Overview
논문명: LETS-C : Leveraging Text Embedding for Time Series Classification
학회(출판연도): ACL(2025)
연구분야: 딥러닝 기반 시계열 표현 학습
Abstract
- 최근 사전학습된 LLM을 시계열 분류 과제에 맞게 파인튜닝하는 방식이 SOTA 달성
- 하지만, LLM기반 모델들의 학습 파라미터가 수백만 개에 달하는 대규모 모델이라는 단점 존재
⇒ LLM을 파인튜닝하기 보단,
① 텍스트 임베딩 모델을 통해서 시계열 데이터를 임베딩 한 후
② CNN과 다층 퍼셉트론(MLP)로 구성된 간단한 분류 헤드와 결합하자!
[결과]
- 기존 SOTA 모델 능가
- 평균적으로 SOTA대비 14.5%정도 학습 가능한 파라미터 사용
1. Introduction
- 시계열 분류
- 금융, 헬스케어, 활동 인식 등 다양한 분야에서 폭넓게 활용
→ 효율적이면서도 정확한 분류 방법에 대한 필요성이 높아지고 있음
- 금융, 헬스케어, 활동 인식 등 다양한 분야에서 폭넓게 활용
- TSC의 NLP와 LLM의 적용
- 프롬프팅 기법
- 사전 학습 LLM에 파인튜닝 하는 방식
- LLM은 수십억개의 파라미터를 가진 거대한 모델 → 계산 비용이 높아 제한된 환경에서는 실용적X
- 부분적으로 동결된 사전 학습 LLM을 파인튜닝하더라도 수백만개의 학습가능한 파라미터 필요
- (S) LETS-C
- 기성 텍스트 임베딩 모델을 활용하자!
- 텍스트 임베딩 + CNN과 MLP로 구성된 분류헤드 결합
- 텍스트 임베딩 모델: 시간적 데이터에 내재된 복잡한 패턴과 의존성 포착
- 분류헤드: 서로 다른 클래스간 구분
[기여]
1. 최고 수준 성능
- 다양한 시계열 도메인 데이터셋에서 SOTA 달성
- 27개의 베이스라인모델 능가
2. 계산 효율성
- 기존 SOTA대비 14.5%의 파라미터만을 사용
3. 시계열 임베딩 내재적 판별력
- 텍스트 임베딩이 분류 정확도 향상에 기여
4. 다양한 텍스트 임베딩 모델에 대한 일반화 성능 - 서로 다른 텍스트 임베딩 모델에서도 굿
5. 정확도 손실을 최소화한 모델 크기 최적화
- 모델 크기를 줄여도 높은 정확도 유지
2. Related Work
Time Series Classification
[초기연구]
- 지도학습
- DTW, SVM 같은 거리 기반 접근법
- 특징추출기법 + XGBoost 분류기 결합 방식
- CNN, MLP, LSTM같은 순환 신경망(RNN)을 포함한 딥러닝 기반 접근법
- 최근 Transformer기반 self-attention을 활용하여 장기 의존성 포착
- 비지도학습
- 마스킹된 시계열 복원 과제로 사전학습
- 분류와 같은 다운스트림 과제에 파인튜닝하는 방식
⇒ 높은 계산 비용으로 인해 학습 과정에서 부담有
Language Models for Time Series
[최근 연구]
- 시계열 - 텍스트 모델링, 시계열에 대한 자연어 설명, 다양한 응용을 포함하여 시계열과 언어의 결합 탐구
- 프롬프팅 → 시계열 예측에 활용 (일부 설명 가능한 금융 예측 생성 가능성 탐구됨)
- Time-LLM
- 시계열 데이터를 언어 임베딩 공간으로 매핑하여 LLM기반 예측
- GPT와 같은 LLM을 파인튜닝 → SOTA 달성
[LETS-C]
- LLM을 직접 사용하기보단 텍스트 임베딩 활용
Text Embeddings
-
NLP의 핵심적 표현 기법
- 단어 또는 문장을 밀집 벡터 공간으로 매핑하여 의미적, 구문적 정보 포착
- 단어 수준의 임베딩: Word2Vec, GloVe
- 문맥기반 임베딩: BERT, RoBERTa
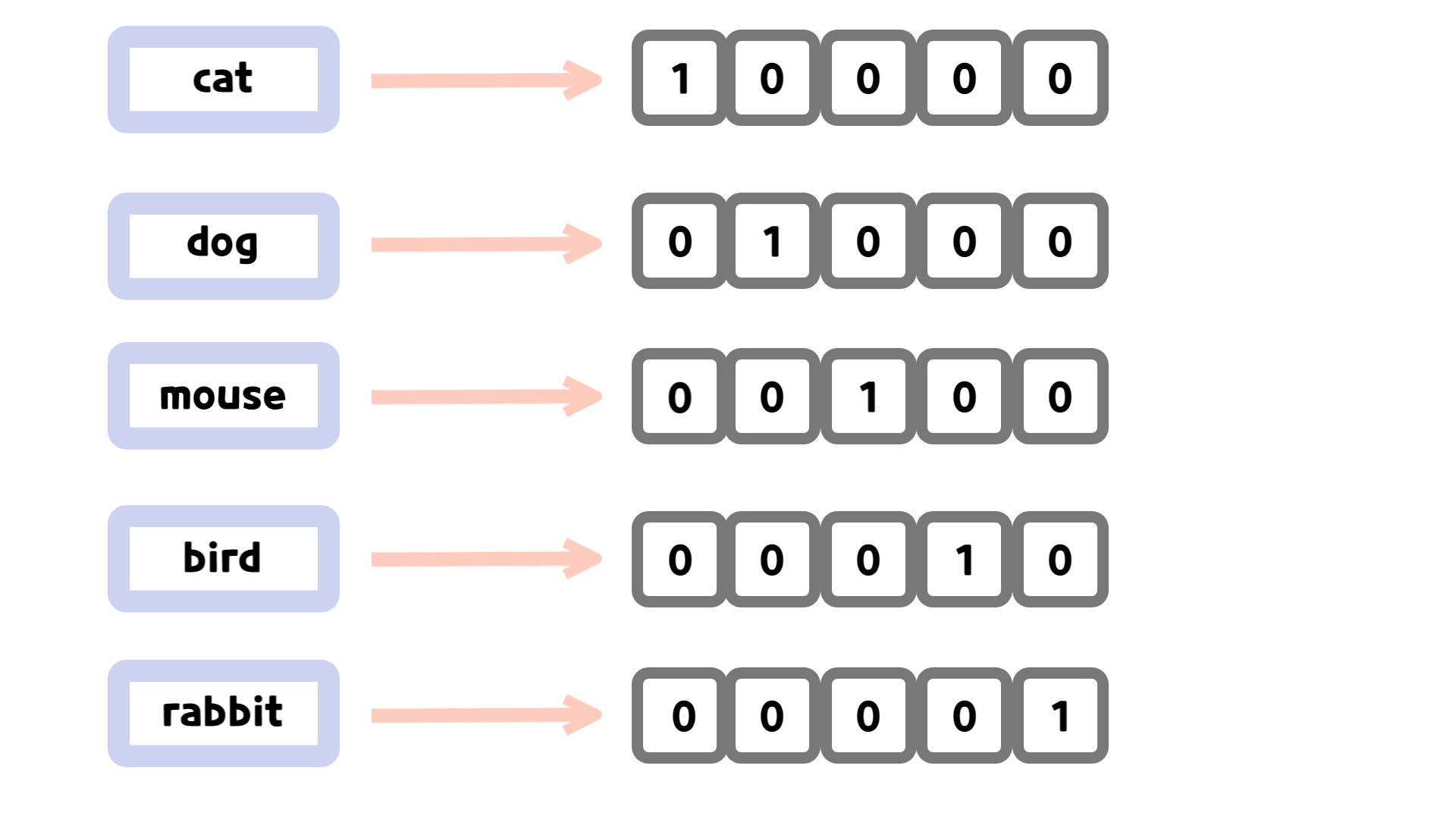
✓ Word2Vec
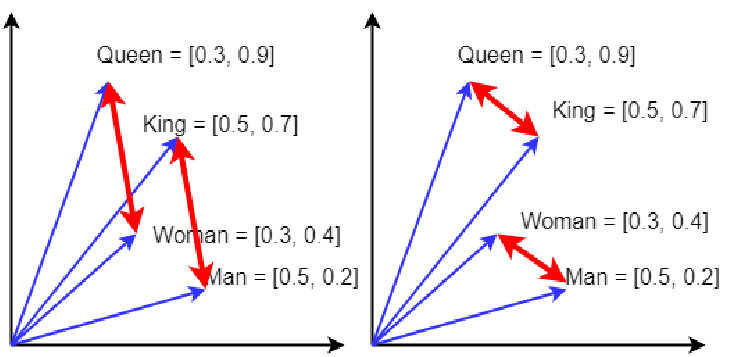
- 단어 하나마다 항상 같은 벡터를 부여하는 방식
- 각 점 = 단어 하나
- 비슷한 단어들이 공간에서 가까이 모여 있음
✓ GloVe
- 단어들이 전체 말뭉치에서 얼마나 같이 등장하는지 보는 방식
- 같이 등장한 빈도 기반으로 벡터 공간 형성
- 고정된 단어 벡터
-
시계열
- NLP에 비해 대규모 데이터셋 부족
- 임베딩을 처음부터 학습하는 것에 대한 어려움
⇒ 시계열을 잘 표현하려면, 시퀀스 전체 문맥을 요약할 수 있는 임베딩이 필요한데, NLP에서는 BERT계열이 가장 잘해왔다.
LETS-C는 그걸 학습하지 않고, 그냥 가져다 쓰는(lightweight) 전략을 사용하자는 것!
즉, LLM을 학습하기 보단, 이미 학습된 표현공간을 활용하자는 아이디어
3. Methodology
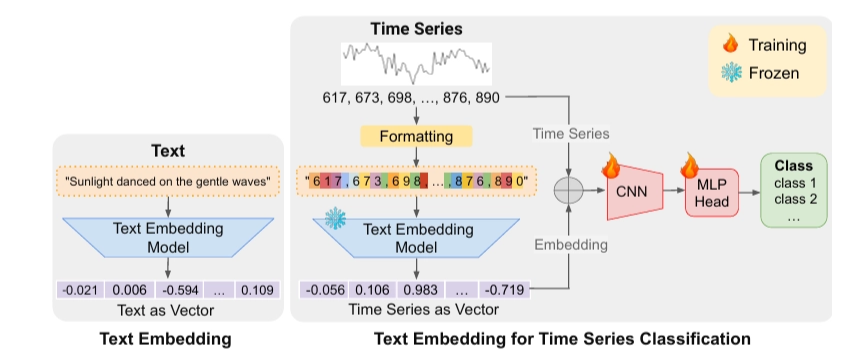
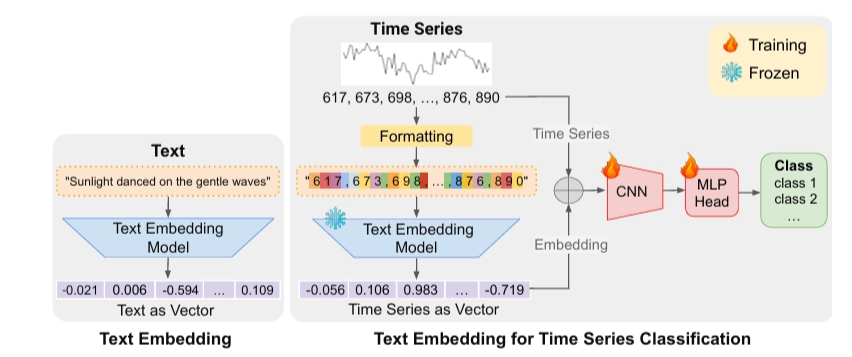
-
시계열 분류 데이터셋
- 다변량 시계열 샘플 x_i를 클래스 레이블 y_i에 대응
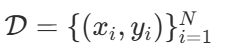
- 다변량 시계열 샘플 x_i를 클래스 레이블 y_i에 대응
-
목표: 각 시계열에 대해 클래스 레이블(햇y)을 정확히 예측하는 분류기 학습
-
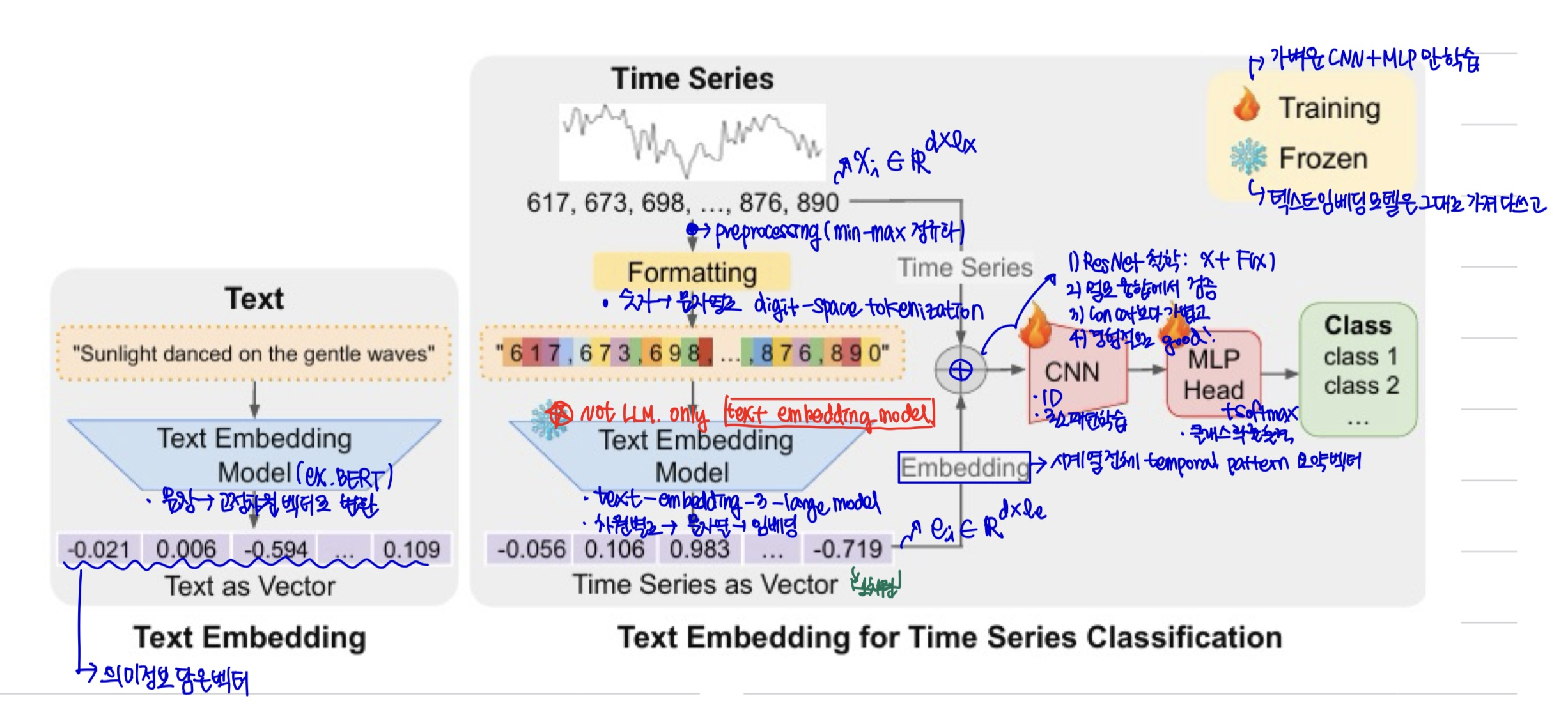
과정
- 시계열 데이터 정규화 (전처리)
- 정규화된 데이터로 임베딩 생성
- 임베딩과 원본 시계열 데이터 결합
- 결합 데이터를 CNN과 MLP로 구성된 분류 헤드에 입력
✓ 단순한 분류 헤드를 선택한 이유
- 텍스트 임베딩만으로도 효과적인 분류를 하기에 충분하다
Preprocessing
- x_i의 각 특징 차원 [0,1]범위로 min-max 정규화
- 일관된 스케일 보장 목적
Text Embedding of Time Series
✓ 임베딩이란?
- 컴퓨터의 입장에서는 "고양이가 귀엽다"에서 고양이? 귀엽다? 의미를 모름 (숫자만 계산 가능)
→ 때문에 단어에 숫자를 붙이기 시작했음!- one-hot encoding
- 이렇게 되면 서로가 모두 다른 값이고 고양이와 강아지가 비슷하다와 같은 정보를 얻을 수 없음
- 또한 단어 수가 늘면 벡터가 엄청나게 커지는 문제 발생
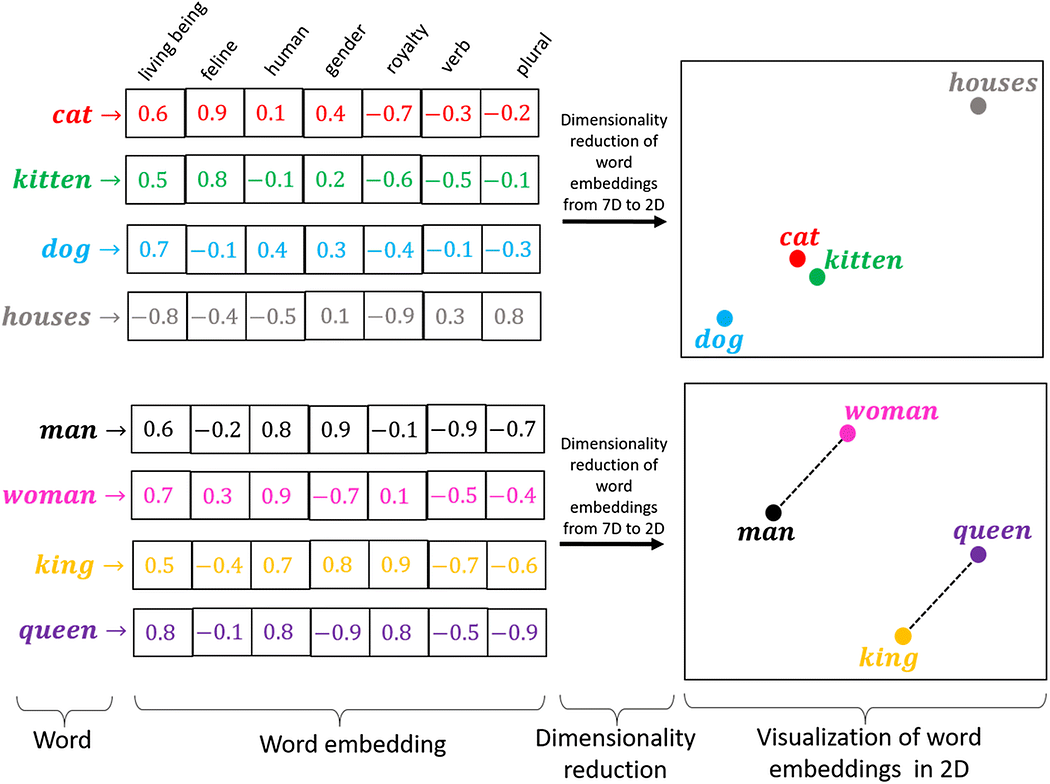
⇒ 비슷한 의미의 단어는 숫자 벡터에서도 비슷하게 만들자!- 임베딩
- 복잡한 대상(단어, 문장, 이미지 등)을 의미를 담은 숫자 벡터로 바꾸는 것
- 벡터간 거리 = 의미 유사도
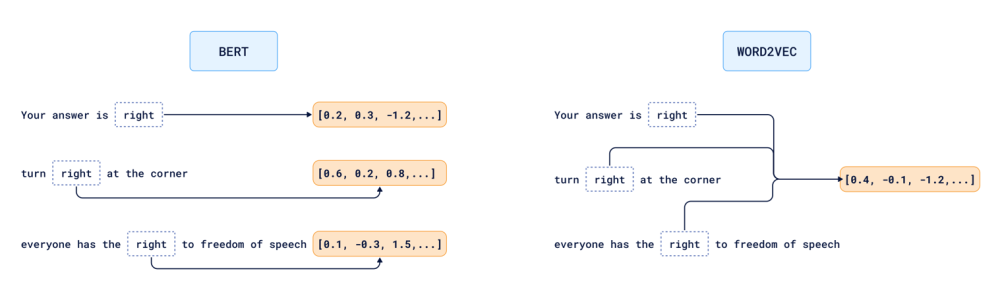
✓ 텍스트 임베딩이란?
- 문장(텍스트)의 "의미"를 숫자 벡터 하나로 압축해서 표현하는 것
- 핵심: 비슷한 의미의 문장은 숫자벡터에서도 가깝게 만들자!
- 어떤 단어들이, 어떤 순서로, 어떤 문맥에서 함께 나오는지를 배움
-
수치 문자열의 토크나이제이션 방식이 임베딩 결과에 큰 영향을 미칠 수 있으므로 텍스트 임베딩 적용 전 전처리된 시계열을 문자열 형태로 신중하게 변환하는 것이 중요!
- (P) 일반적으로 사용되는 서브워드 토크나이저 → 숫자를 임의로 분할
- (S) digit-space 토크나이제이션
- 각 자릿수를 공백으로 분리
- 시간 단계 구분을 위해 쉼표 추가
- 고정 소수점 정밀도 가정 → 소수점 제거
-
text-embedding-3-large model 사용
- 변환된 시계열 문자열을 임베딩 공간으로 매핑하기 위함
즉, NLP모델을 쓰기 위함

- 변환된 시계열 문자열을 임베딩 공간으로 매핑하기 위함
즉, 정리하자면
- 시계열은 길고 무겁기 때문에 각 채널별로 텍스트 임베딩을 만든 후
- 각 채널 임베딩을 쌓아 행렬로 만든다
- 이 결과는 항상 같은 크기이기 때문에 한 번 계산하면 계속해서 사용 가능하다
Fusing Embedding and Time Series
- 제로 패딩 적용
- 차원 일관성 유지 목적
- 요소별 덧셈을 하기 위해서는 두 벡터(또는 행렬)의 크기가 완전히 같아야 함
- 보통 임베딩 벡터 길이 < 시계열 길이 이므로 남는 길이는 0으로 채움
⇒ 즉, 정보는 왜곡하지 않으면서 형태만 맞춘다
- 차원 일관성 유지 목적
- 요소별 덧셈(element-wise addition) 사용
- 같은 위치의 값을 더한다
⇒ 임베딩과 전처리된 시계열 데이터 결합
✓ 임베딩과 전처리된 시계열 데이터의 결합
- 시계열 임베딩(Global)
- 텍스트 임베딩으로 얻은 벡터로, 전체 시계열의 전반적인 패턴 요약 - 전처리된 시계열(local)
- 정규화 및 패딩만 거친 시계열로 시간 별 세부 변화, 로컬 패턴
⇒ (P)이 둘의 형태가 다르기 때문에 (S)제로패딩!
- 요소별 덧셈은 ResNet의 Shortcut과 일맥상통하는 아이디어!
- ResNet에서 깊은층이 입력을 뭉그러뜨릴 수 있는 것처럼 LETS-C에서는 임베딩이 원본시계열을 뭉그러뜨릴 수 있음
- 때문에, 임베딩 정보를 쓰되, 원본 시계열 기준으로 보정만 하자!
⇒ fused = raw time seires + embedding
✓ ResNet의 Shortcut?
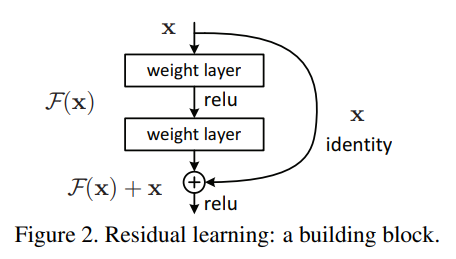
- 이전 딥러닝에서는 층을 많이 쌓으면 더 똑똑하겠지?라는 믿음으로 CNN을 점점 더 깊게 만듦
- 그런데 20층 모델보다 50층의 모델이 더 성능이 나쁜것임!
과적합도 아니고 데이터 부족도 아니었음
⇒ 성능열화문제(degradation problem)
예를 들어, 입력이 고양이 → 출력도 고양이가 나와야함
(P) 층을 거치면서 변형이 너무 많아지면 "고양이였다"는 정보 자체가 사라질 수 있음
(S) 어떤 층은 아무 일도 안하는게 최선이라면?
→ 출력 = 원래 + 바뀐 것 (즉, 차이(residual)을 배우게 하자!)
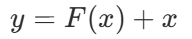
- x: 원본입력
⭐ 절대로 잃으면 안되는 정보! - F(x): 여러 층을 거쳐 계산한 결과
ex. 귀 강조, 털 질감 등
- 원본을 보완하기 위해 학습된 변화로, 만일 어떤층이 쓸모가 없다면 F(x)=0 즉, y=x로 학습하도록 함
⇒ 층을 쌓더라도 최소한 손해를 보지 않음!
⇒ ResNet의 핵심은 학습된 표현이 원본 입력을 대체하지 못하게 하고 원본 입력을 항상 기준으로!
- 같은 위치의 값을 더한다
- 서로 다른 모달리티 임베딩 결합
- 시계열, 텍스트 임베딩은 서로 다른 종류의 정보
- 멀모에서 흔한 결합 방식으로는 concat, attention, element-wise addition이 있는데 그중 덧셈이 가장 단순하고 파라미터 증가가 없는 안정적인 방법이었음
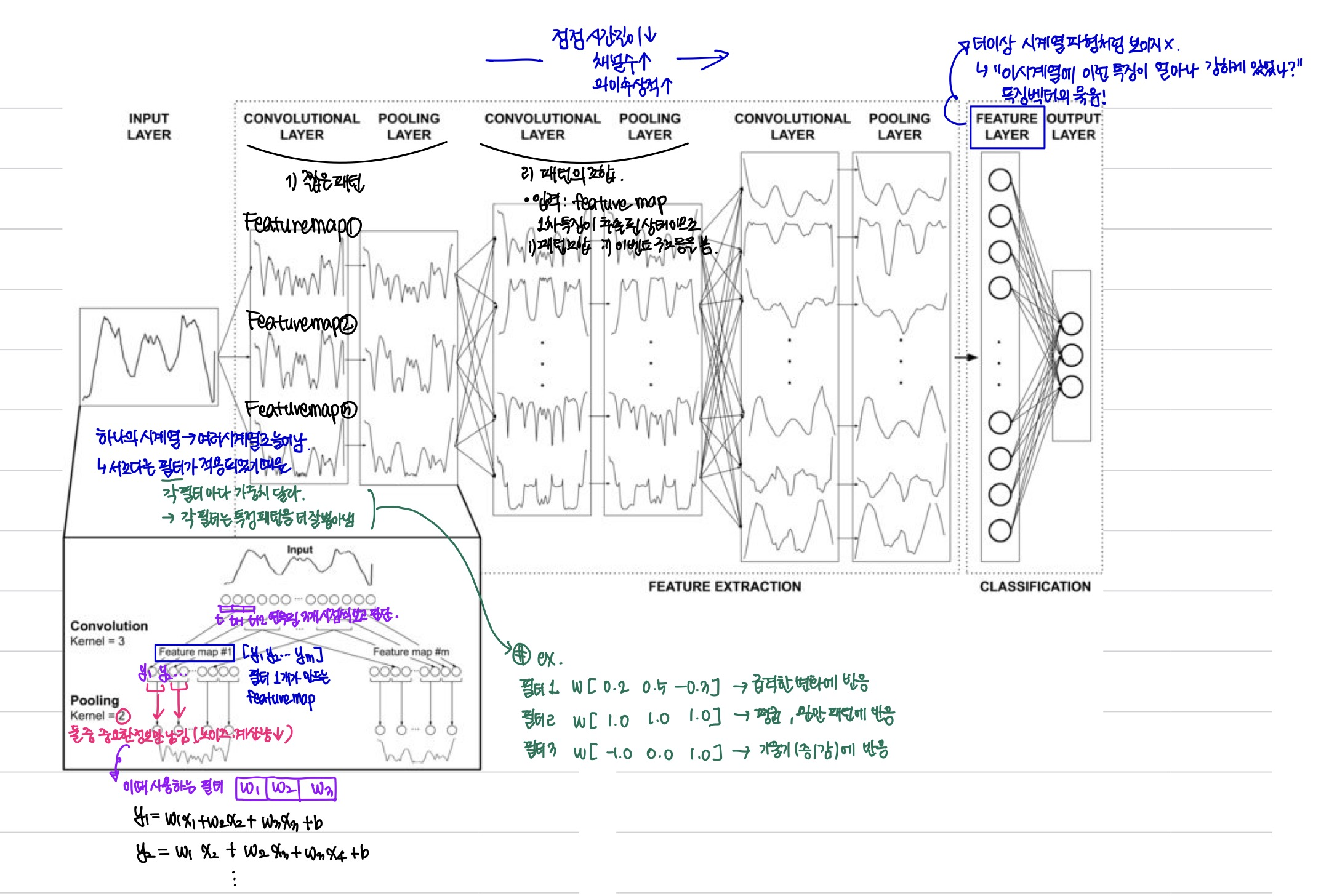
Lightweight Classification Head
- 위에서 결합한 시계열 표현이 1차원 CNN과 MLP로 구성된 분류 헤드와 결합
- CNN 출력 → 평탄화 → MLP(softmax) → 시계열 클래스 확률 벡터 출력
✓ 주의: CNN은 특징추출기이고, CNN 뒤의 MLP와 softmax가 분류기!
✓ 텍스트 임베딩을 통해 이미 특징을 다 뽑아 온거 아닌가? 왜 CNN이 필요한가?
- 텍스트 임베딩 모델은
- 입력을 고정된 벡터로 매핑, 비슷한 패턴을 가깝게 배치까지는 해줌
- 하지만 어떤 방향이 클래스 경계인지, 어떤 조합이 최적의 분리인지는 알려주지 않음
⇒ 즉 임베딩 = feature space, CNN = dicision boundary learner- CNN은 지역적 패턴을 다시 추출해서 데이터셋의 specific한 특징을 강조하고 노이즈를 걸러내는 역할
- 특징을 또 뽑는다기보단, 특징을 재구성한다는 표현이 더 맞음
- local 패턴 강조
- embedding이 준 global 정보와 raw가 준 local 정보를 조합하여 어떤 조합이 클래스 구분에 중요한가를 학습!- 단순 MLP만 사용할 경우 완전 연결이므로 시간 구조를 직접적으로 활용하지 못함
✓ 시계열 CNN
✓ 최종 흐름
4. Experimental Protocol and Details
Datasets and Evaluation Metrics
- 벤치마크 기준으로 평가
- 데이터셋
- Ethanol Concentration, Face Detection, Handwriting, Heartbeat, Japanese Vowels, PEMS-SF, SelfRegulationSCP1, SelfRegulationSCP2, Spoken Arabic Digits, UWaveGestureLibrary
- 변수 차원: 3~963
- 시계열 길이: 최대 1751
- 클래스 수: 최대 26개
- 평가지표: AvgWins
- 우수한 성능 평균 횟수(동률포함), 학습가능파라미터 수 기준으로 계산 효율성
Baselines
- 27개의 베이스 라인 모델
- 전통적
- Dynamic Time Warping(DTW), eXtreme Gradient Boosting(XGBoost), RandOm Convolutional KErnel Transform(ROCKET)
- MLP기반
- DLinear
- RNN기반
- LSTM, LSTNet, 그리고 Linear State Space Layer(LSSL)
- CNN기반
-
Temporal Convolutional Network(TCN), TimesNet
+) 비지도 T-Loss, Temporal Neighborhood Coding(TNC), TS2Vec
-
- Transformer기반
-
Transformer, Reformer, Informer, Pyraformer, Autoformer, Non-stationary Transformer, FEDformer, ETSformer, Flowformer, PatchTST
+) 비지도 TS-TCC, Time Series Transformer(TST), MOMENT
-
- LLM기반
- OneFitsAll
- 전통적
5. Results and Analysis
5.1 Performance and Efficiency
Comparison to State of the art
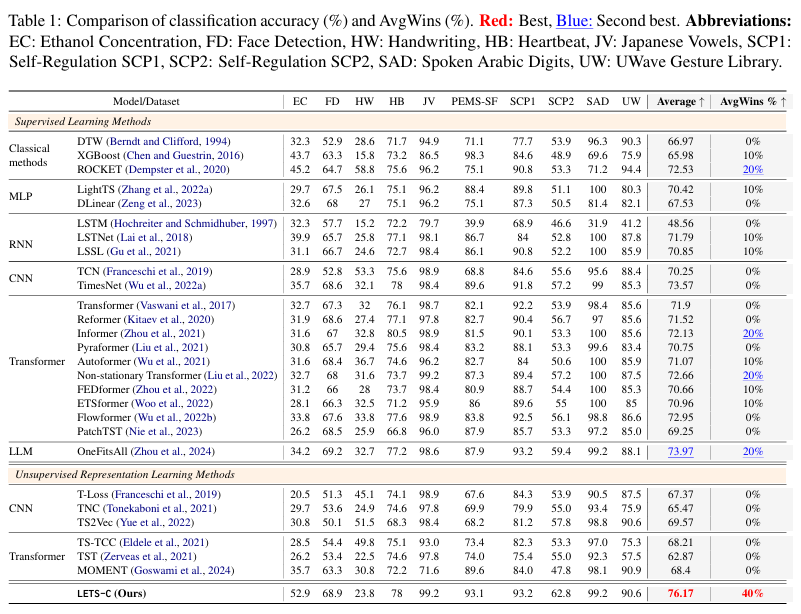
- 27개의 베이스 라인 모델과 비교했을 때 LETS-C 모든 데이터셋에서 강건한 성능
- 기존 SOTA 대비 경쟁력 있다~
Computational Efficiency
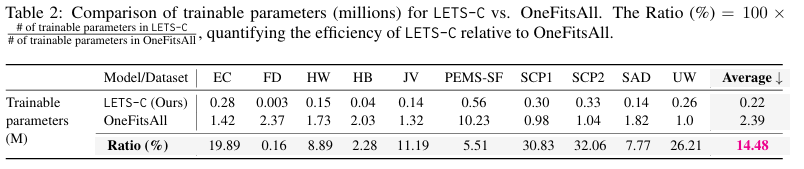
- 자원이 제한된 환경에서 성능과 계산 효율성 간의 균형 평가
- OneFitsAII대비 평균적으로 14.48%정도의 학습가능파라미터만으로도 좋은 성능
- OneFitsAII은 TimesNet이나 FEDformer와 같은 주요 모델 대비 파라미터 수가 적다는 장점이 있는 모델임
- LETS-C는 텍스트 임베딩 계산이 딱 1번 수행된다는 점이 중요!
- OneFitsAII같은 모델은 부분 동결 LLM을 파인튜닝하는 과정에서 지속적으로 계산 발생
5.2 Effectiveness of LETS-C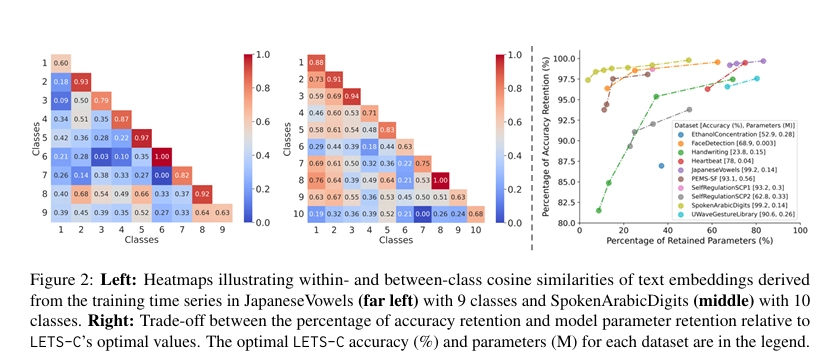
- 텍스트 임베딩이 시계열 분류에 적절한지 검증
- 동일 클래스 내의 시계열 쌍과 서로 다른 클래스 간의 시계열 쌍에 대해 평균 코사인 유사도 계산
- 히트맵: 빨간색 - 유사도 높고, 파란색 - 유사도 낮음
- 클래스 내부 유사도가 클래스 간 유사도보다 일관되게 높게 나타남
Generalization Across Various Text Embedding Models
- text-embedding-3-large이외의 다양한 텍스트 임베딩 모델에 대한 일반화 성능 평가
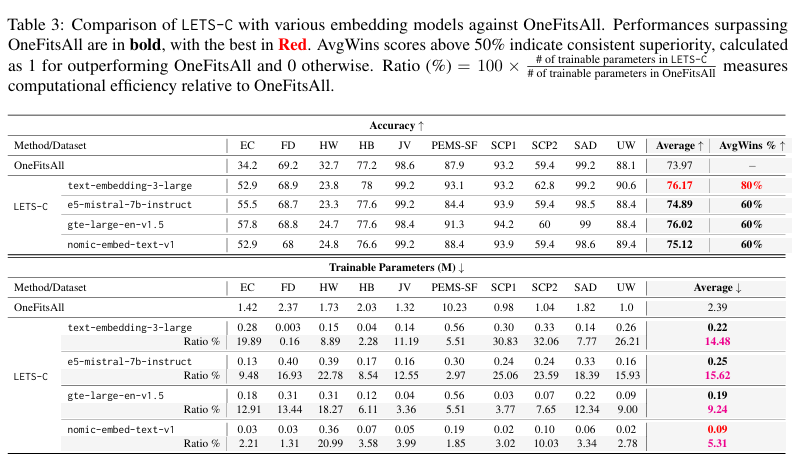
- e5-mistral-7b-instruct, gte-large-en-v1.5, nomic-embed-text-v 모델 추가 적용
- 다양한 텍스트 임베딩 모델 전반에서도 우수한 성능
Optimizing Model Size with Minimal Accuracy Loss
- 모델 정확도와 모델 크기 간의 trade-off 분석
- 분류 헤드의 선형 계층 및 합성곱 계층 수를 1개~5개까지 조절
- trade-off가 데이터셋에 따라 다소 차이가 있으나 전반적으로 파라미터수를 줄여도 정확도 크게 안변함
5.3 Additional Analysis
Ablation Study
- 텍스트 임베딩 + 시계열 데이터 결합이 단일 모달리티보다 어떤 이점을 갖는지 검증
Alternative Methods for Fusing Time Series with Embeddings
- 단순 덧셈 외, 시계열과 임베딩을 결합하기 위한 2가지 추가적인 방법 검증
- 임베딩 → 합성곱 계층, 시계열 데이터 → 완전연결계층으로 처리한 뒤
두 분기의 특징을 하나의 최종 밀집 네트워크에서 결합 - 시계열과 임베딩 concat한 후, 경량 분류 헤드를 통해 처리
- 교차 어텐션은 계산복잡도가 커서 안했음
- 임베딩 → 합성곱 계층, 시계열 데이터 → 완전연결계층으로 처리한 뒤
- 본 연구의 목표는 경량모델개발이므로 보다 단순한 파라미터 구조의 덧셈 방식 최종 채택
6. Conclusion
- 기성 텍스트 임베딩을 시계열 분석, 특히 분류 과제에 적용한 최초의 연구
- 시계열 데이터를 텍스트 임베딩 모델을 통해 투영하고 단순하지만 효과적인 분류 헤드를 사용함으로써 SOTA달성
