스트림 활용
- 스트림을 활용하여 컬렉션을 사용하는 외부반복을 내부반복으로 바꿀 수 있다.
- 외부 반복: for(Dish d: menu) {
- 내부 반복: .filter(Dish::isVegeterian)
- 스트림 API가 지원하는 연산을 활용하면 -> 필터링, 슬라이싱, 매핑, 검색, 매칭, 리듀싱 등 다양한 데이터 처리 가능
필터링
- filter 메서드는 predicate (boolean을 반환하는 함수)를 인수로 받아, 조건에 만족하는 요소들에 대해 필터링한다.
- distinct 메서드는 주어진 요소들로부터 고유 요소로 이루어진 스트림을 반환 (필터링) 한다.
스트림 슬라이싱 (for Java9)
- takeWhile, dropWhile
- 이미 정렬돼있음을 아는 list 또는 stream에서 사용
- predicate을 input으로 받아서, predicate이 참 또는 거짓이 되면 더이상의 스트림 반복을 멈추고 결과를 return 한다.
- limit(n)
- 스트림 축소: predicate을 만족하는 n개가 채워지면, 즉시 결과를 반환
- 소스가 정렬되지 않았다면, limit 결과도 미정렬 상태로 반환
- skip(n)
- 처음 n개 요소 제외한 스트림 반환
매핑
- map
- 함수를 인수로 받음
- map 메서드 여러개 chaining 가능
- flatMap
- ["Hello", "World"] -> [h, e, l, l, o, W, o, r, l, d]
- 각 배열을 스트림이 아니라 스트림의 contents로 매핑
검색과 매칭
- allMatch(boolean 반환), anyMatch(boolean 반환), noneMatch(boolean 반환), findFirst(객체 반환), findAny(객체 반환)
- 모두 최종연산
- 쇼트서킷 기법(전체 스트림을 처리하지 않더라도 앞에서의 결과에 따라 즉시 결과를 반환)으로 동작, 즉 자바의 &&, ||와 같은 연산 활용
- findFirst vs. findAny ?
- 언뜻 보면 둘다 비슷해보임. 실제로 병렬 실행이 아닌 경우에는 둘 모두 같은 결과를 반환함.
- 하지만 병렬 실행의 경우, 첫번째 요소를 찾기 어려움 (각 스레드에서 수행되었을 때, 어떤 것이 첫번째 요소인지 판단 hard). -> 따라서 요소의 반환 순서가 상관 없다면 병렬 스트림에서는 제약이 적은 findAny를 사용
리듀싱
- 요소의 합
- .reduce(0, (a,b) -> a+b) = .reduce(0, Integer::sum)
- 초기값 0, BinaryOperator를 통해, 우리는 sum을 도출해낼 수 있음
- 마찬가지로 요소의 min, max도 .reduce(0, Integer::max) 등으로 reduce 가능
- reduce의 장점 & 병렬화
- reduce를 사용하게 되면 내부 반복의 추상화로, 내부 구현에서 병렬로 reduce를 실행할 수 있게 됨
- but 외부 반복의 명시적 합계에서는 sum 변수를 공유해야하므로 (가변 누적자 패턴, mutable accumulator pattern) 쉽게 병렬화가 어려움
- 이렇게 쉽게 병렬화를 이용할 수 있게 되는 대신에 몇가지 제한점이 있는데, reduce에 넘겨준 람다의 상태가 바뀌지 말아야하고, 연산이 어떤 순서로 실행되더라도 결과가 바뀌지 않아야 한다. (like sum)
- 스트링 연산의 stateless & stateful
- map, filter 등은 입력 스트림에서 각 요소를 받아, 결과를 출력 스트림으로 보내기만 하면 되어서, 내부 상태를 갖지 않는 stateless 이다.
- 반면 reduce, sum, max 등은 누적된 결과를 기반으로 다음 operation 의 대상이 달라지는 동작으로, 결과를 누적할 내부 상태가 필요하다. sorted나 distinct도 마찬가지로, 기존에 정렬된 스트림 또는 기존에 나왔던 요소의 정보에 따라 다음 요소를 정렬할지, 담을지가 달라지려면, 과거의 이력을 알고 있어야한다.
- 즉, 모든 요소가 버퍼에 추가되어있어야 한다. -> 데이터 스트림의 크기가 크거나 무한이라면 문제 발생 가능
-> 요러한 친구들을 stateful operation이라고 한다. (내부상태 가짐)
실전 연습
- .sorted(comparing(Transaction::getValue))
-> 요소의 getValue된 값을 기반으로 정렬함 - .distinct.collect(toList())
-> 요소를 중복없이 나열 (.collect(toSet())도 가능) - .collect(joining())
-> 요소 문자열을 한 문자열로 합친다. - .min(comparing(Transaction::getValue))
-> 요소의 getValue 된 값이 가장 작은 아이를 return
숫자형 스트림
- 줄곧 우리가 해왔던 .reduce(0, Integer::max)
- 이 친구는 알고보면 박싱 비용 (Integer -> int) 가 숨어있음
- 해당 박싱 비용 없이 max, sum등을 바로 호출하기 위해 기본형 특화 스트림을 제공한다 (IntStream, DoubleStream, LongStream 등)
- .stream().mapToInt(Dish::getCalories) 등을 통해 특화 스트림으로 변경 가능하고, 특화 스트림을 다시 일반 스트림으로 전환하려면 intStream.boxed() 와 같이 boxed 메서드를 이용하면 된다.
- 특정 범위의 숫자를 이용할 때 용이함
- Intstream.range(1, 100): 2포함 ~ 99포함
- Intstream.rangeClosed(1, 100): 1포함 ~ 100포함
스트림 만들기
- Arrays.stream()을 통해 배열 -> stream 전환 가능
- 파일로 스트림 만들기
- File.lines는 주어진 파일의 문자열을 스트림으로 반환
- 스트림은 자원을 자동으로 해제 가능한 AutoCloseable 이라 try-finally를 활용하여 finally에서 파일의 파이프를 닫아주는 작업을 따로 하지 않아도 된다. (Stream 인터페이스는 AutoCloseable 인터페이스의 구현체)
- 함수로 무한 스트림 만들기
- Stream.iterate, Stream.generate
- 스트림은 요청할 때마다 주어진 함수를 이용해서 값을 만든다.
- Stream.iterate(0, n->n+2).limit(10).forEach(System.out::println)
- limit 조건이 없다면 무한히 n->n+2 를 호출하여 무한히 짝수를 뱉게될 것이다.
- 0은 초기값 의미. 이러한 스트림을 무한 스트림, 언바운드 스트림이라고 표현한다.
- iterate는 연속된 일련의 값을 만들 때 사용
java8 까지는 이렇게 limit으로 밖에 스트림의 종료를 구현 못하지만, 이를 타파하기 위해 java9에서는 iterate에 두번째 인수를 추가하여, 언제까지 작업을 수행할 것인지 제한이 가능하다.- ex. Stream.iterate(0, n->n<100, n->n+2)
- 생각해보니 java8에서 위의 기능을 구현하려면, iterate 후에 takeWhile을 사용하면 동등한 기능을 구현할 수 있다.
- generate: 생산된 각 값을 연속적으로 계산하지 않는다.
- Supplier를 인수로 받아서 새로운 값을 생산한다.
- ex. Stream.generate(Math::random)
부록
stream의 forEach와, collection의 forEach()의 차이점
- 어엿 듣기로는, stream foreach를 되도록이면 사용하지 않는게 좋다는 이야기를 들어서..
- 이펙티브 자바 아이템 46에 따르면, forEach 연산은 최종 연산 중 기능이 가장 적고 가장 ‘덜’ 스트림답기 때문에, forEach 연산은 스트림 계산 결과를 보고할 때(주로 print 기능)만 사용하고 계산하는 데는 쓰지 말자 라며, stream.forEach()의 사용에 주의를 준다.
- 스트림 병렬화에 대한 공식 문서의 Side-effects 항목을 참고하면, forEach 내부에 로직이 하나라도 더 추가된다면 동시성 보장이 어려워지고 가독성이 떨어질 위험이 있다.
- from) https://woowacourse.github.io/javable/post/2020-05-14-foreach-vs-forloop/
- Angelika Langer가 컨퍼런스에서 발표한 글에 따르면, 일반적으로 Stream.forEach()를 사용하면 전통적인 for-loop를 사용할 때보다 오버헤드가 훨씬 심각하게 발생하기 때문에, 모든 for-loop를 Stream.forEach()로 대체하면, 애플리케이션 전체에 걸쳐 누적되는 CPU 싸이클 낭비는 무시하지 못할 수준이 될 수 있다.
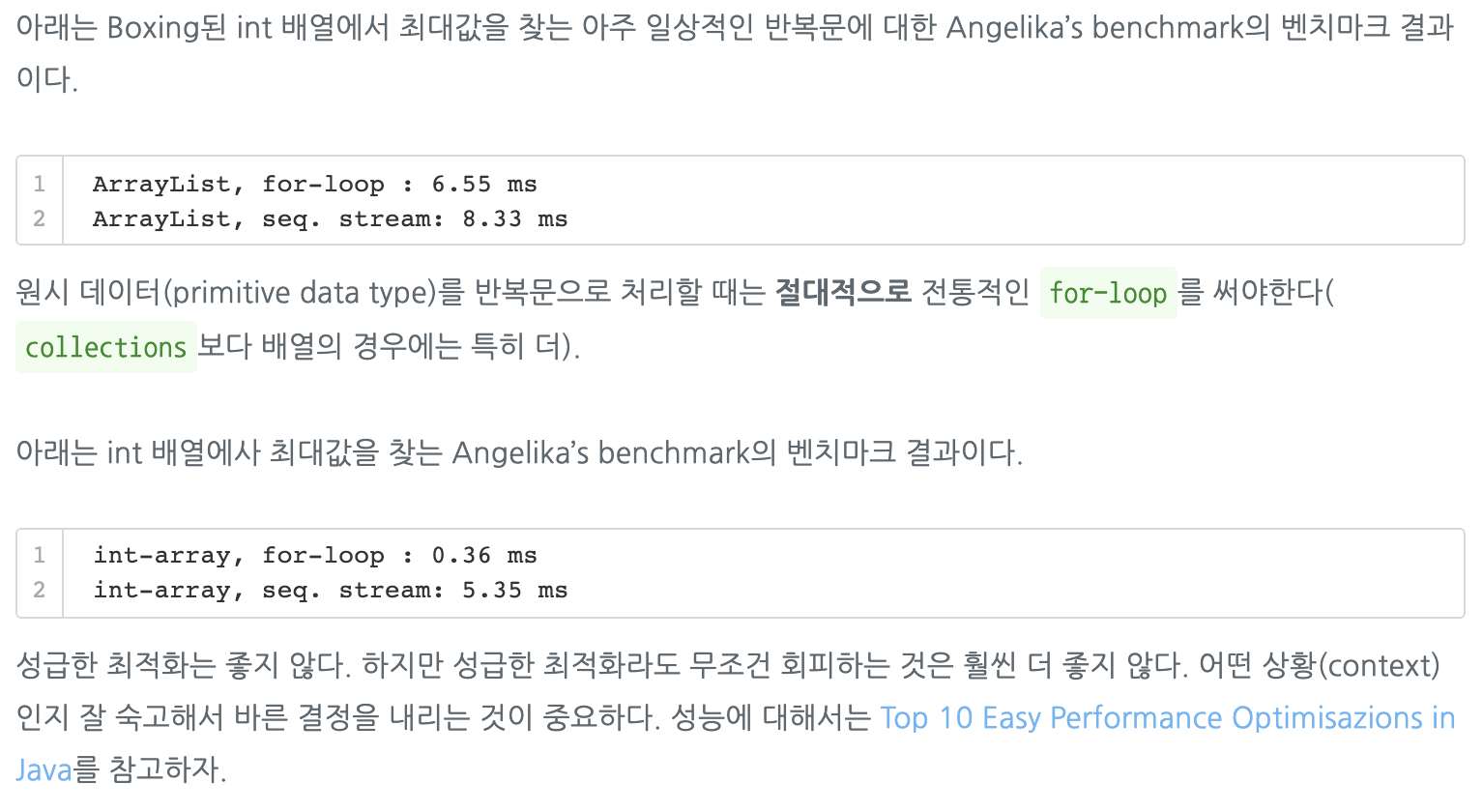
- from) https://homoefficio.github.io/2016/06/26/for-loop-%EB%A5%BC-Stream-forEach-%EB%A1%9C-%EB%B0%94%EA%BE%B8%EC%A7%80-%EB%A7%90%EC%95%84%EC%95%BC-%ED%95%A0-3%EA%B0%80%EC%A7%80-%EC%9D%B4%EC%9C%A0/
- stream ForEach
- 처리 순서 보장하지 않음
- 병렬 스레드에서 예상치 못한 상황이 발생할 수 있음 (synchronization 등)
- https://stackoverflow.com/questions/23218874/what-is-difference-between-collection-stream-foreach-and-collection-foreach 참고
java8에서 등장한 null을 확인하는 Optional이라는 새로운 라이브러리 클래스
- null의 많은 에러 때문에 Optional를 만들었다는 자바8 라이브러리 설계자.
- Optional은 값이 존재하는지 확인하고, 값이 없을 때 어떻게 처리할지 강제하도록 되어있음
- isPresent() -> Optional에 값의 여부를 boolean으로 반환
- isPresent(Consumer block)은 값이 있으면 주어진 블록 수행
- get() -> 값이 있으면 값 반환, 없으면 NPE가 아닌 NoSuchElementException을 일으킴
- orElse(T other) -> 값이 있으면 값 반환, 없으면 other(기본값) 반환
- npe vs. nosuchelementException
- NPE: runtime Exception, 즉 unchecked Exception
- 그런데 NoSuchElementException도 runtime exception이넹 ㅎ;
- chekced exception과 unchecked exception의 간단한 차이
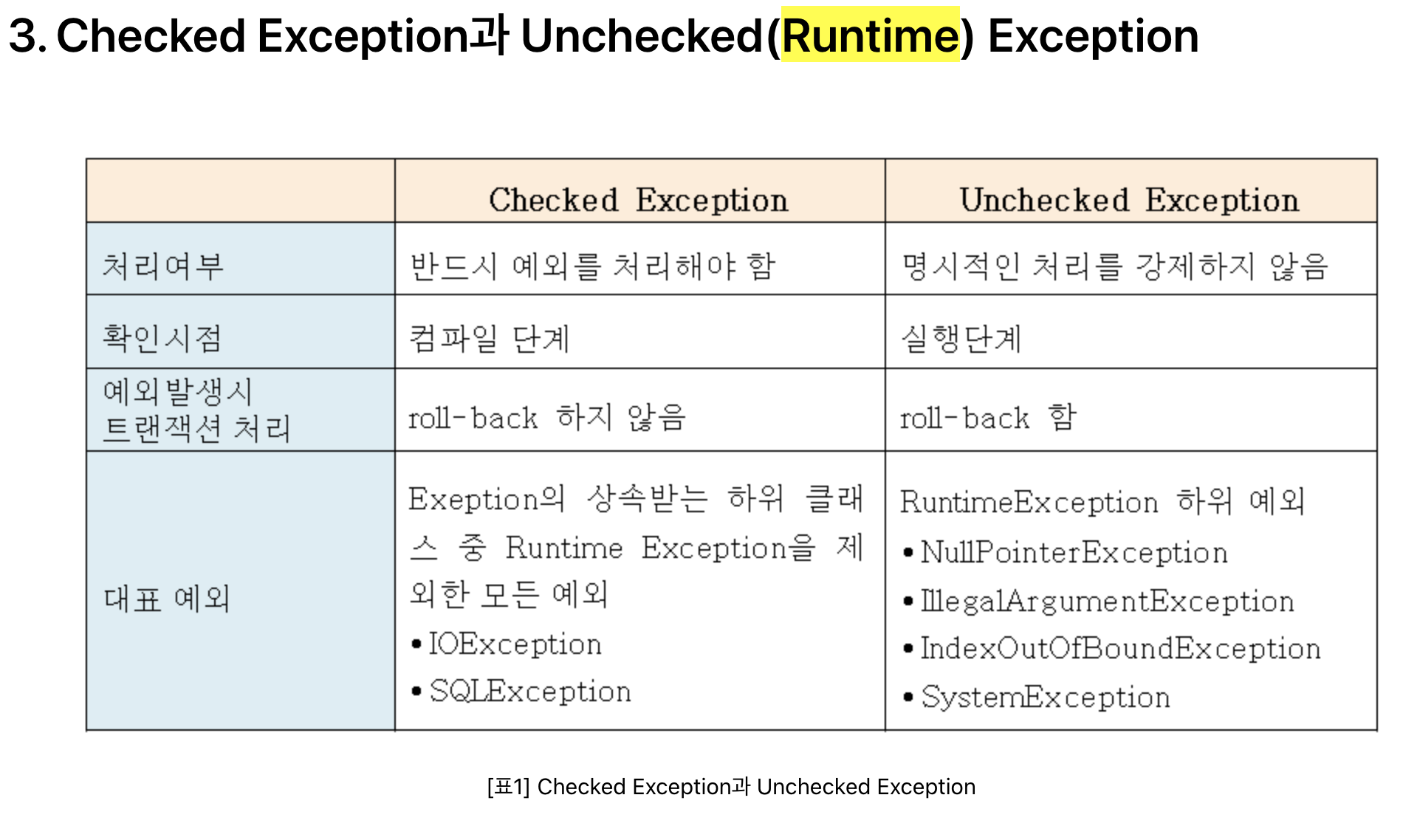
(from https://www.nextree.co.kr/p3239/) - checked Exception은 제일 끝단 까지 던지더라도 rollback이 안된다는 충격적인 이야기,, !_!
익명클래스 vs. 람다
- 사실 람다 자체가 FI의 구현에 한해서, 익명클래스를 더욱 단순화한 개념이라고 앞서 다룬적이 있다.
- 하지만 익명클래스는, FI를 구현할 때에 추가적인 인스턴스 변수를 추가하고, 추가적인 메소드를 구현할 수 있는 반면, 람다는 FI에서 명시했던 abstract method 구현밖에 할 수가 없다.
- 이 덕분에 람다는, stateless 하다고 명시적으로 이야기할 수 있으나, FI를 구현한 클래스는 stateless 하다고 명시적으로 얘기할 수 없다.
- 즉, 람다는 상태를 바꾸지 않는다.
- 스트림을 병렬로 처리하면서 올바른 결과를 얻으려면, stateless 해야하므로, FI를 구현하더라도 최대한 인스턴스 변수를 추가하여 상태를 저장하게 하는 등과 같은 구현은 피해야 병렬성에 문제가 없다. (Stream에서 제공해주는 병렬성 편하게 쓰려면 이정도는 감수해라~ 고런느낌 ㅎㅎ;)

꿈많은 개발자, 일상 기록을 곁들인