개요
- 주제 : 에이블스쿨 지원자를 위한 QA 챗봇 만들기
- 데이터 : 에이블스쿨 홈페이지 Q&A, 조별 데이터 수집
- 데이터 출처 : 에이블스쿨
- 데이터구분 : TEXT 데이터
중점사항 :
- text 데이터를 vector DB로 만들기
- GPT 3.5 버전과 연계한 RAG 챗봇 모델 생성
- 웹 서버와 서비스 구현
요구사항
- AI모델 : LLM, RAG 기반 챗봇 모델
- H/W : 클라우드 웹 서버
- DB : 벡터DB on SQLite3
- S/W : 장고 웹 프레임워크
1. 요구사항
1. 데이터 수집
- 기본 에이블스쿨 홈페이지 Q&A
- 홈페이지에 등록되어 있는 FAQ 데이터를 수집하여 데이터셋으로 구성
- 질문과 답변을 하나의 chunk로 구성
- 데이터 추가 수집
- 에이블러들의 블로그 글, 의견 등
- 지원자들에게 소개하는 글 안에 담긴 내용을 chunk로 구성
- DB 구성
- RAG 용 Vector DB
- 사용 기록 DB
2. 기능 요구사항 1 : 질문 답변 기능
1) OpenAI 모델 사용
2) Vector DB를 Retriever로 이용
3) 단발성 질문 답변
질문 답변 기능
- 1) 대화가 이어지도록 구성
- 2) 정확한 답변을 하기 위한 다양한 시도
2. 가상환경 준비 및 OpenAPI 연결
1. 가상환경 만들기
1.1 새로운 가상환경 만들기
VS Code에서 폴더 선택:
C:\Users\<여러분ID>\mini7터미널에서 Command Prompt 추가
가상환경 생성:
conda create -n qa_system python=3.11
- 가상환경 확인:
conda env list
- 가상환경 활성화:
conda activate qa_system
1.2 필요 라이브러리 설치
- requirements.txt 파일을 이용해 라이브러리 설치:
pip install -r requirements.txt
1.3 Jupyter Notebook에 가상환경(커널) 연결
- Jupyter Notebook 파일 열기
- 오른쪽 위 [커널선택] 버튼 클릭
- 새로 생성한 가상환경 선택
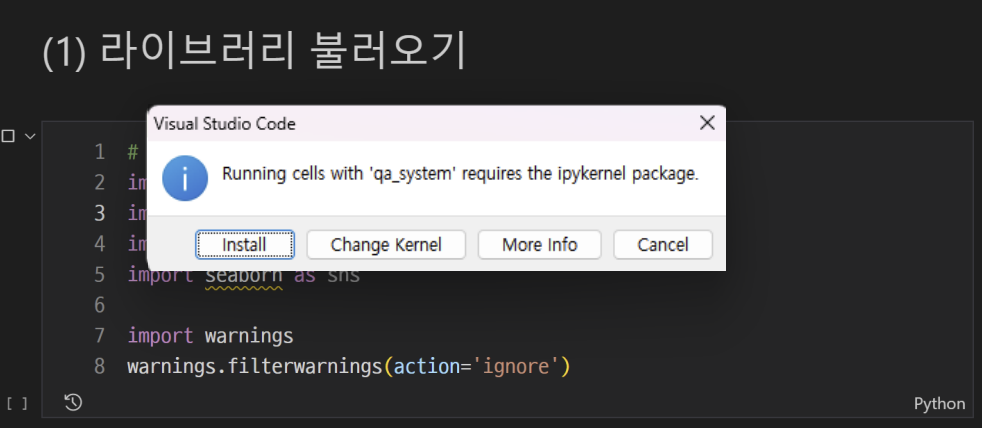
- 첫 번째 코드 셀 실행: Ipykernel package 설치
1.4 가상환경 삭제
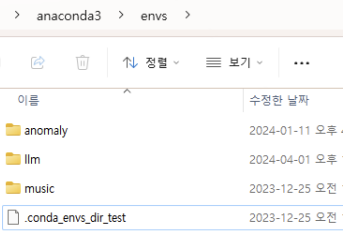
- 삭제 방법:
- 자신의 아이디 > anaconda3 > envs 폴더로 이동
- 삭제할 가상환경 폴더 삭제
2. OpenAI API 키 발급받기
2.1 API 키 생성
- OpenAI 접속 > 로그인 > API 선택
- API Key 생성:
- 이름은 원하는 대로 입력하고, 키 생성 버튼 클릭
- API 키 복사 후 따로 저장 (잊어버리면 다시 발급 필요)
3. OpenAI API 키 환경변수 등록하기
3.1 Windows에서 환경변수 등록
- '시작' 메뉴에서 '시스템 환경 변수 편집' 검색 및 선택
- '환경 변수' 버튼 클릭
- '새로 만들기' 클릭
- 변수 이름:
OPENAI_API_KEY- 변수 값: 여러분의 OpenAI API 키
- 확인 클릭하여 저장
3.2 파이썬 코드에서 환경 변수 확인
import os import openai api_key = os.getenv('OPENAI_API_KEY') print(api_key)
3.3 코드에서 직접 API 키 설정 (환경변수 설정이 잘 안될 경우)
import os import openai os.environ['OPENAI_API_KEY'] = '여러분의 OpenAI API키' openai.api_key = os.getenv('OPENAI_API_KEY')
- 이 방법은 운영체제에 상관없이 파이썬 코드에서 동일하게 작동
- 파이썬 프로그램이 실행되는 동안에만 환경 변수가 설정됨
- 프로그램이 종료되면 설정한 환경 변수는 사라짐
- 코드에 API 키를 저장하므로 보안 노출 위험 있음
- 이 정리된 단계를 따라가면 가상환경 설정 및 OpenAI API 연결을 쉽게 할 수 있을 것입니다.
3. RAG + LLM 모델 만들기
1. API 란?
- API (Application Programming Interface)는 소프트웨어 간에 데이터를 교환하고 통신할 수 있도록 하는 인터페이스를 제공합니다.
- API는 클라이언트와 서버 간의 통신을 중재하여 데이터를 요청하고 응답받는 구조로 작동합니다.
API 작동 원리
- 클라이언트 프로그램이 요청을 보냄
- 예: Jupyter Notebook, Web Browser, Database, AI Service
- 서버 프로그램이 요청을 처리
- 서버는 클라이언트로부터 받은 요청을 처리하여 결과 데이터를 생성
- API가 결과 데이터를 클라이언트로 전달
- 서버가 처리한 결과 데이터를 API를 통해 클라이언트로 전달
- 클라이언트 프로그램이 응답을 받음
1-1. API 사용
Request
- API 주소 + API Key
- API를 호출하기 위해 필요한 주소와 인증키(API Key)
- Request 형식 (요청 양식)
- 요청 데이터의 구조 및 형식 (예: JSON, XML)
Response
- Response 형식 (결과 양식)
- 응답 데이터의 구조 및 형식 (예: JSON, XML)
2. LangChain이란?
- LangChain은 대규모 언어 모델(LLMs)을 활용하여 체인을 구성하고, 이를 통해 복잡한 작업을 자동화하고 쉽게 수행할 수 있도록 돕는 라이브러리입니다.
3. RAG (Retrieval Augmented Generation)
- LLM을 통한 답변 생성
- LLM 모델: 학습하지 않은 내용은 모름
- LLM with RAG:
- 사용자 질문을 받음
- 준비된 정보 DB에서 답변에 필요한 문서 검색
- 필요한 문서를 포함한 프롬프트 생성
- LLM이 답변 생성
준비된 정보 DB와 LLM with RAG 절차
- Vector DB: 대규모 텍스트 데이터 및 임베딩 벡터를 저장하고 검색하는 데 사용
- Chroma DB: Vector DB로 사용
4. Vector DB 구축 절차 및 대화형 시스템 설계
Vector DB 구축 절차 (Chroma DB)
- 텍스트 추출 (Document Loader)
- 다양한 문서 (Word, PDF, Web Page 등)로부터 텍스트 추출
- 텍스트 분할 (Text Splitter)
- 추출된 텍스트를 chunk 단위로 분할
- 분할된 텍스트를 Document 객체로 변환
- 텍스트 벡터화 (Text Embedding)
- 텍스트 데이터를 벡터화
- Vector DB로 저장 (Vector Store)
- 벡터화된 데이터를 Chroma DB에 저장
5. Chroma DB
- SQLite3 기반의 Vector DB
- DB Browser for SQLite3로 접속 가능
절차
- 임베딩 모델 지정
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
- Chroma DB 선언 및 경로 지정
database = Chroma(persist_directory="./db", embedding_function=embeddings)
- 해당 경로에 DB가 있으면 연결, 없으면 새로 생성
Memory
- 대화의 맥락을 유지하기 위해 이전 대화를 기억하고 현재 대화에 반영
Chain
- 각 모듈 (LLM 모델, Retriever, Memory)을 연결
ConversationalRetrievalChain 함수
- return_source_documents=True
- 답변과 함께 출처 문서도 반환
- Output_key
- 모델 출력이 저장될 키를 지정
qa = ConversationalRetrievalChain.from_llm(llm=chat, retriever=retriever, memory=memory, return_source_documents=True, output_key="answer")
6. Chain 함수의 Memory 설정
- memory_key
- 메모리에서 대화 기록 저장을 위한 키 (대화 내역 저장 및 불러오기)
- input_key
- 사용자 입력 (질문) 키 (사용자의 질문이 메모리에 저장)
- output_key
- 모델의 출력 키 (모델의 답변이 메모리에 저장)
- return_messages = True
- 메모리에 저장된 대화 내역이 메시지 형식으로 반환
memory = ConversationBufferMemory(memory_key="chat_history", input_key="question", output_key="answer", return_messages=True)
4. 실전 챗봇 만들기
- 환경준비
- OpenAI API Key 확인 및 Vector DB 만들기
- RAG + LLM 모델 확인
import pandas as pd
import os
import warnings
import openai
from langchain.chat_models import ChatOpenAI
from langchain.schema import Document
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
warnings.filterwarnings("ignore", category=DeprecationWarning)
# 1. 환경 준비
# 환경변수에서 OpenAI API 키 불러오기
api_key = os.getenv('OPENAI_API_KEY')
openai.api_key = api_key
# 데이터 불러오기
data = pd.read_csv('aivleschool_qa.csv', encoding='utf-8')
print(data.head())
# 2. OpenAI API Key 확인 및 Vector DB 만들기
# Embeddings 생성
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# Vector DB 생성 및 문서 추가
database = Chroma(persist_directory="./db", embedding_function=embeddings)
documents = [Document(page_content=text) for text in data['QA']]
database.add_documents(documents)
# 3. RAG + LLM 모델 확인
# 문서 조회 : 유사도 점수도 함께 조회
query = "지원 자격은 어떻게 돼?" # 질문할 문장
k = 3 # 유사도 상위 k 개 문서 가져오기
result = database.similarity_search_with_score(query, k=k)
# 유사도 점수와 문서 내용 출력
print(result)
print('-' * 50)
for doc in result:
print(f"유사도 점수 : {round(doc[1], 5)}, 문서 내용: {doc[0].page_content}")
# Chat 모델 설정
chat = ChatOpenAI(model="gpt-3.5-turbo")
# RetrievalQA 생성
retriever = database.as_retriever()
qa = RetrievalQA.from_llm(llm=chat, retriever=retriever, return_source_documents=True)
# 질문에 대한 답변 얻기
result = qa(query)
print(result["result"])
print(result)주요 포인트
- 환경 준비: 필요한 패키지를 임포트하고, API 키를 환경변수에서 가져옵니다.
- 데이터 불러오기: 챗봇에 사용할 데이터를
pandas를 이용하여 불러옵니다.- 벡터 DB 생성:
langchain라이브러리를 사용하여 벡터 데이터베이스를 생성하고, 데이터를 추가합니다.- 유사도 검색 및 결과 출력: 질문(query)에 대한 유사도 검색을 수행하고, 결과를 출력합니다.
- RetrievalQA 사용:
RetrievalQA체인을 이용하여 질문에 대한 답변을 생성합니다.
이 코드는 데이터베이스에 저장된 문서와 질문의 유사도를 계산하고, 가장 유사한 문서들을 기반으로 질문에 대한 답변을 생성합니다.

안녕하세요. wony입니다.