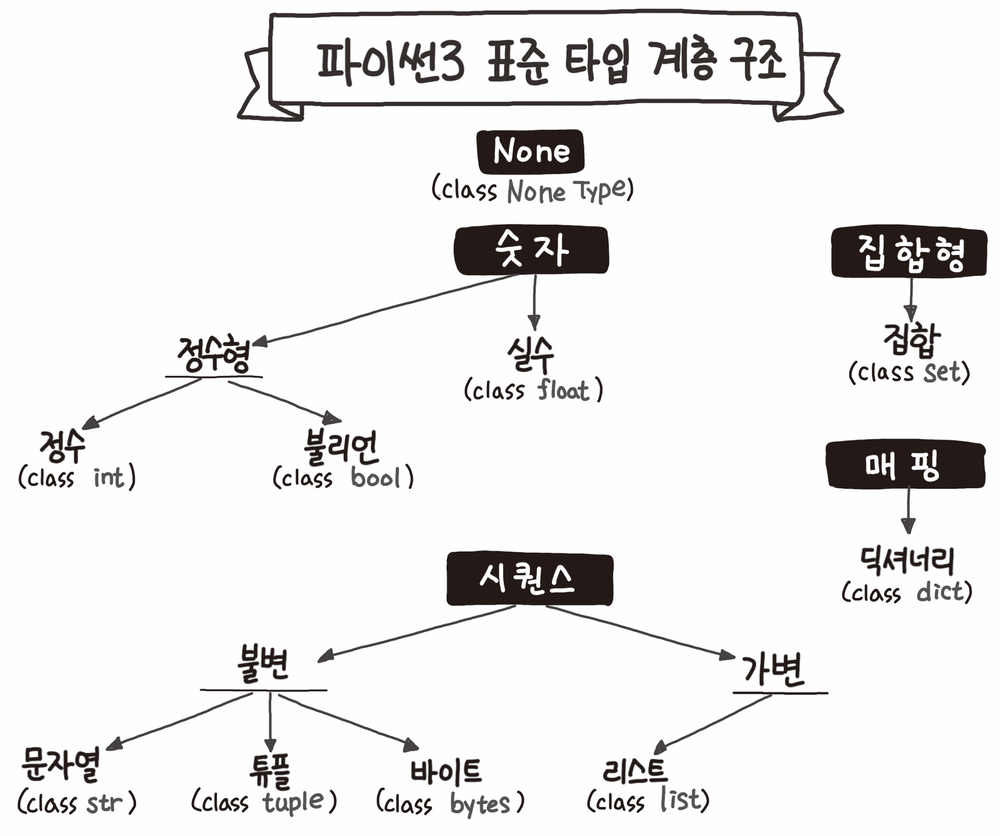
📌 리스트(list)
리스트(list)는 가변 형태의 시퀀스 자료형이다.
C++의 std::vector, 자바의 ArrayList와 유사하다.
a = list()
b = []
c = [1, 2, 'Kim']| 연산 | 설명 |
|---|---|
| len(a) | 전체 요소의 개수를 리턴한다. |
| x in a | x가 존재하는지 앞에서부터 순차 확인한다. |
| a.count(x) | x의 개수를 리턴한다. |
| a.index(x, i=0) | i번째 값 이후로 등장하는 x의 인덱스를 리턴한다. |
| min(a), max(a) | 최솟값/최댓값을 리턴한다. |
| x.join(a) | 리스트에 존재하는 값들을 문자열 x로 연결해 리턴한다. |
| a.append(x) | 리스트 마지막에 x를 추가한다. |
| a.insert(i, x) | 리스트 i번째 인덱스에 x를 추가한다. |
| del a[i] | 리스트 i번째 인덱스 요소를 제거한다. 슬라이싱이 가능하다. |
| a.remove(x) | 리스트에서 첫번째로 등장하는 x를 찾아 삭제한다. |
| a.pop() | 리스트 마지막 요소를 제거하고 그 값을 리턴한다. |
| a.pop(i) | 리스트 i번째 인덱스 요소를 제거하고 그 값을 리턴한다. |
| a.sort() | Timsort를 이용해 리스트를 정렬한다. |
| a.reverse() | 리스트를 반대로 뒤집는다. |
📌 문자열(string)
문자열(string)은 불변 형태의 시퀀스 자료형이다.
a = 'string1'
b = "string2"
c = '''string3'''
d = """string4"""| 연산 | 설명 |
|---|---|
| len(a) | 문자열의 길이를 리턴한다. |
| x in a | x가 포함되는지 앞에서부터 순차 확인한다. |
| a.count(x) | x의 개수를 리턴한다. |
| a.index(x, i=0) | i번째 값 이후로 등장하는 x의 인덱스를 리턴한다. |
| a.find(x, i=0) | i번째 값 이후로 등장하는 x의 인덱스를 리턴한다.(없으면 -1) |
| min(a), max(a) | 최솟값/최댓값을 리턴한다. |
| a.split(x='') | 문자열을 x 단위로 쪼개어 리스트로 리턴한다. |
| a.isalpha() | 알파벳으로만 이루어져 있는지 검사한다. |
| a.isdigit() | 숫자로만 이루어져 있는지 검사한다. |
| a.isalnum() | 알파벳 또는 숫자로만 이루어져 있는지 검사한다. |
| a.isspace() | 공백으로만 이루어져 있는지 검사한다. |
| a.isupper() | 대문자로만 이루어져 있는지 검사한다. (숫자, 공백 등은 확인 X) |
| a.islower() | 소문자로만 이루어져 있는지 검사한다. (숫자, 공백 등은 확인 X) |
| a.istitle() | 'This Is Title.' 형식인지 검사한다. |
| a.upper() | 모든 문자를 대문자로 변경한다. |
| a.lower() | 모든 문자를 소문자로 변경한다. |
| a.title() | 'This Is Title.' 형식으로 변경한다. |
| a.capitalize() | 'This is title.' 형식으로 변경한다. |
| a.replace(x,y,k) | 처음 k개의 x를 y로 변경한다. (k를 생략할 시 모두) |
| a.strip() | 공백, \n, \t 등을 제거한다. lstrip(), rstrip()도 존재. |
📌 딕셔너리(dict)
딕셔너리(dict)는 가변 형태의 매핑 자료형이다.
key: value 형식으로 데이터를 저장하며,
C++의 std::unordered_map, 자바의 HashMap과 유사하다.
파이썬 3.7부터 입력 순서를 유지한다.
a = dict()
b = {}
c = {'k1':'v1', 'k2':'v2', 'k3':'v3'}| 연산 | 설명 |
|---|---|
| len(a) | 전체 요소의 개수를 리턴한다. |
| key in a | 키가 존재하는지 확인한다. |
| a[key] | 키를 조회하여 값을 리턴한다. |
| del a[key] | key를 키로 하는 데이터 쌍을 삭제한다. |
| a.pop(key) | key를 키로 하는 데이터 쌍을 삭제하고 대응되는 값을 리턴한다. |
| a.keys() | 모든 키들을 리스트 형태로 리턴한다. |
| a.values() | 모든 값들을 리스트 형태로 리턴한다. |
📌 집합(set)
파이썬의 집합(set)은 수학에서 배운 집합이 실로 구현된 자료형이다.
같은 값은 하나만 저장하는 점이 핵심이며, 입력 순서가 유지되지 않는다.
a = set()
b = {1} # {} is a dictionary.| 연산 | 설명 |
|---|---|
| x in a | x가 존재하는지 확인한다. |
| a.add(x) | x를 추가한다. |
| a.remove(x) | x를 삭제한다. x가 없으면 KeyError가 발생한다. |
| a.discard(x) | x를 삭제한다. x가 없어도 KeyError를 발생시키지 않는다. |
| a <= b | a가 b의 부분집합인지 확인한다. |
| a | b | a와 b의 합집합을 리턴한다. |
| a & b | a와 b의 교집합을 리턴한다. |
| a - b | a와 b의 차집합을 리턴한다. |
| a ^ b | a와 b의 대칭차집합을 리턴한다. |
📌 튜플(tuple)
파이썬의 튜플(tuple)은 불변 형태의 시퀀스 자료형이다.
a = tuple()
b = ()
c = (1,) # has just one element.
d = 1, 2, 3
e = (1, 'Kim', (3,4))튜플 내 요소들을 삭제/변경/추가할 수 없다. (read-only)
이 점만 주의한다면 리스트 연산들을 대부분 똑같이 활용할 수 있다.
tp = (1, 2, 3)>>> tp[0] = 10
TypeError: 'tuple' object does not support item assignment
>>> tp.append(4)
AttributeError: 'tuple' object has no attribute 'append'
>>> tp.insert(2, 7)
AttributeError: 'tuple' object has no attribute 'insert'
>>> tp.remove(3)
AttributeError: 'tuple' object has no attribute 'remove'
>>> tp.sort()
AttributeError: 'tuple' object has no attribute 'sort'
>>> tp.reverse()
AttributeError: 'tuple' object has no attribute 'reverse'
시각 자료 출처 :
파이썬 알고리즘 인터뷰 (박상길 지음)