학습 목표 및 학습 내용
학습 목표
- 파일시스템 구현을 위한 기본 개념을 설명할 수 있다.
학습 내용
- File system implementation
- File allocation
- Free space management
- Directory implementation
- Performance and recovery
File System Implementation
File system of the user’s viewpoint
- How to show the file system to user?
- File system interface
- File, directory, attribute, and operation
- E.g. tree structure
File system of the storage management viewpoint
- How to map the logical file system to the storage device?
- File system implementation
- Layout, data structures, and algorithms
- It is required to understand the storage internals.
사용자 관점의 파일 시스템
사용자 관점의 파일 시스템은 파일 시스템이 사용자에게 어떻게 표시되는지에 대한 부분입니다. 이는 파일 시스템 인터페이스, 파일, 디렉토리, 속성 및 작업 등을 포함합니다. 예를 들어, 대부분의 운영 체제에서 파일 시스템은 트리 구조로 사용자에게 표시되며, 이는 사용자가 파일과 디렉토리를 쉽게 탐색하고 이해할 수 있도록 해줍니다.
스토리지 관리 관점의 파일 시스템
스토리지 관리 관점의 파일 시스템은 논리적인 파일 시스템을 스토리지 장치에 어떻게 매핑하는지에 대한 부분입니다. 이는 레이아웃, 데이터 구조, 알고리즘 등의 구현 세부사항을 포함합니다. 이는 스토리지의 내부 작동 방식을 이해하는 것이 필요하며, 이는 파일이 저장 장치에 어떻게 저장되고 검색되는지에 영향을 줍니다.
스토리지 관리 관점에서, 파일 시스템은 논리적인 파일과 디렉토리 구조를 물리적인 디스크 섹터와 블록에 매핑하게 됩니다. 이 매핑은 디스크의 효율적인 사용을 가능하게 하며, 파일과 디렉토리의 생성, 삭제, 수정, 읽기 등의 작업을 가능하게 합니다.
따라서, 사용자 관점의 파일 시스템은 사용자의 관점에서 파일과 디렉토리를 조작하고 이해하는 방법에 초점을 맞추고, 스토리지 관리 관점의 파일 시스템은 이러한 파일과 디렉토리가 실제 스토리지 장치에 어떻게 저장되고 관리되는지에 초점을 맞춥니다.
File System Implementation
File system regards a storage device as a sequence of blocks.
- Data is transferred between disk and memory in units of blocks.
- Each block has one or more sectors, which is typically 512 bytes.
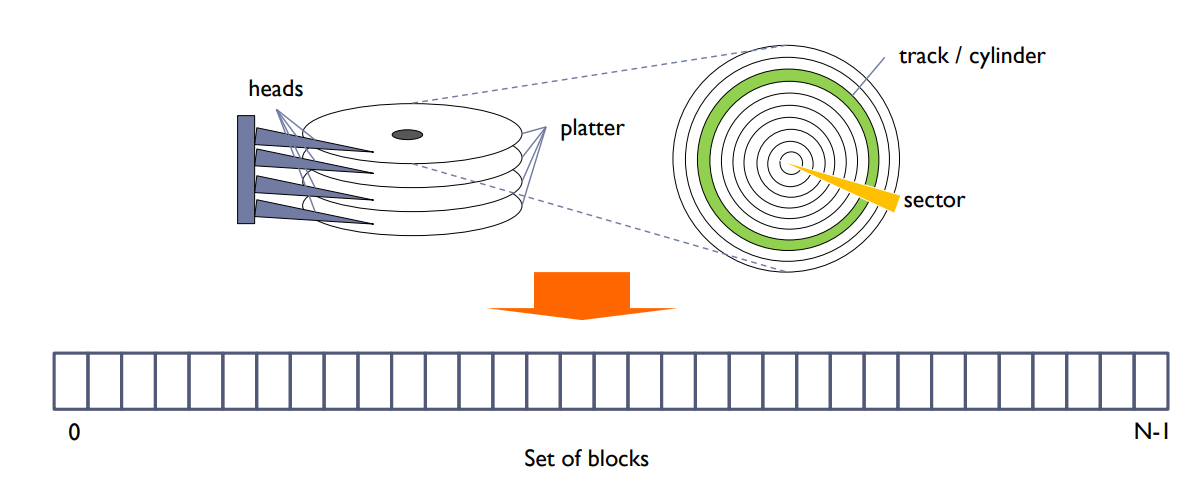
블록 기반 파일 시스템
파일 시스템은 저장 장치를 일련의 블록으로 간주합니다. 데이터는 블록 단위로 디스크와 메모리 사이에서 전송됩니다. 각 블록은 하나 이상의 섹터로 구성되며, 일반적으로 각 섹터는 512 바이트입니다. 이렇게 하는 이유는 대용량 데이터를 처리하는 데 있어서 효율성을 향상시키기 위함입니다.
File system implementation
- Both attribute and file data should be stored for each file.
- Attributes - size, permission, owner, time, etc.
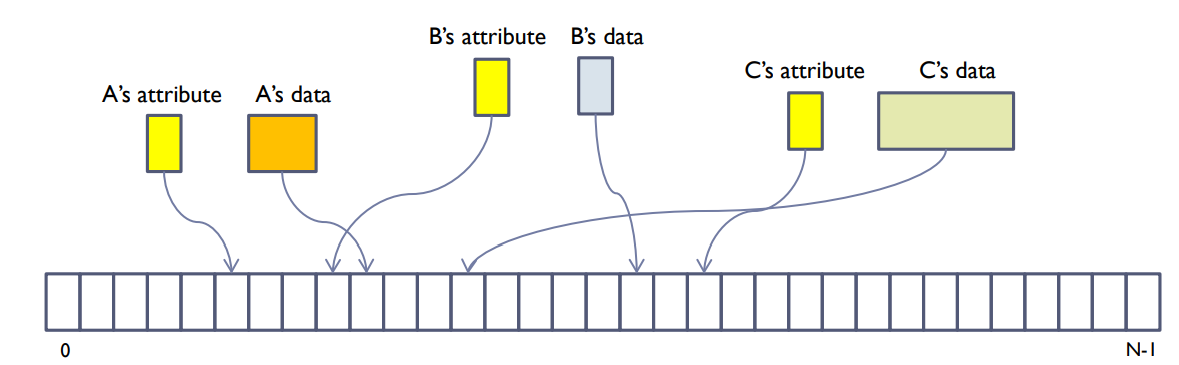
- Attributes - size, permission, owner, time, etc.
- How to allocate the storage for both attributes and file data?
파일 시스템 구현
파일 시스템 구현에는 각 파일에 대해 속성과 파일 데이터 모두가 저장되어야 합니다. 속성에는 크기, 권한, 소유자, 시간 등이 포함됩니다.
Unix file system
- Inode
- Attribute + indexes for file data
- Inode region and file data region are separated.
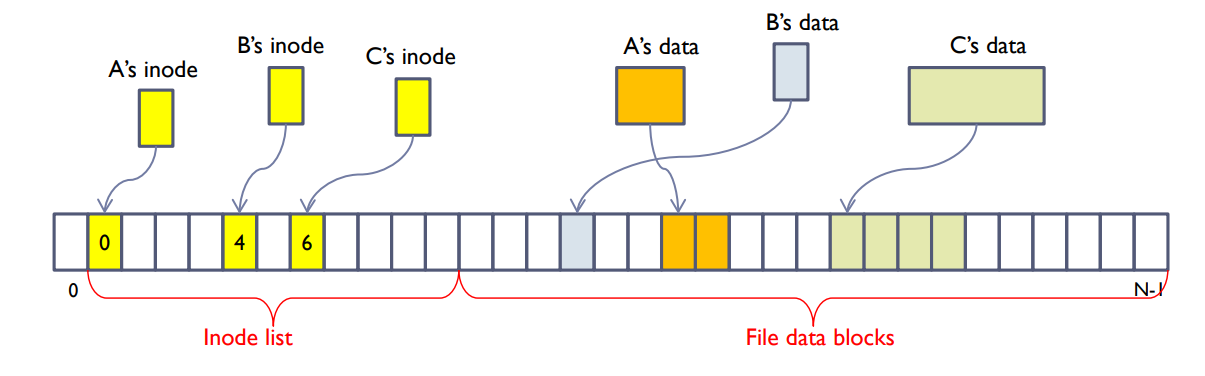
- The sizes of inodes are same, but those of file data are different.
- Inodes can be accessed via i-number.
- How to allocate the storage for file data?
- contiguous / linked / indexed allocation
유닉스 파일 시스템
유닉스 파일 시스템은 이러한 문제를 해결하기 위한 특별한 데이터 구조인 'inode'를 사용합니다. inode는 파일의 메타데이터(크기, 소유자, 수정 시간 등의 속성)와 파일 데이터의 인덱스를 저장합니다. 파일 시스템은 inode 영역과 파일 데이터 영역을 분리하여 관리합니다.
inode의 크기는 일정하지만 파일 데이터의 크기는 다릅니다. inode는 i-number를 통해 접근할 수 있습니다. 이는 각 파일을 고유하게 식별하고 참조하는 데 사용되는 고유 번호입니다.
파일 데이터에 대한 저장 공간을 어떻게 할당할 것인지는 여러 가지 방법이 있습니다. 이에는 연속 할당, 연결 할당, 색인 할당 등이 포함됩니다. 이러한 방식들은 각각의 장단점이 있으며, 특정 파일 시스템에서는 이 중 하나 또는 여러 가지 방식을 사용하여 데이터를 관리합니다.
Contiguous Allocation
- Each file occupies a set of contiguous blocks on the disk.
- Only starting location and length are required.
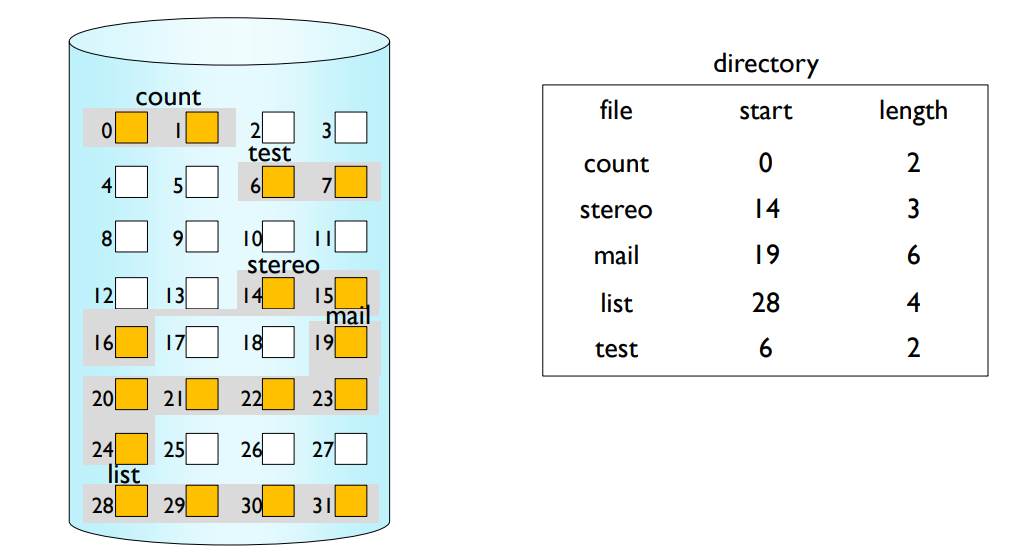
- It is simple to sequential/random access the file.
- It is difficult to find space for a new file.
- Only starting location and length are required.
연속 할당
연속 할당 방식에서는 각 파일이 디스크의 연속적인 블록들에 할당됩니다. 따라서 파일의 시작 위치와 길이만 알면 전체 파일에 접근할 수 있습니다. 이 방식의 장점은 파일에 대한 순차적 혹은 임의 접근이 간단하다는 것입니다. 즉, 파일의 다른 부분에 접근하려면 시작 위치에서 원하는 위치까지 이동하면 됩니다.
그러나 이 방식의 단점은 새로운 파일에 대한 공간을 찾는 것이 어렵다는 것입니다. 이는 디스크 공간이 '단편화'되기 때문입니다. 파일들이 삭제되고 새로 만들어질 때 각각의 파일들이 디스크의 다른 위치에 나타나고 사라지게 되어, 여러 파일이 디스크 상에 불연속적으로 분포하게 됩니다.
Linked Allocation
- Each file is a linked list of disk blocks.
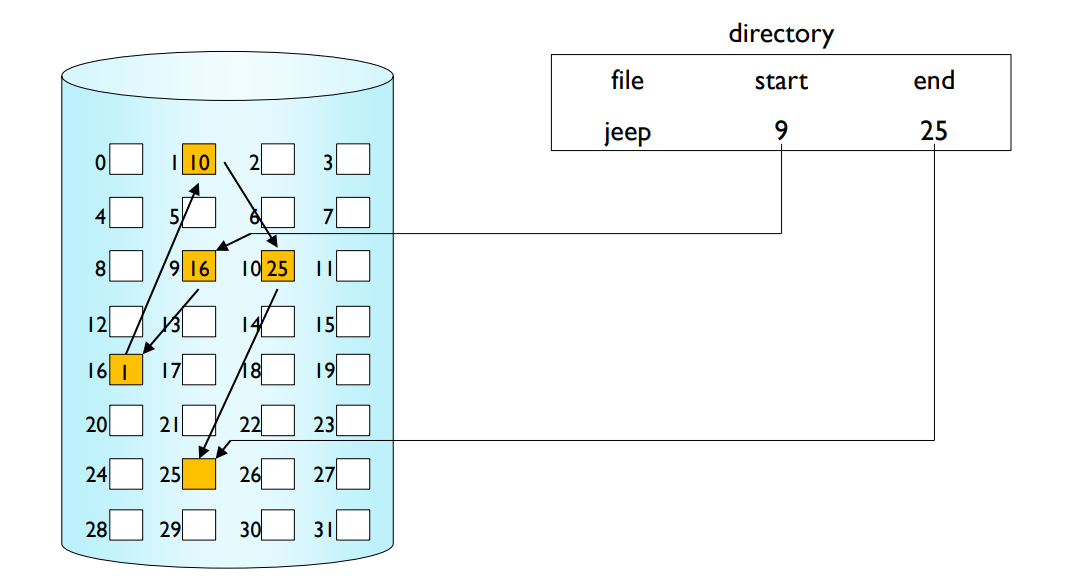
-
E.g. MS-DOS file system (FAT file system)
-
Blocks may be scattered anywhere on the disk. No waste of space.
-
Effective only for sequential access.
-
If a pointer is lost or damaged?
연결 할당
-
연결 할당 방식에서는 각 파일이 디스크 블록의 연결 리스트로 표현됩니다. MS-DOS 파일 시스템(즉, FAT 파일 시스템)이 이 방식의 대표적인 예입니다.
연결 할당의 주요 장점은 블록이 디스크 어디에나 분산될 수 있으므로 공간 낭비가 없다는 것입니다. 즉, 파일의 블록들이 디스크의 빈 공간에 무작위로 분산될 수 있습니다.
그러나 연결 할당의 주요 단점은 파일에 대한 접근이 순차적으로만 가능하다는 것입니다. 즉, 파일의 특정 부분에 직접 접근하려면, 파일의 처음부터 시작하여 해당 부분에 도달할 때까지 모든 블록을 거쳐가야 합니다. 또한, 포인터가 손상되거나 잃어버리게 되면 해당 파일의 일부 또는 전체에 접근할 수 없게 됩니다.
MS-DOS’s FAT file system
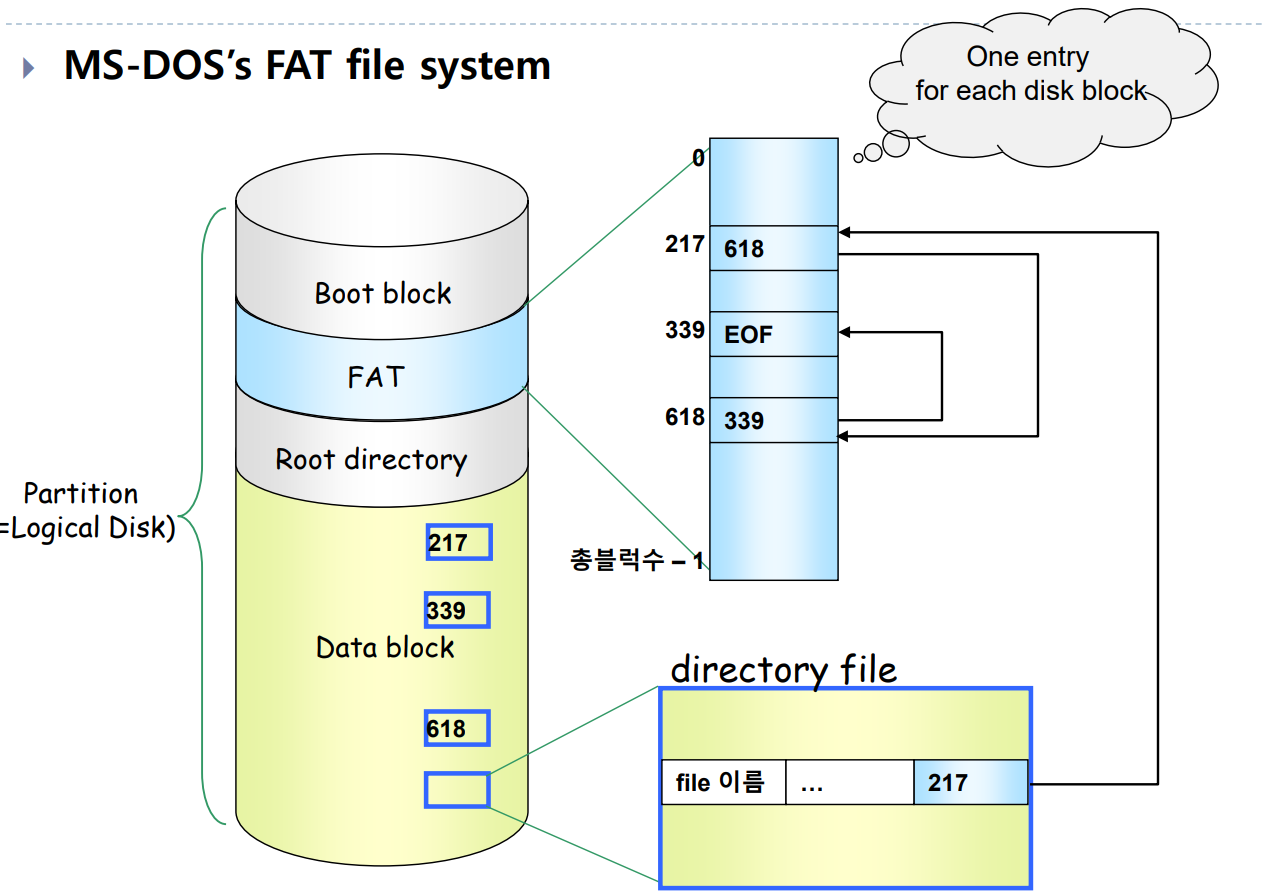
MS-DOS의 FAT 파일 시스템
FAT 파일 시스템은 연결 할당 방식을 사용하는 대표적인 예입니다. 각 블록이 어디에 위치하고 있는지를 추적하기 위해 '파일 할당 테이블'이라는 특별한 구조를 사용합니다. 이 테이블은 디스크의 각 블록에 대한 포인터를 저장하고 있으며, 이를 통해 파일의 다음 블록이 어디에 있는지 알 수 있습니다.
Indexed Allocation
- It brings all pointers into the index block.
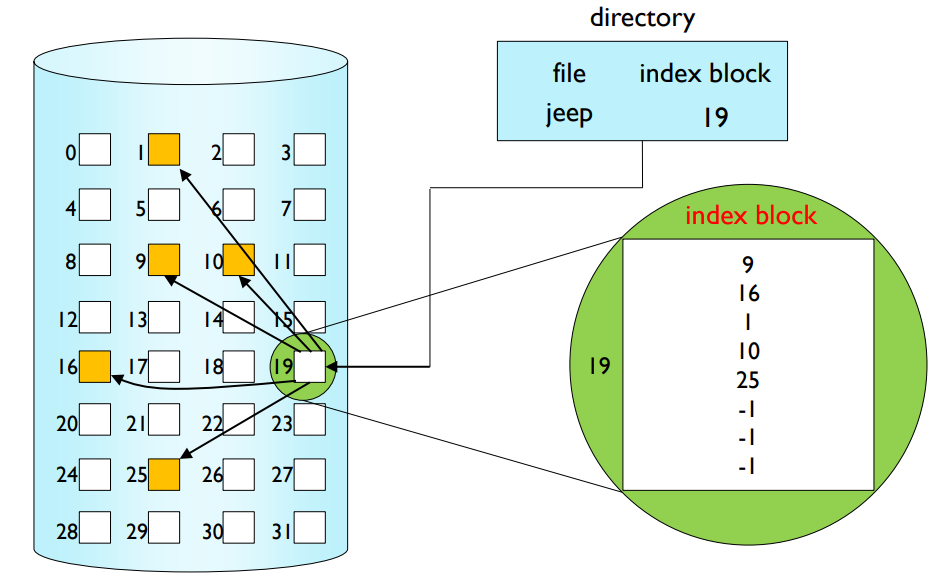
- Random access is possible.
- It doesn’t need to find a contiguous blocks.
- It requires one index block per file.
- If the size of index block is still small to hold pointers for a large file?
- Multilevel index (e.g. UNIX file system)
- 15 pointer fields in inode of Unix file system.
- 12 pointer fields for direct blocks
- 3 pointer fields for indirect blocks.
- Single, double, triple
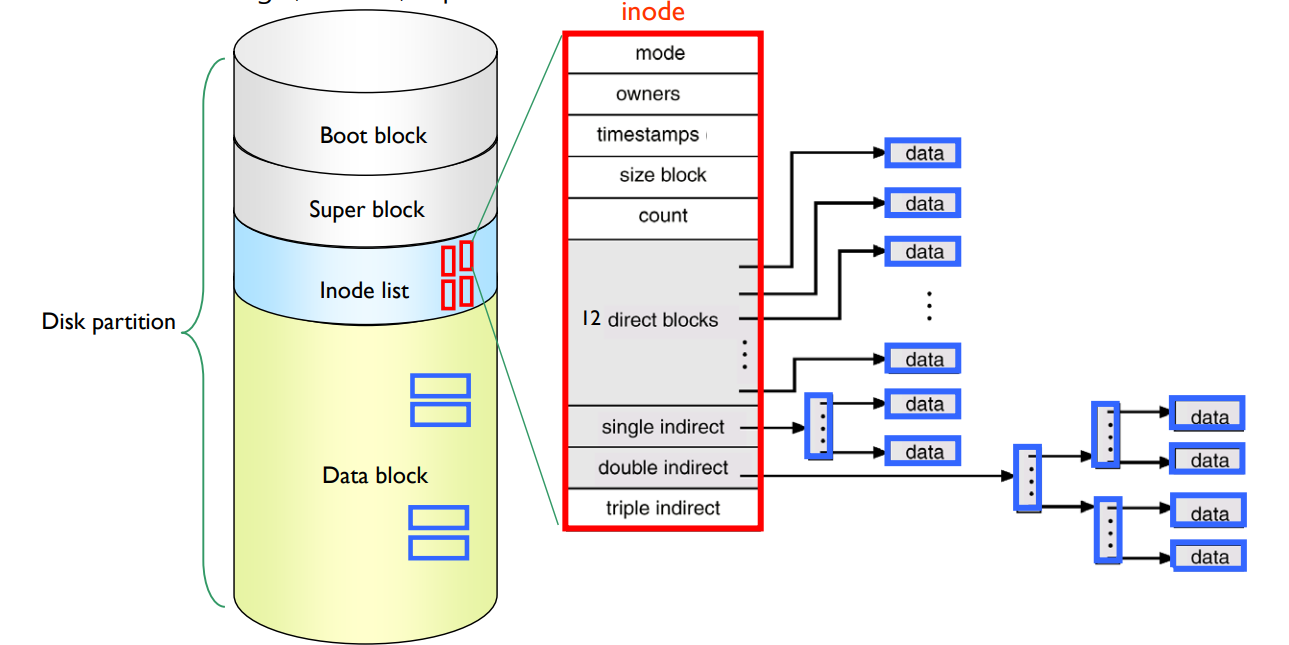
- 15 pointer fields in inode of Unix file system.
인덱스 할당
인덱스 할당 방식에서는 모든 포인터를 인덱스 블록에 모읍니다. 이로 인해 임의 접근이 가능해지고, 연속적인 블록을 찾는 데 필요하지 않게 됩니다. 하지만, 각 파일마다 하나의 인덱스 블록이 필요하다는 단점이 있습니다. 만약 인덱스 블록의 크기가 큰 파일을 위한 포인터를 들고 있기에 너무 작다면 문제가 발생할 수 있습니다.
이를 해결하기 위해 다중 레벨 인덱스 방식이 사용될 수 있습니다. 예를 들어, Unix 파일 시스템에서는 inode에 15개의 포인터 필드가 있습니다. 이 중 12개는 직접 블록을 위한 것이고, 나머지 3개는 간접 블록을 위한 것입니다. 간접 블록은 다시 단일, 더블, 트리플 등으로 나뉘어집니다.
Free Space Management
Bit map (also called bit vector)
- If block[i] is allocated, bit is 1; else, bit is 0.
- E.g.
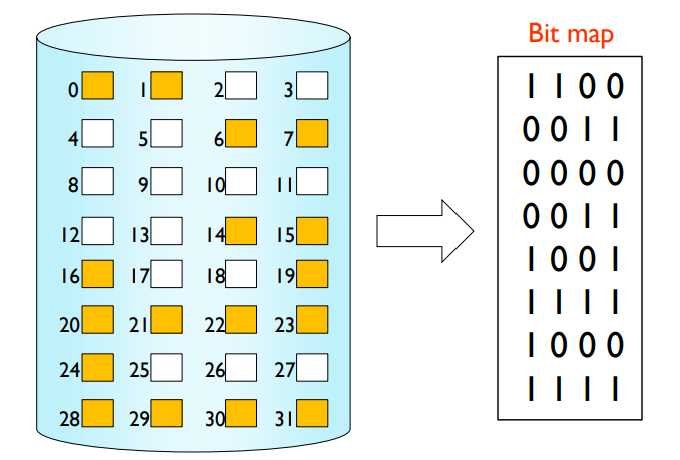
- Easy to get contiguous free blocks.
- Bit map requires extra space.
- e.g. block size = 2^12 bytes (= 4KB)
- disk size = 2^40 bytes (= 1TB)
- n = 2^40/2^12 = 2^28 bits (= 32MB)
Linked list
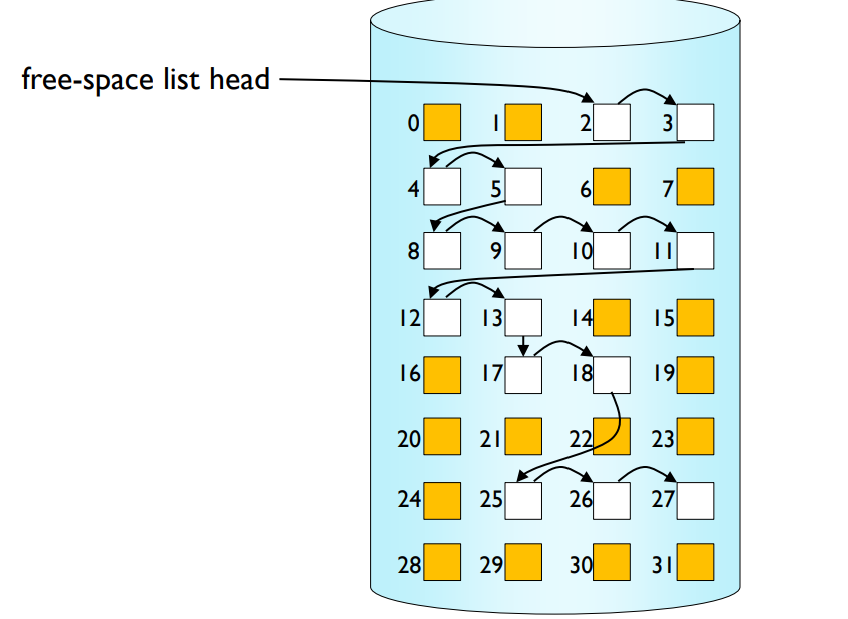
- No space overhead.
- Cannot get contiguous free blocks easily.
Grouping
- Modification of linked list approach.
- The first n-1 of free blocks are actually free.
- The last block contains the addresses of another n free blocks.

공간 관리
공간 관리 방식에는 비트맵(또는 비트 벡터) 방식, 연결 리스트 방식, 그룹핑 방식 등이 있습니다.
비트맵 방식에서는 할당된 블록을 1로, 미할당 블록을 0으로 표시합니다. 이는 연속적인 빈 블록을 쉽게 찾을 수 있다는 장점이 있습니다. 하지만 비트맵 자체가 추가적인 공간을 필요로 한다는 단점이 있습니다.
연결 리스트 방식에서는 공간 오버헤드가 없다는 장점이 있습니다. 하지만 연속적인 빈 블록을 쉽게 찾는 것이 어렵다는 단점이 있습니다.
그룹핑 방식은 연결 리스트 접근 방식의 변형입니다. 여기서 첫 n-1개의 빈 블록은 실제로 빈 블록이며, 마지막 블록은 다른 n개의 빈 블록의 주소를 담고 있습니다. 이로써, 연결 리스트 방식의 공간 오버헤드 문제를 해결하면서도 빈 블록을 효과적으로 관리할 수 있습니다.
Directory Implementation
Linear list
- ( file name, pointer to the file )
- Simple to implement.
- Time-consuming to search a file.
- B-tree can be used.
Hash Table
- Linear list with hash data structure.
- Hash function converts “file name” to “pointer to the file’s linear list”.
- Reduces directory search time.
- Collisions should be solved.
디렉토리 구현
디렉토리 구현은 주로 선형 리스트 방식과 해시 테이블 방식을 사용합니다.
선형 리스트 방식에서는 파일 이름과 파일을 가리키는 포인터를 한 쌍으로 구성합니다. 이 방식은 간단하게 구현할 수 있지만, 파일을 검색하는 데 시간이 많이 소요됩니다. 이를 개선하기 위해 B-트리와 같은 데이터 구조를 사용할 수 있습니다.
해시 테이블 방식에서는 해시 데이터 구조를 활용한 선형 리스트를 사용합니다. 해시 함수는 "파일 이름"을 "파일의 선형 리스트를 가리키는 포인터"로 변환합니다. 이를 통해 디렉토리 검색 시간을 줄일 수 있지만, 충돌 해결 문제가 발생할 수 있습니다.
Performance and Recovery
Efficiency
- Keeps a file’s data blocks near that file’s inode block to reduce seek time.
- The “last access time” information in inode requires a block read and write.
- The size of pointers used to access data? 16bit or 32bit.
Performance
- Buffer cache
- Separate section of main memory for frequently used blocks.
- read-ahead
- Techniques to optimize sequential access
Buffer cache
- Whenever files are accessed, file data should be fetched from disks.
- However, the disk accesses incurs large I/O overhead.
- On file access patterns, data that are accessed once will be used again soon(temporal locality)
- Buffer cache keeps the blocks that will be used again soon to reduce disk accesses.
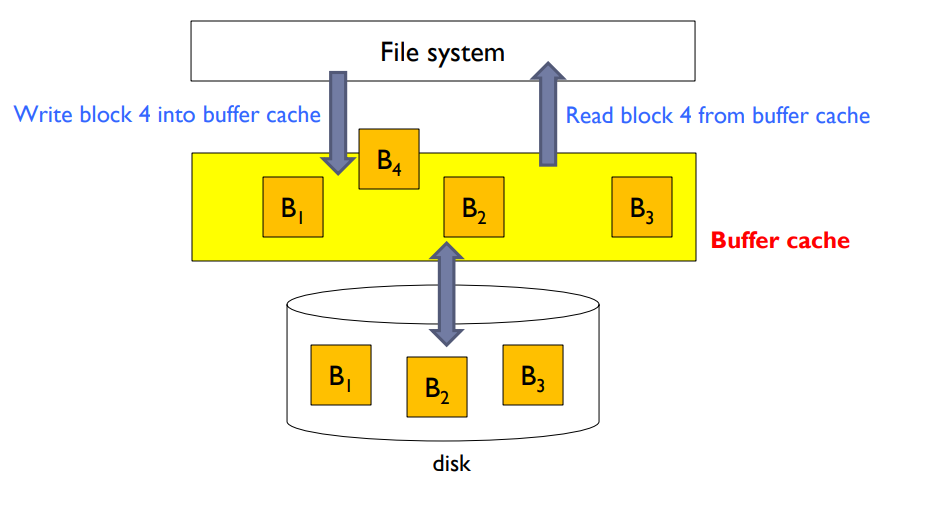
성능과 복구
효율성을 높이기 위해, 파일의 데이터 블록은 파일의 inode 블록 근처에 유지되어 탐색 시간을 줄입니다. inode의 "마지막 접근 시간" 정보는 블록 읽기 및 쓰기를 필요로 합니다. 데이터 접근에 사용되는 포인터의 크기는 16비트 또는 32비트일 수 있습니다.
성능 향상을 위해 "버퍼 캐시"와 "read-ahead" 기법이 사용됩니다. 버퍼 캐시는 주기억장치의 별도 섹션에서 자주 사용되는 블록을 보관합니다. read-ahead 기법은 순차적 접근을 최적화하는 데 사용됩니다.
Inconsistency can occurs.
- Some part of file system is kept in memory for speed up.
- What if system crashes? Not all data can be saved to disk.
- If directory or metadata(inode) are lost?
Solutions for consistency
- Consistency checker (e.g. fsck in UNIX)
- Compare data in directory structure with data blocks on disk, and tries to fix inconsistencies.
- Synchronous write for important metadata.
- Journaling
Use system programs to back up data
- From disk to another storage device.
- Recover lost file or disk by restoring data from backup.
불일치 발생 가능성
파일 시스템의 일부는 속도를 높이기 위해 메모리에 유지됩니다. 그러나 시스템이 충돌하면 모든 데이터가 디스크에 저장되지 않을 수 있습니다. 디렉토리나 메타데이터(inode)가 손실된다면 문제가 발생할 수 있습니다.
일관성 유지 방법
일관성 검사기: UNIX의 fsck와 같은 일관성 검사기는 디렉토리 구조의 데이터와 디스크 상의 데이터 블록을 비교하고 일관성을 복원하려 시도합니다.
중요 메타데이터에 대한 동기화 쓰기: 중요한 메타데이터를 안전하게 유지하기 위해 동기화 쓰기를 사용할 수 있습니다.
저널링: 파일 시스템 변경에 대한 로그를 유지하여 시스템 충돌 후 일관성을 복원하는 방법입니다.
시스템 프로그램을 사용한 데이터 백업
디스크에서 다른 저장 장치로 데이터를 백업하면 파일이나 디스크가 손실될 경우 백업에서 데이터를 복원할 수 있습니다. 이를 통해 시스템의 안정성을 높일 수 있습니다.
Summary
- File system regards a storage device as a sequence of blocks.
- In file system implementation, both attribute and file data should be stored for each file.
- The various files can be allocated on the disk in three ways: contiguous, linked, and indexed allocation.
- Free space management scheme is also required for file system implementation.
- In many operating systems, buffer cache is used to improve the file system performance, but data inconsistency can occur.
네, 요약된 내용에 대해 자세히 설명하겠습니다.
- 파일 시스템은 스토리지 장치를 블록의 연속으로 간주합니다.
파일 시스템은 디스크 상의 데이터를 블록 단위로 관리합니다. 이 블록은 일반적으로 512바이트와 같이 고정된 크기를 가지며, 이는 파일 시스템이 데이터를 관리하는 기본 단위입니다.
- 파일 시스템 구현에서는 각 파일에 대해 속성과 파일 데이터 모두를 저장해야 합니다.
각 파일에 대한 메타데이터(파일의 크기, 권한, 소유자, 시간 등의 속성)와 실제 파일 데이터를 디스크에 저장합니다. 이는 파일 시스템이 파일을 찾아서 사용자에게 제공할 수 있도록 하는 기본적인 요소입니다.
- 다양한 파일은 디스크에 연속 할당, 연결 할당, 색인 할당의 세 가지 방법으로 할당될 수 있습니다.
연속 할당: 각 파일이 디스크 상의 연속된 블록에 저장되는 방식입니다. 이 방법은 구현이 단순하지만, 디스크 공간을 효율적으로 사용하기 어렵습니다.
연결 할당: 각 파일이 디스크의 여러 위치에 분산되어 저장되며, 이 위치들은 링크를 통해 연결된 방식입니다. 이 방식은 디스크 공간을 효율적으로 활용할 수 있지만, 임의 접근이 느립니다.
색인 할당: 각 파일에 대한 모든 블록 포인터를 하나의 색인 블록에 모으는 방식입니다. 이 방식은 임의 접근이 가능하며 연속 할당의 단점을 해결했지만, 대용량 파일에 대해서는 복잡해질 수 있습니다.
4. 파일 시스템 구현에는 또한 빈 공간 관리 체계가 필요합니다.
비트맵이나 연결 리스트, 그룹화와 같은 여러 가지 방식을 통해 빈 공간을 효과적으로 관리할 수 있습니다.
- 많은 운영체제에서는 파일 시스템 성능을 향상시키기 위해 버퍼 캐시를 사용하지만, 데이터 불일치가 발생할 수 있습니다.
버퍼 캐시는 메모리에 자주 사용되는 블록을 보관하여 디스크 I/O를 줄이는 방식입니다. 이는 시스템의 전반적인 성능을 크게 향상시키지만, 시스템의 충돌이나 비정상적인 종료 등이 발생했을 때 데이터 불일치 문제를 일으킬 수 있습니다. 메모리에 있는 데이터와 디스크에 있는 데이터 간에 불일치가 생기면, 파일 시스템은 일관성을 잃게 됩니다.
이러한 문제를 해결하기 위해 일관성 검사 도구(UNIX에서는 fsck와 같은)가 사용됩니다. 이 독특한 도구는 디스크 상의 데이터 블록과 디렉토리 구조의 데이터를 비교하고 불일치를 수정하려고 시도합니다.
또 다른 방법은 중요한 메타데이터에 대해 동기식 쓰기를 수행하는 것입니다. 이는 메모리와 디스크 간에 데이터 일관성을 유지하는데 도움이 됩니다.
더 나아가, 저널링이라는 기법도 사용됩니다. 저널링 파일 시스템은 모든 변경사항을 로그(저널)에 먼저 쓴 후에 실제 파일 시스템에 적용하여, 시스템 충돌 등으로 인한 데이터 불일치 문제를 방지합니다.
또한, 시스템 프로그램을 사용하여 데이터를 다른 저장 장치로 백업하는 것도 중요합니다. 이렇게 하면 손실된 파일이나 디스크를 백업 데이터로부터 복원할 수 있습니다.
