0. 개요
주제 : 머신러닝. 머신러닝의 전체 과정의 코드 실습
내용 : 회귀에 대해 이해하고 코드를 작성할 수 있다.
1. 선형회귀 모델링 및 평가
# 1단계: 불러오기
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, r2_score
# 2단계: 선언하기
model = LinearRegression()
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계: 예측하기
y_pred = model.predict(x_test)
# 5단계: 평가하기
print('MAE:', mean_absolute_error(y_test, y_pred))
print('R2-Score:', r2_score(y_test, y_pred))
# 회귀계수 확인
print(model.coef_)
print(model.intercept_)1-1. 회귀식 시각화
# 선형회귀식
a = model.coef_
b = model.intercept_
speed = np.linspace(x_train.min(), x_train.max(), 10)
dist = a * speed + b# 학습용 데이터와 선형회귀선 시각화
plt.scatter(x_train, y_train)
plt.plot(speed, dist, color='r')
plt.xlabel('Speed(mph)')
plt.ylabel('Dist(ft)')
plt.show()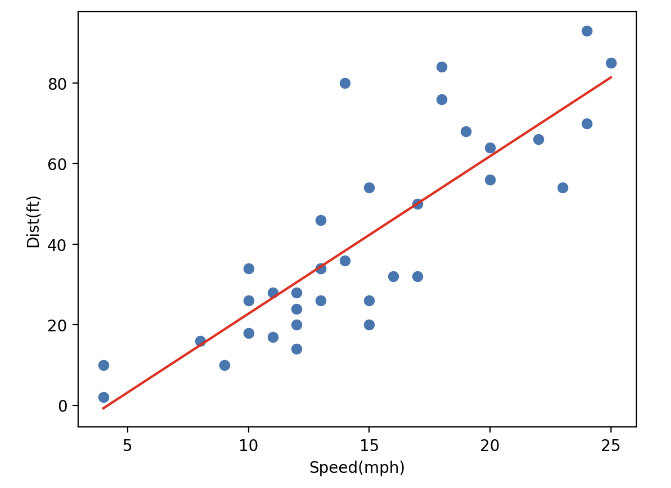
평가용 데이터와 선형 회귀식 시각화
plt.scatter(x_test, y_test)
plt.plot(speed, dist, color='r')
plt.xlabel('Speed(mph)')
plt.ylabel('Dist(ft)')
plt.show()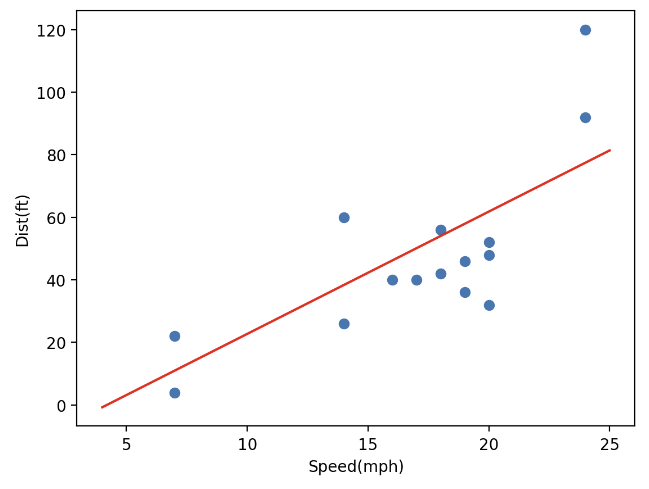
# 예측값, 실젯값 시각화
plt.plot(y_test.values, label='Actual')
plt.plot(y_pred, label='Predicted')
plt.legend()
plt.ylabel('Dist(ft)')
plt.show()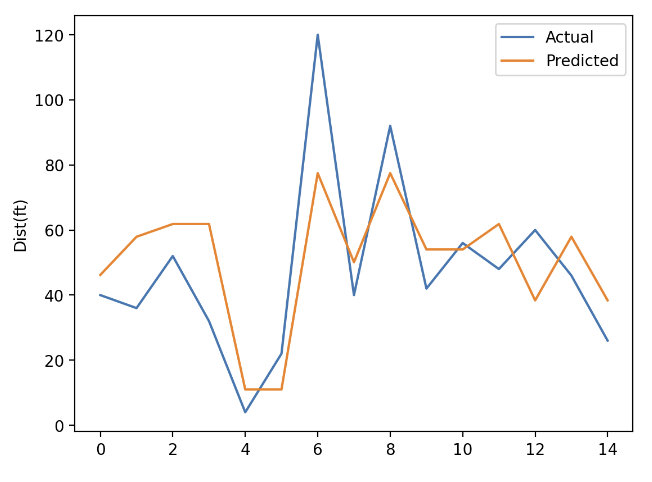
2. KNN 알고리즘
# 데이터 준비
1) 결측치 처리
# data.interpolate(method = 'linear', inplace = True)
# data.isnull().sum()
2) 변수 제거
drop_cols = ['Month', 'Day']
data.drop(drop_cols, axis=1, inplace=True)
# 확인
data.head()
3) x,y 분리
# target 확인
target = 'Ozone'
# 데이터 분리
x = data.drop(target, axis=1)
y = data.loc[:, target]
4) 학습용, 평가용 데이터 분리
# 모듈 불러오기
from sklearn.model_selection import train_test_split
# 데이터 분리
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1)2-1.정규화 - 중요!! KNN은 정규화 필수
방법1.
# 최댓값, 최솟값 구하기
x_max = x_train.max()
x_min = x_train.min()
# 정규화
x_train = (x_train - x_min) / (x_max - x_min)
x_test= (x_test - x_min) / (x_max - x_min)방법2.
# 모듈 불러오기
from sklearn.preprocessing import MinMaxScaler
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_train) # 여기 무조건 x_train
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)2-2. KNN 모델링 및 시각화
# 1단계: 불러오기
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_absolute_error, r2_score
# 2단계: 선언하기
model = KNeighborsRegressor()
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계 예측하기
y_pred = model.predict(x_test)
# 5단계: 평가하기
print('MAE:', mean_absolute_error(y_test, y_pred))
print('R2-Score:', r2_score(y_test, y_pred))
# 모델 복잡도
model = KNeighborsRegressor(n_neighbors=len(x_train))
model.fit(x_train, y_train)
y_pred = model.predict(x_train)
# 시각화
plt.plot(y_train.values, label='Actual')
plt.plot(y_pred, label='Predicted')
plt.legend()
plt.ylabel('Ozone')
plt.show()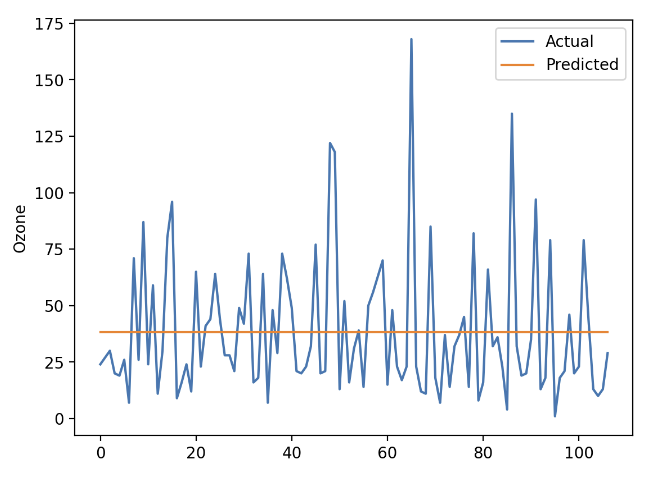

안녕하세요. wony입니다.