정확도 올리기 2
저번 시간에는 바로 flatten()을 쓰면 안 되는 이유와 그 문제점을 해결하기 위해 등장한 컨볼루셔널 레이어와 풀링 레이어에 대해 소개했었다.
이번 시간에는 전에 만들었던 옷 이미지를 카테고리별로 구분해주는 알고리즘의 정확도를 컨볼루셔널 레이어와 풀링 레이어를 사용하여 올리는 시간을 가져보겠다.
tf.keras.layers.Conv2D(32,(3,3), padding="same", activation='relu', input_shape=(28,28,1)),전에 만들었었던 덴스레이어 제일 위쪽에 컨볼루셔널 레이어를 넣어줬다.
차례대로, 32는 저번 시간 설명했던 이미지의 정보와 특징을 강조하여 만든 복사본 장수를 의미하고, 그 뒤 (3,3)은 kernel의 가로 세로 사이즈를 의미한다.
Padding은, kernel을 이미지가 지나게 되면 필연적으로 작아지는데 이를 다시 키워주는 역할을 한다.
활성화 함수는 사진에서 픽셀의 색상은 음수로 표현될 수 없기에 relu 활성화 함수를 사용했다.
그 다음으로, input_shape에서 28,28은 28X28 픽셀을 의미하고 1은 색상값을 의미한다. 우리는 흑백 사진을 사용하기에 R, G, B 값이 아닌 하나의 색상값만 필요하기에 1을 사용했다. 만약 우리가 컬러 사진을 썼다면 3을 넣어주면 되는 것이다.
그 다음으로는 풀링 레이어를 넣어보겠다.
tf.keras.layers.MaxPooling2D((2,2)),이는 학습한 이미지를 2X2 크기로 압축하여 중앙으로 정렬하게 해 준다.
컨볼루셔널 레이어와 풀링 레이어를 넣은 이후, flatten()을 넣어주는데, 어쨌든 결과값은 테스트 이미지가 어떤 클래스인지 인덱스를 1차원으로 반환해주어야 하기 때문에 flatten()을 써줘야 한다. 그 다음 우리가 전에 적어두었던 덴스레이어들을 넣어주면,
tf.keras.layers.Conv2D(32,(3,3), padding="same", activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(10,activation="softmax"),
모델의 노드들이 완성이 된다. 학습이 된 척도를 테스트 해보면서 컨볼루셔널 레이어와 풀링 레이어를 추가해도 된다.
그리고 데이터의 형태를 reshape 할 수 있는데, 바로 numpy를 이용하면 된다.
import numpy as np
trainX=trainX.reshape((trainX.shape[0],28,28,1))
testX=testX.reshape((testX.shape[0],28,28,1))이런 형식으로 코드를 입력하면 데이터의 형태를 조정할 수 있다.
그리고, 때에 따라서 사진 이미지 정보를 0에서 1로 압축하고 데이터 학습을 시켜야하는 상황이 생길 수 있는데, 이 때 쓰이는 것이
trainX = trainX / 255.0
testX = testX / 255.0이다.
그리고 모델을 평가하는 함수를 사용할 건데,
model.evaluate(testX, testY)이다. 이는 학습이 얼마나 잘 됐는지 평가를 해준다. 하지만, 여기서 짚고 넘어가야 할 게, 우리가 만약 evaluate 하는 항목에 trainX와 trainY를 넣는다면 알고리즘이 계속 테스트 값으로 학습했기에, 정확도가 높지 않음에도 테스트값에서는 정확도가 많이 나올 가능성이 있다. (테스트 값을 외우는 것) 따라서 evaluate할 데이터 값은 알고리즘이 처음 보는 데이터값인 testX와 testY를 넣어주는 것이 더 정확하다.
그런데, 이 evaluate 함수를 각 에포크 별로 학습이 끝나면 볼 수 없을까?
이 때는
model.fit(trainX,trainY,validation_data=(testX,testY) ,epochs=10) model.fit 안에 validation_data=()를 넣어주면 된다. 이러면 모든 에포크 별로 학습이 끝나면 loss와 accuracy를 출력해주게 된다.
그럼 이제 컨볼루셔널 레이어를 적용한 이 코드를 실행해보자.
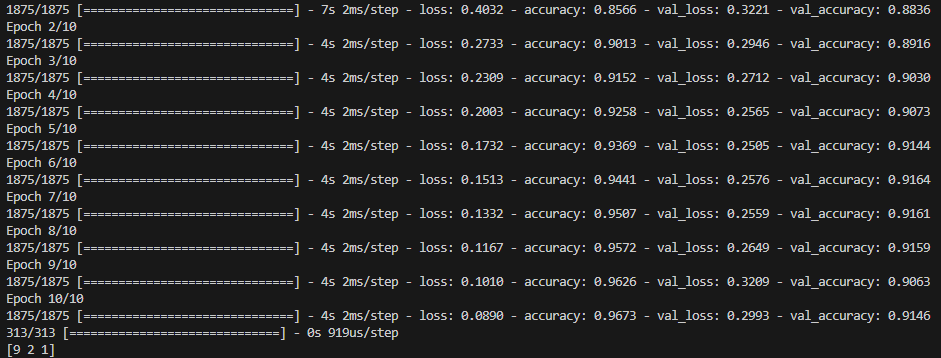
코드를 실행해보면 정답률이 거의 100% 가까운 수치인 걸 볼 수 있다. 저번 시간 정답률이 최대 88% 였던 걸 생각하면 굉장히 높게 정답률이 올라간 셈이다.
하지만, 트레이닝 데이터의 정답률은 100%에 가깝지만, val_accuracy는 91%대에 머물러 있다.
이는 overfitting이라고 하는데, 아까 말했듯이 모델이 학습용 데이터만 과도하게 학습을 해서 새로운 데이터에 비해서 트레이닝 데이터만 잘 구분을 해주는 것이다.
따라서 새로운 데이터를 넣어줬을 때 트레이닝 데이터 만큼의 퍼포먼스가 나오지 않게 되므로 좋은 모델이라고 할 수 없는 것이다. 이는 오버피팅이 언제 일어나는지 체크하고 이를 방지하기 위한 방법들을 도입하면 된다. 이는 학습하며 차차 방법을 설명하도록 하겠다.
다음 시간에는 미리 전처리 된 데이터를 가지고 구별 알고리즘을 구현하는 것이 아닌 전처리 되지 않은 생 데이터를 가지고 구분 알고리즘을 구현해보겠다.
