0. 개요
주제: 시각지능 딥러닝
내용: 6주차에 한 내용을 notMNIST가지고 분석 후 CNN모델도 적용
1. notMNIST 데이터셋 분석
1) 데이터 및 환경변수 설정
# notMNIST 데이터셋을 사용(!wgt는 url에서 데이터 다운 받을 때 사용) # MATLAB 파일 형식은 MathWorks사의 MATLAB 소프트웨어에서 사용되는 데이터 파일 형식입니다. # 일반적으로 .mat 확장자를 가지며, MATLAB에서 생성된 데이터를 저장하고 전송하기 위해 사용 !wget http://yaroslavvb.com/upload/notMNIST/notMNIST_small.mat import numpy as np import matplotlib.pyplot as plt from scipy import io
2) 데이터 로딩
- x = data['images']와 y = data['labels']는 로드된 MATLAB 파일에서 이미지 데이터와 해당 이미지의 레이블을 가져와 변수에 할당하는 것입니다.
- 일반적으로 이러한 형태의 데이터를 다룰 때, 이미지 데이터는 x에, 이미지에 대응하는 레이블은 y에 할당합니다. 이것은 일반적인 머신러닝 및 딥러닝 모델의 학습 및 평가를 위해 사용되는 표준적인 방법입니다.
- 이렇게 데이터를 구성하면 모델이 입력 데이터와 레이블 간의 관계를 학습할 수 있습니다.
data = io.loadmat('notMNIST_small.mat') data x = data['images'] y = data['labels'] x.shape, y.shape
- 실행결과 : ((28, 28, 18724), (18724,))
- x데이터의 순서를 바꾸기 (2,0,1 순서로)
- -1은 남은 차원이 자동으로 결정되도록 하는 것이며, (resolution, resolution, 1)은 이미지의 형태를 나타냅니다.
- 따라서 최종적으로 (18724, 28, 28, 1) 형태의 배열로 변경됩니다.
resolution = 28 # 해상도 classes = 10 # 클래스 수 x = np.transpose(x, (2, 0, 1)) print(x.shape) x = x.reshape( (-1, resolution, resolution, 1) )
- 데이터 살펴보기
rand_i = np.random.randint(0, x.shape[0])
plt.title( f'idx: {rand_i} , y: {"ABCDEFGHIJ"[ int(y[rand_i]) ]}' )
plt.imshow( x[rand_i, :, :, 0], cmap='gray' )
plt.show()
3) 데이터 전처리
- Scaling
x.shape, y.shape from sklearn.model_selection import train_test_split train_x, test_x, train_y, test_y = train_test_split(x,y,test_size = 0.2, random_state = 2024) train_x.shape, train_y.shape, test_x.shape, test_y.shape
- Min-Max scaling
max_n, min_n = train_x.max(), train_x.min() train_x = (train_x - min_n) / (max_n - min_n) test_x = (test_x - min_n) / (max_n - min_n)
- One-hot encoding
from keras.utils import to_categorical class_n = len(np.unique(train_y)) train_y = to_categorical(train_y, class_n) test_y = to_categorical(test_y, class_n) train_x.shape, train_y.shape
4) 모델링
- Sequential API, Functional API 중 택일
- Flatten Layer 사용할 것
- Activation Function이 주어진 Dense Layer 뒤에 BatchNormalization 사용할 것
- Dropout을 0.2 정도로 사용할 것
- Early Stopping을 사용할 것
## Functional API # 1. 세션 클리어 : 메모리에 기존 모델 구조가 남아있으면 정리해줘. keras.backend.clear_session() # 2. 레이어 사슬처럼 엮기 il = keras.layers.Input(shape=(28,28,1) ) hl = keras.layers.Flatten()(il) hl = keras.layers.Dense(256, activation='relu')(hl) hl = keras.layers.Dense(256, activation='relu')(hl) hl = keras.layers.BatchNormalization()(hl) hl = keras.layers.Dropout(0.2)(hl) hl = keras.layers.Dense(128, activation='relu')(hl) hl = keras.layers.Dense(128, activation='relu')(hl) hl = keras.layers.BatchNormalization()(hl) hl = keras.layers.Dropout(0.2)(hl) hl = keras.layers.Dense(64, activation='relu')(hl) hl = keras.layers.Dense(64, activation='relu')(hl) hl = keras.layers.BatchNormalization()(hl) hl = keras.layers.Dropout(0.2)(hl) ol = keras.layers.Dense(10, activation='softmax')(hl) # 3. 모델의 시작과 끝 지정 model = keras.models.Model(il, ol) # 4. 컴파일 model.compile(optimizer='adam', loss=keras.losses.categorical_crossentropy, metrics=['accuracy'] ) # 요약 model.summary()
- Early stopping
- monitor='val_loss': 모니터할 지표를 지정합니다. 여기서는 검증 손실(validation loss)을 모니터링하며, 이 지표가 개선되지 않을 때 훈련이 중지됩니다.
- verbose=1에서의 1은 출력 메시지의 상세도를 나타냅니다. 여기서 1은 최소한의 정보를 제공하는 것을 의미합니다.
- 0: 아무런 출력 메시지를 표시하지 않습니다.
- 2: 더 많은 정보를 제공하는 출력 메시지를 표시합니다.
- restore_best_weights=True: 얼리스토핑이 적용되었을 때 가장 성능이 좋았던 시점의 모델 가중치를 복원할지 여부를 지정합니다. 이렇게 하면 Early stopping이 적용된 이후에도 가장 좋은 모델의 성능을 유지할 수 있습니다.
from keras.callbacks import EarlyStopping es = EarlyStopping(monitor='val_loss', # 얼리스토핑을 적용할 관측 대상 min_delta=0, # Threshold. 설정한 값보다 크게 변해야 성능 개선 간주! patience=3, # 성능 개선이 이뤄지지 않을 때 몇 번 더 지켜볼 것인가. verbose=1, # 어느 epoch에서 얼리스토핑이 적용되었는지 보여줌 restore_best_weights=True) # 가장 성능이 좋은 시점의 epoch 가중치로 돌려줌!
- .fit()
model.fit(train_x, train_y, epochs=5, verbose=1, validation_split=0.2, # 매 epoch마다 랜덤하게 20%를 validation 데이터로 사용! callbacks=[es] )
- .evaluate()
model.evaluate(test_x, test_y)
- .predict()
y_pred = model.predict(test_x) y_pred[:2] test_y.shape # 원핫 인코딩 한 것을 다시 묶어주는 코드 # 평가 지표 및 실제 데이터 확인을 위해 필요 y_pred_arg = np.argmax(y_pred, axis=1) test_y_arg = np.argmax(test_y, axis=1)
- 평가 지표
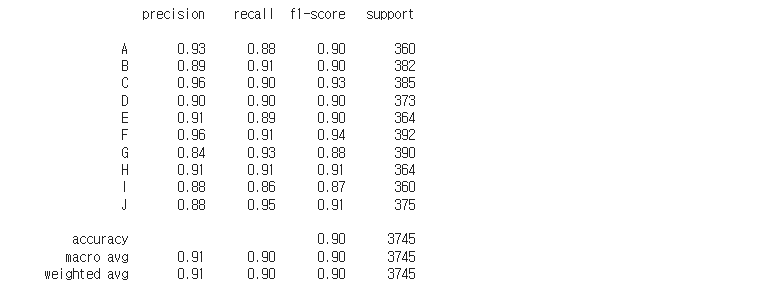
from sklearn.metrics import accuracy_score, classification_report accuracy_score(test_y_arg, y_pred_arg) classes = ['A','B','C','D','E','F','G','H','I','J'] print( classification_report(test_y_arg, y_pred_arg, target_names=classes) )
2. CNN 적용 MNIST 데이터셋 분석
1) 데이터 및 환경변수 설정
import numpy as np import pandas as pd import matplotlib.pyplot as plt import random as rd from sklearn.metrics import accuracy_score import keras
2) 데이터 로딩
- keras.datasets.mnist.load_data()를 호출하면 훈련 데이터와 테스트 데이터가 각각 (train_x, train_y)와 (test_x, test_y)의 형태로 반환됩니다. 따라서 이렇게 분리해서 로딩
(train_x, train_y), (test_x, test_y) = keras.datasets.mnist.load_data() print(train_x.shape, train_y.shape, test_x.shape, test_y.shape)
3) 데이터 전처리
- Convolutional Layer를 사용하기 위한 reshape!
train_x.shape, test_x.shape _, h, w = train_x.shape print(h, w) train_x = train_x.reshape(train_x.shape[0], h, w, 1) test_x = test_x.reshape(test_x.shape[0], h, w, 1) print(train_x.shape, train_y.shape, test_x.shape, test_y.shape)
- 이미지가 0 ~ 1 사이 값을 갖도록 스케일 조정!
max_n, min_n = train_x.max(), train_x.min() train_x = (train_x - min_n) / (max_n - min_n) test_x = (test_x - min_n) / (max_n - min_n) print(f'max : {train_x.max()} , min : {train_x.min()}')실행 결과 : max : 1.0 , min : 0.0
- One-hot Encoding
from keras.utils import to_categorical class_n = len(np.unique(train_y)) class_n train_y = to_categorical(train_y, class_n) test_y = to_categorical(test_y, class_n) train_y.shape
4) 모델링
from keras.backend import clear_session from keras.models import Model from keras.layers import Input, Dense, Flatten, Conv2D, MaxPool2D from keras.callbacks import EarlyStopping # Functional API # 1. 세션 클리어 : 메모리에 모델 구조가 남아있으면 지워줘. clear_session() # 2. 레이어 엮기 : 사슬처럼! il = Input(shape=(28,28,1) ) hl = Conv2D(filters=128, # 새롭게 제작하려는 feature map의 수! kernel_size=(3,3), # Convolutional Filter의 가로세로 사이즈! strides=(1,1), # Convolutional Filter의 이동 보폭! padding='same', # 패딩 적용 유무! activation='relu' # 활성화 함수 반드시! )(il) hl = Conv2D(filters=128, # 새롭게 제작하려는 feature map의 수! kernel_size=(3,3), # Convolutional Filter의 가로세로 사이즈! strides=(1,1), # Convolutional Filter의 이동 보폭! padding='same', # 패딩 적용 유무! activation='relu' # 활성화 함수 반드시! )(hl) hl = MaxPool2D(pool_size=(2,2), # Pooling Filter의 가로세로 크기 strides=(2,2) # Pooling Filter의 이동 보폭! (None은 기본적으로 pool_size를 따라감) )(hl) hl = Conv2D(filters=64, # 새롭게 제작하려는 feature map의 수! kernel_size=(3,3), # Convolutional Filter의 가로세로 사이즈! strides=(1,1), # Convolutional Filter의 이동 보폭! padding='same', # 패딩 적용 유무! activation='relu' # 활성화 함수 반드시! )(hl) hl = Conv2D(filters=64, # 새롭게 제작하려는 feature map의 수! kernel_size=(3,3), # Convolutional Filter의 가로세로 사이즈! strides=(1,1), # Convolutional Filter의 이동 보폭! padding='same', # 패딩 적용 유무! activation='relu' # 활성화 함수 반드시! )(hl) hl = MaxPool2D(pool_size=(2,2), # Pooling Filter의 가로세로 크기 strides=(2,2) # Pooling Filter의 이동 보폭! (None은 기본적으로 pool_size를 따라감) )(hl) hl = Flatten()(hl) hl = Dense(128, activation='relu')(hl) ol = Dense(10, activation='softmax')(hl) # 3. 모델의 시작과 끝 지정 model = Model(il, ol) # 4. 컴파일 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'] ) model.summary() es = EarlyStopping(monitor='val_loss', # 얼리스토핑 적용할 관측 대상 min_delta=0, # Threshold. 설정한 값 이상으로 변화해야 개선되었다 간주. patience=3, # 성능 개선이 발생하지 않을 때, 몇 Epochs 더 볼 것인지. verbose=1, restore_best_weights=True # 가장 성능이 좋게 나온 Epoch의 가중치로 되돌림 ) hist = model.fit(train_x, train_y, epochs=5, verbose=1, validation_split=0.2, # 학습 데이터로부터 validation set을 생성! callbacks=[es] )
5. 모델 평가
performance_test = model.evaluate(test_x, test_y) print(f'Test Loss : {performance_test[0]:.6f} | Test Accuracy : {performance_test[1]*100:.2f}%') pred_train = model.predict(train_x) pred_test = model.predict(test_x) single_pred_train = pred_train.argmax(axis=1) single_pred_test = pred_test.argmax(axis=1) train_y_arg = train_y.argmax(axis=1) test_y_arg = test_y.argmax(axis=1) logi_train_accuracy = accuracy_score(train_y_arg, single_pred_train) logi_test_accuracy = accuracy_score(test_y_arg, single_pred_test) print('CNN') print(f'트레이닝 정확도 : {logi_train_accuracy*100:.2f}%' ) print(f'테스트 정확도 : {logi_test_accuracy*100:.2f}%' )
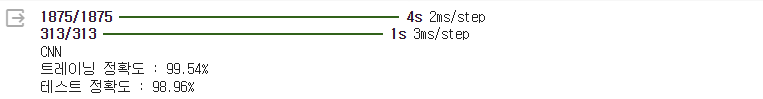

안녕하세요. wony입니다.