링크드 리스트(Linked List)
- 연결 리스트라고도 한다.
- 배열은 순차적으로 연결된 공간에 데이터를 나열하는 데이터 구조이다.
- 링크드 리스트는 떨어진 곳에 존재하는 데이터를 화살표로 연결해서 관리하는 데이터 구조이다.
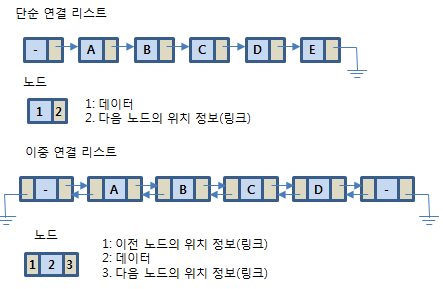
링크드 리스트(linked list)는 컴퓨터 과학에서 사용하는 기본적인 선형 자료 구조 중 하나다. 링크드 리스트는 각 요소가 데이터와 다음 요소를 참조(링크)하는 정보를 포함하는 노드로 구성된다. 이러한 특징 덕분에 링크드 리스트는 데이터의 동적 추가, 삭제를 상대적으로 쉽게 할 수 있는 장점이 있다.
링크드 리스트의 핵심 요소는 다음과 같다.
- 노드(Node): 링크드 리스트의 기본 단위로서, 데이터를 저장하는 데이터 필드 와 다음 노드를 가리키는 링크 필드 로 구성된다.
- 포인터:각 노드 안에서, 다음이나 이전의 노드와의 연결 정보를 가지고 있는 공간
- 헤드(Head): 링크드 리스트에서 가장 처음 위치하는 노드를 가리킨다. 리스트 전체를 참조하는데 사용된다.
- 테일(Tail): 링크드 리스트에서 가장 마지막 위치하는 노드를 가리킨다. 이 노드의 링크 필드는 Null을 가리킨다.
링크드 리스트는 다양한 형태로 확장될 수 있다. 예를 들어, 각 노드가 이전 노드와 다음 노드를 모두 참조하는 양방향 링크드 리스트(doubly linked list), 마지막 노드가 처음 노드를 참조하는 원형 링크드 리스트(circular linked list) 등이 있다.
링크드 리스트는 데이터의 동적 추가, 삭제에 효율적이지만, 특정 위치의 노드를 검색하기 위해서는 처음부터 차례대로 접근해야 하기 때문에, 검색에는 상대적으로 비효율적이다. 이는 배열과 비교했을 때의 단점으로 볼 수 있다.
링크드 리스트 구현(Python)
# 노드 클래스 정의
class Node:
def __init__(self, data):
self.data = data
self.next = None
# 링크드 리스트 클래스 정의
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
else:
current = self.head
while current.next:
current = current.next # current.next가 존재하지 않을 때 까지 next를 한다.
current.next = Node(data)
def print_list(self):
current = self.head
while current:
print(current.data)
current = current.next
# 링크드 리스트 객체 생성 및 데이터 추가
linked_list = LinkedList()
linked_list.append('A')
linked_list.append('B')
linked_list.append('C')
# 링크드 리스트 데이터 출력
linked_list.print_list() # 출력: A, B, C위의 코드에서 LinkedList 클래스는 head를 속성으로 가진다. 이 head는 리스트의 첫 번째 노드를 참조한다. append 메소드는 리스트의 끝에 새 노드를 추가하고, print_list 메소드는 리스트의 모든 노드를 출력한다.
- Node 클래스: 각 노드를 나타내는 클래스입니다. 각 노드는 data와 next라는 두 가지 속성을 가진다. data는 노드에 저장된 데이터를 나타내며, next는 다음 노드를 가리키는 링크다. 초기에는 next는 None으로 설정된다.
- LinkedList 클래스: 이 클래스는 링크드 리스트 자체를 표현한다. head 속성은 리스트의 첫 번째 노드를 가리킨다. 초기에는 head는 None으로 설정된다.
- LinkedList의 append 메소드: 이 메소드는 링크드 리스트의 끝에 새로운 노드를 추가한다. 만약 리스트가 비어 있다면(head가 None이라면), head를 새 노드로 설정한다. 그렇지 않다면, 리스트의 끝을 찾아서(current.next가 None이 될 때까지) 그곳에 새 노드를 추가한다.
- LinkedList의 print_list 메소드: 이 메소드는 리스트의 모든 노드의 데이터를 출력한다. head부터 시작해서 next를 이용해 리스트의 끝까지 이동하면서 각 노드의 data를 출력한다.
- 링크드 리스트 사용 예제: LinkedList 객체를 생성하고, append 메소드를 이용해 여러 데이터('A', 'B', 'C')를 리스트에 추가한다. 그리고 print_list 메소드를 이용해 리스트의 모든 데이터를 출력합니다. 출력 결과는 'A', 'B', 'C' 순서대로 나타낸다.
이렇게 파이썬에서 링크드 리스트는 일반적으로 각 노드를 표현하는 Node 클래스와, 링크드 리스트 자체를 표현하는 LinkedList 클래스를 이용해 구현한다. 이러한 방식은 링크드 리스트뿐만 아니라 다른 복잡한 자료 구조를 표현할 때도 자주 사용된다.
연결리스트 삽입, 삭제 구현(Python)
생각해야 할 case는 다음과 같다.
- 헤드 부분에 추가, 삭제
- 중간 부분에 추가, 삭제
- 꼬리 부분에 추가, 삭제
class Node:
def __init__(self, data):
self.data = data # 노드가 저장하는 데이터
self.next = None # 다음 노드를 가리키는 포인터
class LinkedList:
def __init__(self):
self.head = None # 링크드 리스트의 첫 번째 노드를 가리키는 포인터
def append(self, data): # 새로운 노드를 리스트의 끝에 추가
if not self.head: # 만약 리스트가 비어있으면
self.head = Node(data) # 새 노드를 head로 지정
else: # 리스트가 비어있지 않으면
current = self.head
while current.next: # 리스트의 끝을 찾아가는 루프
current = current.next
current.next = Node(data) # 리스트의 끝에 새 노드 추가
def print_list(self): # 리스트의 모든 노드를 출력
current = self.head
while current:
print(current.data)
current = current.next
def insert(self, data, position): # 새로운 노드를 리스트의 특정 위치에 삽입
new_node = Node(data) # 새 노드 생성
if position == 0: # 만약 맨 앞에 삽입하는 경우
new_node.next = self.head # 새 노드의 다음 노드를 현재의 head 노드로 지정
self.head = new_node # 새 노드를 head 노드로 지정
else:
current = self.head
for _ in range(position - 1): # 삽입할 위치의 앞 노드를 찾는 루프
if current:
current = current.next
else:
raise IndexError('Position out of range') # 삽입 위치가 리스트의 길이를 초과하면 예외 발생
if current is None:
raise IndexError('Position out of range') # 삽입 위치가 리스트의 길이를 초과하면 예외 발생
new_node.next = current.next # 새 노드의 다음 노드를 삽입 위치의 노드로 지정
current.next = new_node # 삽입 위치의 앞 노드의 다음 노드를 새 노드로 지정
def delete(self, data): # 주어진 값을 가진 노드를 리스트에서 삭제
if self.head and self.head.data == data: # 삭제할 노드가 head 노드인 경우
self.head = self.head.next # head 노드를 다음 노드로 지정
else:
current = self.head
while current and current.next and current.next.data != data: # 삭제할 노드를 찾는 루프
current = current.next
if current and current.next: # 삭제할 노드를 찾은 경우
current.next = current.next.next # 삭제할 노드 앞의 노드의 다음 노드를 삭제할 노드의 다음 노드로 지정
else:
raise ValueError('Value not found in the list') # 삭제할 노드를 찾지 못한 경우 예외 발생위 코드에서 insert 메소드는 새 노드를 주어진 위치에 삽입한다. 위치가 0이라면 새 노드를 리스트의 앞에 삽입하고, 그렇지 않으면 주어진 위치의 앞에 삽입한다. 주어진 위치가 리스트의 길이를 초과하면 IndexError를 발생시킨다.
delete 메소드는 주어진 값을 가진 노드를 삭제한다. 삭제할 노드가 리스트의 앞에 있다면 head를 다음 노드로 이동시키고, 그렇지 않으면 삭제할 노드의 앞 노드의 next를 삭제할 노드의 다음 노드로 변경한다. 주어진 값이 리스트에 없으면 ValueError를 발생시킨다.
이렇게 구현된 insert와 delete 메소드를 사용하면, 링크드 리스트에서 특정 위치에 노드를 삽입하거나 특정 값을 가진 노드를 삭제하는 것이 가능해진다.
아래는 위 코드를 사용하여 노드를 삽입하고 삭제하는 예제이다.
linked_list = LinkedList()
linked_list.append('A') # 노드 'A' 추가
linked_list.append('B') # 노드 'B' 추가
linked_list.append('C') # 노드 'C' 추가
linked_list.append('D') # 노드 'D' 추가
linked_list.print_list()
# Output: A B C D
linked_list.insert('E', 0) # 'E' 노드를 맨 앞에 삽입
linked_list.print_list()
# Output: E A B C D
linked_list.insert('F', 2) # 'F' 노드를 index 2 (세 번째 위치)에 삽입
linked_list.print_list()
# Output: E A F B C D
linked_list.delete('B') # 'B' 노드를 삭제
linked_list.print_list()
# Output: E A F C D
linked_list.delete('E') # 'E' 노드를 삭제
linked_list.print_list()
# Output: A F C DDouble linked list(더블 링크드 리스트)
물론입니다. 더블 링크드 리스트(Double Linked List)는 각 노드가 이전 노드와 다음 노드를 모두 가리키는 링크드 리스트다. 각 노드는 이전 노드를 가리키는 'prev' 포인터와 다음 노드를 가리키는 'next' 포인터를 가진다.
class Node:
def __init__(self, data, prev=None, next=None):
self.data = data
self.prev = prev
self.next = next
class DoubleLinkedList:
def __init__(self):
self.head = None
self.tail = None
def append(self, data):
if self.head is None:
self.head = Node(data)
self.tail = self.head
else:
node = Node(data, prev=self.tail)
self.tail.next = node
self.tail = node
def print_list(self):
current = self.head
while current:
print(current.data)
current = current.next이 코드에서 DoubleLinkedList 클래스는 더블 링크드 리스트를 표현하고, Node 클래스는 더블 링크드 리스트의 각 노드를 표현한다. DoubleLinkedList에는 노드를 추가하는 append 메서드와 리스트의 모든 노드를 출력하는 print_list 메서드가 있다. append 메서드를 사용하면 새 노드가 리스트의 마지막에 추가되고, 새 노드의 'prev' 포인터는 이전의 마지막 노드를 가리키게 된다.
이런 식으로 더블 링크드 리스트를 구현하면 각 노드에서 바로 이전 노드와 다음 노드로 이동할 수 있어, 노드의 삽입이나 삭제 등의 연산이 더 유연해진다.
Double linked list(더블 링크드 리스트) 삽입, 삭제
class Node:
def __init__(self, data, prev=None, next=None):
self.data = data
self.prev = prev
self.next = next
class DoubleLinkedList:
def __init__(self):
self.head = None
self.tail = None
def append(self, data):
if self.head is None:
self.head = Node(data)
self.tail = self.head
else:
node = Node(data, prev=self.tail)
self.tail.next = node
self.tail = node
def insert(self, data, index):
if self.head is None or index == 0:
# 리스트가 비어있거나 index가 0일 때
node = Node(data, next=self.head)
if self.head:
self.head.prev = node
self.head = node
if node.next is None:
self.tail = node
else:
temp = self.head
# index 위치로 이동
for _ in range(index - 1):
if temp.next is None:
break
temp = temp.next
if temp.next is None:
# index가 리스트의 크기를 초과하면 마지막에 추가
self.append(data)
else:
# 이전 노드와 다음 노드 사이에 새로운 노드 삽입
node = Node(data, prev=temp, next=temp.next)
temp.next.prev = node
temp.next = node
def delete(self, data):
temp = self.head
while temp:
if temp.data == data:
if temp.prev is not None:
temp.prev.next = temp.next
if temp.next is not None:
temp.next.prev = temp.prev
if temp == self.head:
self.head = temp.next
if temp == self.tail:
self.tail = temp.prev
temp = temp.next
def print_list(self):
current = self.head
while current:
print(current.data)
current = current.next위 코드에서 insert 메서드는 노드를 특정 위치에 삽입하는 기능을 가지고 있다. 만약 노드를 리스트의 첫 번째 위치에 삽입하거나 리스트가 비어 있을 경우, 삽입하려는 노드를 리스트의 헤드로 설정한다. 그리고 삽입하려는 위치가 리스트의 마지막을 넘어설 경우, 삽입하려는 노드를 리스트의 마지막에 추가한다. 그 외의 경우에는 삽입하려는 위치의 이전 노드와 다음 노드를 찾아, 삽입하려는 노드의 'prev' 포인터와 'next' 포인터를 각각 이전 노드와 다음 노드로 설정한다.
delete 메서드는 특정 데이터를 가진 노드를 찾아서 리스트에서 삭제하는 기능을 가지고 있다. 삭제하려는 노드를 찾으면, 삭제하려는 노드의 이전 노드와 다음 노드를 서로 연결하고, 삭제하려는 노드를 리스트에서 제거한다. 만약 삭제하려는 노드가 리스트의 헤드나 테일일 경우, 헤드나 테일을 적절히 업데이트한다.
연결 리스트의 장점
링크드 리스트(linked list)는 동적으로 데이터를 관리하는 데 있어서 여러 가지 장점을 가지고 있다.
- 동적 크기: 링크드 리스트는 미리 데이터의 크기를 지정할 필요가 없다. 배열과는 달리, 링크드 리스트는 런타임 중에도 데이터를 추가하거나 삭제하는 것이 가능하므로 유연성이 뛰어나다.
- 효율적인 메모리 사용: 링크드 리스트는 노드가 메모리의 어디에든지 위치할 수 있다. 따라서 메모리를 효율적으로 활용할 수 있다. 반면에 배열은 연속적인 메모리 공간을 필요로 하기 때문에, 크기를 변경하려면 메모리를 재배치해야 할 수도 있다.
- 데이터 삽입 및 삭제의 용이성: 링크드 리스트에서는 노드를 삽입하거나 삭제하는 과정이 간단하다. 특정 노드의 참조만 변경하면 되므로, 이러한 연산은 상수 시간에 이루어질 수 있다. 반면에 배열에서는 삽입 또는 삭제 후에 데이터를 재배치해야 하므로 더 많은 시간이 소요될 수 있다.
하지만 이러한 장점들은 일부 상황에서만 적용되며, 링크드 리스트가 모든 상황에서 배열보다 뛰어나다는 것은 아니다. 예를 들어, 링크드 리스트에서 특정 인덱스의 데이터에 접근하려면 리스트를 처음부터 순회해야 하므로, 이러한 접근은 배열에 비해 비효율적일 수 있다. 또한, 링크드 리스트의 각 노드는 데이터와 함께 다음 노드를 가리키는 링크 정보를 저장해야 하므로, 이로 인한 추가 메모리 사용이 필요하다.
연결 리스트의 단점
링크드 리스트는 동적 데이터 관리에 용이하며 유연한 메모리 사용이 가능하지만, 몇 가지 단점도 가지고 있다.
- 직접 접근 불가능: 배열과는 달리 링크드 리스트는 인덱스를 이용한 직접적인 데이터 접근이 불가능하다. 즉, 특정 인덱스의 요소에 접근하려면 링크드 리스트의 처음부터 해당 인덱스까지 순차적으로 이동해야 한다. 이로 인해 데이터 검색에 있어서 비효율적일 수 있다.
- 메모리 오버헤드: 링크드 리스트의 각 노드는 데이터 필드와 함께 링크(참조) 필드를 가지고 있어야 한다. 이 링크 필드는 추가적인 메모리를 사용하므로, 링크드 리스트는 배열에 비해 메모리 오버헤드가 크다고 볼 수 있다.
- 역방향 탐색의 어려움: 일반적인 단방향 링크드 리스트에서는 노드들이 다음 노드만을 참조하므로, 리스트를 역방향으로 탐색하는 것이 어렵다. 이 문제는 이중 링크드 리스트를 사용하면 해결할 수 있지만, 그러면 또 다른 메모리 오버헤드가 발생하게 된다.
- 복잡한 구현: 배열에 비해 링크드 리스트의 구현은 복잡하다. 특히, 노드의 삽입, 삭제 시에 링크를 정확히 관리해야 하므로 버그가 발생할 가능성이 더 높다.
따라서 링크드 리스트를 사용할지, 배열을 사용할지는 구체적인 상황과 필요성에 따라 결정해야 한다.
파이썬 (raise)
raise는 파이썬의 내장 키워드로, 예외를 강제로 발생시키는 데 사용된다. raise 뒤에는 발생시킬 예외의 종류와, 선택적으로 예외 메시지를 적을 수 있다. 예를 들어, raise ValueError('Invalid value')는 ValueError를 발생시키고 "Invalid value"라는 메시지를 함께 전달한다. 이렇게 예외를 강제로 발생시키는 기능은 예상치 못한 상황을 미리 처리하거나, 개발자가 직접 오류 상황을 제어할 필요가 있을 때 사용된다.
구현1 (Linkedlist)
"""
링크드 리스트 구현 해보기.
1. 서로 연결되어 있어야함.
2. 각 요소를 Node라 칭해야 한다.
3. Node에는 데이터와 다음 데이터인 next에 관한 정보를 담는다.
4. 시작(Head)과 끝(Tail)이 있어야함
5. append를 할 때, 마지막 Node인 tail을 어떻게 탐색할 것인가?
"""
class Node:
def __init__(self, data):
self.data = data # 데이터를 저장
self.next = None # 현재 데이터에 다음 데이터의 위치 정보를 저장한다. 포인터 역할.
class LinkedList:
def __init__(self):
self.head = None # 처음엔 아무 데이터도 없으므로 헤드가 None이다. 추후 데이터가 들어오면, 헤드값이 없을 때 헤드로 저장.
def append(self, data):
if not self.head:
self.head = Node(data)
else:
current = self.head # 처음 head부터 시작해서, tail까지 가기 위한 변수 current
while current.next: # 다음 노드가 계속 존재하는 동안, current를 다음 노드로 계속 옮겨가며 tail 탐색
current = current.next
current.next = Node(data)
def print_list(self):
current = self.head
while current:
print(current.data)
current = current.next
linkedlistA = LinkedList()
linkedlistA.append("스우")
linkedlistA.append("데미안")
linkedlistA.append("루시드")
linkedlistA.print_list()구현2 (Insert)
"""
insert구현해 보기
1. 헤드에 관한 insert
2. 헤드가 아닌 부분에선? tail인지 중간 위치인지 판별.
3. 만약 tail일 경우, 그냥 append형식으로 해줘도 된다.
4. 중간부분인 경우? 기존 연결에서 변형이 필요하다.
"""
class Node:
def __init__(self, data):
self.data = data # 데이터를 저장
self.next = None # 현재 데이터에 다음 데이터의 위치 정보를 저장한다. 포인터 역할.
class LinkedList:
def __init__(self):
self.head = None # 처음엔 아무 데이터도 없으므로 헤드가 None이다. 추후 데이터가 들어오면, 헤드값이 없을 때 헤드로 저장.
def append(self, data):
if not self.head:
self.head = Node(data)
else:
current = self.head # 처음 head부터 시작해서, tail까지 가기 위한 변수 current
while current.next: # 다음 노드가 계속 존재하는 동안, current를 다음 노드로 계속 옮겨가며 tail 탐색
current = current.next
current.next = Node(data)
def insert(self, data, position): # data는 insert할 데이터를 말하고, position은 위치를 가르킴.
if position == 0:
insert_data = Node(data)
insert_data.next = self.head
self.head = insert_data
elif position != 0:
current = self.head
while position > 1:
current = current.next
position = position - 1
if current.next is None:
current.next = Node(data)
elif current.next is not None:
temporary_value = current.next
current.next = Node(data)
current.next.next = temporary_value
def print_list(self):
current = self.head
while current:
print(current.data)
current = current.next
linkedlistA = LinkedList()
linkedlistA.append("스우")
linkedlistA.append("데미안")
linkedlistA.append("루시드")
linkedlistA.append("윌")
linkedlistA.insert("가엔슬", 4)
linkedlistA.print_list()리팩토링
- 주석 정리
- 주석은 코드를 이해하는 데 도움을 주지만, 지나치게 많거나 자명한 주석은 오히려 가독성을 떨어뜨릴 수 있다. 주석을 간결하게 유지하면서도 핵심 정보를 전달하는 것이 좋다.
- insert 메소드의 논리 개선:
- 현재 insert 메소드에서 position == 0과 position != 0으로 분리하는 것은 필요하지 않다. position이 0인 경우도 반복문에서 처리할 수 있다.
- 리스트의 끝에 요소를 추가하는 경우를 append 메소드를 사용하여 처리하면 코드 중복을 줄일 수 있습니다.
- 경계 조건 검사
- 리스트의 길이보다 큰 position이 주어질 경우 예외처리를 추가하는 것이 좋다.
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
return
current = self.head
while current.next:
current = current.next
current.next = Node(data)
def insert(self, data, position):
new_node = Node(data)
if position == 0:
new_node.next = self.head
self.head = new_node
return
current = self.head
for i in range(position - 1):
if current is None:
raise ValueError("Position out of bounds")
current = current.next
if not current:
raise ValueError("Position out of bounds")
new_node.next = current.next
current.next = new_node
def print_list(self):
current = self.head
while current:
print(current.data)
current = current.next
linkedlistA = LinkedList()
linkedlistA.append("스우")
linkedlistA.append("데미안")
linkedlistA.append("루시드")
linkedlistA.append("윌")
linkedlistA.insert("가엔슬", 4)
linkedlistA.print_list()구현2 (delete)
"""
delete
1. 헤드에 관한 delete
2. 헤드가 아닌 부분에선? tail인지 중간 위치인지 판별.
3. 만약 tail일 경우, 그냥 삭제해버려도 무방하다
4. 중간부분인 경우? 기존 연결에서 변형이 필요하다.
"""
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
return
current = self.head
while current.next:
current = current.next
current.next = Node(data)
def insert(self, data, position):
new_node = Node(data)
if position == 0:
new_node.next = self.head
self.head = new_node
return
current = self.head
for i in range(position - 1):
if current is None:
raise ValueError("Position out of bounds")
current = current.next
if not current:
raise ValueError("Position out of bounds")
new_node.next = current.next
current.next = new_node
def delete(self, position):
if position == 0:
self.head = self.head.next
return
current = self.head
for i in range(position - 1):
if current is None:
raise ValueError("Position out of bounds")
current = current.next
current.next = current.next.next
def print_list(self):
current = self.head
while current:
print(current.data)
current = current.next
linkedlistA = LinkedList()
linkedlistA.append("스우")
linkedlistA.append("데미안")
linkedlistA.append("루시드")
linkedlistA.append("윌")
linkedlistA.insert("가엔슬", 4)
linkedlistA.delete(4)
linkedlistA.print_list()리팩토링
- Tail 삭제 예외 처리
- 현재 코드에서는 tail 삭제를 특별히 다루지 않았지만, 일반적인 삭제 로직으로도 tail 삭제가 가능하다. 그러나 이렇게 삭제할 경우 tail의 next가 None인 상황에 대한 예외 처리가 필요하다.
- 삭제할 노드의 메모리 해제
- Python에서는 가비지 컬렉터가 있기 때문에 삭제할 노드의 메모리 해제를 직접 처리할 필요는 없다. 그러나 다른 언어에서는 삭제할 노드를 직접 메모리에서 해제해야 할 경우도 있다.
- 불필요한 예외 처리 제거
- insert 메소드와 비교하여 delete 메소드에서는 불필요한 예외 처리가 중복으로 들어 있다. delete 메소드에서는 해당 position이 리스트의 범위를 벗어나면 예외를 발생시키기만 하면 된다.
아래는 개선된 delete 메소드다
def delete(self, position):
if position == 0:
if self.head is None: # 리스트가 비어있을 때의 예외 처리
raise ValueError("List is empty")
self.head = self.head.next
return
current = self.head
for i in range(position - 1):
if current is None or current.next is None: # current나 current.next가 None인 경우 예외 처리
raise ValueError("Position out of bounds")
current = current.next
current.next = current.next.next구현3 (Double linked list)
"""
Double linked list
1. prev를 구현
2. insert, append, delete에서도 prev를 고려해 코드를 짜야함
"""
class Node:
def __init__(self, data):
self.data = data
self.next = None
self.prev = None
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
return
current = self.head
while current.next:
current = current.next
current.next = Node(data)
current.next.prev = current
def insert(self, data, position):
new_node = Node(data)
if position == 0:
new_node.next = self.head
self.head = new_node
return
current = self.head
for i in range(position - 1):
if current is None:
raise ValueError("Position out of bounds")
current = current.next
if not current:
raise ValueError("Position out of bounds")
if current.next is not None:
new_node.next = current.next
current.next.prev = new_node
new_node.prev = current
current.next = new_node
def delete(self, position):
if position == 0:
self.head = self.head.next
self.head.prev = None
return
current = self.head
for i in range(position - 1):
current = current.next
if current is None:
raise ValueError("Position out of bounds")
if current.next and current.next.next is not None:
current.next = current.next.next
current.next.prev = current
if current.next is None:
current.next = None
return
elif current.next.next is None:
current.next = None
return
def print_list(self):
current = self.head
while current:
print(current.data)
current = current.next
def print_prev(self, position):
if position == 0:
print("0번째 노드의 prev는 존재하지 않습니다.")
else:
current = self.head
for i in range(position):
current = current.next
if current is None:
raise ValueError("Position out of bounds")
print(current.prev.data) # current.prev를 하면, 위치만 표시된다.
return
linkedlistA = LinkedList()
linkedlistA.append("스우")
linkedlistA.append("데미안")
linkedlistA.append("루시드")
linkedlistA.append("윌")
linkedlistA.delete(3)
linkedlistA.print_list()리팩토링
- Head 노드 삭제시의 예외 처리: 만약 linked list가 비어 있을 경우 head를 삭제하려고 하면 에러가 발생한다. 이에 대한 예외 처리가 필요하다.
- delete 메소드의 간소화: delete 메소드 내에서 if current.next is None:와 elif current.next.next is None: 조건은 본질적으로 동일한 작업을 수행한다. 따라서 중복을 줄일 수 있다.
- print_prev 메소드의 구현: 현재 구현에서는 position으로 노드를 찾아 그 노드의 prev를 출력하는 기능을 합니다. 그러나 더 직관적인 방법은 특정 데이터를 찾아 해당 데이터의 prev를 출력하는 것이다.
class LinkedList:
# ... (다른 메소드들은 유지)
def delete(self, position):
if position == 0:
if not self.head:
raise ValueError("List is empty.")
self.head = self.head.next
if self.head:
self.head.prev = None
return
current = self.head
for i in range(position - 1):
current = current.next
if current is None:
raise ValueError("Position out of bounds")
if not current.next:
raise ValueError("No node to delete at given position")
elif current.next.next:
current.next = current.next.next
current.next.prev = current
else:
current.next = None
def print_prev_of(self, data):
current = self.head
while current:
if current.data == data:
if current.prev:
print(current.prev.data)
else:
print("This node is the head and has no previous node.")
return
current = current.next
print(f"Node with data '{data}' not found.")
# ... (이후 코드 생략)
linkedlistA.print_prev_of("데미안")

잘 읽고 갑니다!