오늘은 자료구조 중 Linked-list와 Hash-Table에 대해 알아보겠습니다.
1. Linked-list
Linked-list의 구조에 대해서 알아보겠습니다. linked-list는 영어의 뜻 그대로 서로(각 노드)가 링크되어있는 형태의 리스트로 되어있는 자료구조 입니다.
간단하게 예를 들자면 기차놀이를 생각한다고 하면 됩니다. 하지만 일반적인 기차놀이와는 차이가 있습니다. 일반적인 기차놀이가 그냥 리스트 혹은 배열이라고 한다면, linked-list는 'link'라는 개념으로 묶여있는데요. 설명을 조금 더 해보겠습니다.
우리가 스마트폰을 보고있다가 친구가 재미있는 영상을 찾았다며 '링크'를 하나 보내줬습니다. 우리는 이 링크를 클릭해서 친구가 보여주려고 하는 재미있는 영상을 볼수 있습니다. 하지만 이 '링크'자체로만 본다면 우리는 그 동영상을 볼수 있는 주소만 가지고 있을뿐 친구가 보내준 동영상의 내용까지 알수는 없습니다.
linked-list는 이와같이 서로의 주소를 갖음으로써 연결되어있습니다.
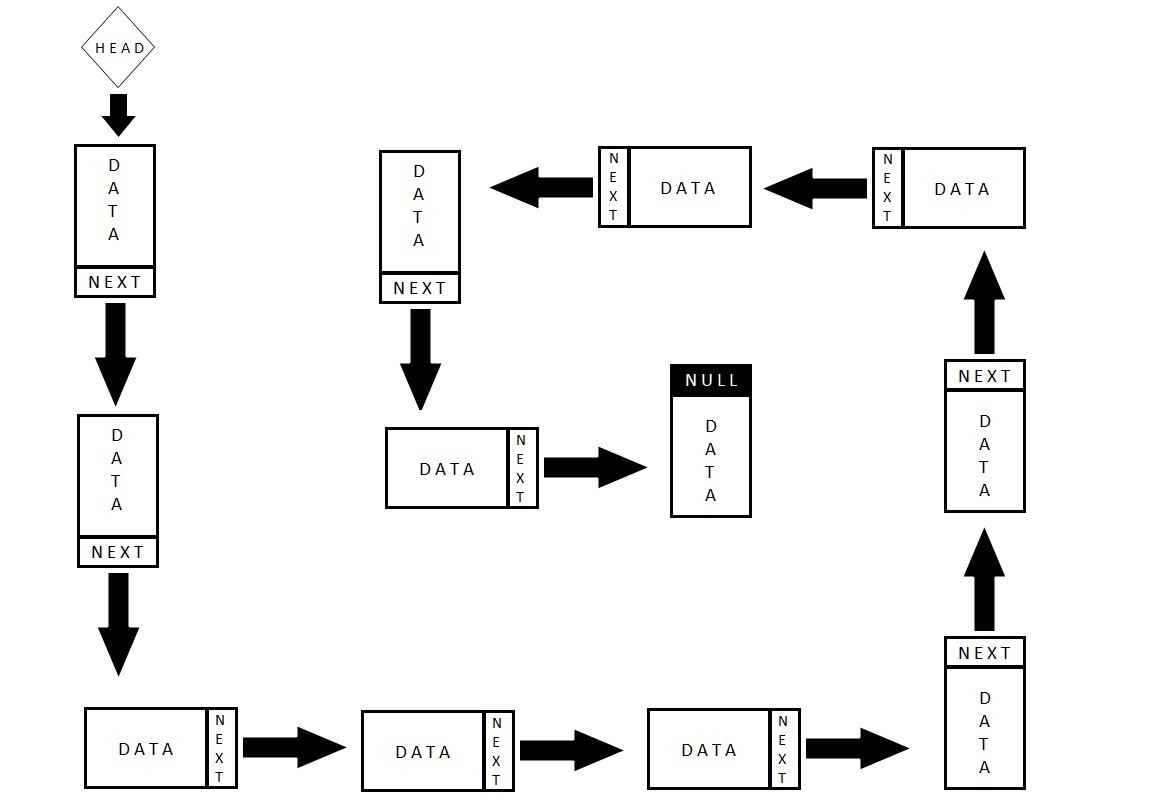
위의 그림을 보시면, 각 노드들이 서로 연결되어있는 모습을 볼수 있습니다.
각 노드들은 DATA라고 써있는 공간에 자신의 값을 가지고 있고, NEXT라는 공간에는 다음 노드의 주소만 가지고 있을뿐 다음 노드의 DATA값이 무엇인지는 알수 없습니다.
Linked-list에서 맨 처음에 시작하는 노드를 head, 맨 마지막에 위치한 노드를 tail이라고 부릅니다.
Linked-list는 위의 그림과 같은 구조를 갖고 있으나, 앞에있는 노드의 주소와 뒤에있는 노드의 주소를 모두 갖고있는 구조와 tail노드가 head노드의 주소를 갖고있어 원형의 구조가 되는 형태도 있습니다.
property
-
node : 한개의 데이터 단위로, value와 다음 노드의 주소값을 갖고있는 객체
-
head : 첫번째 노드를 가르키는 변수
-
tail : 마지막 노드를 가르키는 변수
method
-
addToTail() : 새로운 tail 노드를 삽입
-
removeHead() : 첫번째 노드를 삭제
-
contain() : 해당 요소를 리스트가 포함하고 있는지 확인
pseudo code
likedList{
빈리스트 생성
head 초기화
tail 초기화
size 초기화
노드추가{
- 새로운 노드 인스턴스 생성
- 사이즈가 0이면 head에 노드 추가, tail에 노드 추가
- tail의 next에 노드 추가
- tail에 node추가
- 사이즈 1 증가
}
head 노드삭제{
- 사이즈가 0이면 리턴
- 헤드 = 헤드의 next
- 사이즈 1 감소
}
노드찾기{
- 반복문 돌면서 찾는 노드가 있다면 true 반환. 없다면 false 반환.
}
리스트사이즈{
- 사이즈 리턴
}
리스트 리턴
}
Node(value){
노드 객체 생성
노드의 value값 초기화
노드의 next값 초기화
노드 리턴
}2. Hash-table
Hash-table 구조에 대해 알아보겠습니다. Hash-table 의 구조는 어떠한 특정 연산을 실행하는 함수(이를 Hash function이라고 합니다)를 거쳐 함수를 실행한 결과에 의해 데이터를 저장하는 구조입니다. 구조를 보면 다음과 같습니다.
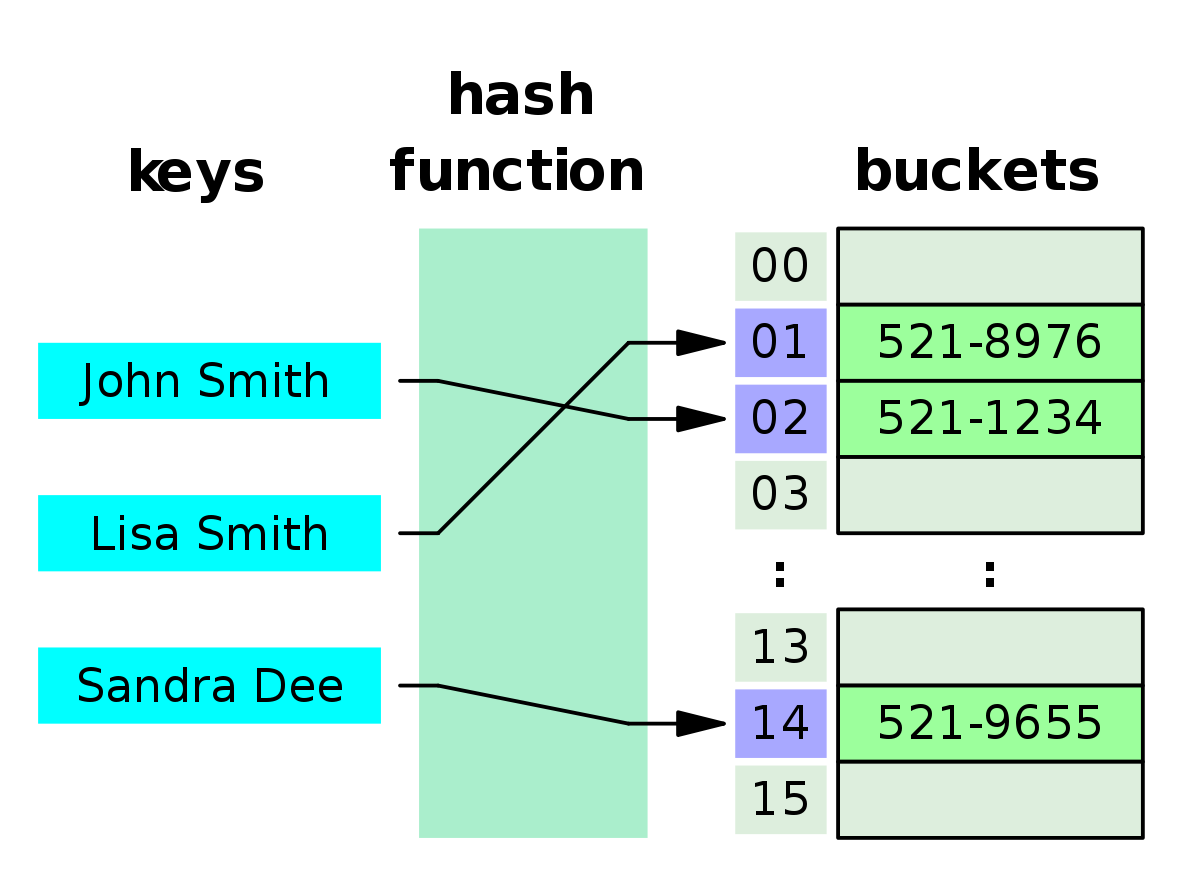
위의 그림을 보면 각 key값들이 hash function을 거쳐 일정한 규칙에 의해 index값을 갖고 저장되는 모습을 볼수 있습니다. hash function에 대해 이해가 잘 안될수 있으니 간단한 예를 하나 더 들어보겠습니다.
예를들어 단어사전을 단어의 길이에 따라 저장하는 구조가 필요하다고 합시다. 그러면 hash function에서는 key값(각 단어들)의 길이에 따라 각 인덱스에 저장하도록 할 수있습니다. apple이라는 단어는 05번째 인덱스 테이블에, banana라는 단어는 06번째 인덱스 테이블에 말이죠.
property
- Object(key,value) : storage에 데이터를 넣거나 찾을때 쓰기 위한 key와 value가 있는 객체
method
-
hashFunction(key) : storage에 데이터를 저장하기 위해 사용하는 알고리즘, 함수
-
insert(key, value) : storage에 value를 저장한다. / insert()로 받은 key값을 hashFunction에 넘긴후 hashFunction이 정해준 위치에 value 저장
-
find(key) : key값을 기준으로 해당하는 value를 찾음.
-
remove(key) : key값을 기준으로 해당하는 value를 삭제
3. Graph
그래프 자료구조는 각 노드와 노드를 연결하는 간선을 하나로 연결해 놓은 구조를 뜻합니다.
그래프에서는 각 노드를 정점(Vertex), 각 정점을 연결하는 선을 간선(Edge)이라고 표현합니다. 즉, 다시말하면 그래프는 정점과 간선으로 이루어진 형태의 구조라고 할 수 있습니다.
그래프의 특징에는 다음과 같은 것들이 있습니다.
- 그래프는 네트워크 모델입니다.
- 2가지 이상의 경로를 가질수 있다.
- 루트가 존재하지 않는다
- 부모-자식의 관계가 존재하지 않는다
- 간선의 유무는 그래프마다 다르다.
그래프 구조는 여러가지가 있지만 이 글에서는 무방향 그래프와 방향 그래프에 대해 알아보겠습니다.
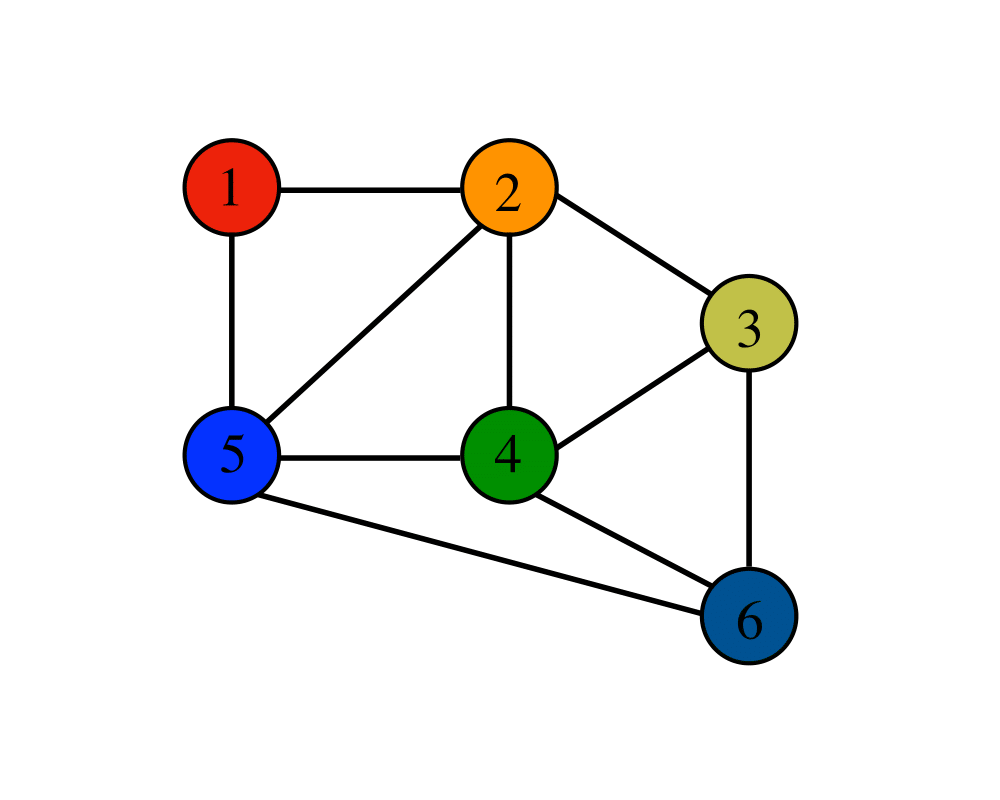
위 사진은 무방향 그래프에 대해 설명한 그림입니다. 위에 보시는 사진과 같이 각 노드들이 연결되어있지만 방향을 가지지 않고 그냥 연결만 되어있는 모습을 볼수 있습니다.
무방향 그래프는 방향을 갖고 있지 않아 자신과 연결된 간선을 통해 양방향 통신이 가능합니다.
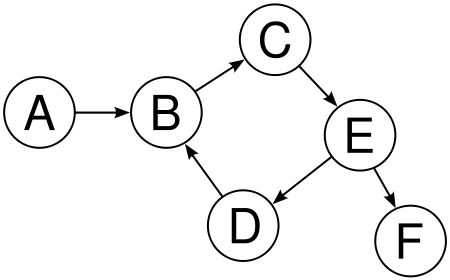
위의 그림은 방향 그래프에 대해 설명하는 그림입니다. 방향 그래프는 무방향 그래프와 동일하지만 각 노드의 간선이 방향을 가진다는 것이 특징입니다. 그렇기 때문에 어떠한 노드에서 다른 노드로 이동하기 위해서는 정해진 방향으로만 이동해야 합니다.
property
- node
- edge
method
- addNode() : 노드 추가
- contains() : 그래프에 노드가 존재하는지 확인
- removeNode() : 노드 삭제
- addEdge () : 간선 추가
- hasEdge () : 그래프의 노드에 간선이 있는지 확인
- removeEdge() : 간선 삭제
4. Tree
트리는 하나의 노드(root)에서 가지처럼 뻗어나가는 구조를 가진 자료구조 입니다.
우리가 잘 알고있는 DOM이 바로 트리구조를 가지고 있습니다. 트리구조는 DOM뿐만 아니라 주변에서도 아주 쉽게 찾아볼수 있습니다. 회사나 기관등에서 사용하는 조직도 또한 트리구조이며, 지금 보고있는 블로그도 한명의 블로그 라는 루트 노드에서 카테고리와 각 게시글들로 뻗어나가는 구조입니다.
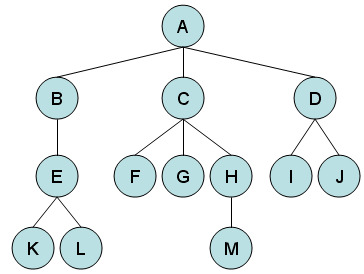
트리구조는 위의 사진처럼 구성되어 있습니다. 트리구조는 워낙 많이 사용되고 평소에도 접할수 있어 이해가 빨리 될것 같습니다.
property
- root node : 최상위 노드, 부모가 없는 노드
- leaf node : 잎사귀 노드, 가장 밑에 있는 노드로 자식 노드가 없는 노드
method
- addChild() : 자식노드(childNode) 추가
- contains() : 노드가 tree에 존재하는지 확인
- removeChild() : 자식노드 삭제
5. Binary-tree(이진 트리)
이진 트리는 트리와 비슷하지만 루트를 중심으로 두개로 나누어진 트리를 뜻하며, 자식 노드 또한 자신의 자식은 두개가 존재 합니다. 하지만 반드시 그런것은 아니며 자식으로 하나의 노드만 있다면, 나머지 하나는 빈 노드가 존재하는 것으로 간주하여 자식이 하나만 존재하는 구조도 있습니다.
이진 트리에서 부모로 부터 나눠진 두개의 자식들도 트리구조를 가지며, 이 자식 트리를 '서브트리' 라고 합니다. 다시 정리하면, 이진 트리는 루트를 중심으로 서브트리들로 구성된 트리라고 할 수 있습니다.
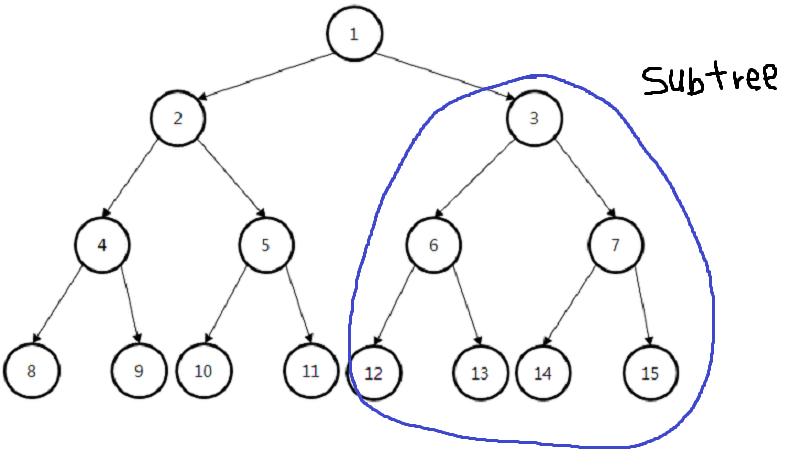
보통 이진 트리는 각 노드별로 예 아니오와 같은 조건을 통해 뻗어나가며 노드들이 자리를 잡게 됩니다. 위의 사진은 숫자의 대소를 비교하여 나뉜 모습을 볼 수 있습니다.
property
- node
- left : 왼쪽으로 구분 되어 저장될 node
- rigth : 오른쪽으로 구분 되어 저장될 node
method
- insert() : value값을 저장
- contains() : value값이 tree에 있는지 확인
#DFS(깊이 우선탐 색)& BFS(넓이 우선 탐색)
트리와 그래프의 구조 탐색 방법중 대표적인 두 가지, DFS와 BFS에 대해 간단하게 살펴보겠습니다.
DFS(깊이 우선 탐색, Depth First Search)
깊이 우선 탐색은 루트 혹은 기준이 되는 노드의 분기점(branch)를 탐색하기 전 하나의 가지를 먼저 탐색하는 기법입니다.
DFS의 특징
- 모든 노드를 탐색하고자 할때 용이하다
- BFS에 비해 간단하다
- BFS와 비교하여 속도가 느리다
BFS(넓이 우선 탐색, Breath First Search)
넓이 우선 탐색은 루트 혹은 기준이 되는 노드 와 연관된 노드들을 먼저 탐색하는 기법입니다.
BFS의 특징
- 루트 노드에서 인접한 노드부터 탐색한다
- 어떠한 두 노드 사이의 경로를 탐색할때 용이하다
다음 그림을 보면 두 가지 탐색 방법의 차이점을 직관적으로 확인 할 수 있습니다.
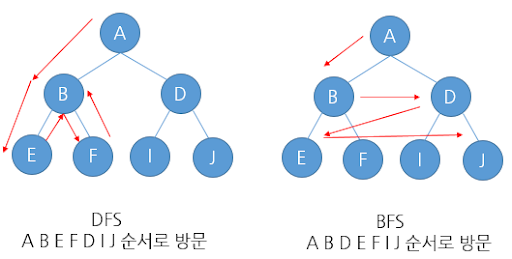
사진출처
https://m.blog.naver.com/PostView.nhn?blogId=591923&logNo=220913738926&proxyReferer=https%3A%2F%2Fwww.google.com%2F
http://algorist.com/problems/Graph_Data_Structures.html
http://www2.stat.duke.edu/~cr173/Sta523_Fa14/hw/hw4.html
https://parksh86.tistory.com/145
https://ko.wikipedia.org/wiki/%ED%95%B4%EC%8B%9C_%ED%85%8C%EC%9D%B4%EB%B8%94
https://velog.io/@dankim/2019.09.18-Linked-List-z5k0oqvd2z
