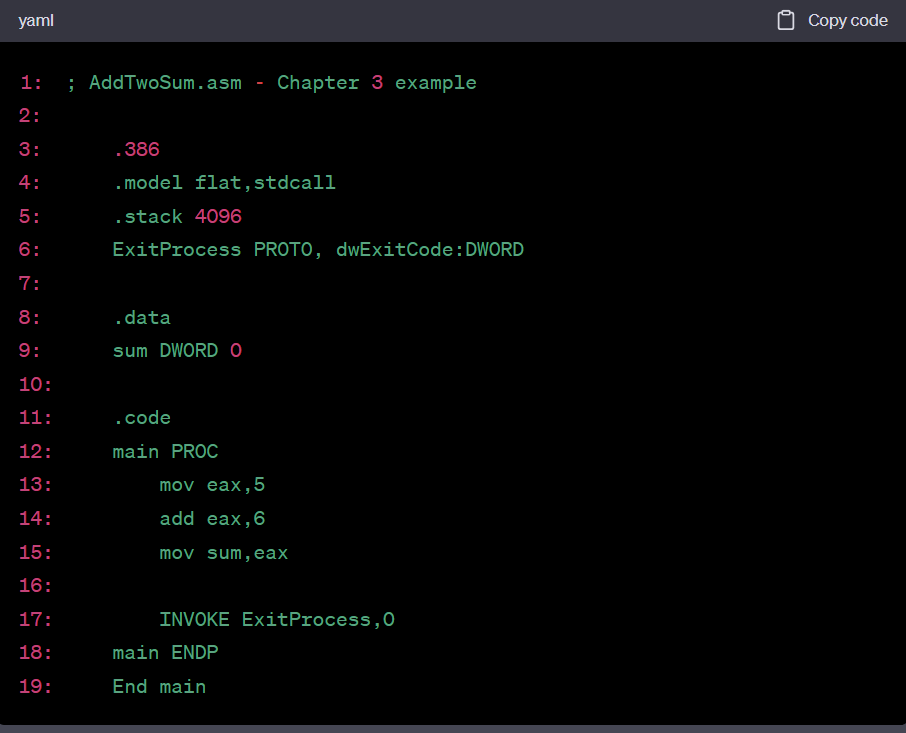
3. Adding a Variable to the AddTwo Program
- Run this in the debugger by setting a breakpoint on [line 13] and stepping through the program one line at a time
- Check the value of the sum variable after executing [line 15]
1: ; AddTwoSum.asm - Chapter 3 example
2:
3: .386
4: .model flat,stdcall
5: .stack 4096
6: ExitProcess PROTO, dwExitCode:DWORD
7:
8: .data
9: sum DWORD 0
10:
11: .code
12: main PROC
13: mov eax,5
14: add eax,6
15: mov sum,eax
16:
17: INVOKE ExitProcess,0
18: main ENDP
19: End main- AddTwo 프로그램에 변수 추가하기
이 프로그램은 두 수를 더하는 간단한 예제입니다. 디버거에서 실행하려면 라인 13에 브레이크 포인트를 설정하고 한 줄씩 실행해 보세요. 라인 15를 실행한 후 sum 변수의 값을 확인해 보세요.
4. Defining BYTE and SBYTE Data
-
Allocate storage for one or more unsigned or signed values
-
Each initializer must fit into 8 bits of storage
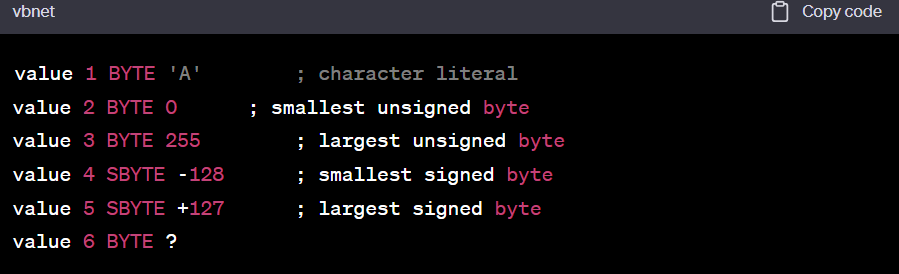
value 1 BYTE 'A' ; character literal value 2 BYTE 0 ; smallest unsigned byte value 3 BYTE 255 ; largest unsigned byte value 4 SBYTE -128 ; smallest signed byte value 5 SBYTE +127 ; largest signed byte value 6 BYTE ? -
The optional name is a label marking the variable’s offset from the beginning of its enclosing segment
- If value1 is located at offset 0000 in the data segment and consumes one byte of storage, value2 is automatically located at offset 0001
-
The DB directive can also define an 8-bit variable, signed or unsigned
val1 DB 255 ; unsigned byte
val2 DB -128 ; signed byte-
Multiple Initializers
- If multiple initializers are used, its label refers only to the offset of the first initializer
list BYTE 10,20,30,40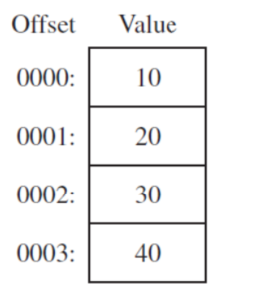
-
Not all data definitions require labels
- To continue the array of bytes begun with any label, we can define additional bytes on the next lines:
list BYTE 10,20,30,40 BYTE 50,60,70,80 BYTE 81,82,83,84 -
Within a single data definition, its initializers can use different radixes
list1 BYTE 10, 32, 41h, 00100010b
list2 BYTE 0Ah, 20h, 'A', 22h- Defining Strings
- To define a string of characters, enclose them in single or double quotation marks
- A null-terminated string
greeting1 BYTE "Good afternoon",0 greeting2 BYTE 'Good night',0- The most common type of string ends with a null byte (containing 0)
- Used in many programming languages
- A string can be divided between multiple lines without having to supply a label for each line
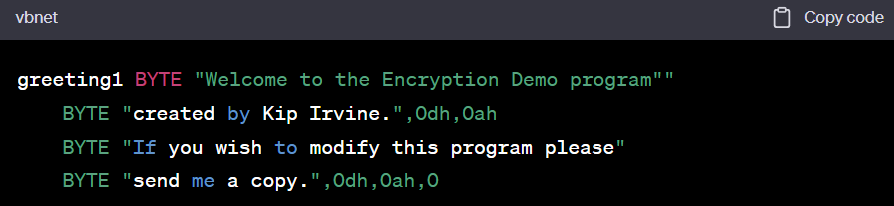
greeting1 BYTE "Welcome to the Encryption Demo program"" BYTE "created by Kip Irvine.",0dh,0ah BYTE "If you wish to modify this program please" BYTE "send me a copy.",0dh,0ah,0 - The hexadecimal codes 0Dh and 0Ah are alternately called CR/LF or end-of-line characters
- » When written to standard output, they move the cursor to the left column of the line following the current line
- The line continuation character (\ ) concatenates two source code lines into a single statement
- » It must be the last character on the line
greeting1 \ BYTE "Welcome to the Encryption Demo program"
- DUP Operator
- Allocates storage for multiple data items, using an integer expression as a counter
- Particularly useful when allocating space for a string or array
- can be used with initialized or uninitialized data
BYTE 20 DUP(0) ; 20 bytes, all equal to zero
BYTE 20 DUP(?) ; 20 bytes, uninitialized
BYTE 4 DUP("STACK") ; 20 bytes: "STACKSTACKSTACKSTACK"4.BYTE와 SBYTE 데이터 정의하기
이 부분에서는 부호 있는 값 또는 부호 없는 값에 대한 저장 공간을 할당하는 방법을 배웁니다. 각 초기화 값은 8비트 저장 공간에 들어갑니다
예시는 아래와 같다.
선택적인 이름은 변수의 오프셋을 나타내는 레이블입니다. 여러 개의 초기화 값이 사용되는 경우, 해당 레이블은 첫 번째 초기화 값의 오프셋만을 가리킵니다.
예시는 아래와 같다.

모든 데이터 정의가 레이블을 필요로 하는 것은 아닙니다. 레이블로 시작된 바이트 배열을 계속 정의하려면 다음 줄에 추가 바이트를 정의할 수 있습니다.
예시

단일 데이터 정의에서 초기화 값은 다양한 진수를 사용할 수 있습니다.

이를 통해 다양한 형식의 데이터를 정의하고 초기화할 수 있으며, 이를 사용하여 프로그램에서 다양한 연산을 수행할 수 있습니다.
문자열 정의하기
- 문자열을 정의하려면 작은따옴표나 큰따옴표로 묶어야 합니다. 널(null)로 종료되는 문자열은 다음과 같이 정의합니다.

- 널로 종료되는 문자열은 여러 프로그래밍 언어에서 자주 사용됩니다. 문자열은 여러 줄에 걸쳐 정의할 수 있으며, 각 줄마다 레이블을 지정할 필요가 없습니다.
- 여기서 16진수 코드 0Dh와 0Ah는 CR/LF 또는 줄 끝 문자로 불립니다. 표준 출력에 작성되면 커서를 현재 줄 다음 줄의 왼쪽 열로 이동시킵니다. 줄 연속 문자()는 두 개의 소스 코드 줄을 하나의 문으로 연결합니다. 이 문자는 줄의 마지막 문자여야 합니다.

DUP 연산자
- DUP 연산자는 정수 표현식을 카운터로 사용하여 여러 데이터 항목에 대한 저장 공간을 할당합니다. 문자열이나 배열의 공간을 할당할 때 특히 유용합니다. 초기화된 데이터 또는 초기화되지 않은 데이터에 사용할 수 있습니다.

5. Defining WORD and SWORD Data
- Create storage for one or more 16-bit integers
word1 WORD 65535 ; largest unsigned value
word2 SWORD -32768 ; smallest signed value
word3 WORD ? ; uninitialized, unsigned
val1 DW 65535 ; unsigned
val2 DW -32768 ; signed- Array of 16-Bit Words
array WROD 5 DUP (?) ; 5 values, uninitialized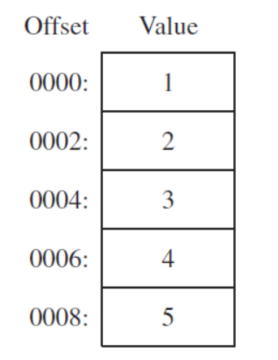
WORD와 SWORD 데이터 정의하기
16비트 정수를 위한 저장 공간을 생성합니다.
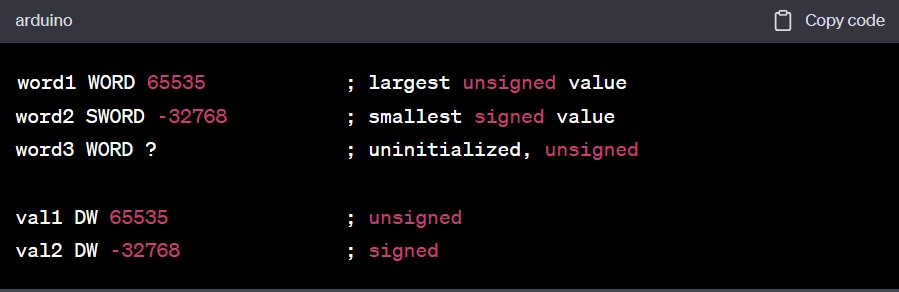
16비트 워드 배열을 만드는 예시:

6.Defining DWORD and SDWORD Data
-
Allocate storage for one or more 32-bit integers
val1 DWORD 12345678h ; unsigned val2 SDWORD -2147483648 ; signed val3 DWORD 20 DUP(?) ; unsigned array val1 DD 12345678h ; unsigned val2 DD -2147483648 ; signed -
The DWORD can be used to declare a variable that contains the 32-bit offset of another variable
- Below, pVal contains the offset of val3
pVal DWORD val3 -
Array of 32-Bt Doublewords
myList DWORD 1,2,3,4,5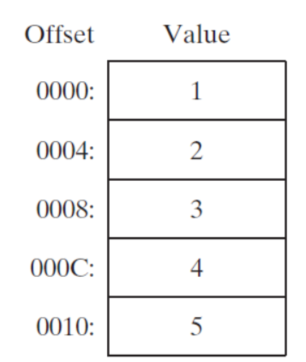
DWORD와 SDWORD 데이터 정의하기
하나 이상의 32비트 정수에 대한 저장 공간을 할당합니다.
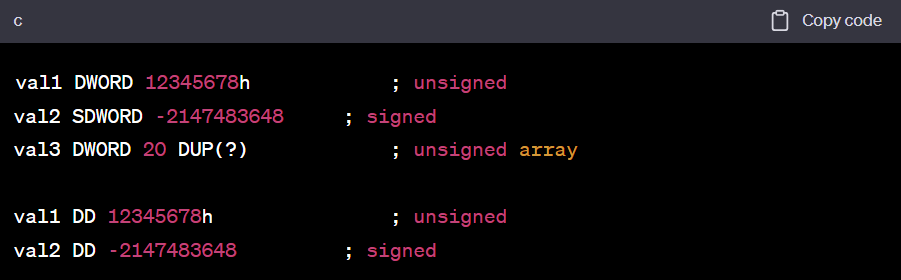
DWORD는 다른 변수의 32비트 오프셋을 포함하는 변수를 선언하는 데 사용할 수 있습니다. 아래 예제에서 pVal은 val3의 오프셋을 포함합니다.

32비트 더블워드 배열을 생성하는 예시:

이렇게 정의하면 프로그램에서 32비트 정수 값을 저장하고 사용할 수 있습니다. 이를 통해 더 큰 정수 값을 처리하거나 메모리 주소와 같은 32비트 오프셋을 저장하는 데 사용할 수 있습니다.
7. Defining QWORD Data
- Allocates storage for 64-bit (8-byte) values
quad1 QWORD 12345678h
quad DQ 12345678hQWORD 데이터 정의하기
64비트(8바이트) 값을 위한 저장 공간을 할당합니다.

이러한 정의를 통해 프로그램에서 다양한 크기와 형식의 데이터를 저장하고 사용할 수 있습니다.
8. Defining Floating-Point Types
- REAL4 defines a 4-byte single-precision floating-point variable
- REAL8 defines an 8-byte double-precision value
- REAL10 defines a 10-byte extended-precision value
- Each requires one or more real constant initializers
rVal1 REAL4 -1.2 rVal2 REAL8 3.2E-260 rVal3 REAL10 4.6E+4096 ShortArray REAL4 20 DUP(0.0)- The DD, DQ, and DT directives can define also real numbers
rVal1 DD -1.2 ; short real rVal2 DQ 3.2E-260 ; long real rVal3 DT 4.6E+4096 ; extended-precision real
부동 소수점 유형 정의하기
- REAL4는 4바이트 단정밀도 부동 소수점 변수를 정의합니다.
- REAL8은 8바이트 배정밀도 값을 정의합니다.
- REAL10은 10바이트 확장 정밀도 값을 정의합니다.
- 각각은 하나 이상의 실수 상수 초기화값이 필요합니다.
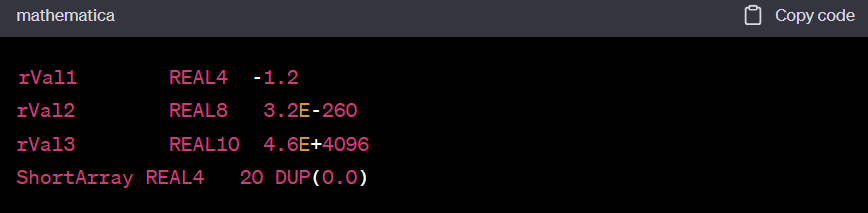
- DD, DQ, DT 지시문으로도 실수를 정의할 수 있습니다.

- DD, DQ, DT 지시문으로도 실수를 정의할 수 있습니다.
9. A Program That Adds Variables
1: ; AddVariables.asm - Chapter 3 example
2:
3: .386
4: .model flat,stdcall
5: .stack 4096
6: ExitProcess PROTO, dwExitCode:DWORD
7:
8: .data
9: firstval DWORD 20002000h
10: secondval DWORD 11111111h
11: thirdval DWORD 22222222h
12: sum DWORD 0
13:
14: .code
15: main PROC
16: mov eax,firstval
17: add eax,secondval
18: add eax,thirdval
19: mov sum,eax
20
21: INVOKE ExitProcess, 0
22: main ENDP
23: END main- [Lines 9–11] initialized three variables with nonzero values
- [Lines 16–18] add the variables
- The x86 instruction set does not let us add one variable directly to another, but it does allow a variable to be added to a register (That is why [lines 16–17] use EAX)
- [Line 19] the sum is copied into the variable named sum
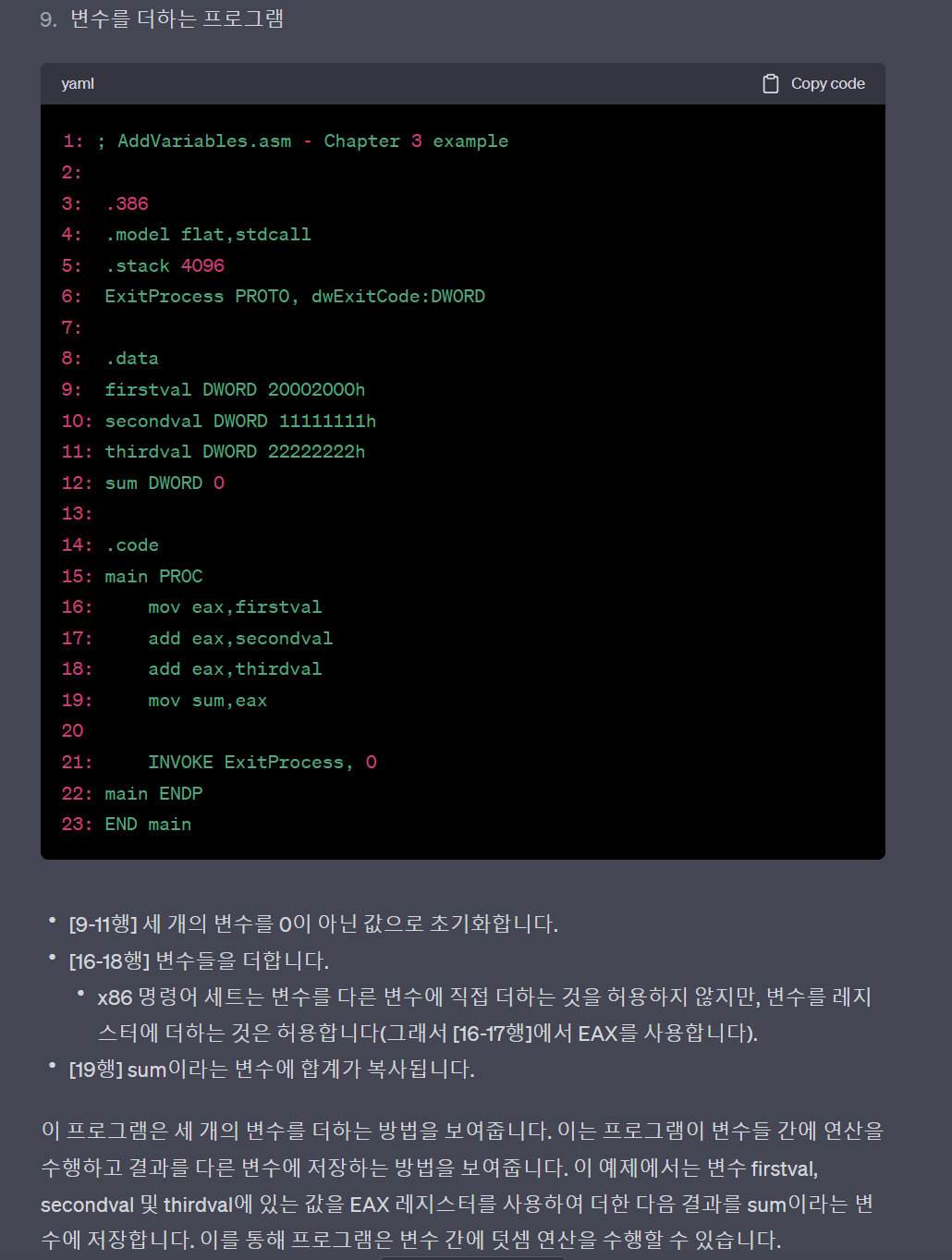
10. Little-Endian Order
- x86 processors store and retrieve data from memory using little-endian order (low to high)
- The LSB is stored at the first memory address allocated for the data
- The remaining bytes are stored in the next consecutive memory positions
- E.g) the doubleword 12345678h
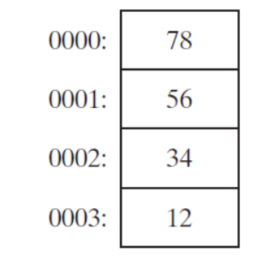
- Some other computer systems use big-endian order (high to low)
10.리틀 엔디안 순서
- x86 프로세서는 메모리에서 데이터를 저장하고 검색할 때 리틀 엔디안 순서(낮은 주소에서 높은 주소로)를 사용합니다.
- 최하위 바이트(LSB)는 데이터에 할당된 첫 번째 메모리 주소에 저장됩니다.
- 나머지 바이트는 연속되는 메모리 위치에 저장됩니다.
- 예) 더블워드 12345678h
- 일부 다른 컴퓨터 시스템은 빅 엔디안 순서(높은 주소에서 낮은 주소로)를 사용합니다
11. Declaring Uninitialized Data
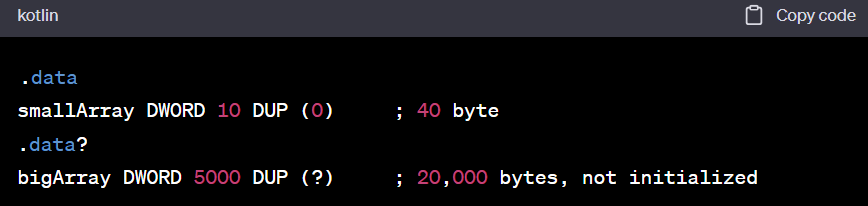
- The .DATA? directive declares uninitialized data
- When defining a large block of uninitialized data, the .DATA? directive reduces the size of a compiled program
.data smallArray DWORD 10 DUP (0) ; 40 byte .data? bigArray DWORD 5000 DUP (?) ; 20,000 bytes, not initialized- On the other hand, the following code produces a compiled program 20,000 bytes larger
,data smallArray DWORD 10 DUP (0) ; 40 byte bigArray DWORD 5000 DUP (?) ; 20,000 bytes - Mixing Code and Data
- The assembler lets you switch back and forth between code and data in your programs
11.초기화되지 않은 데이터 선언.code mov eax,ebx .data temp DWORD ? .code mov temp,eax
- The assembler lets you switch back and forth between code and data in your programs
- .DATA? 지시문은 초기화되지 않은 데이터를 선언합니다.
- 초기화되지 않은 대용량 블록을 정의할 때 .DATA? 지시문은 컴파일된 프로그램의 크기를 줄입니다.
- 반면, 다음 코드는 컴파일된 프로그램이 20,000 바이트 더 크게 됩니다

- 코드와 데이터 섞기
- 어셈블러는 프로그램에서 코드와 데이터를 왔다갔다 할 수 있게 해줍니다.

- 어셈블러는 프로그램에서 코드와 데이터를 왔다갔다 할 수 있게 해줍니다.
Symbolic Constants
- A symbolic constant is created by associating an identifier (a symbol) with an integer expression or some text
- Symbols do not reserve storage
- They are used only by the assembler when scanning a program
- They cannot change at runtime
| Symbol | Variable | |
|---|---|---|
| Uses storage? | No | Yes |
| Value changes at runtime? | No | Yes |
심볼릭 상수
- 심볼릭 상수는 식별자(심볼)를 정수 표현식 또는 일부 텍스트와 연결하여 생성됩니다.
- 심볼은 저장 공간을 예약하지 않습니다.
- 프로그램을 스캔하는 어셈블러에서만 사용됩니다.
- 런타임에 변경할 수 없습니다.
| 심볼 | 변수 | |
|---|---|---|
| 저장 공간 사용? | 아니오 | 예 |
| 런타임에 값이 변경되나요? | 아니오 | 예 |
1.Equal-Sign Directive
- Associates a symbol name with an integer expression
- Syntax: name = expression
- Ordinarily, expression is a 32-bit integer value
- When a program is assembled, all occurrences of name are replaced by expression during the assembler’s preprocessor step
- E.g.)
Count = 500 . . . mov eax, Count- When the file is assembled, MASM will scan the source file and produce the corresponding code lines: mov eax, 500
- Why Use Symbols?
- Programs are easier to read and maintain if symbols are used
- Current Location Counter ($)
- One of the most important symbols of all
- For example, the following declaration declares a variable named selfPtr and initializes it with the variable’s offset value:
selfPtr DWORD $ - Keyboard Definitions
- Programs often define symbols that identify commonly used numeric keyboard codes
Esc_key = 27 mov al,Esc_key ; good style mov al,27 ; poor style - Using the DUP Operator
- The counter used by DUP should be a symbolic constant, to simplify program maintenance
array dword COUNT DUP(0) - Redefinitions
- A symbol defined with = can be redefined within the same program
- The changing value of a symbol has nothing to do with the runtime execution order of statements
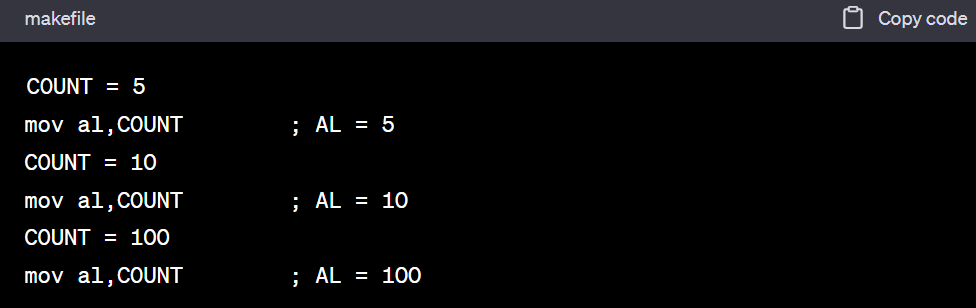
COUNT = 5 mov al,COUNT ; AL = 5 COUNT = 10 mov al,COUNT ; AL = 10 COUNT = 100 mov al,COUNT ; AL = 100
1.등호 지시문(Equal-Sign Directive)
- 심볼 이름을 정수 표현식과 연결합니다.
- 구문: name = expression
- 일반적으로 expression은 32비트 정수 값입니다.
- 프로그램이 어셈블될 때, 어셈블러의 전처리 단계에서 name의 모든 발생이 expression으로 대체됩니다.
- 예)

- 파일이 어셈블될 때, MASM은 소스 파일을 스캔하고 해당하는 코드 줄을 생성합니다: mov eax, 500
- 왜 심볼을 사용해야 하나요?
- 심볼이 사용되면 프로그램을 읽고 유지 관리하기가 더 쉽습니다.
- 현재 위치 카운터 ($)
- 가장 중요한 심볼 중 하나입니다.
- 예를 들어, 다음 선언은 selfPtr라는 변수를 선언하고 변수의 오프셋 값으로 초기화합니다.

- 키보드 정의
- 프로그램은 일반적으로 사용되는 숫자 키보드 코드를 식별하는 심볼을 정의합니다.

- 프로그램은 일반적으로 사용되는 숫자 키보드 코드를 식별하는 심볼을 정의합니다.
- DUP 연산자 사용
- DUP에 의해 사용된 카운터는 프로그램 유지 관리를 단순화하기 위해 심볼릭 상수여야 합니다.

- DUP에 의해 사용된 카운터는 프로그램 유지 관리를 단순화하기 위해 심볼릭 상수여야 합니다.
- 재정의
- 등호(=)로 정의된 심볼은 동일한 프로그램 내에서 재정의될 수 있습니다.
- 심볼의 값 변경은 문장의 런타임 실행 순서와 관련이 없습니다.
2.Calculating the Sizes of Arrays and Strings
- Symbolic constant for array size
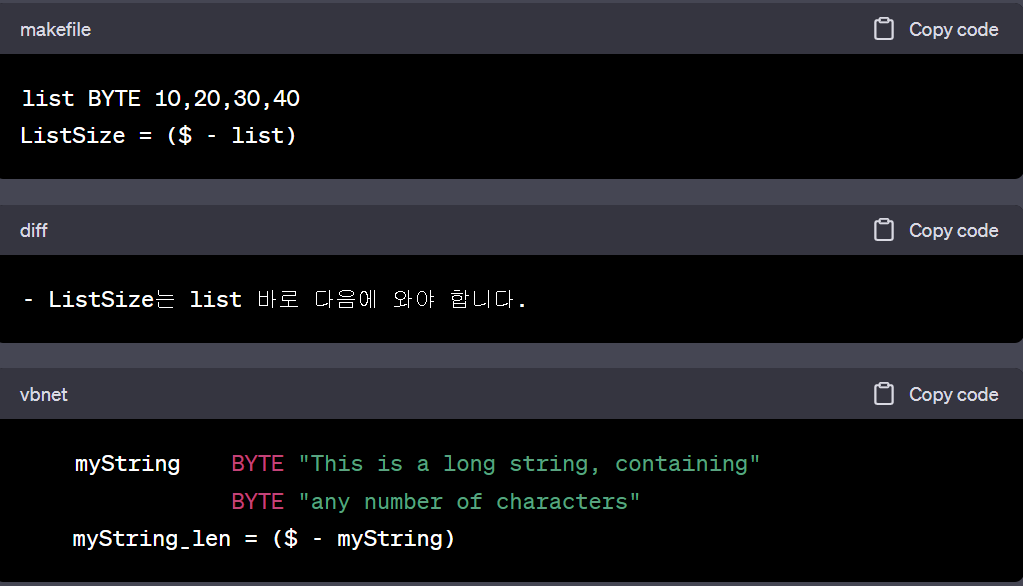
list BYTE 10,20,30,40 ListSize = 4- Explicitly stating an array’s size can lead to a programming error, particularly if you should later insert or remove array elements
- A better way: to let the assembler calculate its value for you
- The $ operator (current location counter) returns the offset associated with the current program statement
list BYTE 10,20,30,40 ListSize = ($ - list)- ListSize must follow immediately after list
myString BYTE "This is a long string, containing" BYTE "any number of characters" myString_len = ($ - myString)
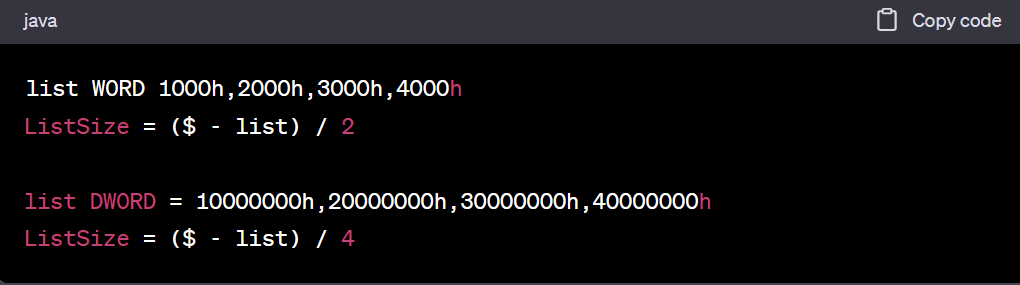
- Arrays of Words and DoubleWords
- When calculating the number of elements in an array containing values other than bytes, you should always divide the total array size (in bytes) by the size of the individual array elements
list WORD 1000h,2000h,3000h,4000h
ListSize = ($ - list) / 2
list DWORD = 10000000h,20000000h,30000000h,40000000h
ListSize = ($ - list) / 42.배열과 문자열의 크기 계산하기
- 배열 크기에 대한 심볼릭 상수

- 배열의 크기를 명시적으로 지정하면 프로그래밍 오류가 발생할 수 있습니다. 특히 나중에 배열 요소를 삽입하거나 제거할 경우에요.
- 더 나은 방법: 어셈블러가 값을 계산하도록 합니다.
- $ 연산자(현재 위치 카운터)는 현재 프로그램 문의 오프셋을 반환합니다.
- $ 연산자(현재 위치 카운터)는 현재 프로그램 문의 오프셋을 반환합니다.
- 워드와 더블워드의 배열
- 바이트 이외의 값을 포함하는 배열의 요소 수를 계산할 때 항상 전체 배열 크기(바이트 단위)를 개별 배열 요소의 크기로 나누어야 합니다.
- 바이트 이외의 값을 포함하는 배열의 요소 수를 계산할 때 항상 전체 배열 크기(바이트 단위)를 개별 배열 요소의 크기로 나누어야 합니다.
3.EQU Directive
- Associates a symbolic name with an integer expression or some arbitrary text
- There are three formats:
name EQU expression name EQU symbol name EQU <text>- In the first format, expression must be a valid integer expression
- In the second format, symbol is an existing symbol name, already defined with = or EQU
- In the third format, any text may appear within the brackets <. . .>
- When the assembler encounters name later in the program, it substitutes the integer value or text for the symbol
- EQU can be useful when defining a value that does not evaluate to an integer
PI EQU <3.1416>pressKey EQU <"Press any key to continue...",0>
.
.
.data
prompt BYTE pressKey- An example
matrix EQU 10 * 10 matrix EQU <10 * 10> .data M1 WORD matrix1 M2 WORD matrix2- The assembler produces different data definitions for M1 and M2
- The integer expression in matrix1 is evaluated and assigned to M1
- On the other hand, the text in matrix2 is copied directly into the data definition for M2
M1 WORD 100 M2 WORD 10 * 10
- No Redefinition
- Unlike the = directive, a symbol defined with EQU cannot be redefined in the same source code file
- This restriction prevents an existing symbol from being inadvertently assigned a new value
4. TEXTEQU Directive
- Creates what is known as a text macro
- There are three different formats:
name TEXTEQU <text> name TEXTEQU textmacro name TEXTEQU %constExpr- The first assigns text
- The second assigns the contents of an existing text macro
- The third assigns a constant integer expression
continueMsg TEXTEQU <"Do you wish to continue (Y/N)?"> .data prompt1 BYTE continueMsg - Text macros can build on each other
rowSize = 5 count TEXTEQU &(rowSize * 2) move TEXTEQU <mov> setupAL TEXTEQU <move al,count> ; setup → mov al,10 - A symbol defined by TEXTEQU can be redefined at any time
여기서 설명하는 두 가지 지시어, EQU와 TEXTEQU는 어셈블리어에서 심볼과 값을 연결하는 데 사용됩니다. 이들은 코드를 더 간결하고 읽기 쉽게 만드는 데 도움이 됩니다.
3.EQU Directive
EQU 지시어는 심볼 이름을 정수 표현식이나 임의의 텍스트와 연결합니다. 세 가지 형식이 있습니다:
name EQU expression: expression은 유효한 정수 표현식이어야 합니다.
name EQU symbol: symbol은 이미 = 또는 EQU로 정의된 기존 심볼 이름입니다.
name EQU : 괄호 안에는 임의의 텍스트가 나타날 수 있습니다.
EQU 지시어는 정수로 평가되지 않는 값을 정의할 때 유용할 수 있습니다.
4.TEXTEQU Directive
TEXTEQU 지시어는 텍스트 매크로를 생성합니다. 세 가지 형식이 있습니다:
name TEXTEQU : text를 할당합니다.
name TEXTEQU textmacro: 기존 텍스트 매크로의 내용을 할당합니다.
name TEXTEQU %constExpr: 상수 정수 표현식을 할당합니다.
TEXTEQU는 다른 텍스트 매크로에 기반하여 새로운 매크로를 만드는 데 사용될 수 있습니다. TEXTEQU로 정의된 심볼은 언제든지 다시 정의될 수 있습니다.
EQU와 TEXTEQU의 주요 차이점 중 하나는 EQU로 정의된 심볼은 동일한 소스 코드 파일에서 다시 정의할 수 없지만, TEXTEQU로 정의된 심볼은 언제든지 다시 정의할 수 있다는 점입니다. 이로 인해 TEXTEQU는 코드를 수정하고 조정할 때 더 유연한 옵션이 될 수 있습니다.
