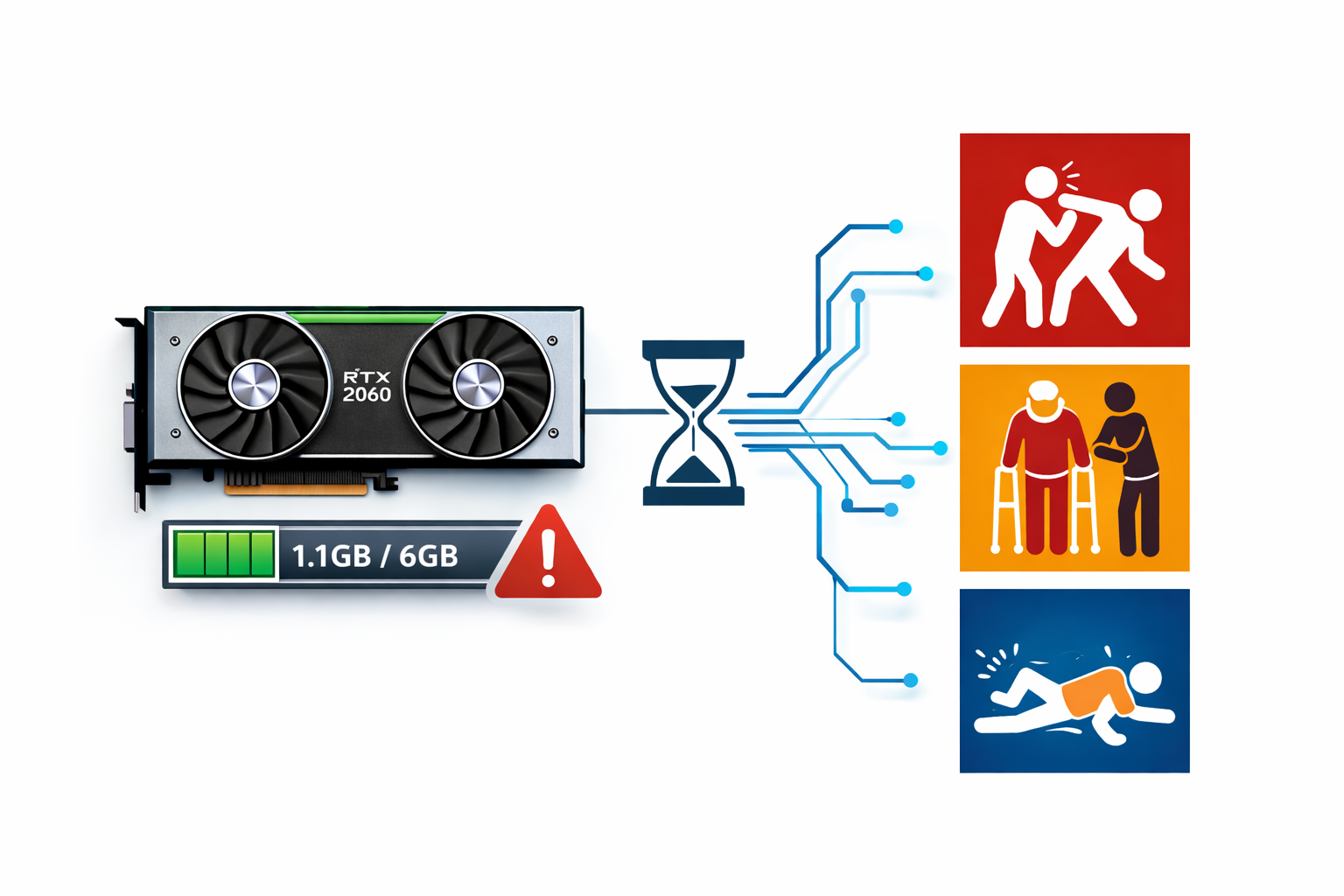
베이커리 키오스크 시스템을 구축하는 중에 3개의 AI 모델(폭행 감지, 이동약자 지원, 낙상 감지)을 6GB GPU 메모리 내에서 동시에 돌려야 하는 상황이 생겼습니다.
이 글에선 그 중 폭행 감지 모델을 어떻게 설계하고 최적화했는지 공유합니다.
1. 시스템 제약 조건
요구사항
목표: 베이커리에서 실시간 폭행 감지
- 모든 이벤트 로깅
- GPU: RTX 2060 (6GB VRAM)
- 30fps 유지 필요
- AI의 역할: 폭행 여부만 판정GPU 메모리 배분
GPU 메모리 6GB가 우리가 가진 전부였습니다. 3개 모델을 동시에 돌려야 하니까:
YOLOv8 Pose (낙상 감지): 최대 500MB
YOLOv8 Detection (보조기구): 최대 500MB
분류 모델 (폭행 판정): 100MB
─────────────────────────
총 1.1GB
남은 4.9GB로 다른 시스템을 감당할 수 있겠다고 봤습니다.
속도 계산
실시간 처리를 위해 속도도 확인했습니다:
YOLOv8 Pose: 최대 33ms/프레임
YOLOv8 Detection: 최대 30ms/프레임
분류 모델: 최대 1.5ms/프레임
전처리/후처리: 5ms/프레임
─────────────────────
최대 70ms/프레임→ 30fps 달성 가능
2. 분류 모델 선택
분류 모델 선택 기준은:
1. 정확도 80% 이상
2. 메모리 최소화
3. 과적합 최소화
후보를 비교해봤습니다:
| 모델 | 정확도 | 메모리 | 특징 |
|---|---|---|---|
| SVM | 60~82% | 가장 높음 | - |
| XGBoost | 87~98% | 39.7MB | 과적합 위험 높음 |
| RF | 80.8~89.5% | 23.8MB | 안정적 |
선택: XGBoost + Random Forest의 soft voting
이유는 두 모델의 약점을 서로 보완할 수 있기 때문입니다:
- XGBoost의 높은 정확도 + RF의 안정성
- 메모리: 약 63.5MB (충분)
- 예상 정확도: 82~85% (목표 80% 충분)
3. 학습 결과
초기 성능
훈련 정확도: 99.90%
테스트 정확도: 83.30%
과적합 차이: 16.60% ← 심각함Confusion Matrix:
| 실제 \ 예측 | 비폭행 | 폭행 |
|---|---|---|
| 비폭행 | 202 (TN) | 39 (FN) |
| 폭행 | 68 (FP) | 265 (TP) |
문제: 과적합
과적합을 해결하려면 보통은:
- 더 큰 모델 사용 (메모리 초과)
- 모델 추가 (리소스 초과)
- 더 많은 데이터 수집 (시간 부족)
이 모든 게 불가능했습니다. 메모리가 6GB로 정해져 있으니까요.
그 대신 정규화를 강화했습니다.
정규화 강화
# Before
xgb_model = xgb.XGBClassifier(
n_estimators=200,
max_depth=10,
learning_rate=0.1
)
# After
xgb_model = xgb.XGBClassifier(
n_estimators=100, # 연산량 감소
max_depth=8, # 트리 깊이 제한
learning_rate=0.05, # 느린 학습 (안정화)
reg_lambda=1.0, # L2 정규화 추가
reg_alpha=0.5, # L1 정규화 추가
)
rf_model = RandomForestClassifier(
n_estimators=100, # 200 → 100
max_depth=12, # 20 → 12
min_samples_split=10, # 5 → 10
min_samples_leaf=5, # 2 → 5
)결과
훈련 정확도: 99.90% → 90.49%
테스트 정확도: 83.30% → 81.36%
과적합 차이: 16.60% → 9.13% ✅
4. 거짓 경보(FP) 감소
테스트 정확도는 81.36%인데, 거짓 경보가 68개나 됩니다.
AI 모델을 더 개선해보려 했습니다:
- 하이퍼파라미터 조정 → FP: 68 (변화 없음)
- 정규화 강화 → FP: 68 (변화 없음)
- 데이터 리샘플링 → FP: 65 (3개만 감소)
모델 자체의 한계인 것 같았습니다.
해결책: 임계값 조정
AI는 "폭행일 확률"을 주고, 시스템에서 "임계값"을 결정하는 방식으로 바꿨습니다:
prediction = model.predict_proba(features)
# → [비폭행_확률, 폭행_확률]
CONFIDENCE_THRESHOLD = 0.55 # 조정 가능
if prediction_prob >= CONFIDENCE_THRESHOLD:
alert_level = "VIOLENCE"
elif 0.45 <= prediction_prob < 0.55:
alert_level = "SUSPICIOUS"
else:
alert_level = "NORMAL"임계값별 성능
임계값 0.50: FP 68개, Recall 87%
임계값 0.55: FP 50개, Recall 85% ← 선택
임계값 0.60: FP 40개, Recall 83%
임계값 0.65: FP 30개, Recall 80%0.55로 설정한 이유:
- FP 26% 감소 (68 → 50)
- Recall은 충분 (85%)
- 시스템 안정성 확보
최종 성능
정확도: 81.36%
Precision: 79.58%
Recall: 87.17% (폭행 놓칠 확률 낮음)
ROC-AUC: 0.8766
거짓 경보(FP): 50개/일
메모리 사용: ~1.1GB / 6GB (18%)
속도: 70ms/프레임 (30fps 달성)마치며
사실 수업으로 AI 모델 학습에 대해 배웠을 땐, AI 모델 학습에 큰 재미를 가지진 못했습니다.
"정확도를 높이기 위해 더 큰 모델을 쓴다" "데이터를 더 모은다" 이런 식의 접근은 그냥 단순해 보였거든요.
하지만 이 프로젝트에서는 달랐습니다.
"6GB 메모리, RTX 2060, 30fps, 3개 모델을 동시에"라는 제약이 주어졌을 때, 그 안에서 요구사항에 맞는 최적의 모델을 찾는 과정이 정말 재미있었습니다.
- "메모리가 없으니 XGBoost를 쓰자"
- "정확도를 더 높이고 싶지만, 과적합을 줄이는 게 현실적이겠다"
- "AI 모델은 한계네. 그럼 시스템 레벨에서 해결하자"
이렇게 현실과 타협하면서 최선을 찾아가는 과정 자체가 개발의 매력이라고 느꼈습니다.
출처
