HTTP 개요
HTTP는 애플리케이션 계층에서 데이터를 요청하는 클라이언트와 데이터를 제공하는 서버 간의 통신을 위한 프로토콜이다.
-
HTTP를 통해 클라이언트와 서버는 통신 간에 개별적인 메시지로 통신한다.
클라이언트가 보내는 문서 요청을 request message, 서버가 보내는 문서 응답을 response message라고 한다. 클라이언트와 서버의 역할이 명확하게 구분되어 있음을 알 수 있다.
-
HTTP는 지속 연결로 통신량을 절약할 수 있다.
한 쪽이 연결을 종료하지 않으면 연결을 끊지 않는 지속 연결을 지원한다. 데이터 손실을 방지하기 위해 transport 계층의 TCP를 사용하지만, 다수의 요청을 할 경우에는 각 요청과 응답마다 연결과 연결 종료를 반복하게 되면 불필요한 통신이 늘어나기 때문에 HTTP1.1에서 지속 연결 개념을 도입하였다. 이에 더해, 요청에 대한 응답이 오지 않아도 다음 요청을 바로 보내도록 하는 파이프라인 개념도 도입하였다.
기본적인 TCP 제어는 HTTP 헤더 중connection필드를 통해 제어할 수 있다. 그러나 최근 HTTP2.0에서connection필드는 무시된다. 파이프라인 개념은 기존 소프트웨어와 최신 소프트웨어가 공존하는 상황에서 구현하기 어렵다는게 입증(어떻게?왜?)되었기 때문에, HTTP2.0의 프레임 안에서 활발하게 다중 요청을 통해 교체되고 있다(HTTP 버전에 따른 차이는 뒤에 다시 정리해두었다.). -
HTTP는 상태를 유지하지 않는(stateless) 프로토콜이다.
각각 개별적인 메시지로 통신하며 이전 상태를 관리하지 않는다. 데이터를 빠르고 확실하게 처리하기 위해 간단하게 설계되었기 때문이다. 이에 따라 request message당 새로운 response message가 생성된다.
-
HTTP는 간단하고, 확장하기 용이하다.
message의 헤더에 대한 클라이언트와 서버의 간단한 합의를 통해 기능을 쉽게 확장할 수 있다.
-
상태를 유지하기 위해 cookie를 사용한다.
cookie는 확장하기 쉬운 HTTP의 대표적 예시인 것 같다. 기존에 stateless였던 특징은 유지한 채, 새로운 헤더인
Set-Cookie와Cookie헤더에 대한 합의를 통해 cookie라는 이전 상태를 클라이언트에 보관하고, 새로운 요청에 cookie를 담아 보냄으로써 서버가 이전 상태를 확인할 수 있도록 하였다. -
HTTP는 메소드를 통해서 다양한 요청을 할 수 있다.
GET, POST, PUT, HEAD, DELETE, OPTIONS, TRACE, CONNECT 등 여러 메소드를 통해 각각 다른 요청을 할 수 있다.
HTTP 역사
HTTP 버전에 따른 차이를 알아보기 위해 HTTP0.9부터 HTTP2.0까지 버전별로 살펴보자.
HTTP0.9
HTTP0.9는 그 당시에 버전이 없었으므로 단지 HTTP라고 불릴 뿐이었으나, 다음 버전인 HTTP1.0과 구별하기 위해 현재 HTTP0.9라고 불린다. request, response message 모두 헤더가 없었기 때문에, 매우 단순하며 HTML 문서만으로 통신하였다.
경로로 리소스를 요청하는 request message의 메소드는 GET이 유일했다.
GET /index.html응답에는 상태나 오류 코드 없이 HTML 문서의 내용만이 들어가 있다.
<HTML>
...
</HTML>HTTP1.0
1991년부터 시도되었으며, 1996년 RFC 1945에 공개되었지만 공식 표준은 아니었다고 한다.
HTTP0.9와 다른 점은 바로 메시지 헤더의 출현이다. request, response message에 헤더가 포함되면서,
- HTML 문서 뿐만이 아닌 다른 형식의 문서도 주고 받을 수 있게 되었다.
Content-Type: text/html - 응답 상태에 따라 클라이언트에서 다양한 처리를 할 수 있게 되었다.
- 특정 헤더에 대한 합의를 하게 되면, HTTP의 기능을 손쉽게 확장할 수 있게 되었다.
HTTP1.1
HTTP1.0이 공개되고 얼마 지나지 않아 1997년 HTTP1.1이 RFC2068에 첫 번째 HTTP 공식 표준으로 공개되었다.
HTTP1.0과 HTTP1.1의 차이는 다음과 같다.
-
지속 연결을 지원한다.
기존 개별 연결 시에는 TCP 연결, 연결 종료마다 반복되는 handshaking으로 인한 오버헤드가 존재하였다. 이를 해결하기 위해 HTTP1.0 시기에 문서에 없는 기능을 구현하여 지속 연결 개념을 사용하는 서버도 있었다. HTTP1.1에서는 어느 한 쪽이 연결을 종료하지 않으면 기존 연결을 재사용하여 오버헤드를 줄일 수 있게 하였다.
다만 사용이 완료되어 더 이상 통신할 필요가 없는 연결을 적절하게 종료하지 않는다면 리소스를 낭비할 수 있다는 단점이 있다.
다음 코드는 HTTP1.0으로 동작하는 경우에 대비하여 작성하기도 한다(fallback).
Connection: Keep-Alive
Keep-Alive: timeout=5, max=1000 -
파이프라인을 지원한다.
다수의 요청과 응답이 필요할 시 지속 연결보다 효율적인 것이 파이프라인이다. 파이프라인 개념은 요청을 보내고 이에 대한 응답을 기다리지 않고 다음 요청을 바로 보내는 것이다. 이로 인해 통신 지연율을 낮출 수 있으며, request 수가 많아질 수록 효과는 현저하게 나타난다.
-
청크 전송 코딩을 지원한다.
청크 전송 코딩이란 response 메시지의 바디 부분을 조금씩 나누어 보내어 클라이언트가 받아 조금씩 받아볼 수 있게(표시할 수 있게)하는 것이다. 기존에는 요청했던 리소스의 바디가 모두 전송되지 않으면 표시할 수 없었다.
Transfer-Encoding: chunked -
언어/인코딩을 포함한 컨텐츠에 대한 합의를 함으로써 상황에 더 적절한 컨텐츠를 주고받을 수 있게 되었을 뿐 아니라 전송 효율도 높였다.
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
HTTP2.0
현대에 이르러 웹 상에서는 기존 보다 더 많은 요청에 의해 더 많은 데이터를 주고 받게 되었고, HTTP1.1은 이러한 상황을 감당하기에는 많은 오버헤드와 복잡성을 가지고 있었다. 대표적으로 파이프라인은 기존 소프트웨어와 최신 소프트웨어가 공존하는 기존의 네트워크에서 구현하기 어려웠다.
이러한 상황에서 구글은 2010년 SPDY 프로토콜 실험을 통해 응답성 증가 능력(?)을 입증하고 전송된 데이터 중복에 관한 문제(?)를 해결하며 HTTP2.0의 기반을 다졌다.
HTTP1.1과 HTTP2.0의 차이는 다음과 같다.
-
메시지가 이진 포맷으로 인코딩된다.
기존 plain text와 달리, 메시지가 이진 포맷으로 인코딩되었고, 메시지의 전체 구성도 바뀌었다. 기존 헤더는 Headers frame으로, 바디는 DATA frame으로 불린다. 이 두 프레임이 합쳐져 하나의 message를 구성한다.
오버헤드와 에러가 줄어들며, 네트워크 자원을 최적화할 수 있고, HTTP1.x 버전이 가지고 있던 응답 분할과 같은 평문적 보안 취약점을 제거할 수 있게 되었다.
응답 분할 공격이란 request의 파라미터가 response의 헤더로 다 시 전달되는 경우 파라미터 내에 CR 또는 LF가 존재하면 HTTP 응답이 분리되는데 이에 코드를 주입하여 XSS 및 캐시를 훼손하는 것을 말한다.
-
동일한 연결에서 병렬 요청이 가능하다.
HTTP2.0에서는 stream이라는 개념을 사용하는데, stream은 구성된 하나의 연결 내에서 하나 이상의 메시지를 양방향으로 전송할 수 있다.
기존에는 여러 개의 파일을 요청했을 때, 앞의 파일이 전송이 늦어지면 뒤 쪽 파일들이 모두 밀려 전체 전송 시간이 지연되었다(HOL Blocking. Head Of Line Blocking). HTTP1.1에서는 파이프라인을 도입하여 해결하려 했지만, 도입에 문제가 있었다.
HTTP2.0은 stream을 통해 여러 파일을 병렬 요청하고, 병렬적으로 응답받을 수 있게 되어 페이지 로딩 시간을 단축할 수 있게 하였다.
-
중복된 헤더를 압축한다.
HTTP2.0은 HPACK이라는 압축 방식을 사용하여 헤더를 압축하여 전송한다. 클라이언트와 서버는 이전에 전송한 message를 남겨놓았다가, 새로운 message를 전송할 때 이전의 압축된 message를 보고 반복되는 부분을 쉽고 안전하게 압축한다.
-
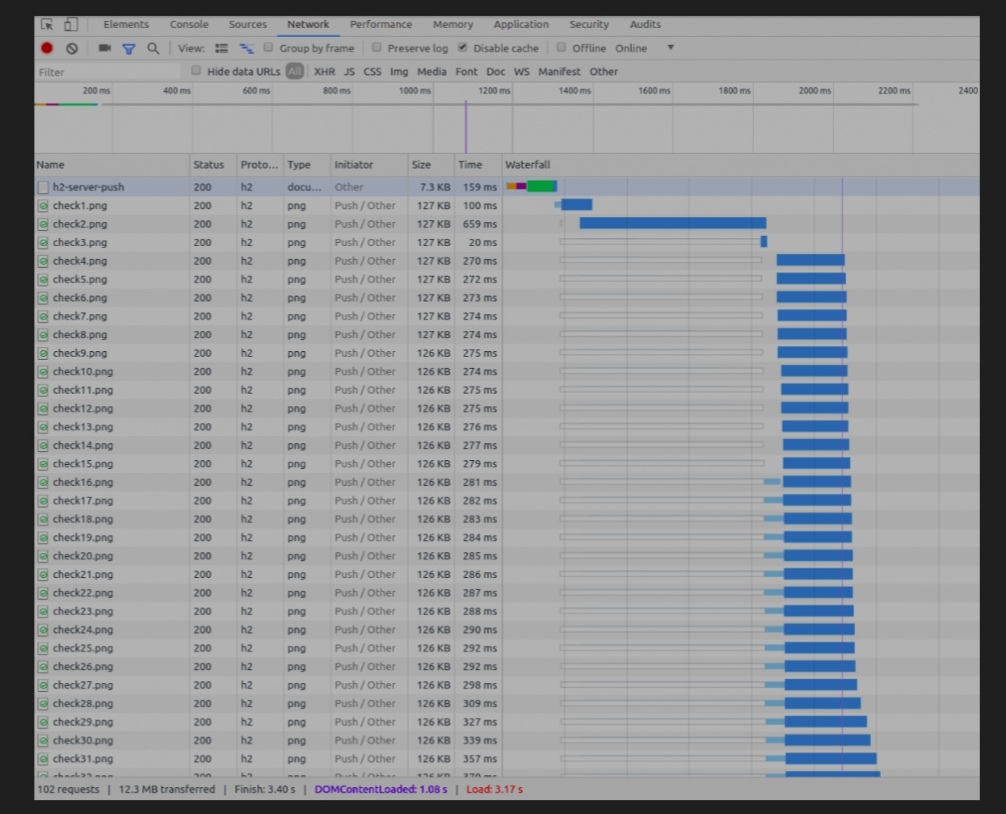
필요하게 될 파일을 미리 전송한다.
서버는 클라이언트가 지금 요청하지 않았지만 요청하게 될 데이터를 보낼 수 있게 되었다. 예를 들어, 클라이언트가 X 리소스를 요청하였고, Y 리소스가 이와 연관되어 있다면, 서버는 클라이언트가 Y 리소스를 요청할 때까지 기다리지 않고 Y 리소스를 X와 함께 '푸시'한다. 이를 Server Push라고 부른다.
클라이언트는 푸시된 리소스를 다른 페이지에 사용 가능하며, 서버가 푸시한 리소스에 우선 순위를 둘 수 있고, 클라이언트가 푸시된 리소스를 거절하거나 서버 푸시 전체를 비활성화할 수 있다.
파이프라인 개념은 기존 소프트웨어와 최신 소프트웨어가 공존하는 상황에서 구현하기 어렵다는게 입증(어떻게?왜?)
출처
MDN - HTTP 개요
MDN - HTTP 진화
HTTP/2: the difference between HTTP/1.1, benefits and how to use it
