AutoScaler
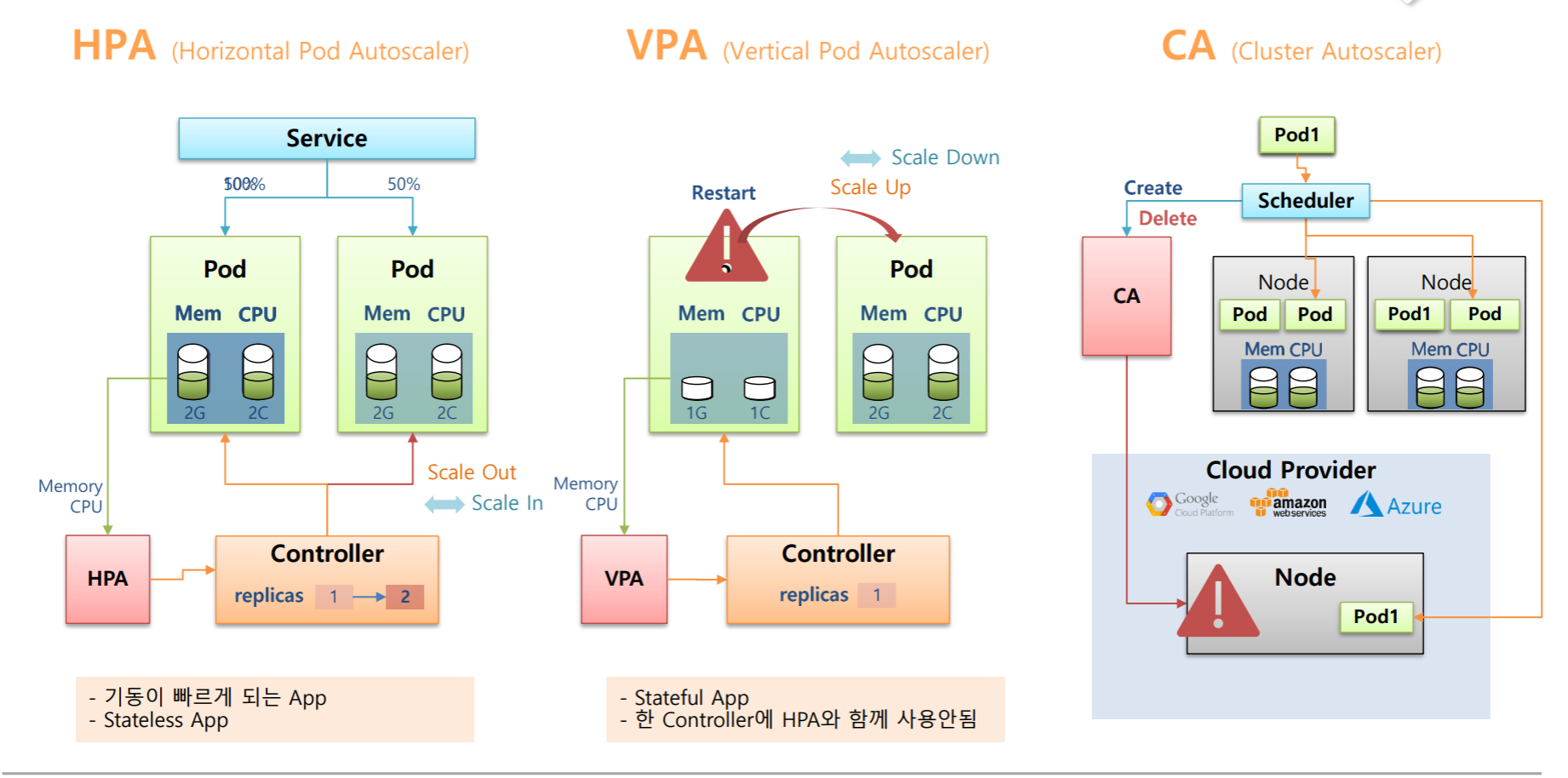
쿠버네티스에는 Pod의 개수를 늘려주는 HPA와 Pod의 Resources를 증가시키는 VPA 그리고 Cluster의 Node를 추가하는 CA 이렇게 3가지의 AutoScaler가 있다.
HPA
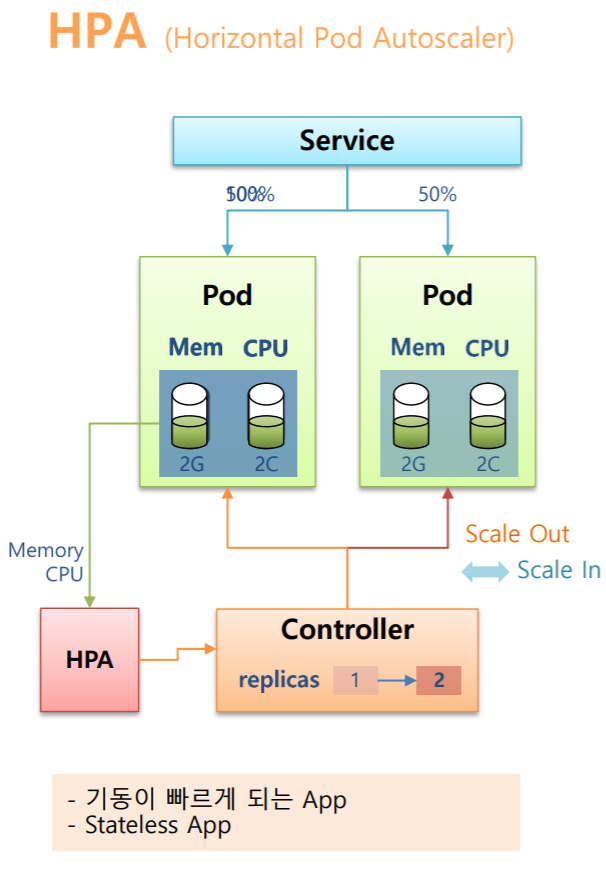
컨트롤러가 있고 replicas= 1로 Pod가 운영되고 있는 상태에서 Service도 연결이 되서 요청 트래픽이 Pod에 흐르고 있다고 가정해보자.
그런데 시간이 갈수록 트래픽이 많아져서 Pod안에 있는 Resources들을 모두 사용하게 되었고 조금 더 트래픽이 증가되면 이 Pod는 죽을 수 있는 상황이 되었다.
이러한 상황을 대비해 사전에 HPA를 만들고 Controller에 연결이 되어 있는 상황이였더라면 HPA가 Pod의 Resources 상태를 감지하고 있다가 위험한 상황이 오면 Controller의 replicas를 높여준다.
그래서 Controller는 Pod를 하나 더 만들게 되고 그렇게 되면 Pod가 수평적으로 증가하게 되는데 이것을 Scale Out이라고 부른다.
cf) 반대로 트래픽이 줄어서 Resources의 상태가 줄어들면 Pod는 삭제가 되는데 이것을 Scale In 이라고 한다.
Pod가 증가되었기 때문에 트래픽은 50%씩 분담을 하게 되서 자원 사용량은 똑같이 배분이되고 안정적인 서비스를 유지하게 된다.
HPA는 장애가 발생할 수 있는 상황을 대비해 만들어진 기술이고 장애 상황에는 빠른 복구가 중요하기 때문에 App자체에 기동이 빠르게 되는 App에서 사용하면 좋다.
만약 HPA를 Stateful App에 사용하게 된다면 Stateful App은 Pod마다 각각의 역할이 있기 때문에 Master의 역할을 하는 Pod와 Slave의 역할을 하는 Pod 중에 HPA는 어떤 Pod를 늘려야할지 판단할 수 없기 때문에 어떤 App이던 상관없이 양적으로 늘리고 줄일 수 있는 Stateless App에 사용하는 것을 권장한다.
VPA
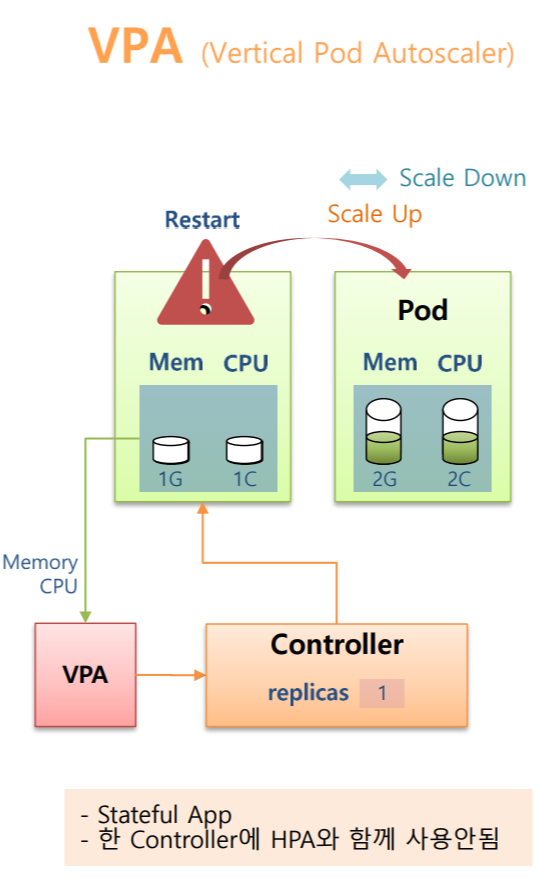
Stateful App에 대한 Auto Scaler다.
Controller에 replicas=1로 Pod가 하나 만들어져 있고(메모리 1G, CPU 1C) 이 Pod의 Resources 자원이 모두 사용되었다고 가정해보자.
마찬가지로 그냥 냅두면 Pod가 죽을 상황이 발생하지만
VPA를 Controller에 달아놨다면 VPA가 Resoureces 상태를 감지하고 있다가 이런 상태를 인지하고 Pod를 Restart 시키면서 Resources를 증가시켜주는데 이것을 Scale Up 이라고 한다.
cf) 반대로 감소가 된다면 Scale Down 이라고 한다.
주의 사항으로는 한 Controller에 VPA와 HPA를 둘 다 달면 기능이 작동하기 않기 때문에 조심해야 한다.
CA
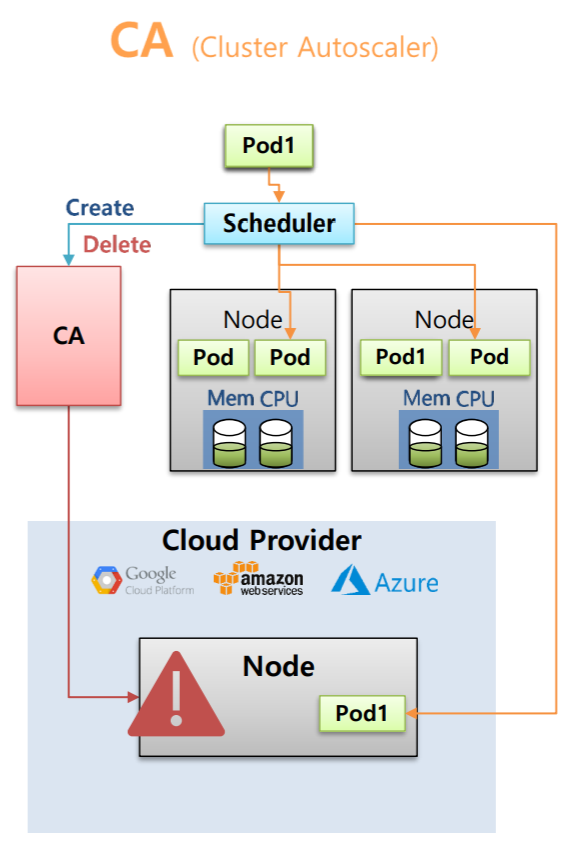
Cluster에 있는 모든 Node에 자원이 없을 경우 동적으로 Worker Node를 추가시켜준다.
Node 2개가 있고 Pod들이 운영되고 있는 상황에서 새로운 Pod를 만들면 Scheduler가 스케줄링하여 Node에 Pod를 할당하는데 Node들의 Resource가 전부 사용하였다면 Scheduler는 CA에게 Worker Node를 생성해달라고 한다.
그리고 CA를 사전에 특정 Cloud Provider와 연결을 해놓았다면 CA는 Cloud Provider에 Node를 하나 만들고 Scheduler는 새로운 Pod를 이 Node에 할당한다.
그러다가 기존의 사용하고 있던 Worker Node들의 Resoureces가 줄어들면 CA에게 Cloud Provider의 Node를 삭제해달라고 요청을 하고 그 안에 있는 Pod들은 Local의 Worker Node들에 할당이 된다.
HPA Architecture
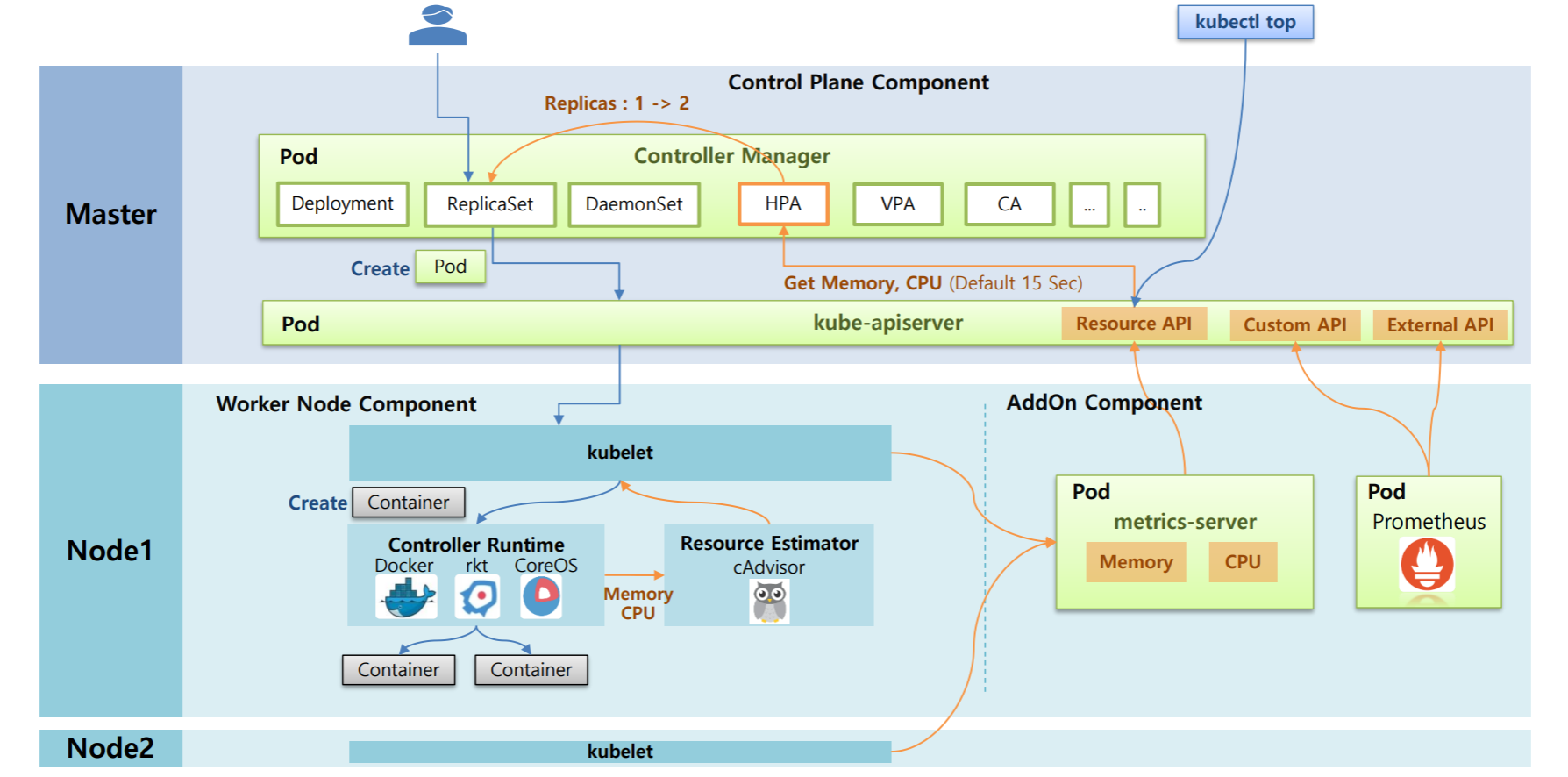
위의 사진을 보면 Master Node와 Worker Node들이 있고 Master Node에 Control Plane Component라고 해서 쿠버네티스의 중요 기능을 하는 Component들이 Pod의 형태를 띄어서 돌아가고 있는데 그 중 Controller Manager는 우리가 사용하고 있는 Controller들 (Deployment, DaemonSet, ReplicaSet, HPA, VPA, CA) 쓰레드의 형태로 돌아가고 있다.
그리고 API 서버가 있는데 쿠버네티스의 모든 통신의 길목 역할을 한다. 사용자가 쿠버네티스에 접근했을 때도 이용하지만 쿠버네티스 내의 Component 조차도 DB에 접근한다던가 타 Component들을 호출할 때 이 kube-API 서버를 통과한다.
Node를 보면 Worker Node Component라고 해서 쿠버네티스 설치시에 kubelet이 각각의 Node마다 설치가 되는데 Node를 나타내는 에이전트 같은 역할을 하는데 자신의 Node에 있는 Pod들을 관리하는 역할을 한다. 그렇다고 kubelet이 직접 Container까지 만드는 것은 아니고
Container Runtime이라고 해서 실제 Controller를 생성하고 삭제하는 구현체가 있다. 대부분 도커를 사용해서 설치하고 있지만 rkt나 CoreOS를 사용해서도 Container를 생성하고 삭제할 수 있다.
사용자가 ReplicaSet을 만들었을 때의 과정
Pod1개가 만들어지는 과정
- ReplicaSet을 담당하는 쓰레드는 replicas=1이라고 했을 때 Pod를 하나 만들어달라고 kube API서버를 통해 kubelet한테 요청을 한다.
- kubelet은 Pod(쿠버네티스의 개념) 안에 있는 Container만 빼서 Container를 만들어 달라고 도커에게 요청을 한다.
- 도커는 Node위에 Container를 만들어준다.
HPA가 Pod의 Resources를 감지하는 과정
- Resource Estimator인 cAdvisor가 도커로 부터 메모리와 CPU에 대한 성능 정보를 측정하는데 이 정보를 kubelet을 통해 가져갈 수 있게 해놓았다.
- AddOn Component로 metrics-server를 설치하면 metrics-server가 각각의 Node에 있는 kubelet한테 메모리와 CPU 정보를 가져와서 저장을 해놓는다.
- 그리고 이 데이터들을 다른 Component들이 사용할 수 있도록 Kube API서버(Resource API)에 등록을 해놓는다.
- 그러면 HPA가 메모리와 CPU 정보를 Kube API서버를 통해서 가져갈 수 있게 되고 HPA는 15초마다 체크를 하고 있다가 Pod의 Resources 사용률이 높아졌을 때 replicaSet의 replicas를 증가시킨다.
- 그리고 kubectl top 명령어를 통해서 Resource API를 통해서 Pod나 Node의 Resources 상태를 조회해 볼 수 있다.
- 추가적으로 Prometheus를 사용하면 메모리와 CPU 외에도 다른 metric 정보를 수집할 수 있다. (패킷 수, Request 양 등등)
HPA 세부 내용
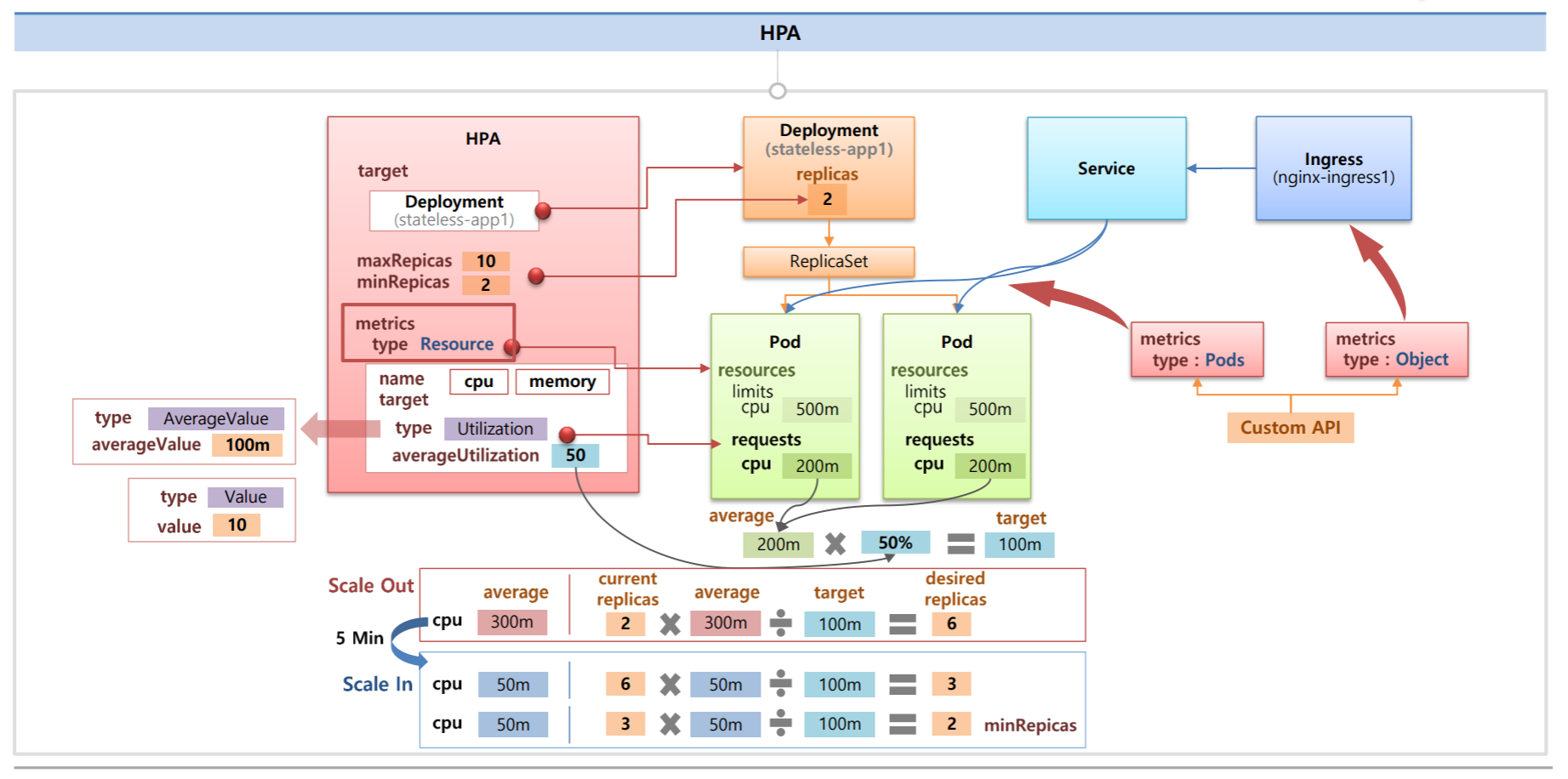
위의 사진처럼 replicas=2로 Deployment를 만들면 ReplicaSet이 만들어지면서 Pod가 2개 생기게 된다.
그리고 Pod의 Resources Requests와 Limits이 설정되어 있는 상태에서 HPA를 만들어 본다고 가정해보자.
HPA에 target Controller를 지정하는 부분이 있고 증감되는 replicas에 대한 Max값과 Min값을 지정해놔야 한다.
metrics는 metric 정보의 어떤 조건을 통해서 replicas를 증가시킬지 감소시킬지에 대한 부분인데 type에 Resource라고 선택하면 Pod의 Resources 부분을 가리키는 것이고 세부적으로 보면 name에 cpu를 볼건지 memory를 볼건지 정할 수 있다.
그리고 어떤 조건으로 증가시킬지에 대한 부분인데 가장 기본으로 사용되는 옵션인 Utilization이 있고 평균을 50이라고 했다면 Pod의 Requests 값을 기준으로 현재 사용 자원이 평균 50%가 넘으면 replicas를 증가시켜준다.
이 수치를 넘으면 무조건 1개씩 Pod가 만들어지는 것이 아니고 정해진 공식을 가지고 한번에 몇개씩 Pod를 만들지 정한다.
공식
예를 들어 type: Resource name: cpu라고 했을 때 이 두 Pod의 평균 CPU는 200이고 type: Utilization averageUtilization: 50이라고 정했다면 실제 CPU 사용률이 100(200 * 50%)이 넘게되면 HPA는 replicas를 증가시키게 된다.
예를 들어 두 Pod의 평균 CPU가 300일 때 현재 replicas는 2 300(평균 CPU) / 100(target(200 50%)) 하면 HPA가 증가시킬 replicas의 값이다. 6
만약 6개의 Pod가 있는 상태에서 평균 CPU가 50으로 떨어졌다면 6 50 / 100 = 3
3 50 / 100 = 1.5 -> 2(minReplicas)
