Hash(Hash function)?

해시는 해시 함수를 줄여 부르는 말이며, 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수 입니다.
해시 함수에 의해 얻어지는 값
- 해시 값
- 해시 코드
- 해시 체크섬
등이 있으며 간단하게 해시 라고 합니다.
용도
해시 테이블이라는 자료구조에 사용되며, 빠른 데이터 검색을 위한 컴퓨터 소프트웨어에 널리 사용됩니다.
특징
- 무결성
해시는 특정한 데이터를 이를 상징하는 더 짧은 길이의 데이터로 변환하는 행위를 의미합니다.
여기서 상징 데이터는 원래의 데이터가 조금만 달라져도 확연하게 달라지는 특성을 가지고 있어 무결성을 지키는 데에 많은 도움을 줍니다.
ex) 'A'라는 문자열의 해시와 'B'라는 문자열의 해시는 고작 한 알파벳이 다를뿐이지만 해시 결과값은 완전히 다른 문자열이 나오게 됨 - 보안성
기본적으로 복호화가 불가능합니다.
따라서 동일한 출력 값을 만들어낼 수 있는 입력 값의 가짓수는 수학적으로 무한개가 되어 보안성이 높습니다. - 비둘기집 원리
대부분의 해시 알고리즘들은 항상 고정된 길이의 결과 문자열을 반환한다는 특징이 있습니다. 하지만 아무리 큰 숫자라도 무한은 아니라는 점에서 특정한 두 값의 결과 해시 값이 동일한 경우가 발생할 수 있습니다.
쉽게 말하자면, 둘기가 5마리일때 상자가 4개밖에 존재하지 않는다면 아무리 비둘기를 균등하게 분배해도 최소한 한 상자에는 2마리의 비둘기가 들어가게 되듯 이러한 비둘기집 원리에 따라 해시에서는 '서로 다른 입력 값의 해시 결과 값이 동일한 문제' 즉, 해시 충돌이 발생할 여지가 있습니다.
- 해시레이트
연산 처리 능력을 측정하는 단위로 해시 속도를 의미합니다.
Hash Table
해시함수를 사용해서 변환한 값을 index로 삼아 key와 value를 저장하는 자료구조
즉, 해시 테이블은 어떤 특정 값을 받아서 해시 함수에 입력하고, 함수의 출력값을 인덱스로 삼아 데이터를 저장합니다.
ex) python - dictionary, ruby - Hash, Java - Map
특징
- 기본 연산으로 insert, delete, select가 있음
- 순차적으로 데이터를 저장하지 않음
- 키를 통해서 value를 얻을 수 있음 → 이진탐색트리나 배열에 비해서 속도가 획기적으로 빠름
- 커다란 데이터를 해시해서 짧은 길이로 축약할 수 있기 때문에 데이터를 비교할 때 효율적임
- value는 중복 가능하지만 key는 유니크해야 함
- 수정 가능함
- 보동 배열로 미리 hash table 사이즈만큼 생성 후 사용
해시 테이블은 key-value가 1:1 매핑되어 있기 때문에 검색, 삽입, 삭제 과정에서 모두 평균적으로 O(1)의 시간복잡도**를 가짐
** 공간 복잡도의 경우 O(N)이며 N은 키의 개수
종류
- Direct Address Table
가장 간단한 형태의 해시 테이블로 키값을 주소로 사용하는 테이블을 말합니다.
키값이 100이라고 했을 때 배열의 인덱스 100에 원하는 데이터를 저장합니다.
특징
- 최대 키 값에 대해 알고 있어야 함
- 최대 키 값이 작을 때 실용적으로 사용할 수 있음
- 키 값들이 골고루 분포되어있지 않다면 메모리 낭비가 심할 수 있음
- Hash Table
해시 함수를 사용하여 특정 해시값을 알아내고 그 해시값을 인덱스로 변환하여 키 값과 데이터를 저장하는 자료구조 입니다. 보통 알고 있는 해시 테이블을 얘기하며, ‘충돌’문제를 가지고 있습니다.
충돌을 최대한으로 줄여 연산속도를 빠르게 하는 것이 해시 테이블의 핵심이며, 이에 중요하게 작용하는 것이 바로 해시함수를 구현하는 해시 알고리즘 입니다.
충돌 완화 방법
- 해시 테이블의 구조 개선
- 해시 함수 개선
해결 1 : 해시 테이블의 구조 개선
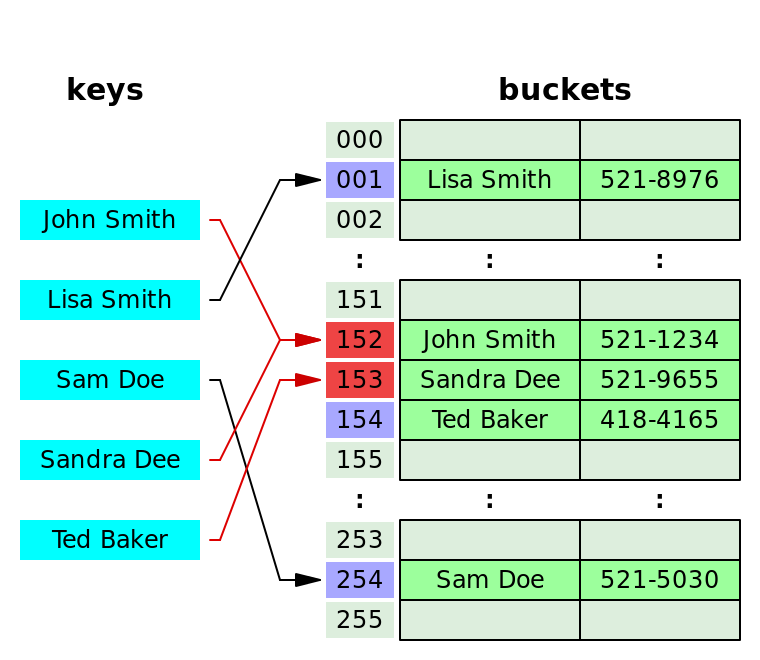
Chaining
충돌 발생 시 동일한 버킷에 저장하며, 이를 연결 리스트 형태로 저장하는 방법을 말합니다.
그림을 보면 John과 Shndra의 인덱스가 152로 충돌하게 됩니다. 이때 Sandra를 John 뒤에 연결함으로 충돌을 처리하게 됩니다.
chaning의 시간 복잡도
- 삽입 : O(1)
- 탐색, 삭제(최악의 경우) : O(K) (이때 K는 키값의 개수)
- 적재율을 이용해서 평균으로 표현(일반적임) : O(α+1)
Open Addressing
원래라면 해시함수로 얻은 해시값에 따라서 데이터와 키값을 저장하지만 동일한 주소에 다른 데이터가 있을 경우 다른 주소도 이용할 수 있게 하는 기법입니다.
앞에서 봤던 체이싱과 달리 동일한 충돌에 대해서 체이닝 방식을 적용하지 않고 다음으로 비어있는 주소에 저장하는 모습입니다.
이러한 원리로 탐색, 삽입, 삭제가 이루어지는데 다음과 같이 동작하게 됩니다.
- 삽입 : 계산한 해시 값에 대한 인덱스가 이미 차있는 경우 다음 인덱스로 이동하면서 비어있는 곳에 저장
이렇게 비어있는 자리를 탐색하는 것을 탐사(Probing)라고 함 - 탐색 : 계산한 해시 값에 대한 인덱스부터 검사하며 탐사를 해나가는데 이 때 “삭제” 표시가 있는 부분은 지나감
- 삭제 : 탐색을 통해 해당 값을 찾고 삭제한 뒤 “삭제” 표시를 함
이런 Open Addressing은 3가지 방법을 통해 해시 충돌을 처리합니다.
- 선형탐사 : 바로 인접한 인덱스에 데이터를 삽입해가기 때문에 데이터가 밀집되는 클러스터링 문제가 발생하고 이로인해 탐색과 삭제가 느려지게 됨
- 제곱 탐사 : 선형탐사에 비해 더 폭넓게 탐사하기 때문에 탐색과 삭제에 효율적일 수 있다. 하지만 이는 초기 해시값이 같을 경우에 역시나 클러스터링 문제가 발생하게 됨
- 이중 해싱 : 선형탐사와 제곱탐사에서 발생하는 클러스터링 문제를 모두 피하기 위해 도입된 것
처음 해시함수로는 해시값을 찾기 위해 사용하고 두번째 해시함수는 충돌이 발생했을 때 탐사폭을 계산하기 위해 사용되는 방식
해결 2 : 해시 함수 개선
나눗셈법(Division Method)
아주 간단하게 해시값을 구하는 방법으로 미리 해시 테이블의 크기인 N을 아는 경우에 사용할 수 있습니다. 해시함수를 적용하고자 하는 값을 N으로 나눈 나머지를 해시값으로 사용하는 방법입니다.
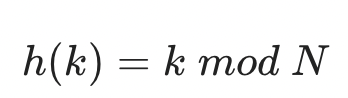
여기서 NN 은 2의 제곱꼴을 사용하면 안된다고 하는데 이는 그 제곱꼴이 로 나타날 때 k의 하위 p개의 비트를 고려하지 않기 때문에 N 은 소수(Prime Number)를 사용하는 것이 좋습니다
곱셈법(Multiplication Method)
0<A<1 인 A 에 대해서 다음과 같이 구할 수 있습니다
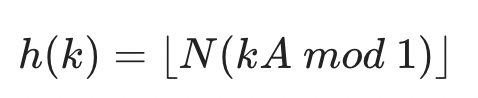
kA mod 1의 의미는 kA 의 소수점 이하 부분을 말하며 이를 N에 곱하므로 0부터 N 사이의 값이 됩니다.
이 방법의 장점은 N이 어떤 값이더라도 잘 동작한다는 것이며 A 를 잘 잡는 것이 중요합니다.
참고
