
2020년은 나에게 특별한 한 해였다. 올해 나는 개발을 처음 배웠고, 동시에 개발자 타이틀로 첫 경력을 시작했다. 주니어 개발자로서 경험한 개발 문화는 다른 직종과는 다른 특별함이 있다. 자신이 갖고 있는 정보들을 남들과 공유하는 것이 자연스럽고, 사람을 뽑을때도 당장 완벽하지 않더라도 성장 가능성이 있는가를 중요하게 여긴다. 기업에서 주최하는 테크 컨퍼런스도 이러한 개발 문화를 경험할 수 있는 좋은 방법이 될 수 있다.
올해는 카카오, 네이버, 쿠팡의 컨퍼런스에 온라인으로 참석했다. 어려운 용어의 등장과, 생소한 주제로 이해할 수 없는 세션도 많았지만 각 기업에서 제공하는 개발문화 관련 또는 주니어를 위한 세션에서 많은 도전을 받을 수 있었다. 디자이너 출신의, 주니어 FE 개발자인 나의 수준에서 이해하기 적당하고 도움이 된 세션들을 큐레이팅하고 간단하게 기록해보고자 한다. (링크를 걸어둘테니 직접 보시는걸 추천합니다!)
🦁 카카오의 if(kakao)2020

작년까지는 개발 컨퍼런스였던 카카오의 if kakao가 올해는 서비스, 비지니스까지 그 영역을 확장하여 개최되었다. 올해 컨퍼런스는 비대면, 온라인으로 진행이 되었다. 각 세션도 10-20분으로 구성되어있어 이동하는 시간에 틈틈이 볼 수 있어서 좋았고, 카카오의 채용 관련 세션, 주니어 개발자 브이로그와 같이 말랑말랑한 콘텐츠도 많아서 또래에게도 많이 배울 수 있었다.
다양한 세션이 마련되었고, 개인의 관심사에 따라 필터링하여 세션들을 골라 볼 수 있게 디자인되었다. 수많은 키워드 중에서 내가 선택한 관심 키워드는 웹/프론트엔드, 개발문화 이다.
개발문화 1. 신입으로 입사하기 vs 인턴으로 입사하기
#개발문화 #기술 #클라우드
정식 블라인드 공채로 들어온 Peny와 2개월의 인턴 경험 후 입사한 Uzu의 인터뷰. 두 분 모두 카카오 클라우드 플랫폼 디벨로퍼로 일하고 있다. 카카오 클라우드팀은 카카오톡, 카카오네비, 카카오페이, 다음 등 서비스를 지탱하는 역할을 한다!
-
클라우드 플랫폼 파트에서는 모두가 프론트엔드, 백엔드를 하기 때문에 처음 입사하면 공부해야할 것이 정말 정말 많다. 다만 엄청나게 성장할 수 있다!
-
B2B 서비스이다보니 실사용자에게 얻는 피드백이 없다. (개인의 성향에 따라 B2B 또는 B2C 서비스를 선택하는 것이 중요할 것 같다!)
-
공채의 경우 코딩테스트, 면접을 보고 들어오는데 굉장히 전형이 빠르게 진행된다. 공채는 동기가 있다는 점, 온보딩이 잘 되어있다는 점이 좋다. 온보딩 기간은 2달이었다.
-
인턴은 공채보다 전형이 단순하다. 서버, 클라이언트, 인프라, 데이터사이언스 따로 서류를 모집하고, 코딩테스트를 본다. 이후 기술 면접을 보고 붙으면 2달 동안 인턴을 진행, 마지막으로 전환 면접을 보게 된다. (인턴 기간은 정말 피말린다. 똑같은 크루로 대해주지만 인턴 전형의 어쩔 수 없는 한계로 경쟁해야하기 때문이다.)
-
수평적으로 일하는 문화로 인해 큰 회사의 하나의 톱니바퀴가 아니라 주체적으로 일하는 작고 귀여운 개발자라는 생각이 든다. (ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ)
-
물고기를 잡아주지 않고 잡는 법을 알려준다. 주변에서 알려주시는 분들이 많은데, 내가 삽질해야 할 부분은 마련해주면서 스스로 헤쳐나갈 수 있도록 도와준다. 최고의 복지는 좋은 동료다!
개발문화 2. 주니어 개발자가 말하는 카카오 FE팀
#개발문화 #기술 #웹/프론트엔드
각 연차별로 회사에서 요구하는 모습이 있을까요?
1년 차
적절한 난이도의 일이 주어지고 그런 일들을 수행하면서 파트에서 1인분을 할 수 있는 역량을 빠르게 키우는게 요구된다. 선배의 이야기도 듣고 스스로 개발을 하면서 본인의 코딩 스타일이나 아키텍쳐 설계를 정립하는 시기라고 생각한다. 이러한 요구사항을 충족하기 위해서 업무를 받았을때 책임감 있게 하자 그 이상으로 좋아하고 제대로 파보자는 생각으로 접근한다.
2년 차
혼자서 일을 시작하고 끝낼 수 있어야 한다고 생각한다. 1년 차 까지는 혼자 프로젝트를 진행하는 일은 거의 없는데 2년차가 되면 프로젝트 세팅부터 개발, 배포까지 혼자서도 할 수 있는 역량을 기르게 한다. 이를 위해서 개발 블로그라던지 오픈 소스라던지 자료를 많이 찾아보게 된다.
시니어
개발을 하더라도 프로젝트 리딩 업무를 맡긴다던지, 채용 프로세스에 기여하는 등 회사의 운영과 관련된 것에도 업무가 내려온다. 따라서 생산성에 더 가치를 두게 된다. 하루에 얼마나 일을 했고 어느 정도 시간이 걸렸는지를 꼼꼼하게 체크하게 되었다.
카카오의 어떤 점이 성장에 도움이 되나요?
-
수평적이고 격의 없는 분위기. 주니어 개발자가 생각한 아이디어라고 해서 대충 듣는 일이 없고 선배 개발자들도 모르는게 있으면 거리낌 없이 물어보곤 한다. 새로운 기술을 써보고 싶을때 반대 없이 써보고 피드백 해주세요 하는 식으로 가볍게 넘어간다.
-
사내 스터디가 역량 향상에 도움이 된다. 간혹 자발적으로 몇 분이 모여서 팀 스터디를 진행하는데 타입스크립트와 관련된 스터디를 했었고, 그 이후로는 다 잘 익혀서 타입스크립트로 된 프로젝트를 진행하고 있기도 하다. 혼자서 공부하는 것 보다는 팀 내에 지식 공유도 되고 다른 분들의 생각을 알 수 있어서 좋았다.
-
사내 위키나 아지트와 같이 개발자들이 자료를 찾을 수 있는 사이트가 있는데, 해당 사이트에 본인이 공부한 내용이나 문제를 어떻게 해결했는지에 관한 글들이 많은데 실제 업무에 많은 도움이 된다.
후배 개발자들에게 해주고 싶은 말이 있나요?
1년 차
FE 개발 말고 또 다른 개발을 한 번쯤은 도전해보고 오면 좋다고 생각한다. 안드로이드나 iOS 개발 경험을 언젠가는 해야지 생각은 했지만 입사를 해서 업무를 하다보면 시간이 많이 없다. 입사 전에 다양한 분야를 한번씩 개발을 해보면 FE 개발에서도 인사이트가 생기고 자신에게 맞는 개발이 뭔지 정립할 수 있다.
2년 차
1년 차에 주눅들어있는 경향이 있었다. 질문도 안하고 혼자 문제를 해결하려고 애썼는데, 질문도 많이 하고 본인 의견도 적극적으로 내는 모습이 필요하다. 카카오는 수평적인 문화이기 때문에 실제로 신입개발자가 의견을 내도 가볍게 여기는 분들은 없다.
3년 차
(대학생 때는) 방학도 있고 빡세게 공부하는 시험기간도 있고 동아리와 개발 컨퍼런스에서 새로운 사람들도 만나고 새로운 환경에 노출될 경우가 많았는데, 회사에 있으면 프로젝트를 계속 하기 때문에 쳇바퀴를 도는 느낌을 받는다. 몸과 마음이 좀 지칠때 어떻게 자신을 리프레쉬할지, 취미나 새로운 사람을 만나는 장소를 찾아가는 등의 방법을 찾는게 중요하다.
기술 1. 두통 없는 비동기 I/O 처리를 위한 Redux-Saga 활용기
#기술 #웹/프론트엔드
발표자 Jenny는 그라운드X에서 카카오톡 더보기란의 서비스 클립을 개발하는 프론트엔드 개발자이다. 블록체인의 NFT(Non-fungible Token)을 웹으로 보여주며 프론트 개발자로서 부딪혔던 문제, 그리고 redux-saga로 해결한 사례를 소개한다.
카드가 발급되는 과정, 카드를 발급하는 주체인 서비스사에서 smart contract를 발급하면 이 정보가 블록체인에 담긴다. 해당 정보는 그라운드X의 자체 블록체인인 Klaytn에 담기게 된다. 이때 클립의 역할은 Klaytn에 있는 카드 정보를 보여주는 것이다. 블록체인의 특성상 용량이 큰 이미지나 장문의 글을 저장하는 것은 네트워크에 부담이 될 수 있고 이는 높은 비용으로 이어진다.
따라서 카드 정보를 저장할때는 기본정보와 속성정보를 분리해서 저장하는 방식을 택한다. 기본정보(받은 시간, 받은 사람의 정보 정도)는 블록체인에, 속성정보(이미지, 장문의 글)는 개발사에서 따로 관리하는 저장소(S3)에 따로 저장되는 방식이다. 이때 속성정보에 대한 URI는 기본정보에 담기게 된다. 따라서 웹에서 두 정보를 받아오기 위해서는 기본정보에서 tokenURI를 받아오고 이를 바탕으로 속성정보를 다시 요청해서 받아와야 하기 때문에 위 정보들이 순차적으로 처리되어야 한다.
문제는 여러 카드 정보를 동시에 리스트 형식으로 보여주는 상황이다. 각 기본정보를 동시에 호출하는 것은 API로 가능했지만, 기본정보에 담긴 URI로 각 카드와 관련된 여러 개의 개별 저장소에 각각 카드 속성정보를 요청하게 된다. 문제는 각 저장소는 카드를 발급해준 서비스사들이 관리하고 있다는 점이다. 때문에 클립 FE 입장에서는 각 저장소의 상황이 어떤지, 시간이 얼마나 걸리는지는 전혀 알 수 없다. 다양한 에러 상황에 대한 예외처리도 필요했고 사용자가 빈 화면을 보지 않게끔 가장 먼저 응답이 오는 카드부터 화면에 노출시켜야 했다. 이렇게 카드 목록에서는 동기, 비동기 코드가 뒤섞여있고 개별 요청 결과에 대한 컨트롤이 필요해졌다.
방법 1 ) Promise
for문도 등장하고 코드가 복잡해지고 가독성이 떨어진다.
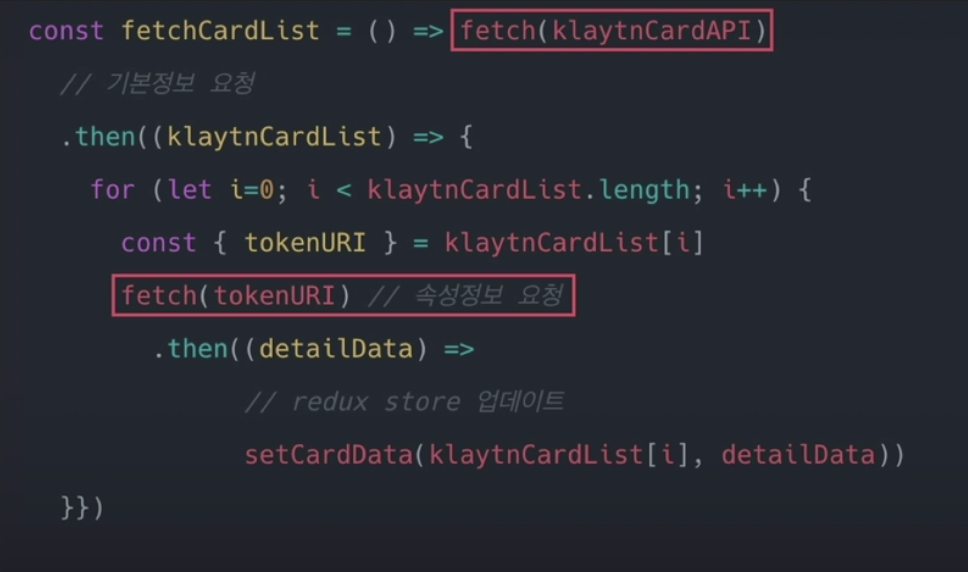
방법 2 ) Async / Await
한결 코드가 깔끔해졌다. 어디서 무슨 요청을 보내는지 한눈에 확인이 가능하다. 비동기지만 동기처럼 차근차근 읽을 수 있다.
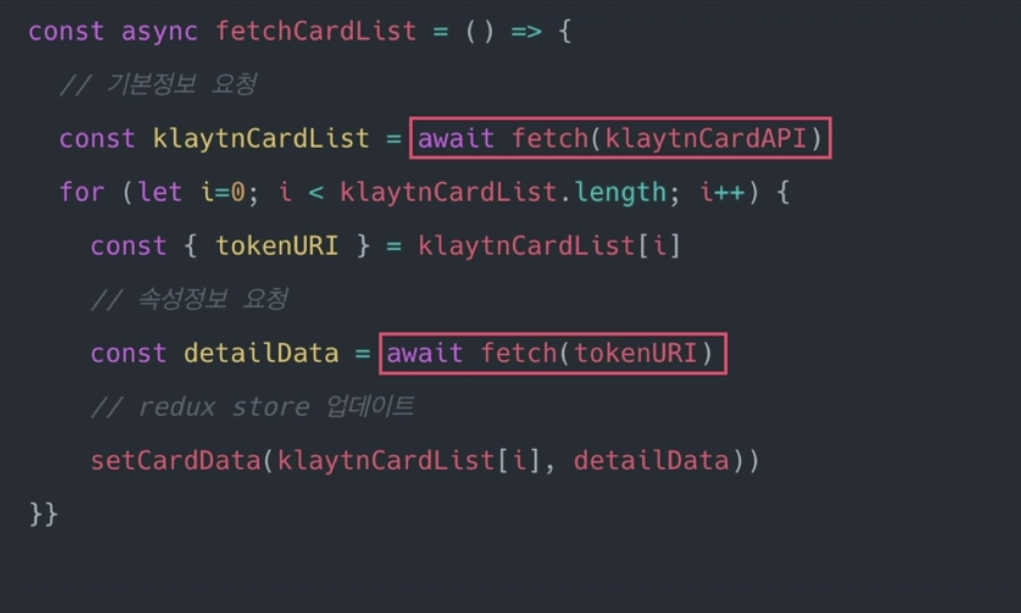
redux-saga?
프로젝트에서 리덕스를 사용하고 있다면 비동기처리를 위해 함께 사용할 수 있는 미들웨어이다. 복잡한 비동기 작업을 쉽게 쓰고 쉽게 테스트할 수 있도록 만들어졌다.
redux-saga의 문법 네 가지
import { select, call, put, take } from 'redux-saga/effects';
function* saga() {
const id = yield select(getID) // redux에서 값 가져오기
const result = yield call(fetchData, id) // api 호출하기
yield put(result) // 응답값 redux에 없데이트하기
}
function* watchSaga() {
take('GET_DATA_ACTION', saga) // GET_DATA_ACTION 기다리기
}select: 리덕스 저장소에서 값을 가져올때 사용한다.call: API 요청 등 비동기 함수를 실행할때 사용한다.put: 리덕스 저장소에 값을 업데이트할 때 액션을 dispatch 할 수 있다.take: 리덕스 액션을 구독하고 있다가 관련 액션이 발생하면 saga를 실행하는 함수이다.
다중 비동기 요청과 관련된 fork/spawn
for (let i=0; i < klaytnCardList.length; i++) {
const { tokenURI } = klaytnCardList[i]
yield fork/spawn(fetch, tokenURI)
}10가지의 자녀 요청을 보낸 뒤에 진행해야하는 작업이 있다고 치면, fork는 10개의 작업이 모두 응답이 온 뒤에 나머지 코드를 실행시키고, spawn은 요청을 보냈다는데에 의의를 두고 나머지 코드를 실행시킨다.
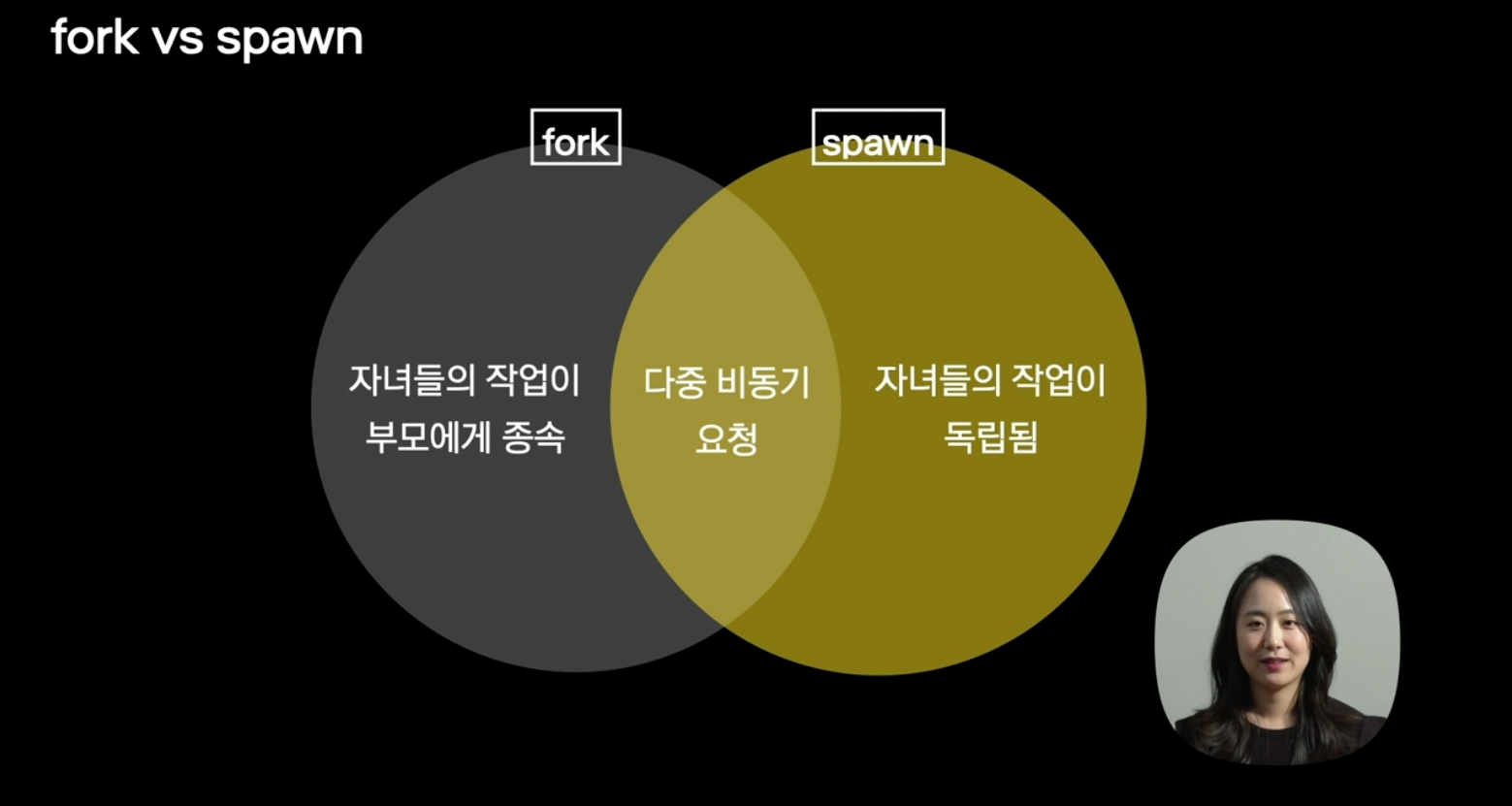
fork
for (let i=0; i < klaytnCardList.length; i++) {
yield fork(fetchAndLog, tokenURI, i);
}
console.log('DONE');
// 모든 응답의 log가 온 뒤에 'DONE'이 찍힌다.spawn
for (let i=0; i < klaytnCardList.length; i++) {
yield spawn(fetchAndLog, tokenURI, i);
}
console.log('DONE');
// 'DONE'이 먼저 찍히고 이후에 자녀들의 응답 log 나타난다.
// spawn은 자녀들의 결과에 대해 책임지지 않는다.위 두가지 문법을 활용해서, 에러 처리 또한 부모 단위에서 관리할지, 자녀 단위에서 관리할지도 제어할 수 있다. redux-saga로 미세한 비동기 처리도 가능하다는 것을 알 수 있다.
문제 해결 코드
function* fetchCardList() {
// 기본정보 요청
const klaytnCardList = yield call(fetch, klaytnCardAPI)
for (let i=0; i < klaytnCardList.length; i++) {
const { tokenURI } = klaytnCardList[i]
// 속성정보 요청
const detailData = yield fork(fetch, tokenURI)
// 응답값 redux에 업데이트 하기
yield put(klaytnCardList[i], detailData)
}
}
function* watchSaga() {
// GET_CARDS_ACTION 기다리기
take('GET_CARDS_ACTION', fetchCardList)
}기술 2. 콘텐츠를 위해 FE 개발자가 설계한 공통 데이터 모델과 활용
#기술 #웹/프론트엔드 #데이터
이 세션에서 나오는 공통 데이터 모델은 현재 나도 사용하고 있던 방식이어서 깜짝 놀랐다. 작업을 이어서 했기에 그대로 따라했을 뿐이었는데, 이래서 JSON 형태로 모든 데이터를 활용했던거구나 세션을 보고 나서야 깨달을 수 있었던...! 💥💥💥
공통 데이터 모델이란?
콘텐츠를 표현할 수 있는 각각의 요소와 속성들을 하나의 형태의 데이터로 체계화하고, 이 데이터를 통해 각 플랫폼의 에디터와 글뷰에서 손쉽게 사용하기 위해 만든 데이터 구조
왜 만들어야 했나?
HTML도 있는데 왜 사용할까? 모든 플랫폼에서 콘텐츠를 잘 만들고 잘 보여주기 위함이다. HTML은 웹에서 콘텐츠를 잘 보여주기 위한 언어이지만 우리는 다른 플랫폼에서는 그렇지 않다. 웹 이외에 다른 플랫폼(안드로이드, iOS)에서도 잘 보여주기 위해서이다. 따라서 플랫폼 간의 원할한 데이터 전환과 전달이 필요해졌다. 각 플랫폼 간의 전환이 용이하고, 가볍고, 보기편한 데이터 포맷을 고민했다. 그 결과 JSON 형태를 선택하게 되었다. 수많은 플랫폼에서도 쉽게 찾아볼 수 있어 전환에 용이하다고 생각했다.

-
공통 데이터 모델은 각 데이터 간에 독립적인 성질을 가지고 있기 때문에 새로운 타입의 요소가 추가되더라도 다른 요소에 영향을 주지 않고 새롭게 확장된 콘텐츠를 만들 수 있다.
-
공통 데이터 모델에 새로운 타입의 요소가 추가되거나 수정될 때 공통 데이터 모델이 업데이트되면 기존의 콘텐츠와 새로운 콘텐츠를 구분하는 버전 정보가 필요하게 되었고, 이를 전환 할 수 있는 규칙이 필요해졌다.
공통 데이터 모델의 활용
에디터에서 공통 데이터 모델로 작성된 콘텐츠를 편집한다고 가정해보자. 편집된 컨텐츠를 각 에디터로 전달하면 에디터는 최적화된 형태로 데이터를 변경해 원할한 편집 환경을 만들어 사용자에게 제공한다. 즉 웹 에디터는 HTML로, 앱 에디터는 App Data로 변형되는 것이다. 이 편집 환경을 만들때 브라우저, OS 등에 따른 조건으로 예외처리도 쉽게 할 수 있게 된다. 편집이 마무리되면 공통 데이터로 만들어진 데이터를 내보냄으로서 편집 과정을 마무리하게 된다.
작성된 콘텐츠 버전에 따른 변환 규칙과 예외처리
(상황 1) 에디터 버전이 편집할 콘텐츠 버전보다 높을 때
이러한 경우 버전 1.0의 콘텐츠는 버전 2.0으로 무리없이 변환되어 저장된다. 버전 2.0의 정보를 해석할 수 있는 에디터는 하위 버전의 정보도 담고 있기 때문이다.
(상황 2) 편집할 콘텐츠 버전이 에디터보다 높을 때
콘텐츠는 2.0이고 에디터는 업데이트 하지 않은 예전 1.0인 경우 읽을 수 없는 콘텐츠로 인식하고 사용자에게 업데이트 권유와 같은 적절한 noti를 주게 된다.
공통 데이터 모델의 글뷰 활용
서비스에 따라 데이터를 보여주는 스타일 방식이 달라지게 하는 방식이다. 예를 들어 A 서비스 에서는 글자 크기는 PT로하고 이미지는 가득차게 하지만, 같은 공통 데이터 모델을 B 서비스에서는 글자는 EM단위로 이미지는 여백이 있게 표현하길 원한다고 가정해보자.
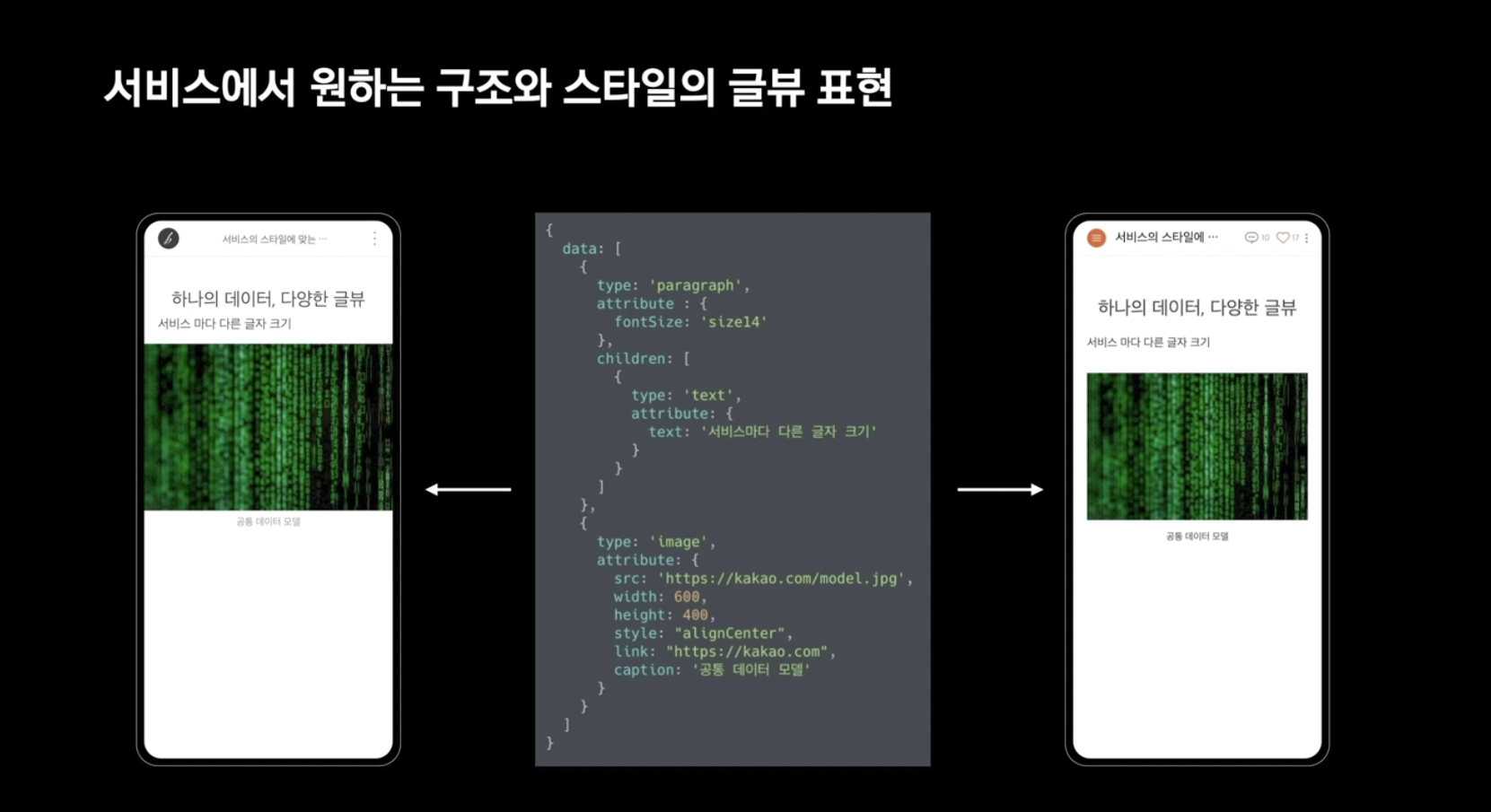
위 사진을 보면 세세한 스타일은 다르지만 큰 차이는 느껴지지 않는다. 각 서비스의 HTML 코드를 보면 확실히 구조가 다르고 css도 차이가 있다는 것을 알 수 있다. 기능적인 부분(반응형)에서도 차이가 있을 수 있는데, 공통 데이터 모델로 같은 데이터지만 무리 없이 다른 형태로 보여줄 수 있었던 것이다. 이는 다른 플랫폼에서도 마찬가지로 적용된다.
기술 3. 유한상태기계로 밀려드는 프로모션 감당하기
#기술 #웹/프론트엔드 #백엔드
정리는 생략하지만 프론트로서 봐도 너무너무 감명 깊은 세션이었다. 12분이 채 안되는 짧은 세션이니, 프로모션 지옥에 빠진 개발자분들은 꼭 영상 보시길 바랍니다!!!
후기
역시 🌟갓카오🌟인가 싶었던 컨퍼런스였다..! 요즘 유행하는 성향 테스트 형식의 이벤트(방구석 개발자 레벨 테스트)를 마련해서 재미도 잡고, 78개의 방대한 양의 토픽이 마련되었음에도 My List와 필터 기능으로 사용자 편의성도 높였다. 서비스, 비즈니스 관련 세션도 준비되어있어 다양한 IT 기업 종사자를 대상으로 하기도 했다. 다른 컨퍼런스들과 달리 시간에 맞춰 라이브로 세션을 진행하는 것이 아니라 각 날짜에 맞는 동영상 세션을 공개했는데, 이 점이 딱 원하는 영상만 원하는 시간에 시청할 수 있게 해서 진짜 좋았다! 세션도 10-20분으로 짧게 마련되어 지루할 즈음 딱 세션이 끝났다. ㅎㅎ 역시 유엑스의 강자 카카오..
열심히 성장해서 내년 if(kakao)2021에서는 더 많은 세션을 이해할 수 있으면 좋겠다. 주니어 개발자를 위한 3대 컨퍼런스 요약정리 2탄, 네이버의 DEVIEW 2020으로 돌아오겠습니다-! To be continued ! ❛˓◞˂̵✧ (찡끗 - )




Thanks a lot for sharing!JOKER123