Deployment
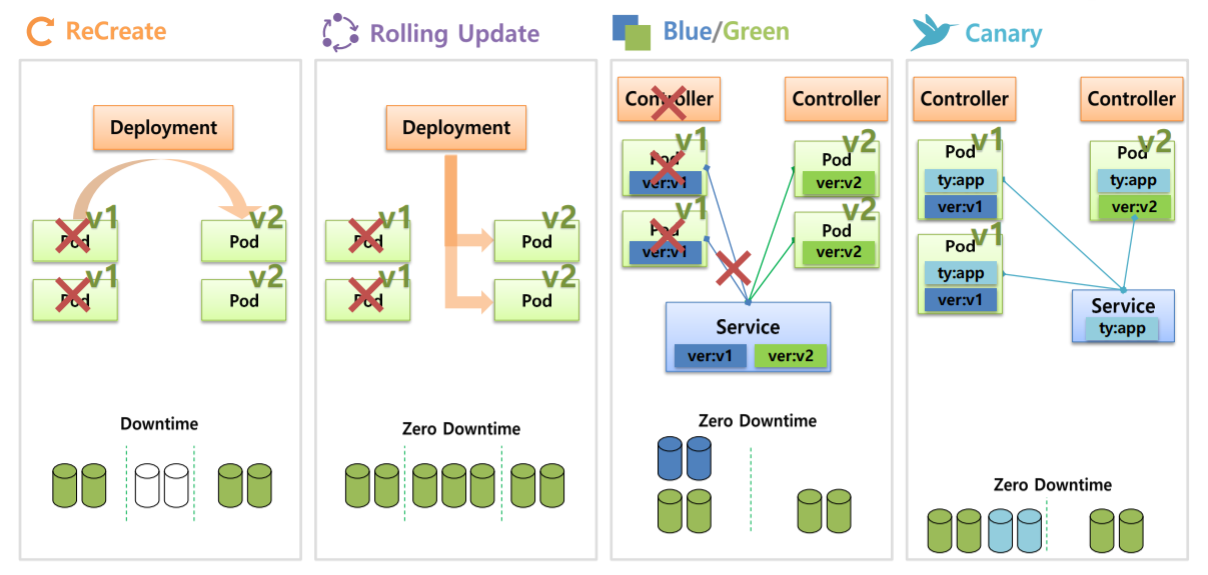
현재 한 Service가 운영중인데 이 Service를 Update해야되서 재배포해야 할 때 많은 도움이 되는 Controller다.
Recrete
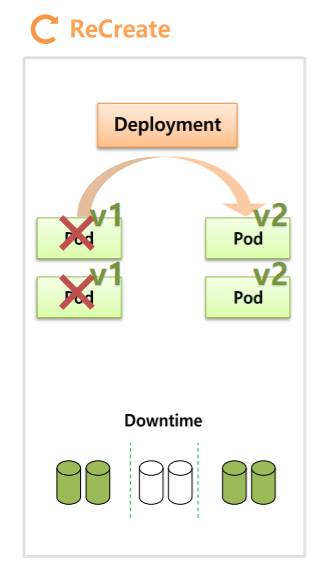
Deployment를 만들면 V1의 Pod들이 만들어진다.
Pod 하나당 하나씩 자원이 사용된다고 가정하면 (자원사용량 = 2)
만약 Recrete 방식으로 업데이트를 하면 Deployment는 우선 기존에 존재하고 있던 V1의 Pod들을 삭제한다. (자원사용량 = 2 -> 0)
그렇게되면 Service에 대한 DownTime이 발생하게 되고 자원사용량 또한 없어지게 된다.
그 다음에 V2에 대한 Pod들이 만들어지고 자원또한 할당된다. (자원사용량 = 0 -> 2)
이 방식은 DownTime이 발생하기 때문에 일시적인 정지가 가능할 때만 사용가능하다.
Rolling Update
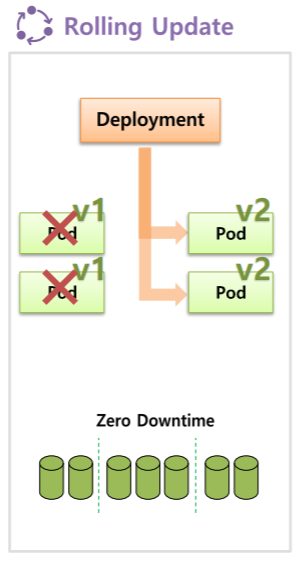
Recrete와 마찬가지로 V1 Pod에서 V2로 업그레이드를 하게 된다고 가정하면
Deployment는 먼저 V2의 Pod를 하나 만든다. 그리고 그만큼 자원사용량이 늘어난다. (자원사용량 = 2 -> 3)
이 상태부터는 V1과 V2의 모두 서비스가 되고 있기 때문에 누군가는 V1에 접속이 되고 누군가는 V2에 접속이 된다.
그런다음 Deployment는 V1의 Pod를 하나 삭제하고 (자원사용량 = 3 -> 2) 그 다음 다시 또하나의 V2 Pod를 만들고 (자원사용량 = 2 -> 3) 그리고 나서 마지막으로 V1의 Pod를 삭제하게 된다. (자원사용량 = 3 -> 2)
이제부터 사용자들은 V2의 서비스에만 접속하게 된다.
이 방식은 배포 중간에 추가적인 자원을 요구하지만 DownTime이 발생하지 않는다.
Bule/Green
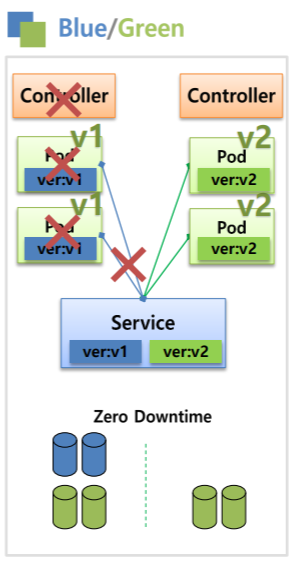
이 방식은 Deployment 자체에서 제공되는 기능이 아니고 Deployment를 사용해서 사용할 수도 있지만 ReplicaSet과 같이 replicas를 관리하는 모든 Controller를 이용해서 사용할 수 있다.
Controller를 만들어서 V1 Pod가 생성되면 Pod에는 Label이 있기 때문에 Service에 있는 Selector와 연결이 된다. (자원사용량 = 2)
이렇게 운영이 되어있는 상태에서 Controller를 하나 더 만들어서 V2 Pod를 생성하고 Label또한 V2로 만들면 자원사용량은 기존의 2배가 된다. (자원사용량 = 2 -> 4)
이 후 Service에 Selector만 V2의 label로 바꿔준다면 Service는 V2 Pod와 연결이 되고 V1 Pod들은 연결이 끊기게 된다.
그래서 사용자는 V2버전의 Service를 사용하게 되고 순간적으로 변경되기 때문에 Service에 대한 DownTime은 발생하지 않는다.
만약 V2에 문제가 발생하면 Service의 Selector를 V1의 Label로만 바꿔주게 되면 기존 서비스로 전환되어 롤백이 쉽다는 장점이 있다.
문제가 없으면 기존 버전은 삭제하면 된다.
이 방식은 많이 사용되고 안정적인 방법이지만 자원이 2배가 필요하다는 단점이 있다.
Canary
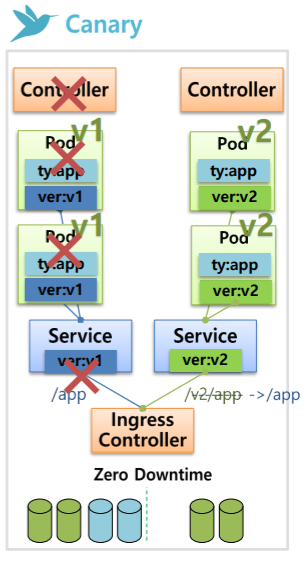
V1 Pod들이 있고 Label이 붙어 있어 Sevice(selector: type: app)와 연결되어 있는 상태라고 가정했을 때 (type: app, ver: v1)
테스트용으로 Controller를 만들 때 replicas=1로해서 V2 Pod를 하나 만들면 (type: app, ver: v2) Service에도 연결이 된다.
따라서 사용자는 V1또는 V2에도 접속이 가능하다. 따라서 V2에 대한 테스트가 가능해진다.
만약 테스트시 문제가 발생했다면 replicas=0으로 만들면 된다.
다른 방법으로는 V1은 V1대로 V2는 V2대로 각각의 Service를 만들고 IngressController를 이용해서 유입되는 path를 Service로 연결하여 테스트를 확인해 볼 수도 있다.
Deployment의 기능
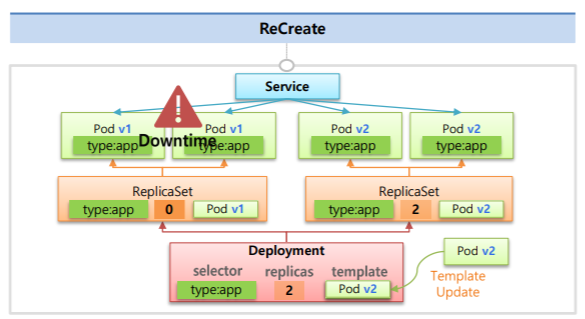
Deployment를 만들 때 ReplicaSet과 동일하게 selector, replicas, template 값을 동일하게 넣게 된다.
하지만 이 값들은 Deployment가 Pod를 직접 관리하기 위해 넣는 값들이 아니고 ReplicaSet을 만들고 여기에 값을을 지정하기 위한 용도이다.
따라서 ReplicaSet은 Deployment의 내용을 바탕으로 Pod들을 만들고 관리하게 된다.
Deployment에서 ReCrete하기 위해 Pod들의 버전을 업데이트하게 된다면
Deployment는 ReplicaSet의 replicas=0으로 변경한다.
그럼 ReplicaSet은 Pod들을 제거하고 Service 또한 연결 대상이 사라지기 때문에 이 떄 DownTime이 발생하게 된다.
그리고 새로운 ReplicaSet을 만들고 이 때 template에 새로 업데이트 된 Pod의 버전을 넣기 때문에
버전이 Update된 Pod들이 생성되고 서비스에 연결된다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-1
spec:
selector:
matchLabels:
type: app
replicas: 2
strategy:
type: Recreate
revisionHistoryLimit: 1
template:
metadata:
name: dp-pod
labels:
type: app
spec:
containers:
- name: container
image: nginx:1.14apiVersion: v1
kind: Service
metadata:
name: service-1
spec:
selector:
type: app
ports:
- port: 9000
protocol: TCP
targetPort: 8080Deployment의 strategy를 통해 배포 방식을 설정할 수 있다.
revisionHistoryLimit은 새로 업그레이드 될 때 replicas=0인 ReplicaSet을 몇개 남길지 정하는 옵션이다. (default= 10)
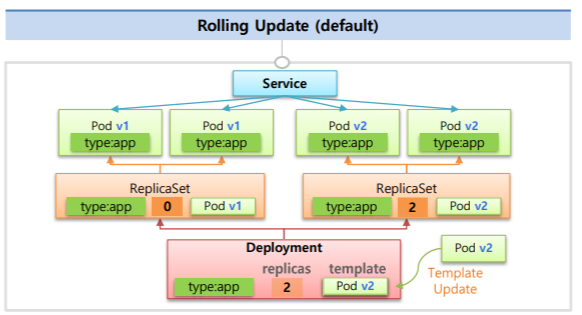
Service가 운영중인 상태에서 마찬가지로 새로운 버전으로 Template를 교체하게 되면 RollingUpdate가 실행되는데 먼저 replicas=1인 ReplicaSet을 먼저 만들고 Pod가 하나 만들어지면서 Service에 연결이 된다.
따라서 Service에 요청이 들어오면 V1과 V2에 분산이 되어서 들어오게 된다.
그런다음 기존 버전의 replicaSet을 개수를 하나 줄이고 새로운 버전의 replicaSet의 개수를 하나씩 늘리는 것을 반복한다.
RollingUpdate또한 ReCreate처럼 기존 버전의 ReplicaSet을 지우지 않는다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-2
spec:
replicas: 2
selector:
matchLabels:
type: app
strategy:
- type: RollingUpdate
mindReadySeconds: 10
template:
metadata:
name: dp-pod
labels:
type: app
spec:
containers:
- name: container
image: nginx:1.14minReadySeconds는 Update시에 텀을 가지고 Update가 진행된다.
