Database에 대해서
Database란?
데이터베이스(영어: database, DB)는 여러 사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합이다. 작성된 목록으로써 여러 응용 시스템들의 통합된 정보들을 저장하여 운영할 수 있는 공용 데이터들의 묶음이다. 데이터베이스에 속해있는 모델은 다양하다.
데이터베이스 장점
- 데이터 중복 최소화
- 데이터 공유
- 일관성, 무결성, 보안성 유지
- 최신의 데이터 유지
- 데이터의 표준화 가능
- 데이터의 논리적, 물리적 독립성
- 용이한 데이터 접근
- 데이터 저장 공간 절약
데이터베이스 단점
- 데이터베이스 전문가 필요
- 많은 비용 부담
- 데이터 백업과 복구가 어려움
- 시스템의 복잡함
- 대용량 디스크로 액세스가 집중되면 과부하 발생
데이터베이스가 필요한 이유
현재까지 앱을 만들었을 때 어떠한 유저를 하나 더 생성하든지 POST 요청을 통해서 데이터를 추가했을 때, 그 당시에는 데이터가 추가되지만 서버를 다시 시작하면 생성한 데이터가 없어지게 된다. 그래서 데이터베이스를 이용해서 영구적으로 데이터를 보관해 줄 필요가 있다.
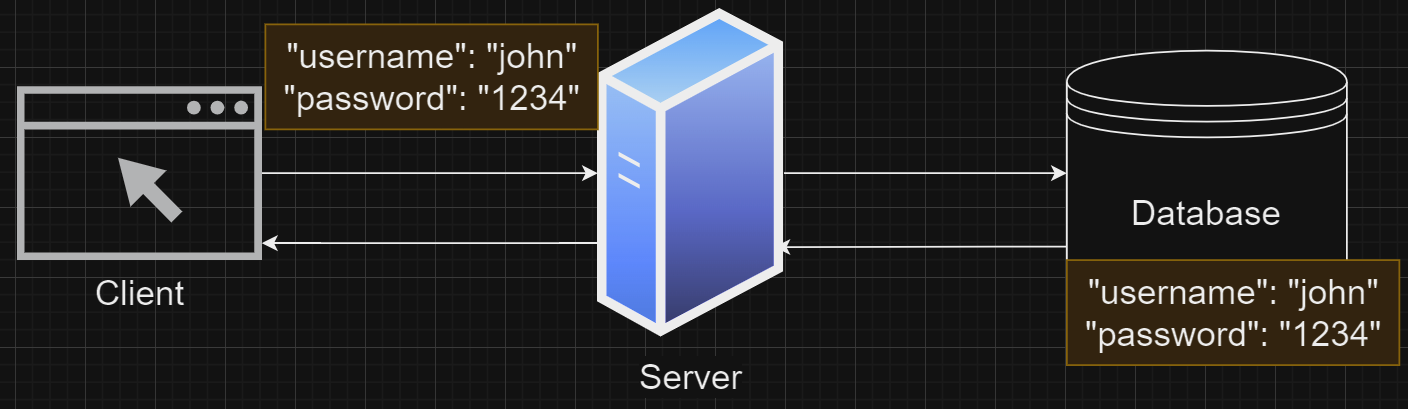
DBMS (Database Management System)
데이터베이스는 데이터의 집합이며, DBMS는 데이터베이스를 관리하고 운영하는 소프트웨어이다. 이 소프트웨어를 이용해서 데이터를 저장하고 검색하는 기능등을 제공한다.
DBMS 종류
DBMS는 계층형, 네트워크형, 관계형, 객체형등이 있다.
그 중에서 현재는 관계형(RDBMS, Relational DBMS)를 주로 사용하고 있다.
대표적인 RDBMS에는 Oracle, MySQL, PostgrSQL 등이 있다.

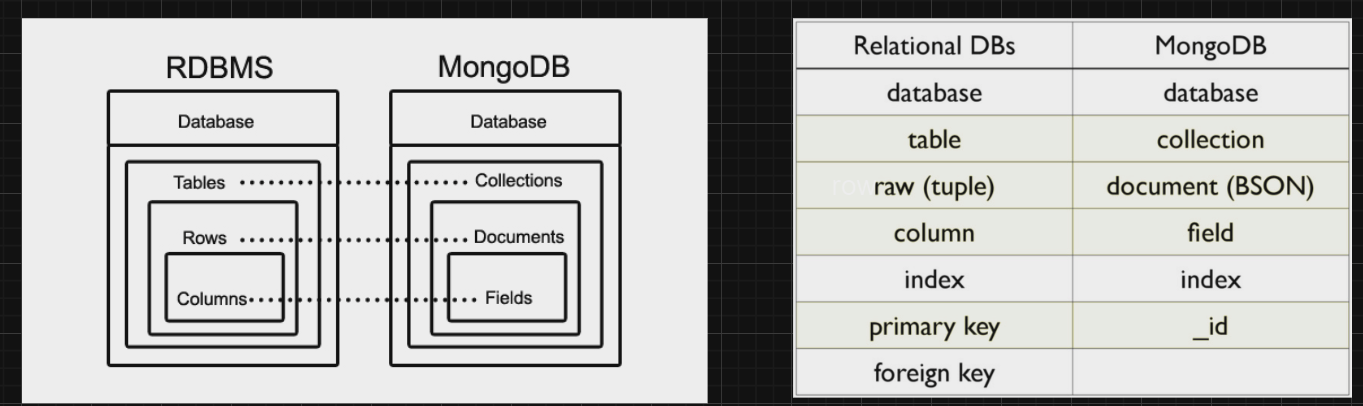
RDBMS 특징
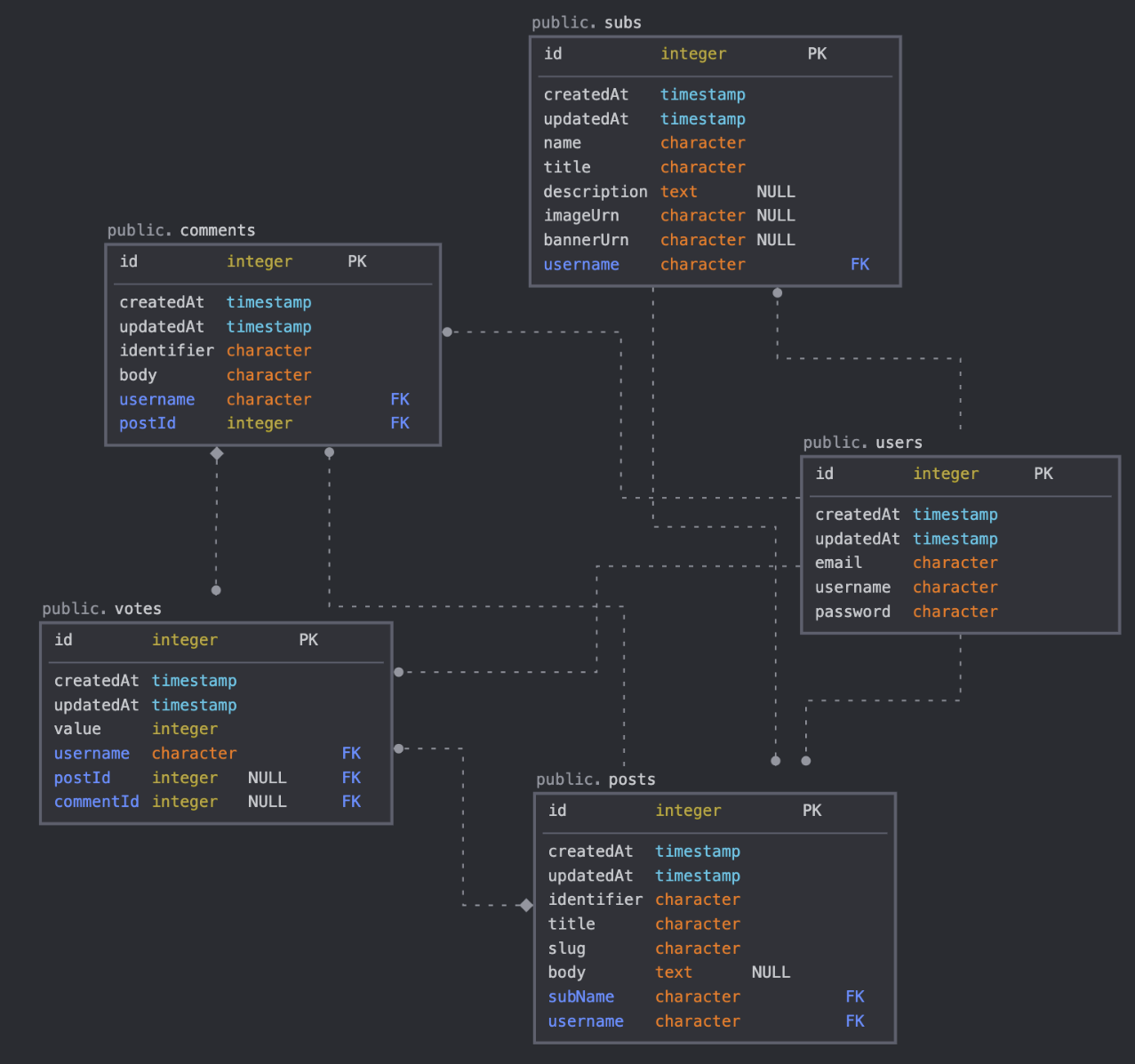
RDBMS 데이터베이스는 테이블을 사용하여 데이터를 저장한다. 테이블은 관련 데이터 항목의 모음이며 데이터를 저장할 행과 열을 포함한다. 각 테이블은 정보가 수집되는 사람, 장소 또는 이벤트와 같은 실제 개체를 나타낸다.

테이블이 여러개가 되면, 아래와 같이 "관계"가 나타나게 된다.
SQL vs NoSQL
SQL (Structured Query Language) 이란?
- SQL은 관계형 데이터베이스(RDBMS)에서 사용하는 언어이며, 데이터에 접근하며 데이터를 컨트롤하게 해준다. 시퀄(Sequel) 또는 에스큐엘로 발음 할 수 있다.
- SQL은 언어이지만 표준이기도 하며 대부분의 RDBMS에서 (Oracle, Mysql, SQL server 등등...) 이 SQL 표준을 준수하고 있다.
- SQL 데이터베이스는 SQL을 언어로 사용한다.
SQL 과 RDBMS의 관계
- RDBMS는 데이터베이스 관리 시스템이다.
- SQL은 RDBMS의 데이터와 통신하는 데 사용되는 언어이다.
- 예를 들어 말하자면, RDBMS는 책이고 SQL은 책에서 사용되는 언어이다.
- 책을 읽거나 쓸 때 SQL을 사용한다.
NoSQL Database 란?
-
단어 뜻 그 자체를 따지자면 "Not only SQL"로, SQL만을 사용하지 않는 데이터베이스 관리 시스템(DBMS)을 지칭하는 단어이다. 관계형 데이터베이스를 사용하지 않는다는 의미가 아닌, 여러 유형의 데이터베이스를 사용하는 것이다.
-
NoSQL이라고 하는 말은 대한민국이 아닌 모든 나라를 외국이라고 부르는 것과 비슷하다. 세상에는 한국 말고도 각자의 문화를 가진 수많은 나라가 존재한다. MongoDB에서 사용하는 쿼리 언어와 CouchDB에서 사용하는 쿼리 언어는 서로 전혀 다르다. 그럼에도 이 두 쿼리 언어는 같은 NoSQL 카테고리에 속한다. 어쨌거나 SQL이 아니기 때문이다. 또한 NoSQL이 No RDBMS를 의미하지는 않는다.
NoSQL에 내려진 구체적인 정의는 없으며, MongoDB나 CouchDB등이 NoSQL 이라고 불리는 이유는 둘이 사용하는 쿼리 언어는 다르지만 SQL이 아니기 때문에 NoSQL이라고 불린다.
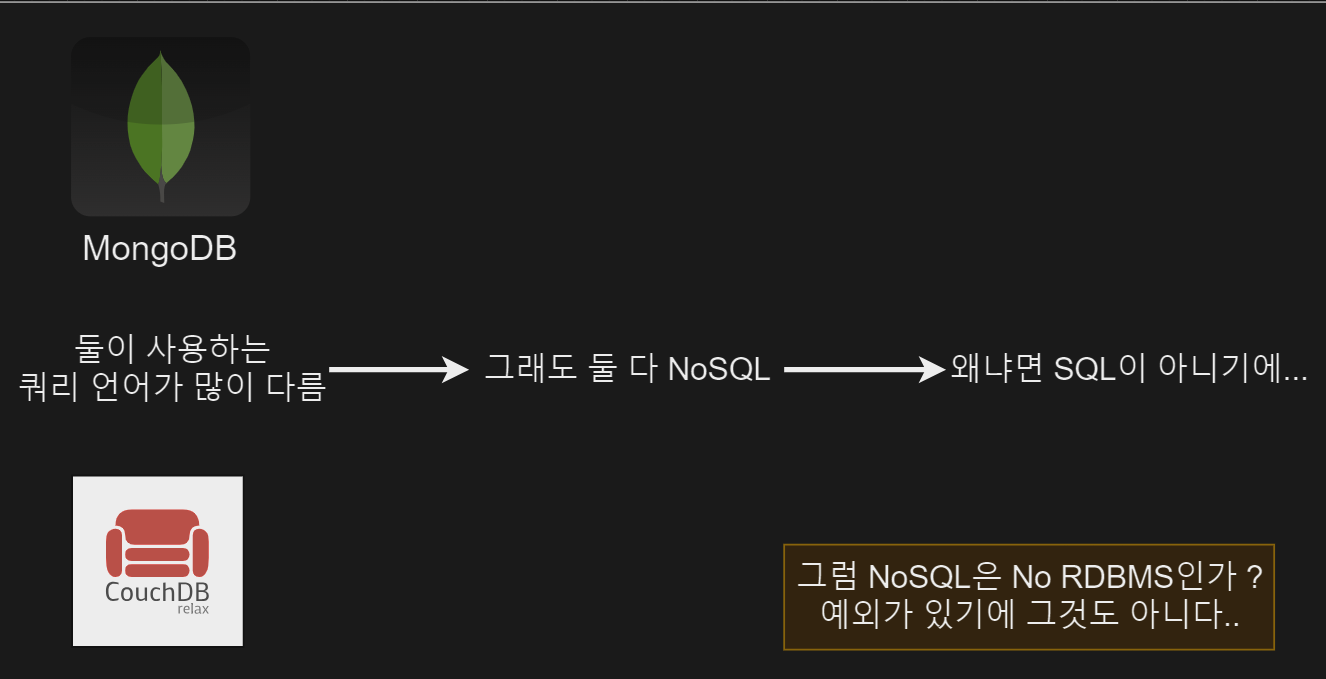
그래도 NoSQL은 전체적으로 비슷한 특징을 가지고 있다.
No SQL 등장 배경
- 빅데이터 등장으로 너무 많은 데이터를 처리해야 함 → 데이터 처리 비용 증가
- 다양한 형태의 데이터를 저장해야 하며, agile 기법이 유행하며 변화되는 요구에 빠르게 응답해야 함
이러한 문제점이나 변화를 해결하고 반영하기 위해서 2000년대에 No SQL이 등장
SQL 데이터베이스와 다른 NO SQL 데이터 베이스가 가진 특징

Database Type
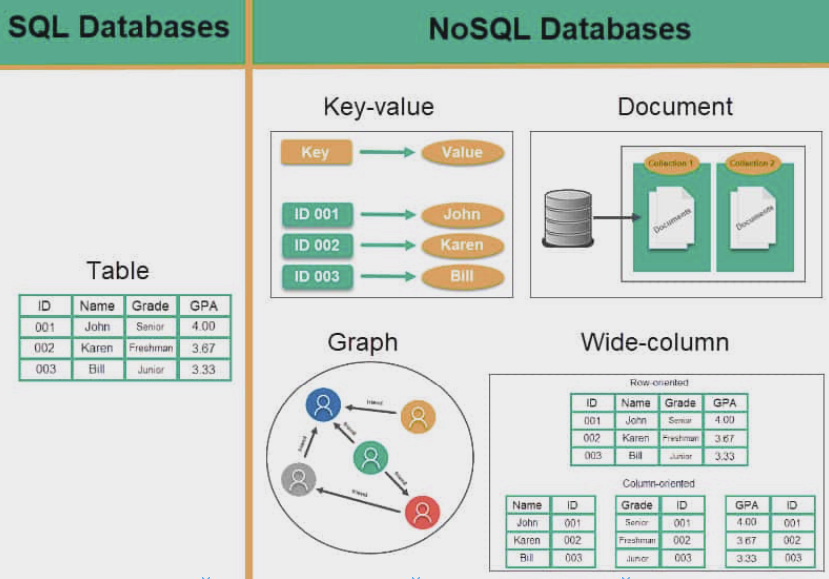
Schema
NoSQL 데이터베이스의 공통적인 특징은 스키마 없이 동작한다는 점이다. 따라서 데이터 구조를 미리 정의할 필요가 없으며, 시간이 지나더라도 언제든지 바꿀 수 있기 때문에 비형식적인 데이터를 저장하는 데 용이하다. 하지만 이는 데이터베이스가 스키마를 직접 관리하지 않는 것을 의미할 뿐, 데이터 타입에 따른 암묵적인 스키마는 여전히 존재한다. 이 때문에 단일 값에 대한 데이터 타입에서 불일치가 발생할 수 있다.
예를 들어 필드의 이름을 “Quantity”라고 하기로 했다고 하자. 이것은 앞으로 저장할 때 반드시 필드의 이름을 “Quantity”라고 저장하겠다는 암묵적인 스키마가 된다. 암묵적인 스키마를 무시할 경우 Quantity를 quantity, qty, QUANTITY 등으로 저장할지도 모른다. 뜬금없이 qty, quantity 같은 새로운 필드가 추가되는 것이나 마찬가지이다. 이는 NoSQL 데이터베이스가 암묵적인 스키마에 대해 전혀 알지 못하며, 이를 강제하지 않기 때문에 발생하는 일이다. 그렇게 때문에 NoSQL을 사용할 때에는 주의를 기울일 필요가 있다.
스키마를 SQL보다 훨씬 자유롭게 작성하고 수정할 수 있다.
Ability to Scale
"Ability to scale"은 시스템의 용량을 늘려 성능을 향상시키거나 더 많은 사용자나 데이터를 처리할 수 있는 능력을 의미한다. 이를 위한 주요 두 가지 방법은 "수직 스케일링"과 "수평 스케일링"이다.
-
수직 스케일링 (Vertical Scaling)
- 정의: 기존의 서버 하드웨어의 성능을 향상시키는 방법. 예를 들면, 더 강력한 CPU, 더 많은 RAM, 더 빠른 디스크 등을 추가하는 것이다.
- SQL DB와의 관계: 전통적인 RDBMS (관계형 데이터베이스 관리 시스템)는 주로 수직 스케일링에 의존한다. 데이터의 일관성을 유지하려면 종종 단일 서버에서 운영되어야 하기 때문이다.
-
수평 스케일링 (Horizontal Scaling)
- 정의: 추가적인 서버나 인스턴스를 시스템에 포함시켜 성능과 용량을 늘리는 방법이다.
- NoSQL DB와의 관계: NoSQL 데이터베이스는 수평 스케일링에 잘 맞는 설계가 되어 있다. 이러한 DB는 데이터를 여러 노드에 분산 저장하므로, 노드를 추가함으로써 성능과 용량을 쉽게 늘릴 수 있다.
SQL과 NoSQL 데이터베이스의 스케일링 관련 특성은 아래와 같다.
- SQL (RDBMS)
- 수직 스케일링에 더 초점을 맞추고 있다.
- 일관성, ACID 속성 (원자성, 일관성, 고립성, 지속성)에 더 중점을 둔다.
- 데이터베이스를 수평적으로 분산하려면 복잡한 설정과 아키텍처가 필요하다.
- NoSQL
- 다양한 데이터 모델과 유형이 있다 (예: Key-Value, Document, Columnar, Graph 등).
- 대부분의 NoSQL 데이터베이스는 처음부터 수평 스케일링을 염두에 두고 설계되었다.
- BASE 속성 (기본적으로 사용 가능, 부드러운 상태, 최종적으로 일관성)에 더 중점을 둔다.
- SQL => Vertical Scale
- ==> 사용하던 것을 장비를 더 좋은 장비로 바꿔야한다. (비용이 많이 든다.)
- NoSQL => Horizontal Scale
- ==> 사용하던 것에 새로운 노드 또는 시스템을 더해준다. (분산 저장을 지원함)
데이터베이스를 선택할 때, 프로젝트의 요구 사항, 데이터의 복잡성, 예상되는 트래픽 및 성장 등 여러 요인을 고려해야 한다. NoSQL이 항상 SQL보다 좋은 선택인 것은 아니며, 반대의 경우도 마찬가지이다. 각 데이터베이스 유형의 장점과 단점을 고려하여 올바른 선택을 해야 한다.
ACID vs BASE

ACID와 BASE는 데이터베이스 트랜잭션의 특성과 일관성을 설명하기 위한 용어로 사용된다. 이 두 용어는 데이터베이스의 일관성과 가용성에 대한 서로 다른 접근 방식을 나타낸다.
-
ACID (원자성, 일관성, 고립성, 지속성)
ACID는 전통적인 관계형 데이터베이스 시스템 (RDBMS)의 트랜잭션 특성을 설명하기 위해 사용된다.- 원자성 (Atomicity): 트랜잭션의 연산은 모두 성공하거나, 아니면 모두 실패해야 한다. 중간 상태는 허용되지 않는다.
- 일관성 (Consistency): 트랜잭션이 성공적으로 완료된 후 데이터베이스는 항상 일관된 상태를 유지해야 한다. 이는 데이터베이스의 모든 무결성 제약 조건이 항상 만족되어야 함을 의미한다.
- 고립성 (Isolation): 동시에 실행되는 여러 트랜잭션이 있을 때, 각 트랜잭션은 다른 트랜잭션의 중간 결과를 볼 수 없어야 한다. 다시 말해, 트랜잭션들은 서로 독립적으로 실행되어야 한다. (트랜잭션이 서로 간섭할 수 없다.)
- 지속성 (Durability): 트랜잭션이 성공적으로 완료된 후에는 결과가 영구적으로 저장되어야 한다. 시스템 장애가 발생하더라도 데이터는 손실되지 않아야 한다. (트랜잭션 적용 결과는 실패가 있더라도 저장된다.)
-
BASE (기본적으로 사용 가능, 부드러운 상태, 최종적으로 일관성)
BASE는 분산 데이터베이스 시스템, 특히 NoSQL 데이터베이스에서의 일관성과 가용성을 설명하기 위해 사용된다.- 기본적으로 사용 가능 (Basically Available): 시스템은 항상 사용 가능한 상태를 유지하려고 한다. 일부 정보가 누락되거나 지연될 수 있지만, 시스템은 계속 작동한다. 즉, 모든 사용자가 쿼리를 수행할 수 있다. 데이터베이스는 여러 시스템에 데이터를 분산하므로 데이터 세그먼트에 오류가 발생하는 경우 데이터베이스가 완전히 중단되지 않는다.
- 부드러운 상태 (Soft State): 시스템의 상태는 시간이 지나면서 변할 수 있으며, 이는 시스템이 항상 일관되지 않을 수 있다는 것을 의미한다.
- 최종적으로 일관성 (Eventually Consistent): 시스템은 특정 시점 후에 일관성을 달성하려고 한다. 즉, 데이터가 모든 노드에 분산 저장되면 시스템은 일관된 상태가 된다. (시스템이 작동하고 충분히 오래 기다리면 데이터베이스가 결국 일관성을 갖게 된다.)
요약하면, ACID는 강력한 일관성을 중시하는 반면, BASE는 시스템의 가용성과 확장성을 중시하며, 시간이 지나면서 일관성을 달성하는 것을 목표로 한다.
가용성(可用性, Availability)이란 서버와 네트워크, 프로그램 등의 정보 시스템이 정상적으로 사용 가능한 정도를 말한다. 가동률과 비슷한 의미이다.
트랜잭션
트랜잭션은 데이터베이스 용어로, 하나 이상의 연산을 포함하는 단일 논리적 작업 단위를 의미한다. 트랜잭션은 데이터의 일관성과 무결성을 유지하기 위해 설계되었으며, 주로 데이터베이스에서 데이터를 추가, 수정, 삭제 또는 조회할 때 사용된다.
- 원자성 (Atomicity): 트랜잭션에 포함된 모든 연산은 전체가 성공하거나 전체가 실패해야 한다. 예를 들어, 두 개의 데이터베이스 테이블에서 동시에 업데이트 작업을 수행할 때, 한 테이블의 업데이트가 실패하면 다른 테이블의 업데이트도 취소된다.
- 일관성 (Consistency): 트랜잭션이 성공적으로 완료된 후, 데이터베이스는 항상 일관된 상태를 유지해야 한다.
- 고립성 (Isolation): 동시에 여러 트랜잭션이 실행될 때, 각 트랜잭션은 다른 트랜잭션의 중간 결과에 영향을 받지 않아야 한다.
- 지속성 (Durability): 트랜잭션이 성공적으로 완료된 후, 그 결과는 영구적으로 데이터베이스에 저장되어야 한다.
예제로, 은행에서 두 계좌 간의 자금 이체를 생각해보면 좋다. 한 계좌에서 돈을 빼고 다른 계좌에 입금하는 두 개의 연산이 포함된 하나의 트랜잭션이다. 만약 두 번째 연산, 즉 입금 연산이 실패한다면 첫 번째 연산, 즉 출금 연산도 취소되어야 한다. 이렇게 전체 작업이 원자적으로 처리되기 때문에 데이터의 일관성이 유지된다.
이러한 트랜잭션 처리는 데이터의 안정성을 보장하며, 여러 사용자나 응용 프로그램이 동시에 데이터베이스에 액세스할 때 데이터의 무결성을 보호한다.
MongoDB 사용하기
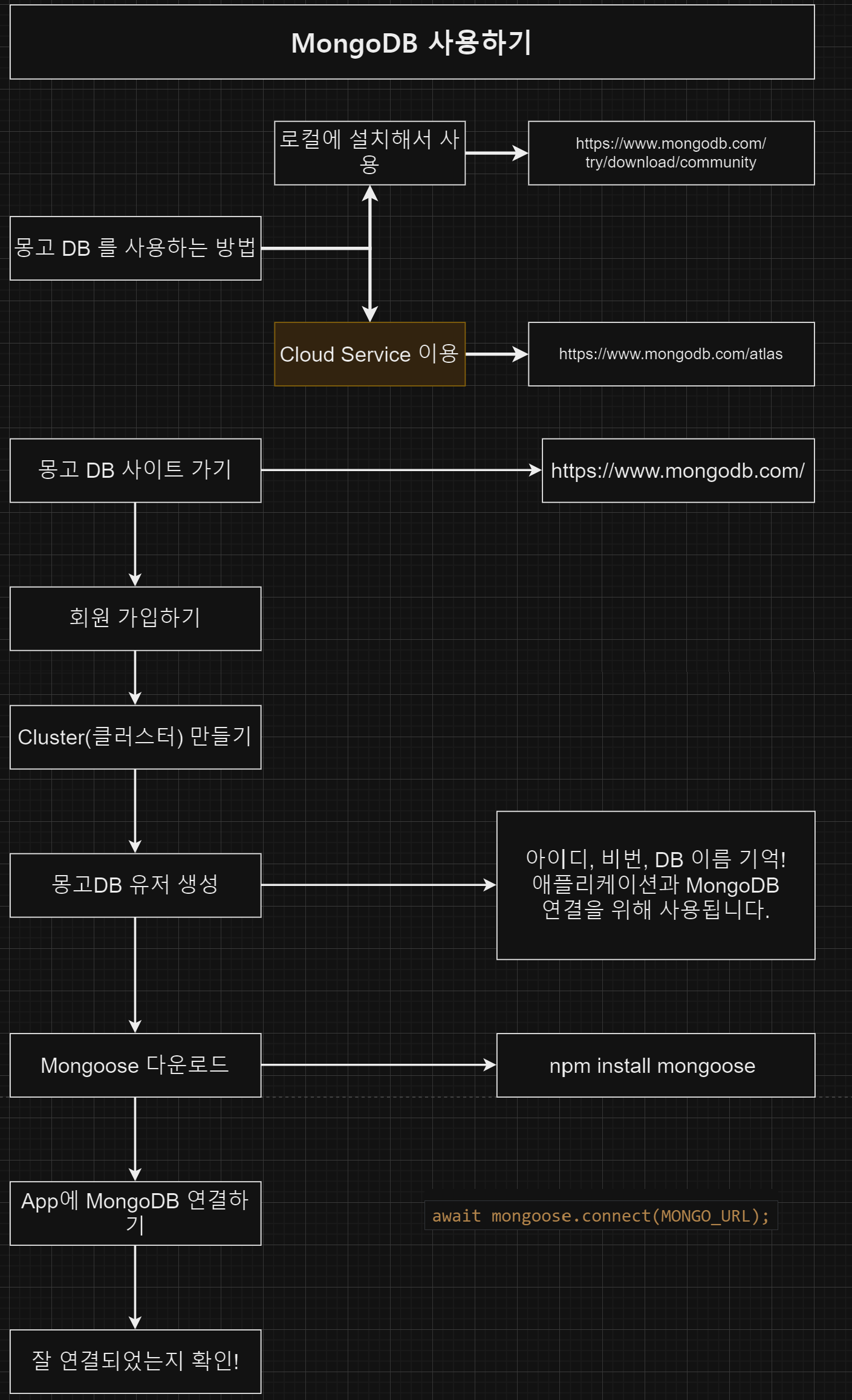
mongoose.connect('mongodb+srv://<name>:<password>@cluster0.e7emq.mongodb.net/<dbname>?retryWrites=true&w=majority')
.then(() => console.log('MongoDb Connected...'))
.catch(err => console.log(err));Mongoose에 대해서
몽구스(mongoose)는 무엇인가요 ?
- 몽고 DB 사용을 위한 다양한 기능을 추가하고 몽고 DB를 더 편리하게 이용하기 위해서 사용하는 모듈이다.
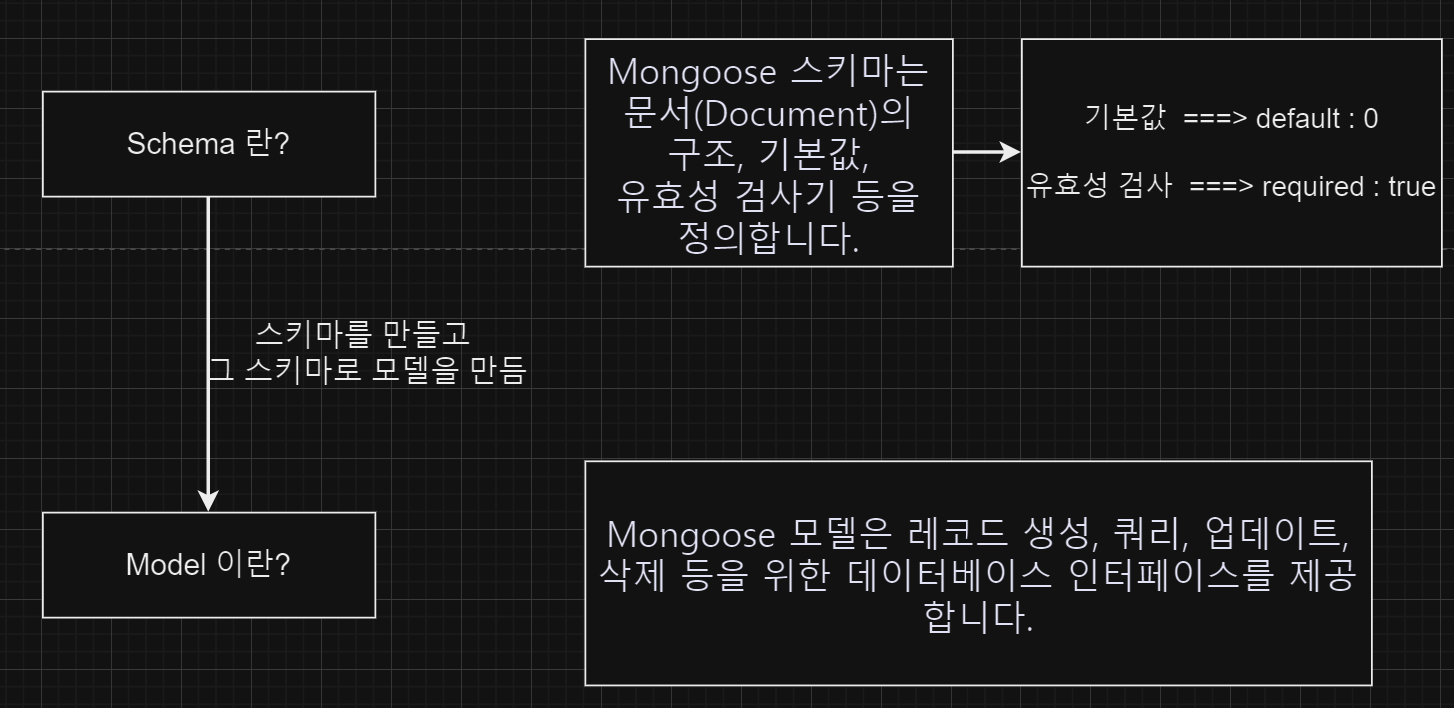
- 몽구스를 이용해서 데이터를 만들고 관리하기 위해서 먼저 Schema를 만들고 그 스키마로 모델을 만든다.
- 몽구스는 몽고 DB를 쓸 때 사용해도 되고 안 써도 되는 선택사항이다.

몽구스 ODM이 하는 역할
- 애플리케이션 계층에서 특정 스키마를 적용
- 모델 유효성 검사
- MongoDB 작업을 쉽게 하기 위한 기타 기능
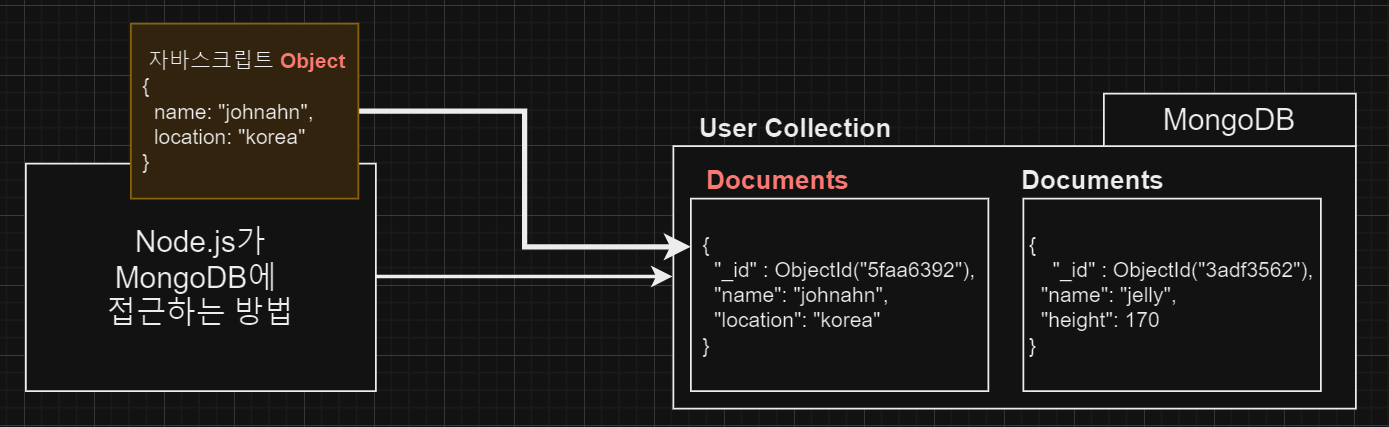

BSON은 "Binary JSON"의 약자로, JSON 데이터를 이진 형식으로 표현하는 방법이다. BSON은 주로 MongoDB와 같은 NoSQL 데이터베이스에서 사용되며, JSON보다 더 효율적인 저장, 검색 및 직렬화, 역직렬화 작업을 가능하게 한다.
BSON의 주요 특징은 다음과 같다.
- 이진 형식: BSON은 이진 데이터 형식으로, 데이터를 빠르게 읽고 쓸 수 있다.
- 타입 지원: BSON은 JSON보다 더 많은 데이터 타입을 지원한다. 예를 들면, int, long, date, float 및 decimal128와 같은 타입이 포함된다.
- 길이 정보 포함: 각 BSON 문서는 그 자체로 문서의 길이 정보를 포함하므로, 스캐너가 필요 없이 문서를 빠르게 순회할 수 있다.
- 효율적인 인코딩/디코딩: BSON 형식은 효율적인 직렬화 및 역직렬화를 위해 설계되었다, 따라서 큰 데이터 집합에서 높은 성능을 제공한다.
- 정렬 가능: BSON 필드는 순서를 유지하므로, 데이터를 쉽게 정렬할 수 있다.
그러나, BSON은 JSON보다 일반적으로 약간 더 큰 용량을 차지한다는 단점도 있다. 이러한 이유로, BSON은 데이터의 크기나 전송 효율성이 중요한 주요 관심사가 아닌 경우에 JSON을 대체하는 것을 목적으로 하지 않는다. 대신, BSON은 MongoDB와 같은 특정 시스템에서 데이터 저장 및 검색의 효율성과 성능 향상을 목적으로 사용된다.
몽구스(mongoose) 사용하는 방법
- 스키마를 생성한다.
- 스키마를 이용해서 모델을 만든다.
- 모델을 이용해서 데이터를 저장하거나 업데이트하거나 삭제하는 등의 작업을 할 수 있다.
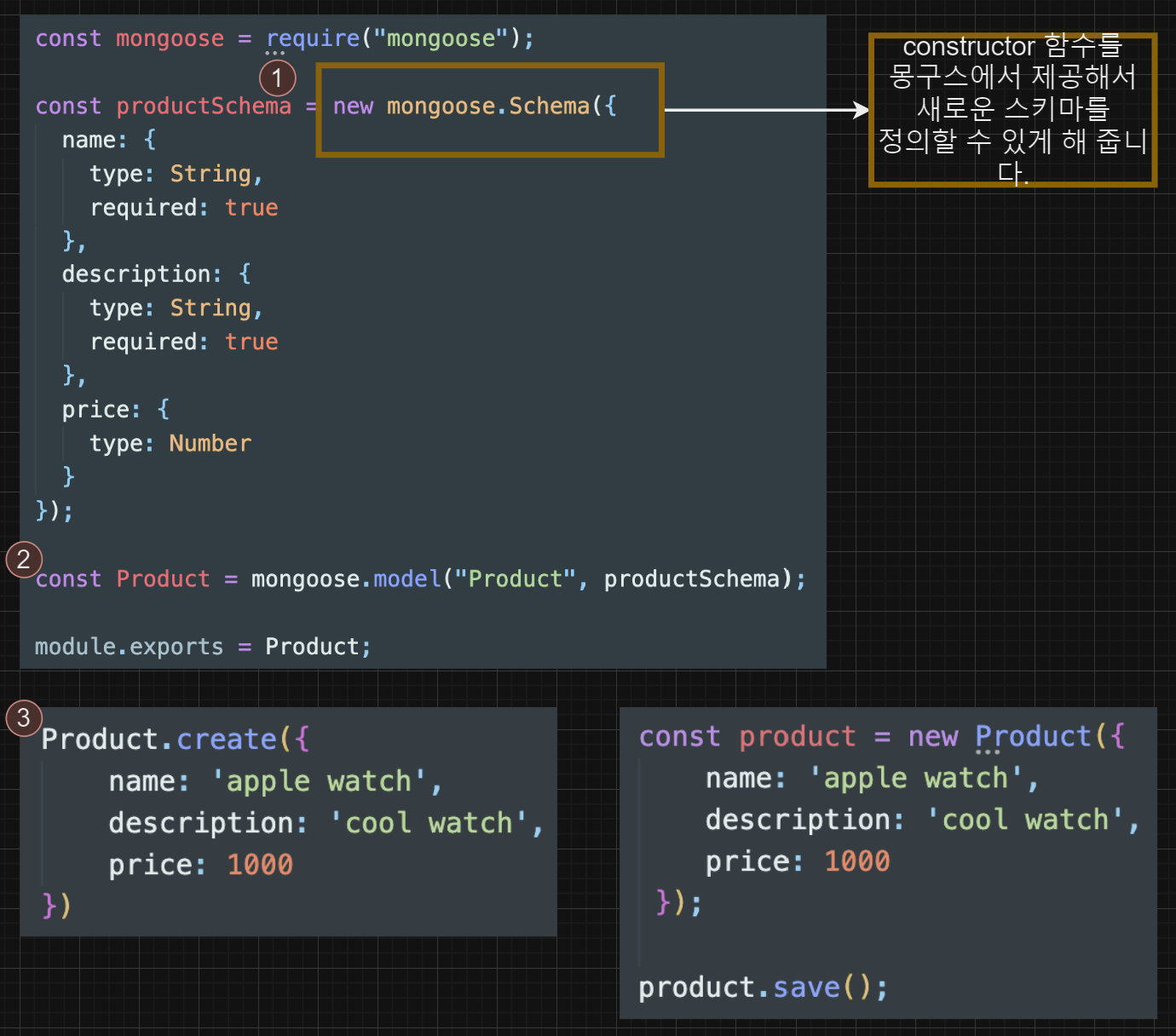
Model 및 Schema 생성하기
파일 생성

스키마 생성
const productSchema = new mongoose.Schema({
name: {
type: String,
required: true
},
description: {
type: String,
required: true
},
price: {
type: Number
}
})const Product = mongoose.model("Product", productSchema)
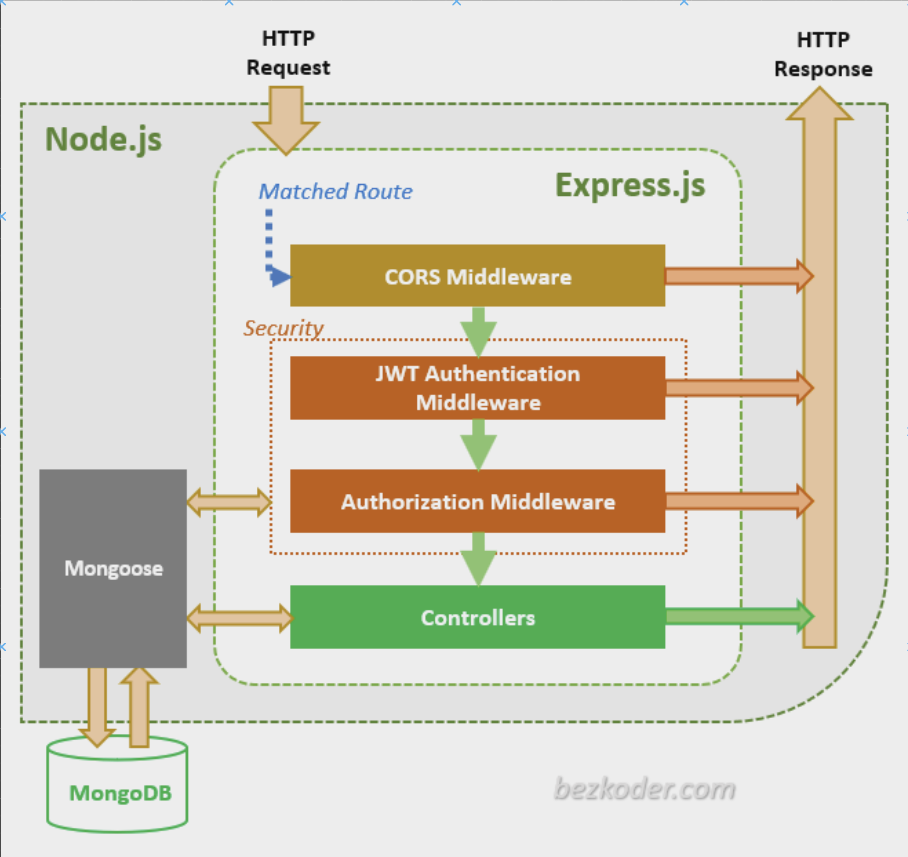
module.exports = ProductCRUD 구현하기
파일 생성
Create
const productModel = require('../models/Product');
async function createProduct(req, res, next) {
try {
const createdProduct = await productModel.create(req.body);
res.status(201).json(createdProduct);
} catch (error) {
next(error);
}
};Product router 생성
const express = require('express');
const productsController = require('../controllers/products.controller');
const productsRouter = express.Router();
productsRouter.post('/', productsController.createProduct) // POST localhost:3000/posts
productsRouter.get('/', productsController.getProducts) // GET localhost:3000/posts
productsRouter.get('/:productId', productsController.getProductById)
productsRouter.put('/:productId', productsController.updateProduct) // PUT localhost:3000/products/1
productsRouter.delete('/:productId', productsController.deleteProduct)Read
async function getProducts(req, res, next) {
try {
const allProducts = await productModel.find({});
res.status(200).json(allProducts);
} catch (error) {
next(error)
}
}
async function getProductById(req, res, next) {
try {
const product = await productModel.findById(req.params.productId);
if (product) {
res.status(200).json(product)
} else {
res.status(404).send()
}
} catch (error) {
next(error)
}
} Update
async function updateProduct(req, res, next) {
try {
let updatedProduct = await productModel.findByIdAndUpdate(
req.params.productId,
req.body,
{ new: true }
// 업데이트가 적용된 후 document를 반환하려면 new옵션을 true로 설정해야 한다.
)
if (updatedProduct) {
res.status(200).json(updateProduct)
} else {
res.status(404).send();
}
} catch (error) {
next (error)
}
};Delete
async function deleteProduct(req, res, next) {
try {
let deletedProduct = await productModel.findByIdAndDelete(req.params.productId)
if (deletedProduct) {
res.status(200).json(deletedProduct)
} else {
res.status(404).send();
}
} catch (error) {
next(error)
}
};Express 에러 처리
const app = require('express')();
app.get('*', function(req, res, next) {
// 이렇게 이 미들웨어에 에러가 발생을 하면
// 익스프레스는 이 에러를 에러 처리기(Handler)로 보내준다.
throw new Error('woops');
});
app.get('*', function(req, res, next) {
// 위의 에러가 발생했기 때문에 에러 처리기로 바로 가야 하기
// 때문에 이 미들웨어는 생략해준다.
// 왜냐하면 이 미들웨어는 에러 처리기(Error Handler)가 아니기 때문이다.
console.log('this will nor print')
});
app.use(function(error, req, res, next) {
// 에러 처리기는 이렇게 4개의 인자가 들어간다.
// 그래서 첫 번째 미들웨어에서 발생한 에러 메시지를 이곳에서 처리해준다.
res.json({ message: error.message });
});
app.listen(3000);원래는 위와 같이 에러처리를 해주면 되지만, 비동기 요청으로 인한 에러를 이렇게 처리해주면 에러 처리기에서 저 에러 메시지를 받지 못하기 때문에 서버가 Crash 되어 버린다.
const app = require('express')();
app.get('*', function(req, res, next) {
// Will crash the server on every HTTP request
setImmediate(() => { throw new Error('woops'); });
});
app.use(function(error, req, res, next) {
// Won't get here, because Express doesn't catch the above error
res.json({ message: error.message });
});
app.listen(3000);How to solve?
const app = require('express')();
app.get('*', function(req, res, next) {
// Reporting async errors *must* go through `next()`
setImmediate(() => { next(new Error('woops')); });
});
app.use(function(error, req, res, next) {
// Will get here
res.json({ message: error.message });
});
app.listen(3000);