
에러 메세지
Exception: Failed to create Livy session for executing notebook. Error: HTTP status code: 400에러 내용
Synapse 파이프라인에서 노트북을 실행하려고 할 때 Livy 세션을 생성하지 못해서 발생한 오류이다.
Apache Livy는 Spark 노트북 실행을 관리하는 REST 인터페이스이므로 이 오류는 Livy와 Spark 풀 간의 연결 문제를 의미한다.
에러 원인
Synpase에서 사용하던 Spark의 버전(런타임)이 더 이상 지원되지 않아, 실행할 수 없는 상태가 되어 에러가 발생
그래서 Livy가 Spark 세션을 생성하려고 해도, 사용 가능한 Spark 환경이 없어서 실패하는 것이다. Synapse에서 Apache Spark를 실행하려면 반드시 지원되는 Spark 런타임이 필요하고, Livy는 이 Spark 풀에 연결해서 세션을 만들어야 한다.
그 외에도 아래와 같은 이유로 해당 에러가 발생할 수 있으며 이번 에러는 Case 3과 관련이 있다.
- Case 1. Spark 풀이 비활성화 상태이거나 오토스케일 설정으로 인해 동작하지 않는 경우
- Case 2. Saprk 풀의 노드 크기가 설정이 너무 작으면 실패할 수 있음
- Case 3. Synapse 파이프라인 내 노트북 Acitivy를 실행할 때 잘못된 Spark 풀을 선택했을 가능성
- 이번 에러에서는 단순히 사용자가 잘못된 Spark 풀을 선택한 것이 아니라, 사용하던 Spark 풀이 더 이상 유효하지 않게 된 것이 핵심 문제이다.
- Case 4. Livy 서비스가 내부적으로 Spark 풀과 통신하지 못하는 경우
에러와 연관된 개념
(1) Livy 세션
Livy(Session) = Spark 작업을 실행하기 위한 웹 API 기반 인터페이스
- Livy는 Apache Spark를 원격으로 실행하고 관리하는 RESTful 서비스
- Azure Synapse 에서는 Synapse Notebook 실행 시 Livy 를 사용하여 Spark 풀과 통신한다.
- 즉, Synapse 에서 파이프라인이 Spark 노트북을 실행하면 내부적으로 Livy가 Spark 풀과 연결되어 세션을 생성하고 실행을 관리한다.
(2) Spark 풀
Spark 풀은 Apache Spark가 실행될 클러스터 환경이다.
- Spark 풀은 특정한 버전의 Synapse Spark 런타임을 사용한다.
https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-version-support#supported-azure-synapse-runtime-releases - Azure가 특정 버전의 Spark 런타임을 더 이상 지원하지 않으면, 해당 Spark 풀을 사용할 수 없다.
(3) 드라이버 프로그램과 SparkContext
드라이버 프로그램은 Spark 세션을 생성하고 실행기(executors)를 할당하는 역할이다.
- Spark 세션을 만들려면 SparkContext가 필요한데, Spark 풀의 지원이 종료되면 이 과정이 중단된다.
해결 방법
Azure Portal 사용 시: 신규 Spark 풀 생성
| 작업 순서 | 시스템 | 작업 내용 |
|---|---|---|
| 1 | Spark 풀 | 버전 업그레이드 Spark 풀 생성 |
| 2 | Synapse 파이프라인 | 파이프라인 Spark 풀 변경 |
-
신규 Spark 풀 생성

-
신규 Spark 풀 생성 후, 기존 패키지 임포트 적용 & Apache Spark 구성 적용
powershell 사용 시: 기존 Spark 풀 버전 업그레이드
Azure Synapse 내의 powershell에서 Apache Spark Pool 버전 업그레이드 명령어 실행
Update-AzSynapseSparkPool -ResourceGroupName "YourResourceGroupName" -WorkspaceName "YourWorkspaceName" -Name "YourSparkPoolName" -SparkVersion "3.4"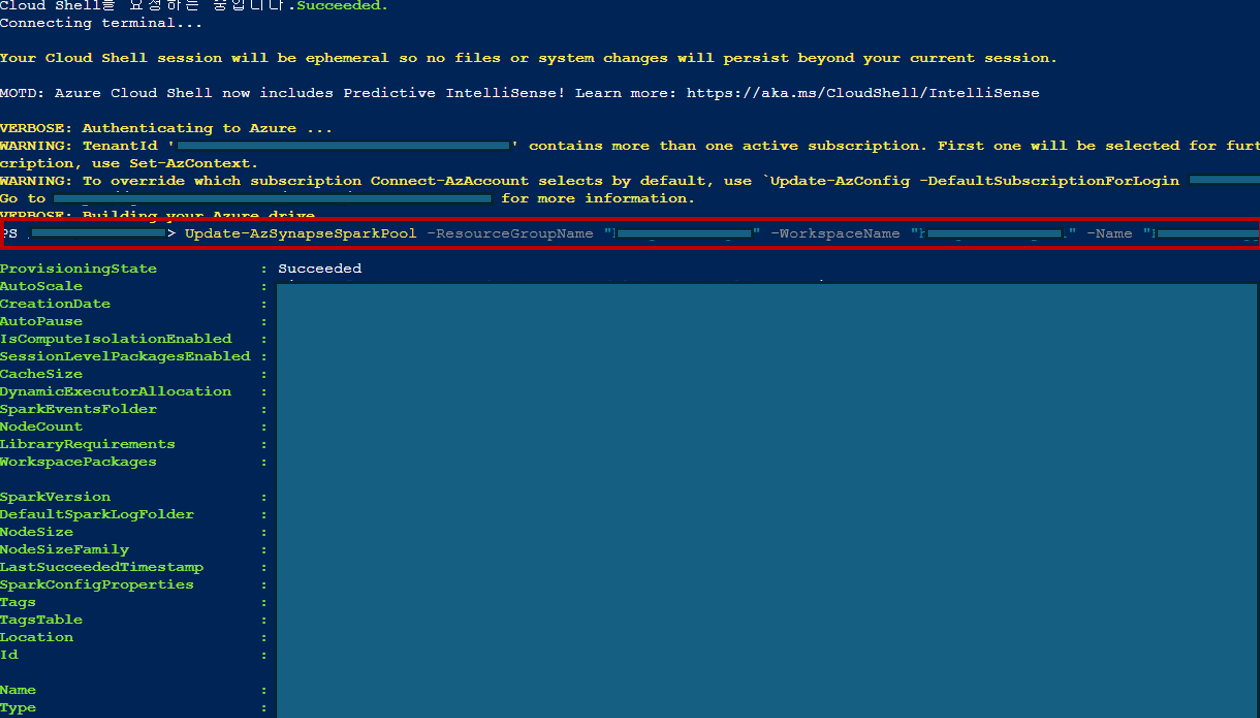
관련 개념 : Azure Synpase와 Apache Spark
Azure Synpase와 Apache Spark의 관계는 Synapse 내에서 분산 처리를 수행할 수 있도록 하는 구조적 연결에 기반한다.
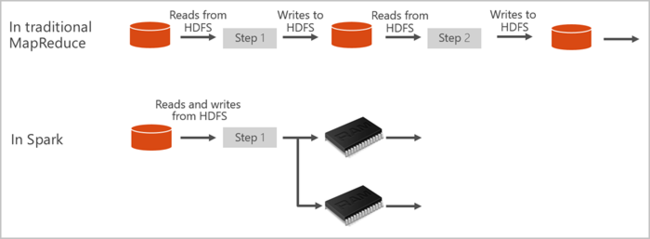
Apache Spark는 메모리 내 처리를 지원하여 빅 데이터 분석 애플리케이션의 성능을 향상하는 병렬 처리 프레임워크이다. Azure Synapse Analytics의 Apache Spark는 Microsoft가 구현한 클라우드의 Apache Spark 중 하나다. Azure Synapse를 사용하면 Azure에서 서버리스 Apache Spark 풀을 쉽게 만들고 구성할 수 있다. Azure Synapse의 Spark 풀은 Azure Storage 및 Azure Data Lake 2세대 스토리지와 호환된다. 따라서 Spark 풀을 사용하여 Azure에 저장된 데이터를 처리할 수 있다.
(1) Apache Spark 란
Apache Spark는 메모리 내 클러스터 컴퓨팅을 위한 기본 형식을 제공합니다. Spark 작업은 메모리로 데이터를 로드하고 캐시하여 반복적으로 쿼리할 수 있습니다. 메모리 내 컴퓨팅은 디스크 기반 애플리케이션보다 빠릅니다. 또한 Spark는 여러 프로그래밍 언어와 통합되기 때문에 로컬 컬렉션과 같은 분산 데이터 세트를 조작할 수 있습니다. 매핑 및 reduce 작업으로 모든 것을 구조화하지 않아도 됩니다. Azure Synapse의 Spark 풀은 완전 관리형 Spark 서비스를 제공합니다.
Azure Synapse의 Spark 풀에는 풀에서 기본적으로 사용할 수 있는 다음 구성 요소가 포함됩니다.
- Spark Core. Spark Core, Spark SQL, GraphX 및 MLlib가 포함됩니다.
- Anaconda
- Apache Livy (Livy is an open source REST interface for interacting with Apache Spark from anywhere.) > 이번 에러와 연관
- nteract Notebook
(2) Spark 풀
Spark 애플리케이션은 주 프로그램(드라이버 프로그램이라고 함)의 SparkContext 개체에 의해 조정된 풀에서 독립 프로세스 세트로 실행됩니다.
즉, Spark는 분산 시스템에서 대량 데이터를 처리하기 위해, 드라이버 프로그램이 SparkContext 를 통해 클러스터 전체를 조정하고, 실행기들이 각각 독립적으로 작업을 수행하는 구조이다.
Spark 풀은 Spark 작업을 실행할 수 있도록 미리 정의된 클러스터이다.
- 일반적으로 Apache Spark는 분산 데이터 처리를 위해 여러 노드(worker nodes)에서 병렬 연산을 수행하는 구조다.
- Spark 풀은 Spark 작업을 실행할 수 있도록 미리 구성된 클러스터이다.
- 필요할 때 클러스터를 자동으로 생성하고, 작업이 끝나면 자동으로 종료된다.
Apache Spark는 드라이버(driver)와 실행기(executor) 구조로 동작한다. Spark 애플리케이션이 실행되면 가장 먼저 드라이버 프로그램이 실행되고, 드라이버가 클러스터 내에 여러 실행기를 할당해서 작업을 수행하는 구조이다.
-
드라이버 프로그램(driver program): Spark 애플리케이션의 중심, 실행기를 관리하고 작업을 배포하는 컨트롤러
- 사용자의 Spark 애플리케이션 코드(python, scala, java 등) 를 실행하는 메인 컨트롤러이다.
- 내부적으로 SparkSession(SparkContext 포함)을 생성하고, 작업(job)을 제출하는 역할을 한다.
- 클러스터에 작업을 할당하고 실행기(executors)와 통신하며, 최종 결과를 반환한다.
-
실행기(executors)
- 드라이버가 할당한 작업(task)을 실제로 수행하는 워크 노드에서 실행되는 프로세스이다.
- Spark 풀에서 작업을 실행할 때, 각 실행기는 하나의 독립된 프로세스로 실행되며, 특정한 코어(cpu)와 메모리를 할당받는다.
- 분산 환경에서 병렬로 데이터를 처리하고 결과를 드라이버에 반환한다.
- 드라이버는 이러한 실행기들과 통신하면서 병렬로 작업을 분배하고 결과를 수집한다.
SparkContext 는 Spark 애플리케이션의 핵심 개체로, 클러스터 리소스를 관리하고 작업을 조정합니다.
- Synapse 내에서는 보통 SparkSession 을 사용하며, 내부적으로 SparkContext 를 포함한다.
- SparkContext 는 드라이버 프로그램 내에서 생성되며, 클러스터 내의 모든 실행기와 통신한다.
Azure Synapse에 대한 Apache Spark의 할당량 및 리소스 제약 조건: MAXIMUM_WORKSPACE_CAPACITY_EXCEEDED
관련 기록 : https://velog.io/@hyojinnnnnan/Azure-AVAILABLEPOOLCAPACITYEXCEEDED
서버리스 Apache Spark 풀은 Azure Portal에서 만든다. 이 풀은 인스턴스화하면 데이터를 처리하는 Spark 인스턴스를 만드는 데 사용되는 Spark 풀의 정의이다. Spark 인스턴스는 Spark 풀에 연결하고, 세션을 만들고, 작업을 실행할 때 생성된다. 여러 사용자가 단일 Spark 풀에 액세스할 수 있기 때문에 연결하는 사용자마다 새 Spark 인스턴스가 만들어진다.
모든 Azure Synapse 작업 영역에는 Spark에 사용할 수 있는 vCore의 기본 할당량이 제공된다. 할당량은 사용자 할당량과 데이터 흐름 할당량 간에 분할되므로 사용 패턴이 작업 영역에서 모든 vCore를 사용하지 않는다. 작업 영역에서 남은 것보다 더 많은 vCore를 요청하면 다음과 같은 오류가 발생한다.
Failed to start session: [User] MAXIMUM_WORKSPACE_CAPACITY_EXCEEDED
Your Spark job requested 480 vCores.
However, the workspace only has xxx vCores available out of quota of yyy vCores.
Try reducing the numbers of vCores requested or increasing your vCore quota. Click here for more information - https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-conceptsSpark 풀 생성 시 크기 설정과 노트북 실행기 크기
- Spark 풀은 클러스터 전체의 가용 리소스를 의미하며, 이 리소스 안에서 여러 사용자가 세션을 실행
- Synapse 노트북을 실행할 때, 실행기(executors) 크기를 설정할 수 있다. 사용자는 필요한 리소스를 지정하여 자신의 세션에서 실행될 executor의 크기를 설정한다. 각 사용자가 실행하는 노트북의 executor 크기는 Spark 풀의 크기보다 작거나 같아야 한다.
여러 사용자가 단일 Spark 풀을 사용할 때 리소스 할당 방식
Synapse의 Spark 풀은 동적 리소스 할당을 기반으로 동작하며, 여러 사용자가 동시에 접근하면 다음과 같은 방식으로 리소스가 분배된다.
-
Synapse는 각 사용자의 요청을 Spark 풀에 전달
Livy가 새로운 Spark 세션을 생성하고, 해당 사용자가 사용할 실행기(executors)를 요청 -
Spark 풀에서 사용 가능한 리소스를 확인하여 할당
Spark 풀은 현재 가용한 리로스를 확인하고, 사용자가 요청한 실행기 크기에 맞춰 할당 -
동시 실행 사용자가 많으면 리소스 제한 발생
- 예를 들어, Spark 풀의 전체 크기가 Medium (8 vCores, 64GB RAM) 이라면, 두 명의 사용자가 각각 Small (4 vCores, 32GB RAM) 크기로 실행할 수 있지만, 세번째 사용자가 요청하면 실행이 대기될 수 있다.
- Auto Scale 기능이 활성화된 경우, Synapse 는 자동으로 새로운 노드를 추가하여 리소스를 확장할 수 있다.
- 실행이 끝난 사용자의 리소스는 반환됨
Spark 풀 수준: Your Spark job requested xx vCores
Spark 풀을 정의하는 경우 해당 풀에 대한 사용자당 할당량을 효과적으로 정의하는 것이다. 여러 개의 Notebook 또는 작업을 실행하거나 이 둘을 혼합하여 실행하면 풀 할당량이 소진될 수 있다. 이렇게 하면 오류 메시지가 생성된다.
Failed to start session: Your Spark job requested xx vCores.
However, the pool is consuming yy vCores out of available zz vCores.Try ending the running job(s) in the pool, reducing the numbers of vCores requested, increasing the pool maximum size or using another pool이 문제를 해결하려면 Notebook 또는 작업을 실행하여 새 리소스 요청을 제출하기 전에 풀 리소스의 사용량을 줄여야 한다.
(3) Azure와 Spark 의 연결 관계
- Azure Synapse는 크게 SQL 기반 엔진(서버리스 SQL 및 전용 SQL 풀) 과 Apache Spark 기반 엔진 2가지를 지원한다.
- Spark 풀을 통해 분산 데이터 처리와 머신 러닝을 실행할 수 있다. 특히 대용량 데이터 처리 및 변환(ETL), ML 모델 학습, 데이터 탐색 같은 작업에서 활용된다.
- Spark는 Azure Blob Storage나 ADLS와 긴밀히 연결되며, 대량 데이터를 읽고 처리할 때 효율적으로 작동한다.
(4) Spark 세션이 필요한 경우
Synapse에서 Spark 코드를 직접 작성하지 않더라도, 특정 작업을 수행할 때 Spark 세션이 자동으로 활성화될 수 있다.
- Synapse Studio 에서 Explore 기능을 사용하여 데이터 레이크의 parquet/csv 데이터 미리보기 등을 수행할 경우
- Synapse 파이프라인 내에서 Spark 관련 작업을 수행하는 경우
- 파이프라인을 실행할 때 Spark 세션이 무조건 켜지는 것은 아니다. 파이프라인의 구성 요소(Activities)에 따라 달라진다.
- 예. 노트북 실행
- 예. 노트북 실행
- 파이프라인을 실행할 때 Spark 세션이 무조건 켜지는 것은 아니다. 파이프라인의 구성 요소(Activities)에 따라 달라진다.
- Spark 기반 테이블 또는 Delta Lake 사용
- Synapse 내부에서 Spark 풀과 SQL 엔진 간의 최적화된 데이터 처리
- 예. Synapse Link for Dataverse
