이미지 구분 AI 만들기 2
이번 시간에는 저번 시간에 설명했던 모델을 직접 구현해보겠다.
먼저 이번 모델은 여러 입력이나 출력을 가지거나 복잡한 연결 구조가 아니므로 Sequential 모델을 사용하겠다.
model = tf.keras.Sequential([])그리고 노드를 쌓아 줄 건데, 이번 시간에는 3층으로 쌓아주겠다.
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax"),
])이번 시간에는 relu 활성화 함수를 사용했는데, relu 함수는 0 미만의 값들은 모두 0으로 리턴을 해준다.
우리는 이미지가 특정 카테고리일 확률을 구하는 모델을 만들 것이므로 음수는 필요하지 않아 relu 함수를 사용했다.
그리고 fashion mnist의 의상 카테고리는 총 10개이므로,
['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker','Bag','Ankle boot']마지막 레이어의 노드 수를 10개로 지정했다.
그런데 왜 이번 시간에는 저번 시간처럼 확률을 구하는 모델인데 sigmoid 함수가 아닌 softmax를 썼는지 궁금할 것이다.
그 이유로, sigmoid 함수는 하나의 확률을 구하면 나머지의 확률은 1 - (구한 확률)로 결정되어 이진 분류에서 간단하고 효율적이지만, softmax 함수는 모든 클래스에서의 확률을 0에서 1로 정규화하고 비교하여 가장 높은 확률을 선택한다. 따라서 이번 모델에서의 마지막 레이어는 softmax 활성화 함수를 채택했다.
model.compile( loss= "sparse_categorical_crossentropy", optimizer = "adam", metrics=['accuracy'])이번 모델의 손실 함수는 sparse_categorical_crossentropy 를 채택했는데, 그 이유로 의상 카테고리는 정수형으로 표현되기 때문이다. 간단하게, 우리는 10가지 카테고리에 해당되는 확률을 모두 계산한 다음 가장 확률이 높은 카테고리를 리턴해주는 모델을 원하는데, sparse_categorical_crossentropy 는 one-hot-encoding (어레이의 첫번째 인수가 정답이면 [1,0,0,0,..,0] 을 리턴)이 아닌 인덱스를 리턴해주어 채택하게 되었다.
이 상태로 우리가 만들 모델의 summary를 볼 수 있는데,
model.summary()를 입력하면 레이어의 출력 형태와 파라미터 개수를 출력해준다.
하지만, 우리가 입력한 상태로 출력하게 되면 에러가 발생하는데, 그 이유는 우리가 입력 데이터의 크기를 지정하지 않아서 가중치인 w값을 지정할 수 없기 때문이다.
따라서
tf.keras.layers.Dense(128,input_shape=(28,28) ,activation="relu")fashion_mnist 사진의 픽셀 값인 (28,28)을 입력해주면,
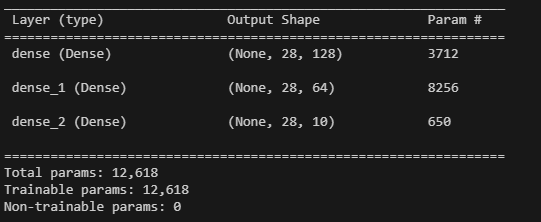
이런 식으로 summary가 프린트된다.
(여기서 parameter는 w값의 개수를 의미한다.)
하지만 여기서 또 문제가 있는데, 우리는 마지막 레이어에서 (28,10) 같은 2차원 결과값이 아닌 10개의 확률을 구해야 하므로 2차원 결과값을 1차원으로 압축을 시켜줘야 한다. 따라서 마지막 레이어 위에
tf.keras.layers.Flatten()를 입력해주면 2차원 행렬을 1차원으로 압축시켜 
이런 식으로 마지막 레이어의 결과값이 10개로 나오게 된다.
model.fit(trainX, trainY,epochs=10) 이제 학습을 시켜보면, 
정답률이 약 88% 정도로 나오게 된다.
예측값=model.predict(testX)
print(tf.argmax(예측값, axis=1).numpy()[:3])
plt.imshow(testX[0])
plt.show()
plt.imshow(testX[1])
plt.show()
plt.imshow(testX[2])
plt.show()이제 테스트 데이터들을 넣어 예측을 하게 되면,

각각 9, 2, 1이 나오게 되는데, 이는 Ankle boot, Pullover, Trouser이다.
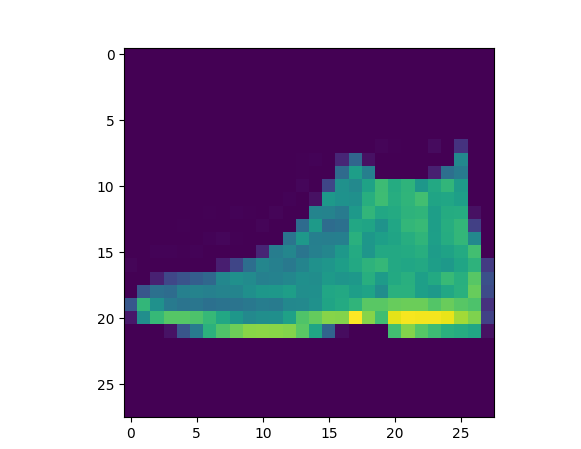
testX[0]
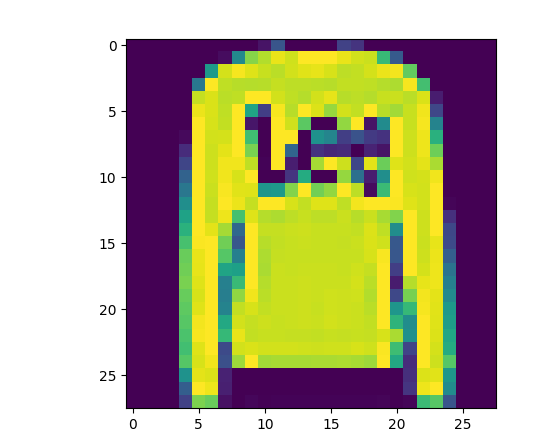
testX[1]
testX[2]
3개의 값만 봤을 때는 완전한 정확도로 의상들을 카테고리별로 구분하는 것을 알 수 있었다.
물론 정답률이 100%가 아니기에 모든 testX를 출력했을 때 오차는 어느정도 있을 수 있다.
다음 시간에는 flatten()의 안 좋은 점과 이미지 구분 AI의 정확도를 더욱 높이는 방법에 대해 포스팅하겠다.
