Attention Is All You Need
자연어 발전
RNN -> LSTM -> Seq2Seq -> Attention -> Transformer -> ...
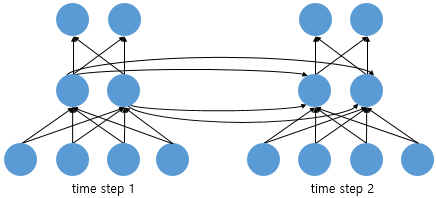
RNN (Recurrent Neural Network)
순환신경망.

결과값을 출력층 뿐만 아니라 다음 은닉층으로도 보낸다.
LSTM (Long Short-Term Memory models)
순환 신경망(RNN) 기법의 하나로 셀, 입력 게이트, 출력 게이트, 망각 게이트를 이용해 기존 순환 신경망(RNN)의 문제인 기울기 소멸 문제(vanishing gradient problem)를 방지하도록 개발되었다.

RNN에서는, t값이 커질수록 x1의 정보량은 손실된다.
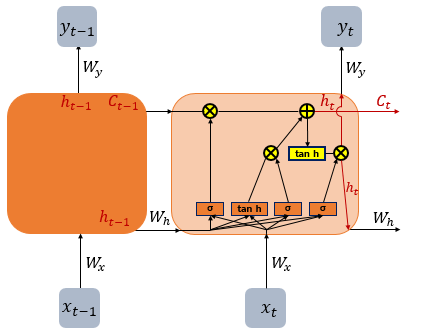
LSTM에서는 은닉층에 입력, 망각, 출력 게이트를 추가함.
Seq2Seq
입력 문장을 하나의 context vector로 압축하는 Encoder,
번역된 단어를 출력하는 Decoder로 구성된다.
Seq2Seq + Attention
Transformer
CNN, RNN 필요없음
Positional Encoding을 이용해 단어의 순서 정보 전달
인코더와 디코더만으로 구성됨
Attention 레이어를 중첩하여 만듦
Embedding: 자연어를 기계가 이해할 수 있는 vector로 표현하는 것
RNN을 사용하지 않기 때문에 임베딩에 위치정보 포함
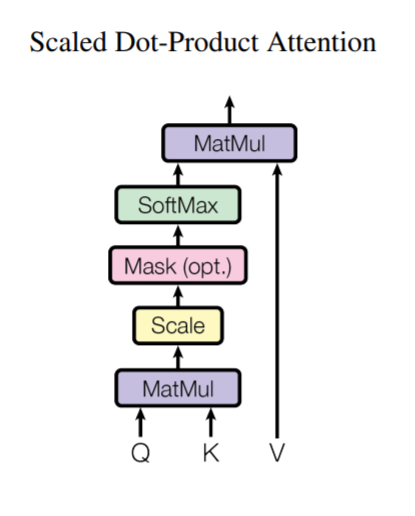
Attention
https://wikidocs.net/22893
한 단어가 다른 단어에 주는 영향력을 attention score로 표현
문맥에 대한 정보를 학습.
어탠션을 위한 3가지 요소 쿼리, 키, 값
물어보는 주체: query
객체: key,
I am a Teacher 에서 I가 다른 am, a, teacher에 대한 영향력이 궁금하다면 I가 쿼리, am a teacher가 키가 된다.
각 Attention들은 h들로 구분된다.

3 Attention Layers
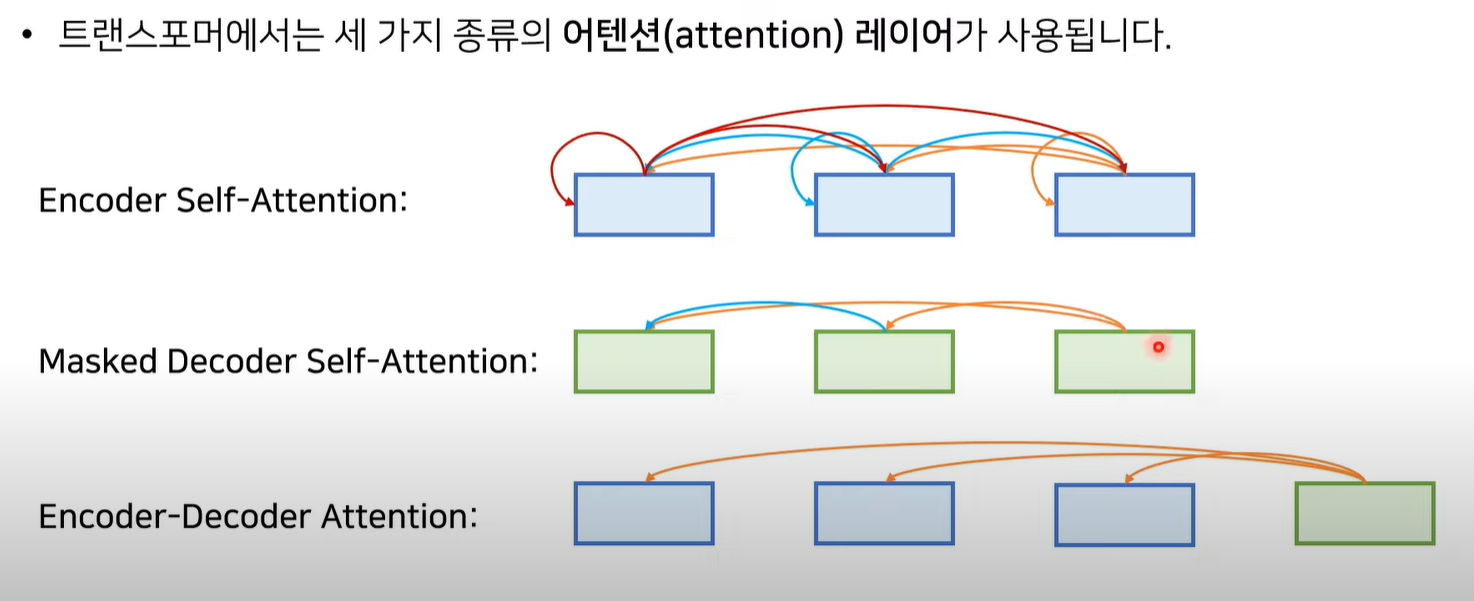
self attention
query와 key를 모두 자기 자신으로 설정.
한 문장 안에서 단어들간의 관계를 파악할 수 있다.
Today is happy because it is sunny.
Positional Encoding
Residual connection (잔여학습)
이전 학습 결과와 원본 데이터를 모두 입력받는 것
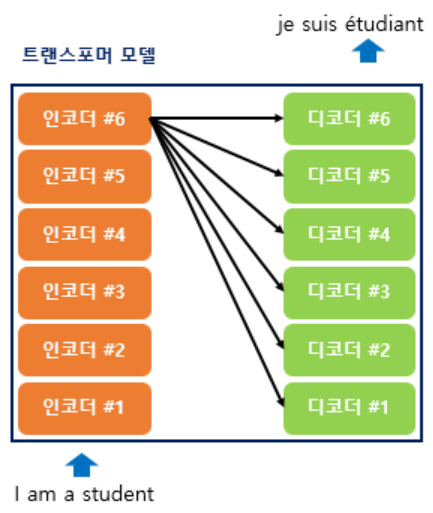
인코더의 출력값이 모든 디코더의 입력값이 된다.
한국어 리뷰
https://idontknowmathematics.tistory.com/11
참고문헌 해설들
[1]Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
https://an-seunghwan.github.io/deep-learning/layernorm/
Layer normalization
[2]Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. CoRR, abs/1409.0473, 2014.
https://misconstructed.tistory.com/49
[12] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation
https://cryptosalamander.tistory.com/175
LSTM
[7]Junyoung Chung, Çaglar Gülçehre, Kyunghyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. CoRR, abs/1412.3555, 2014.
https://coshin.tistory.com/45
Gating Mechanism
[18] Oleksii Kuchaiev and Boris Ginsburg. Factorization tricks for LSTM networks. arXiv preprint arXiv:1703.10722, 2017.
factorization trick.
[26] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
정보 거의 없음
[20] Samy Bengio Łukasz Kaiser. Can active memory replace attention? In Advances in Neural Information Processing Systems, (NIPS), 2016.
https://blog.lunit.io/2017/03/28/neural-gpus-and-extended-neural-gpus/
Extended Neural GPU
[15] Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Koray Kavukcuoglu. Neural machine translation in linear time. arXiv preprint arXiv:1610.10099v2, 2017.
ByteNet
[8] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional sequence to sequence learning. arXiv preprint arXiv:1705.03122v2, 2017.
Conv2S