정규화?
데이터베이스의 데이터를 구성하는 기술
데이터 중복(반복) 및 삽입, 업데이트 및 삭제 이상과 같은 바람직하지 않은 특성을 제거하기 위해 테이블을 분해하는 체계적인 접근 방식입니다.
관계 테이블에서 중복 데이터를 제거하여 데이터를 테이블 형식으로 만드는 다단계 프로세스입니다.
크고, 제대로 조직되지 않은 테이블들과 관계를 재구성하여 잘 조직된 테이블과 관계들로 나누는 것을 포함합니다.
목적
- 중복(쓸모없는) 데이터 제거
- 데이터 종속성이 타당한지 검사 (데이터가 논리적으로 저장되게 됨)
제 1 정규형
- 각 컬럼이 하나의 속성만을 가져야 한다.
- 하나의 컬럼은 같은 종류나 타입(type)의 값을 가져야 한다.
- 각 컬럼이 유일한(unique) 이름을 가져야 한다.
- 칼럼의 순서가 상관없어야 한다.
예시

각 컬럼이 하나의 값(속성)만을 가져야 한다. -> 불만족, 하나의 칼럼(과목)에 두 개의 값을 가짐
하나의 컬럼은 같은 종류나 타입(type)의 값을 가져야 한다. -> 만족
각 컬럼이 유일한(unique) 이름을 가져야 한다. -> 만족
칼럼의 순서가 상관없어야 한다. -> 만족
변경
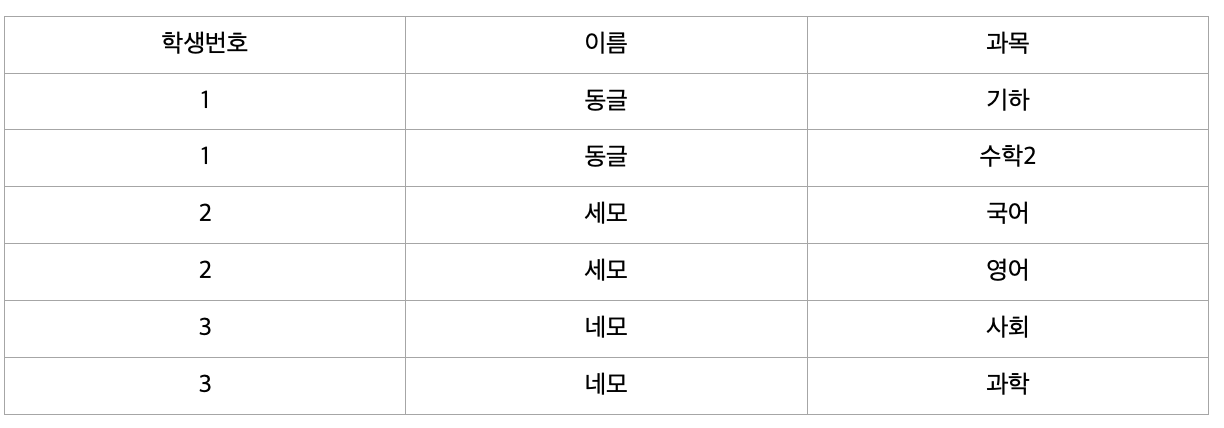
제 2 정규형
- 1정규형을 만족해야 한다.
- 모든 컬럼이 부분적 종속(Partial Dependency)이 없어야 한다. 즉, 모든 칼럼이 완전 함수 종속을 만족해야 한다.
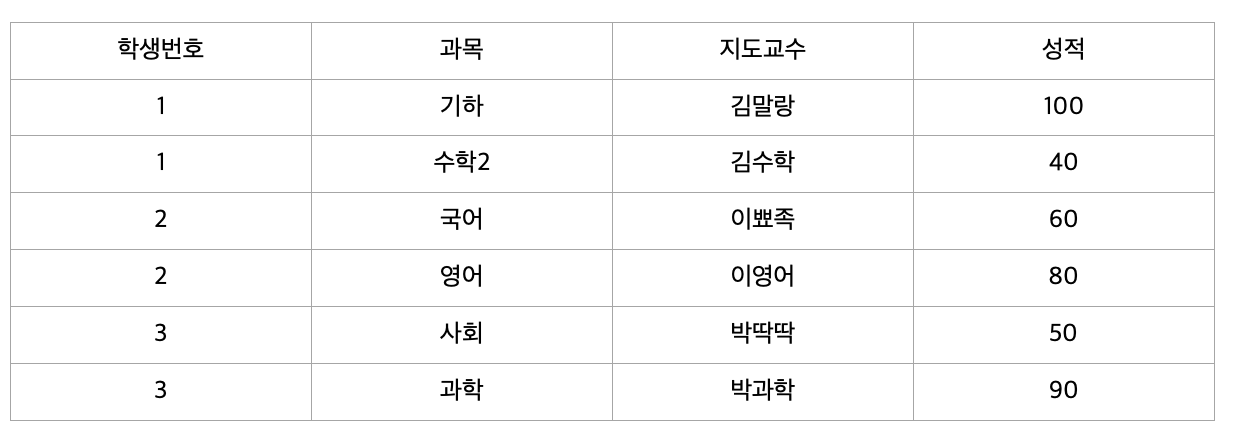
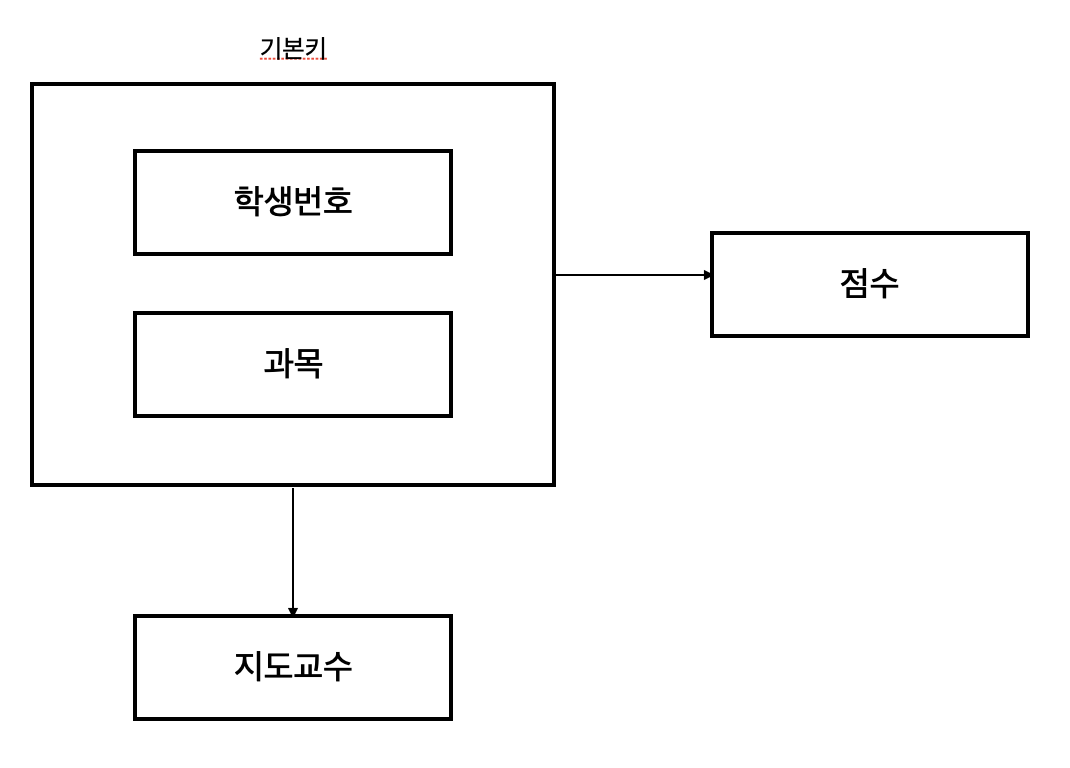
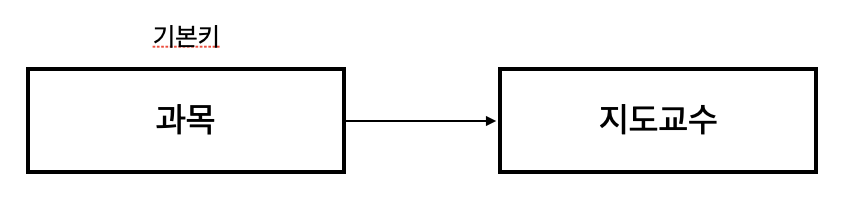
성적의 특정 값을 알기 위해서는 학생 번호+과목이 있어야 한다. (ex : 102번의 자바 성적 70 )
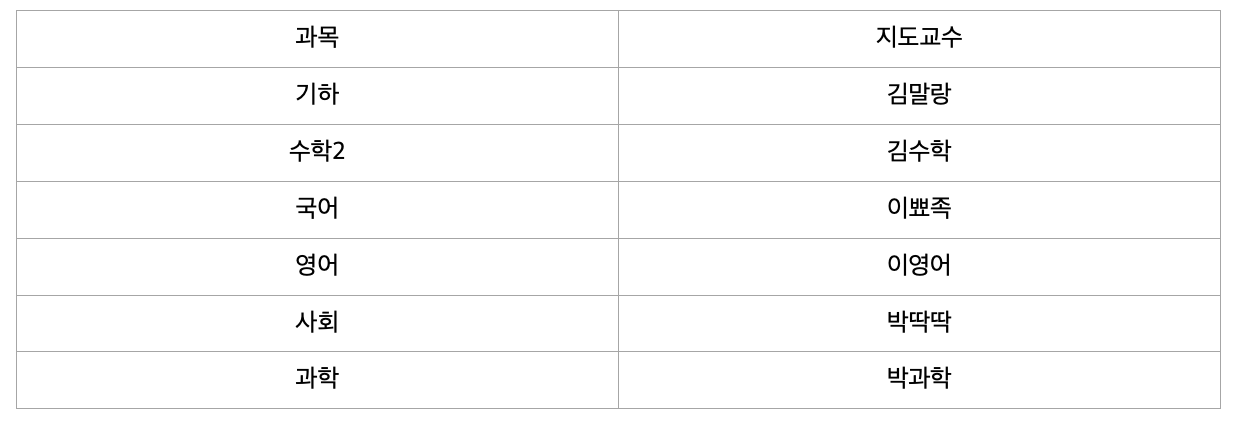
하지만 특정 과목의 지도교수는 과목명만 알면 지도교수가 누군지 알 수 있다. (ex : 자바의 지도교수 박자바)
위 테이블에서 기본키는 (학생 번호, 과목)으로 복합키 입니다.
그런데 이때 지도교수 칼럼은 (학생 번호, 과목)에 종속되지 않고 (과목) 에만 종속되는 부분적 종속입니다.
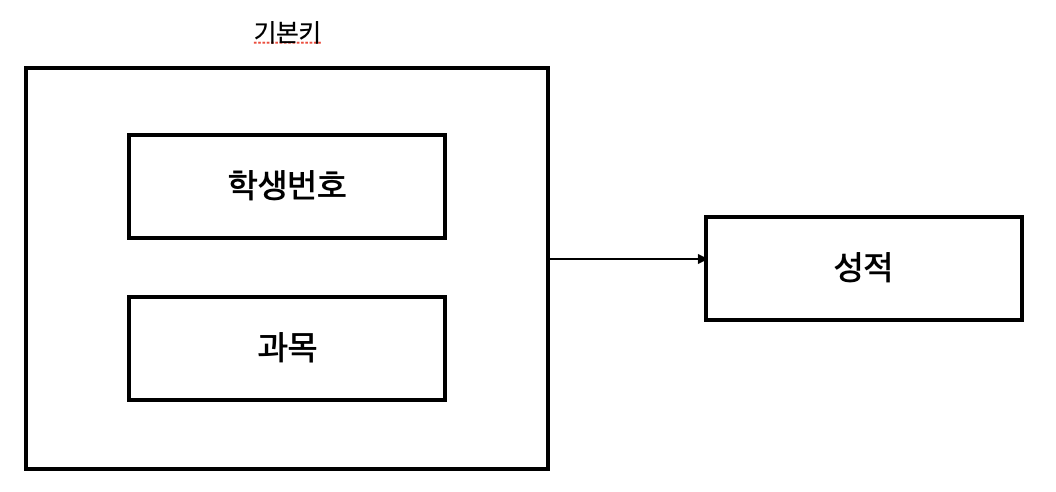
따라서 제2 정규화를 만족하지 않으므로 아래와 같이 분해해 주어야 합니다.
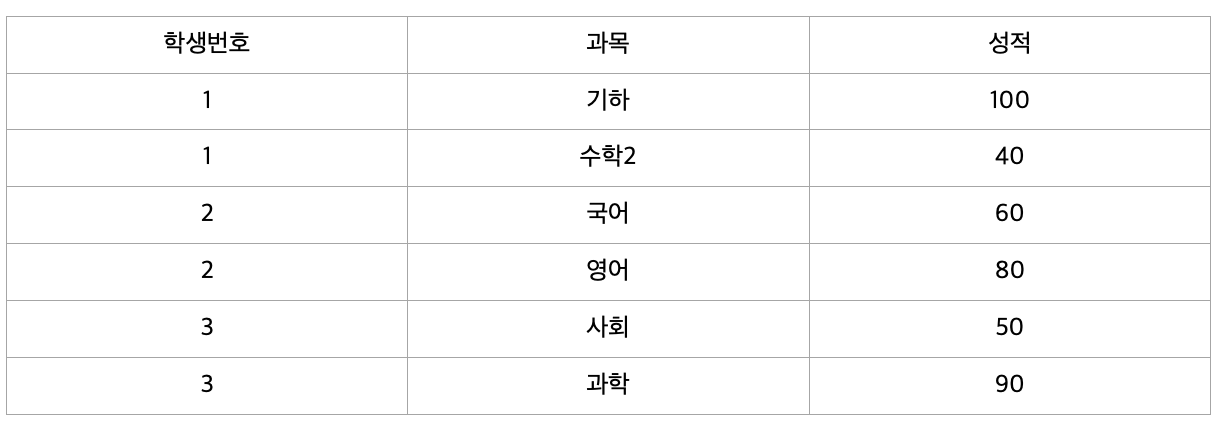
제 3 정규형
- 2 정규형을 만족해야 한다.
- 기본키를 제외한 속성들 간의 이행 종속성 (Transitive Dependency)이 없어야 한다.

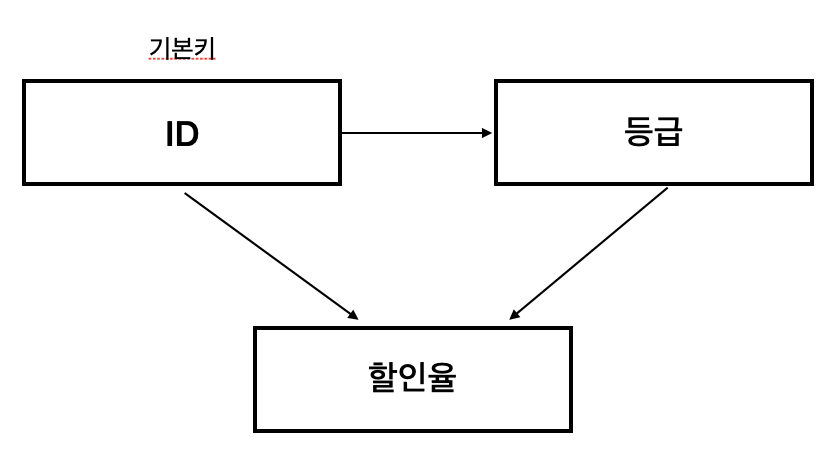
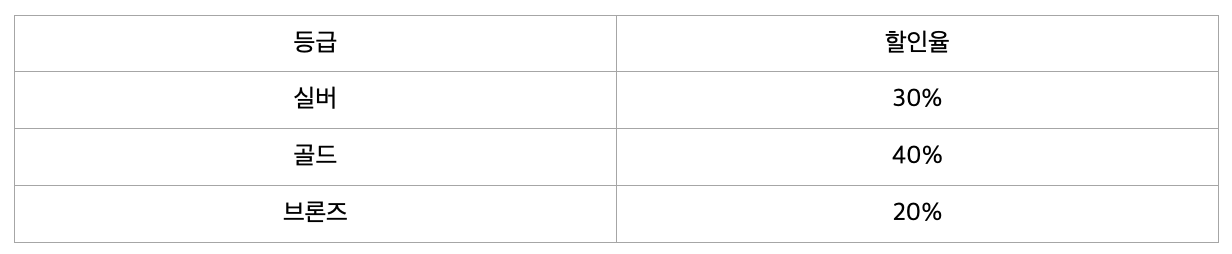
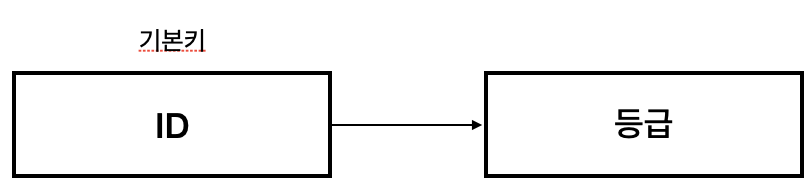
ID를 알면 등급을 알 수 있고, 등급을 알면 할인율을 알 수 있습니다. 따라서 ID를 알면 할인율을 알 수 있수 있기에 이행 종속성이 존재하므로 제 3 정규형을 만족하지 않습니다.
3정규형을 만족하기 위해서는 아래와 같이 분해해야 합니다.


참고
블로그
