0. 개요 및 전처리
- 주제 : 머신러닝. 머신러닝의 전체 과정의 코드 실습
- 내용 :머신러닝의 전반적인 개념 및 관련 용어, 회귀와 분류 구분
1) 결측치 처리
# 결측치 처리
data.isnull().sum()
# 전날 값으로 결측치 채우기
data.fillna(method = 'ffill', inplace = True)
data.isnull().sum()2) 변수 제거
drop_cols = ['Month', 'Day']
drop_cols.drop(drop_cols, axis = 1, inplace = True)3) x,y 분리
# target 확인
target = 'Ozone'
# 데이터 분리
x = data.drop(target, axis= 1)
y = data.loc[:,target]4) 학습용, 평가용 데이터 분리
# 모듈 불러오기
from sklearn.model_selection import train_test_split
# 7:3으로 분리
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1)5) 모델링(뒤에 전체 코드 있음)
1. 머신러닝 (Machine Learning)
- 알고리즘을 이용하여 데이터를 분석하고, 분석 결과를 스스로 학습 한 후 이를 기반으로 어떠한 판단이나 예측을 하는 것
1) 학습 방법에 따른 분류
지도 학습(Supervised Learning) : 학습 대상이 되는 데이터에 정답을 주어 규칙성, 즉 데이터의 패턴을 배우게 하는 학습 방법
비지도 학습(Unsupervised Learning) : 정답이 없는 데이터 만으로 배우게 하는 학습 방법
강화 학습(Reinforcement Learning) : 선택한 결과에 대해 보상을 받아 행동을 개선하면서 배우게 하는 학습 방법
2) 과제에 대한 분류
분류 문제(Classfication) : 이미 적절히 분류된 데이터를 학습하여 분류 규칙을 찾고, 그 규칙을 기반으로 새롭게 주어진 데이터를 적절히 분류하는 것을 목적으로 함(지도학습)
회귀 문제(Regression) : 이미 결과값이 있는 데이터를 학습하여 입력 값과 결과 값의 연관성을 찾고, 그 연관성을 기반으로 새롭게 주어진 데이터에 대한 값을 예측하는 것을 목적으로 함(지도학습)
클러스터링(Clustering) : 주어진 데이터를 학습하여 적절한 분류 규칙을 찾아 데이터를 분류함을 목적으로 함. 정답이 없으니 성능을 평가 하기 어려움(비지도학습)
⇒ 문류 문제인지 회귀 문제인지를 정확히 파악해야한다.
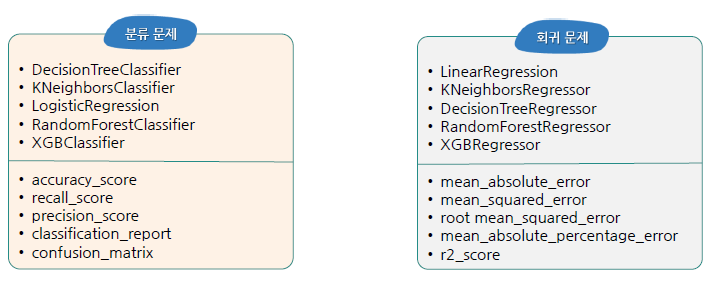
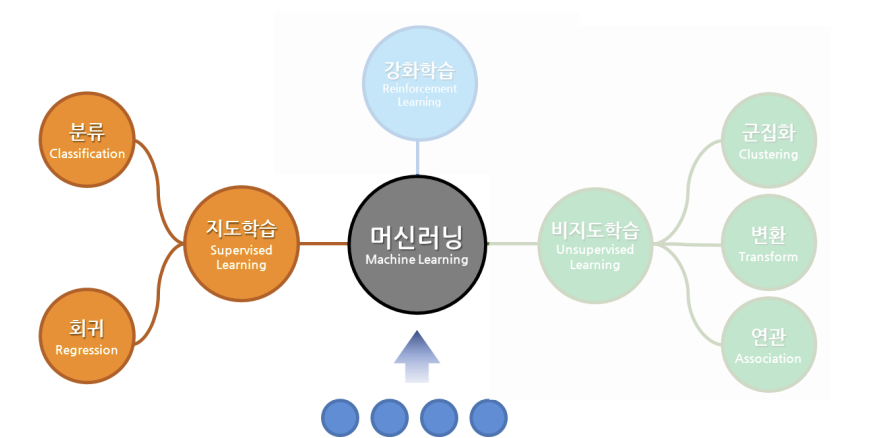
3) 모델링 코드 구조 -> 항상 이걸 생각!
불러오기 - 사용할 라이버리를 import
선언하기 - 사용할 알고리즘을 모델로 선언
학습하기 - 모델.fit(x_train, y_train) 형태로 학습시키기
예측하기 - 모델.predict(x_test) 형태로 예측 값 만들기
평가하기 - 예측 값과 실제 값으로 평가
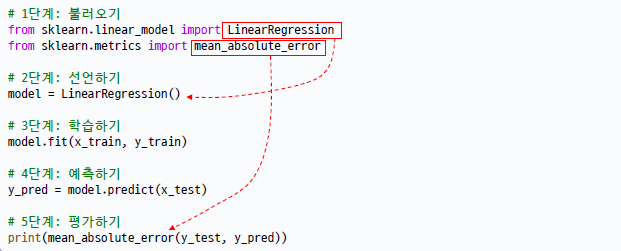
입력
# 데이터 준비
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 데이터 읽어오기
data = pd.read_csv('airquality_simple.csv')
# x, y 분리
target = 'Ozone'
x = data.drop(target, axis=1)
y = data.loc[:, target]
# 학습용, 평가용 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# 모델링
# 1단계: 불러오기
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
# 2단계: 선언하기
model = LinearRegression()
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계: 예측하기
y_pred = model.predict(x_test)
# 5단계: 평가하기
print(mean_absolute_error(y_test, y_pred))
안녕하세요. wony입니다.