
💡 1편에 이어서 계속 되는 내용입니다 ! 앞의 내용은 1편을 참고해주세요 !
형식 검사, 형식 추론, 제약
이 쯤되면 궁금한게 있을 것이다. 람다 표현식 자체에는 람다가 어떤 함수형 인터페이스를 구현하는지의 정보가 포함되어 있지 않은데, 도대체 어떤 함수형 인터페이스를 사용하는지 알고, 검사를 하는 것일까?
이번 챕터에 그 내용이 있다. 하나씩 차근차근 생각해보자.
형식검사
람다가 사용되는 콘텍스트를 이용해서 람다의 형식을 추론할 수 있다. 어떤 콘텍스트에서 기대되는 람다 표현식의 형식을 대상 형식이라고 부른다. 아래의 예제를 가지고 단계별로 살펴보자.
List<Apple> heavierThan150g =
filter(inventory, (Apple apple) -> apple.getWeight() > 150);
- filter 메서드의 선언을 확인 →
filter(List<Apple> inventoty, Predicate<Apple> p); - filter 메서드가 두번째 파라미터로 Predicate 형식을 기대한다.
- Predicate은 test라는 한 개의 추상 메서드를 정의하는 함수형 인터페이스다.
- test 메서드는 Apple을 받아 boolean을 반환하는 함수 디스크립터를 묘사한다.
- filter 메서드로 전달된 인수는 이와 같은 요구사항을 만족해야 한다.
이러한 단계로 형식을 검사한다.
또한 대상 형식이라는 특징 때문에 같은 람다 표현식이더라도 추상 메서드를 가진 다른 함수형 인터페이스로 사용될 수 있다. 밑의 예제를 보면 이해할 것이다.
Comparator<Apple> c1 =
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
ToIntBitFunction<Apple, Apple> c2 =
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
BiFunction<Apple, Apple, Integer> c3 =
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
형식 검사에 대해 알아봤고, 이제는 어떻게 형식을 추론할 것인가에 대해 알아보자.
형식 추론
우리 코드를 좀 더 단순화하면 어떻게 될까? 자바 컴파일러는 람다표현식이 사용된 콘텍스트(대상 형식)를 이용해서 람다 표현식과 관련된 함수형 인터페이스를 추론한다. 즉, 대상 형식을 이용해서 함수 디스크립터를 알 수 있으므로 컴파일러는 람다의 시그니처도 추론할 수 있다 !
이 것은 다음 예제와 같은 코드를 만들 수 있다.
// 파라미터 a의 형식을 명시적으로 지정하지 않았다.
List<Apple> greenApples =
filter(inventory, apple -> GREEN.equals(apple.getColor()));
Comparator<Apple> c1 =
(a1, a2) -> a1.getWeight().compareTo(a2.getWeight());
이렇게 형식을 명시적으로 지정하지 않아도, 컴파일러가 람다 파라미터 형식을 추론할 수 있다. 이 기능을 활용하면 코드의 수를 줄일 수도 있다.
하지만, 어떤 상황에서는 명시적인게 좋을 때가 있다. 개인적으로는 처음 코드를 보는 사람도 이해할 수 있는 코드가 좋다고 생각해 명시적으로 써주는 게 좋다고 생각 하지만, 어떤 상황에는 형식을 배제하는 것이 좋을 때가 있다. 본인이 판단하고 사용하자 !
지역 변수의 사용
지금까지 예제로 본 람다 표현식은 인수를 자신의 바디 안에서만 사용했다. 하지만 람다 표현식은 익명 함수처럼 자유 변수(파라미터가 아닌 외부에서 정의된 변수)를 활용할 수 있다. 이와 같은 동작을 람다 캡처링이라고 부른다. 예제를 보자.
int portNumber = 1337;
Runnable r = () -> System.out.println(portNumber);
하지만 자유 변수를 사용할 때 제약이 있다. 람다 표현식은 인스턴스 변수와 정적 변수를 자유롭게 캡처할 수 있다. 하지만 지역 변수는 명시적으로 final로 선언되어 있어야 하거나 실질적으로 final로 선언된 변수와 똑같이 사용되야 한다. 즉, 한 번만 할당할 수 있는 지역 변수를 캡처할 수 있다.
왜 지역 변수만 이런 제약이 있는걸까? 그리고 왜 인스턴스 변수는 자유롭게 캡처가 가능한 것일까? 개인적으로 가장 어려운 내용이였다. 거의 이 주제 하나만으로 하나의 포스팅이 나올 분량이였다. 책으로만 보고 차근차근 이해하면서 보지 않았을 때는 이해가 안되는 부분이 조금 많았다. 지금부터 차근차근 하나 하나씩 이해하며 살펴보자.
⭐️지역 변수의 제약(Final or Effectively Final 제약)
우선 지역 변수에 대해 알아보자.
지역 변수는 메서드나 블록 내에 선언된 변수로서, 해당 메서드나 블록이 실행될 때 생성되고 메서드나 블록이 종료될 때 소멸된다. JVM 메모리 구조에 Stack 영역에 위치한다.
이제 지역 변수의 제약을 알아보자.책에서는 아래와 같이 지역 변수 제약에 대해 설명한다.
람다를 생각해보면 람다에서 지역 변수에 바로 접근할 수 있다는 가정하에 람다가 스레드에서 실행된다면 변수를 할당한 스레드가 사려져서 변수 할당이 해제되었는데도 람다를 실행하는 스레드에서는 해당 변수에 접근하려 할 수 있다. 따라서, 자바 구현에서는 원래 변수에 접근을 허용하는 것이 아닌 자유 지역 변수의 복사본을 제공하는데, 복사본의 값이 바뀌지 않아야 하므로 지역 변수에는 한 번만 값을 할당해야 한다는 제약이 생긴 것이다.
- 『모던 자바 인 액션』, 113p
이게 무슨 소리일까? 풀어 설명하자면, 람다 표현식은 주로 멀티스레드 환경에서 사용된다. 이때 람다 표현식 내부에서 외부의 지역 변수를 참조하는 경우에 문제가 발생할 수 있다.
무슨 문제일까?
- 지역 변수는 Stack 영역에서 위치한다. Stack 영역은 각 스레드마다 별도로 할당되는 메모리 영역으로, 각 스레드마다 독립적으로 사용되기 때문에, 하나의 스레드는 다른 스레드로 접근 불가능하다. 아래의 그림을 참고하자.
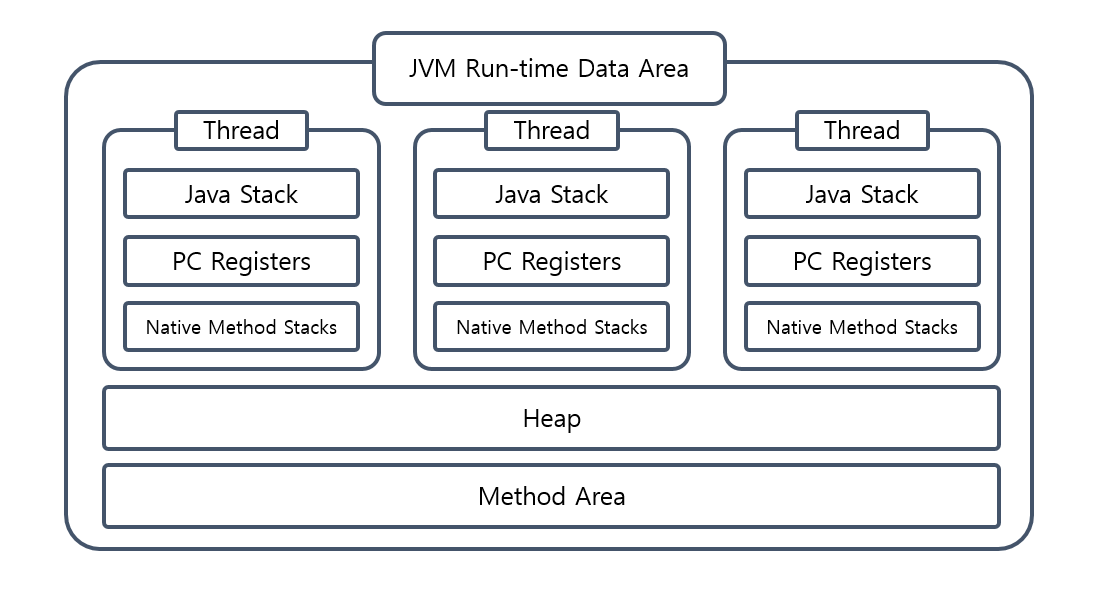
- 람다 스레드가 지역 변수에 바로 접근이 가능하다 가정해도 또 다른 새로운 문제가 발생한다. 람다가 스레드에서 실행된다면 변수를 할당한 스레드가 종료된 후 해당 스레드의 지역 변수로 접근하게 되는 경우에는? 그럼 접근 할 수 없을 것이다.
그렇다면, 이 두 문제를 어떻게 해결할까? 이를 해결하기 위해 자바에서는 람다 표현식에서 참조하는 외부 지역 변수의 복사본을 제공한다. 즉, 람다 스레드의 스택 영역에 복사해서 사용된다. 그래서 람다가 실행되는 스레드는 다른 스레드에 접근이 불가능한 문제를 해결하고, 만약 스레드에 접근할 수 있다 해도, 복사본을 사용하여 지역 변수를 가지고 있는 스레드가 종료되어도 상관없게 된다.
이게 도대체 복사본을 사용하는데 Final or Effectively Final 제약이 있어야 되는 이유랑 무슨 상관일까?
아래의 예제를 보면 쉽게 알 수 있다.
public void lambdaCaptureExample() {
int localValue = 5;
executor.execute(() -> {
while (localValue) {
// Do
}
});
localValue = 10;
}
자, 생각을 해보자. 람다의 스레드를 다루는 스레드와 localValue를 다루는 스레드가 다르다면? 람다로 전달되는 복사본의 값은 5가 될까 10이 될까?
답은 ‘매번 다르다’이다. 스레드별로 지역 변수가 공유 되지 않고 각 스레드의 실행 순서는 매번 실행할 때 마다 달라지는데, 앞서 말했듯 람다는 람다 스레드가 값을 참조하는 시점에 따라 5가 될 수도 있고, 10이 될 수도 있다. 매번 실행할 때마다 결과 값이 바뀌게 될 수 있다.
즉, 동기화 문제(sync)가 발생한다는 것이다. 그럼 동기화 하면 되지 않을까?
조금만 생각해보면 지역 변수를 스레드 간에 동기화해주는 것은 불가능하다는 것을 알 것이다.
왜냐면 앞서 설명 했듯이 지역 변수는 해당 변수를 선언한 메서드나 블록의 실행이 끝나면 스택 영역에서 제거된다. 따라서 다른 스레드와의 동기화를 위해서는 해당 변수가 메서드나 블록을 벗어난 후에도 유효하게 유지할 수 있어야 하는데, 하지만 지역 변수는 스레드의 실행이 끝나면 사라지기 때문에 동기화를 위한 접근이 불가능해진다.
따라서 이러한 문제를 해결하기 위해 자유 변수를 지역 변수로 하게 된다면, final 처럼 동작해야 된다는 것이다 !
그래서, final로 동작하기에 람다 내부에서 복사된 지역 변수 값을 변경할 수 없다 !
그렇다면 인스턴스 변수는 왜 괜찮은 걸까? 지역 변수와 인스턴스 변수는 태생부터 다르다. 인스턴스 변수는 클래스 내에 선언된 변수로서, 클래스의 객체가 생성될 때 함께 생성되고 해당 객체가 소멸할 때 함께 소멸한다. 인스턴스 변수는 JVM 메모리 구조에 Heap 영역에 위치한다.
람다에서 인스턴스 변수를 가져올 땐 스레드끼리 공유되는 힙 영역에서 접근해서 참조하기에 즉, 공유 영역에서 저장되어 있어서 모두가 접근해서 사용할 수 있다. 전역 변수도 마찬가지이다.
다만 멀티 스레드 환경에서는 sync를 맞춰주는 작업은 필요할 수 있다.
이렇게 지역 변수의 제약에 대해 알아봤다. 이번에는 특정 람다 표현식을 축약 할 수 있는 메서드 참조에 대해 간단하게 알아보자.
메서드 참조
// 기존 코드
inventory.sort((Apple a1, Apple a2) ->
a1.getWeight().compareTo(a2.getWeight()));
// 메서드 참조를 활용한 코드
inventory.sort(comparing(Apple::getWeight));
메서드 참조가 왜 중요할까? 메서드 참조는 특정 메서드만을 호출하는 람다의 축약형이라고 생각할 수 있다.
예를 들면 람다가 ‘이 메서드를 직접 호출해’라고 명령한다면 메서드를 어떻게 호출해야 하는지 참조하기보다는 메서드명을 직접 참조하는 것이 편리하다. 이때 명시적으로 메서드명을 참조함으로써 가독성을 높일 수 있다. 메서드 참조는 메서드명 앞에 구분자(::)를 붙이는 방식으로 활용할 수 있다.
메서드 참조를 만드는 방법
아래의 세가지 방법이 있다.
- 정적 메서드 참조
예를 들어 Integer의 parseInt 메서드는Integer::parseInt로 표현할 수 있다. - 다양한 형식의 인스턴스 메서드 참조
예를 들어 String의 length 메서드는String::length로 표현할 수 있다. - 기존 객체의 인스턴스 메서드 참조
예를 들어 Transaction 객체를 할당받은 expensiveTransaction 지역 변수가 있고, Transaction 객체에는 getValue 메서드가 있다면, 이를expensiveTransaction::getValue라고 표현할 수 있다. 비공개 헬퍼 메서드를 정의한 상황에서 유용하다.
이제 활용 예제를 보자!
//2번째 방법 활용
(String s) → s.toUpperCase() ⇒ String::toUpperCase
//3번째 방법 활용(비공개 헬퍼 메서드의 활용)
private boolean is ValidName(String string) {
return Character.isUpperCase(string.charAt(0));
}
filter(words, this::isValidName)
// 예제: 세 가지 종류의 람다 표현식을 메서드 참조로 바꾸는 방법
//1. 정적 메서드 참조
(args) -> ClassName.staticMethod(args)
ClassName::staticMethod
//2. 인스턴스 메서드 참조(arg0은 ClassName 형식)
(arg0, rest) -> arg0.instanceMethod(rest)
ClassName::instanceMethod
//3. 기존 객체의 인스턴스 메서드 참조
(args) -> expr.instanceMethod(args)
expr::instanceMethod
// 예제: 대소문자 무시하고 정렬하기
List<String> str = Arrays.asList("a", "b", "A", "B");
str.sort(String::compareToIgnoreCase);
메서드 참조는 람다 표현식의 형식을 검사하던 방식과 비슷한 과정으로 메서드 참조가 함수형 인터페이스와 호환하는지 확인한다. 즉, 메서드 참조는 콘텍스트의 형식과 일치해야 한다.
생성자 참조
위에서는 기존 메서드의 구현을 재활용해서 메서드 참조를 만드는 방법을 살펴봤다. 이젠 new 키워드를 이용해서 기존 생성자의 참조를 만들 수 있다. 이전 정적 메서드의 참조를 만드는 방법과 비슷하다.
예제 코드를 살펴보자.
//예제 1
Supplier<Apple> c1 = () -> new Apple();
Apple a1 = c1.get();
Supplier<Apple> c1 = Apple::new;
Apple a1 = c1.get(); <- Supplier의 get 메서드를 호출해서 새로운 Apple 객체를 만듦
//예제 2
Function<Integer, Apple> c2 = (weight) -> new Apple(weight);
Apple a1 = c2.apply(100); -> Integer를 인수로 갖는 Apple 객체를 만들어서 반환한다.
Function<Integer, Apple> c2 = Apple::new;
Apple a1 = c2.apply(100);
//예제 3: 두개의 인수를 갖는 생성자
BiFunction<Color, Integer, Apple> c3 =
(color, weight) -> new Apple(color, weight);
Apple a3 = c3.apply(GREEN, 110);
BiFunction<Color, Integer, Apple> c3 = Apple::new;
Apple a3 = c3.apply(GREEN, 110);
예제 코드를 보면 쉽게 이해할 수 있을 것이다. 이제 지금까지 배운 모든 내용을 활용해보는 시간이다 !
람다, 메서드 참조 활용하기
처음에 다룬 사과 리스트를 다양한 정렬 기법으로 정렬하는 문제를 지금까지 배운 내용으로 단계별로 만들어 보자!
1단계 : 코드 전달
자바 8의 List API에서 제공하는 sort를 이용해 정렬하는데, 어떻게 정렬 전략을 전달할까? 일단 sort 메서드의 시그니처를 보자.
void sort(Comparator<? super E> c)
이 코드는 Comparator 객체를 인수로 받아 두 사과를 비교한다. 객체 안에 동작을 포함하는 방식으로 동작 파라미터화가 되어있다 ! 따라서 1단계 코드를 완성해보자.
public class AppleComparator implements Comparator<Apple> {
public int compare(Apple a1, Apple a2) {
return a1.getWeight().compareTo(a2.getWeight());
}
}
inventory.sort(new AppleComparator());
2단계 : 익명 클래스 사용
한 번만 사용할 Comparator이기에 익명 클래스를 이용해 만들어보자.
inventory.sort(new Comparator<Apple> {
public int compare(Apple a1, Apple a2) {
return a1.getWeight().compareTo(a2.getWeight());
}
});
3단계 : 람다 표현식 사용
람다 표현식을 이용해서 코드를 전달해보자. Comparator는 함수형 인터페이스이다(추상 메서드가 compare 하나 뿐이기 때문에). Comparator의 함수 디스크립터(추상 메서드의 시그니처)는 (T, T) → int다. 코드를 개선해보자.
inventory.sort((Apple a1, Apple a2) ->
a1.getWeight().compare(a2.getWeight));
자바 컴파일러는 람다 표현식이 사용된 콘텍스트를 활용해서 람다의 파라미터 형식을 추론할 수 있기 때문에 더 줄여보자.
inventory.sort((a1, a2) -> a1.getWeight().compare(a2.getWeight));
Comparator는 Comparable 키를 추출해서 Comparator 객체로 만드는 Function 함수를 인수로 받는 정적 메서드 comparing을 포함한다. 가독성을 위해서 이를 활용해보자.
Comparator<Apple> c = Comparator.comparing((Apple a) -> a.getWeight());
import static java.util.Comparator.comparing;
inventory.sort(comparing(apple -> apple.getWeight()));
4단계 : 메서드 참조 사용
메서드 참조를 이용해서 더 깔끔하게 전달해보자!
import static java.util.Comparator.comparing;
inventory.sort(comparing(Apple::getWeight));
앞서 배운 내용들을 활용해 이렇게 간결하게 코드를 바꿔졌다.
알게 된 점
- 람다란 무엇인지
- 함수형 인터페이스가 도대체 무엇인지, 람다에 어떻게 활용되는지
- 람다의 활용과 함수형 인터페이스의 대표적인 인터페이스가 무엇인지
- 람다의 형식 검사와 추론, 그리고 어떤 제약이 있는지 내부 원리
- 지역 변수의 제약이 왜 있는지
- JVM의 메모리 구조, 지역 변수, 인스턴스 변수, 클래스 변수
- 스레드
- 동기화
- 메서드 참조
늘 그렇듯, 처음 읽었을 때는 이해가 되지 않았지만, 곱씹어 읽어볼 수록 이해가 되었다. 이번 람다의 내용은 어떤 내용보다 이해가 오래 걸렸던 것 같다. 특히 지역 변수의 제약 부분에서는 정말 오랜 시간이 걸렸다.
책으로는 약 1페이지 정도 밖에 되지 않은 내용이였지만, JVM 메모리 부터 스레드까지 중요한 많은 기초 자바 지식이 있었기 때문에, 오랜만에 복습하면서 이해하도록 노력하면서 실제 JVM과 스레드가 람다의 지역 변수 제약에서 어떤 원리로 작동하는지 예전보단 깊게 알게 된 것같다. 역시 내용을 그대로 받아들이기 보단 실전 예제로 어떻게 쓰이는지 보는 것이 더욱 깊은 이해를 돕는 것 같다. 덕분에 내가 기록했던 어떤 글 중에서 가장 오랜 시간이 걸린 글이 아닐까 싶다.
그리고, 확실히 모르고 무작정 썼던 람다가 알고 나니 이런 깊은 내용이 있었다는 사실을 알게 되어 충격이였다. 가독성이 좋지만 사용하기 어려웠던 람다는 역시 속 내용도 어려웠다. 그래도 이제 람다에 대해 조금 이해하게 된 것 같다 !
이제 파트 1이 끝났는데 깊이 있는 학습을 지향해야 한다는 사실을 뼈저리게 깨닫게 되었다! 깊이 있는 추구하는 사람이 되자!
