Node Scheduling
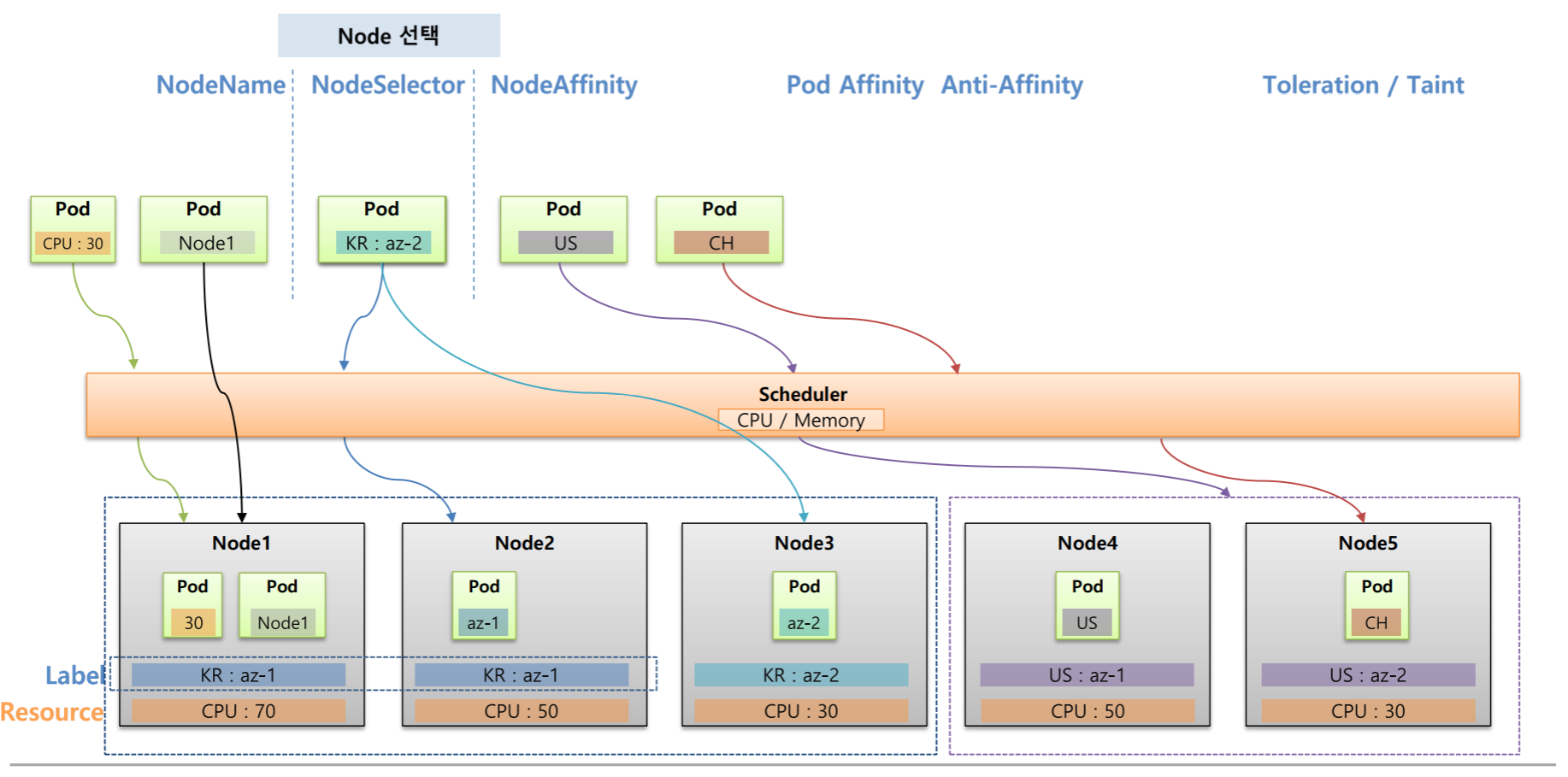
Pod는 기본적으로 쿠버네티스의 스케줄러에 의해서 Node에 할당되지만 사용자에 의해서 직접 Node를 할당하거나 특정 Node에 할당 하지 않도록 지정할 수 있다.
Node선택 : NodeName, NodeSelector, NodeAffinity
NodeName, NodeSelector, NodeAffinity : Pod를 특정 Node에 할당 되도록 선택하기 위한 용도로 사용된다.
위의 사진을 보면 5개의 Node들이 있고 각 Node마다 가용한 CPU 자원들이 있고 Label 또한 달려있다고 가정했을 떄
Node1~3은 서버가 한국에 있어서 KR : az- 라는 Label을 달아서 Grouping하고 Node4~5는 서버가 미국에 있어서 US : az- 라는 Label을 달아서 Grouping 해주었다.
이 상태에서 Pod를 하나 만들면 쿠버네티스의 스케줄러는 CPU자원이 가장 많은 Node에 이 Pod를 할당시킨다.
그런데 내가 원하는 Node를 선택하고 싶을 때
NodeName을 사용하면 스케줄러와 상관없이 해당 Node에 바로 할당된다.
명시적으로는 내가 원하는 Node에 할당할 수 있어서 좋아보이지만 실제 상용 환경에서는 Node가 삭제되고 재생성되는 과정에서 Node의 이름이 변경될 수 있기 때문에 잘 사용하지 않는다.
NodeSelector를 이용하여 Pod에 Key와 Value를 달면 해당 Label이 달려있는 Node에 할당된다.
그런데 Label의 특성상 여러 Node에 같은 Key와 Value를 가진 Label을 달 수 있기 때문에 스케줄러에 의해서 같은 Label이 있는 Node중에 자원이 많은 Node로 할당된다.
Key와 Value가 정확히 일치하는 Node에만 할당 된다는 점과 만약 매칭이 되는 Label이 없으면 Pod는 어느 Node에도 할당 되지 않기 때문에 에러가 발생한다는 단점이 있다.
NodeAffinity는 NodeSelector와 다르게 Pod에 Key만 설정해도 해당 그룹중에 스케줄러에 의해서 자원이 많은 Node에 할당이 되고 만약 해당 조건에 맞지않는 Key를 가지고 있더라도 스케줄러가 판단하여 자원이 많은 Node에 할당하도록 옵션을 줄 수도 있다.
Node Affinity - matchExpressions
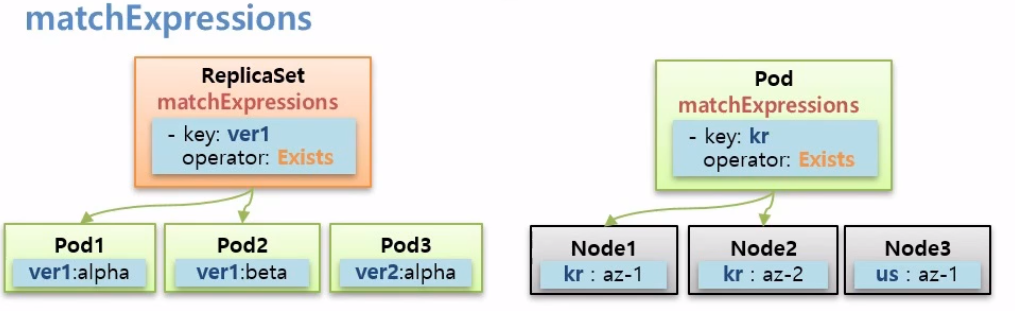
Node Affinity 설정으로 matchExpressions가 있다.
Key를 Grouping 단위로 Pod를 하위 식별자로 붙어진 Label들이 Node에 붙어져있고 Pod를 Key가 kr인 Group 안에 할당하고 싶을 때matchExpressions: - {key: kr, operator: Exists}같이 matchExpressions를 사용할 수 있다.
그럼 스케줄러는 Label이 kr인 Node들 중에 자원이 가장 많은 Node에 할당해준다.
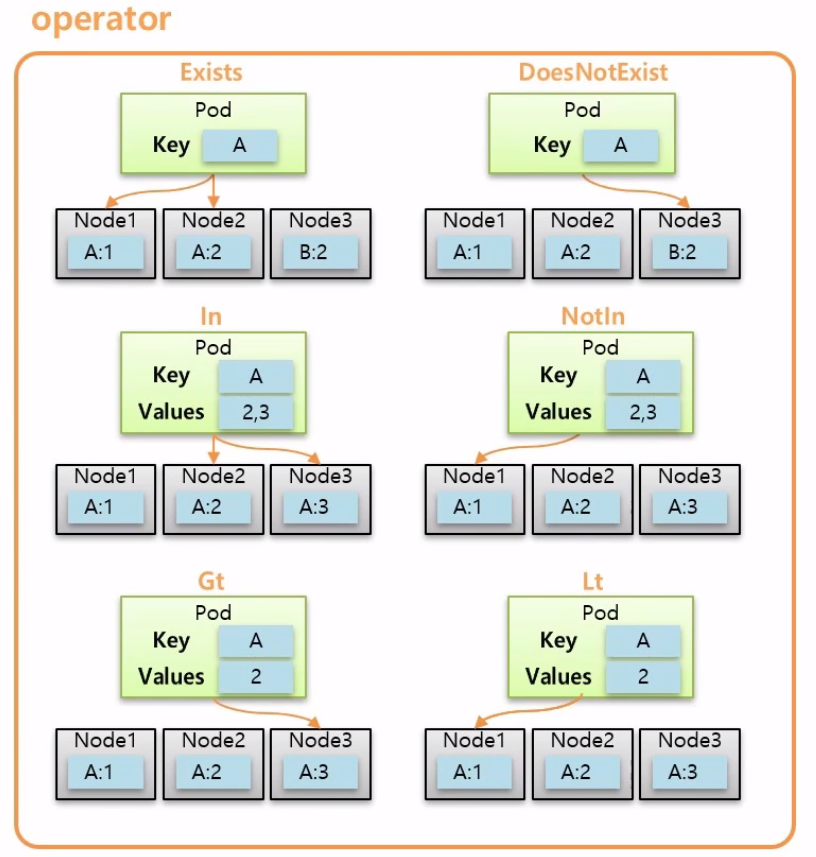
matchExpressions의 opeator의 옵션은 위의 사진과 같이 6가지가 있다.
Gt, Lt는 내가 지정한 Value보다 값이 크거나 작은 Node를 선택할 수 있다.
Node Affinity - required vs preferred
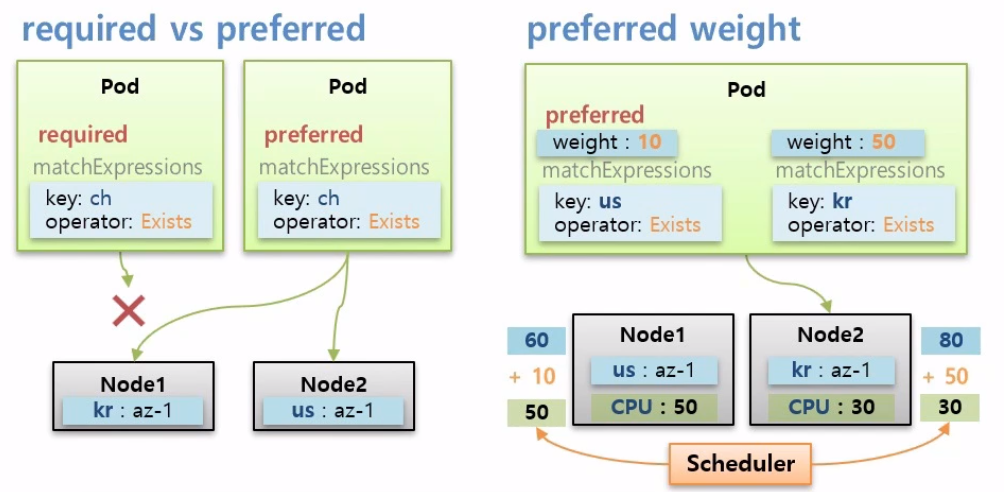
Node Affinity의 다음 속성으로 required와 preferred가 있다.
만약 node Affinity로 required를 가진 Pod가 Node에는 없는 Key를 가지고 있을 때 이 Pod는 Node에 스케줄링 되지 않는다.
반대로 node Affinity로 preferred를 가진 Pod가 Node에는 없는 Key를 가지고 있을 때 이 Pod는 Node에 스케줄링 되어 적절한 Node에 할당된다.
preferred weight
preferred 속성에는 weight라는 필수 값이 있다.
Key가 다른 2개의 Node가 있고 CPU는 50 vs 30 으로 Node1이 Node2보다 많다고 가정해보자.
그리고 preferred를 가진 Pod를 만드는데 두 Node에 모두 Key가 있기 때문에 두 Node 중 CPU 자원이 많은 Node1에 할당이 될 것이다.
weight에는 선호도에 대한 가중치를 줄 수 있는데 위의 사진을 보면 이 Pod는 key가 us나 kr인 Node에 할당 될 수 있다.
하지만 Pod의 preferred weight에 kr에 가중치(50)를 더 줬기 때문에 스케줄러는 최초 CPU 자원을 보고 점수를 매겨놔서 Node1에 할당을 시키려고 했지만 Pod의 가중치가 합산이 되면서 다시 점수를 매기게 된다.
그리고 다시 매긴 점수가 높은 쪽으로 Pod를 할당시킨다.
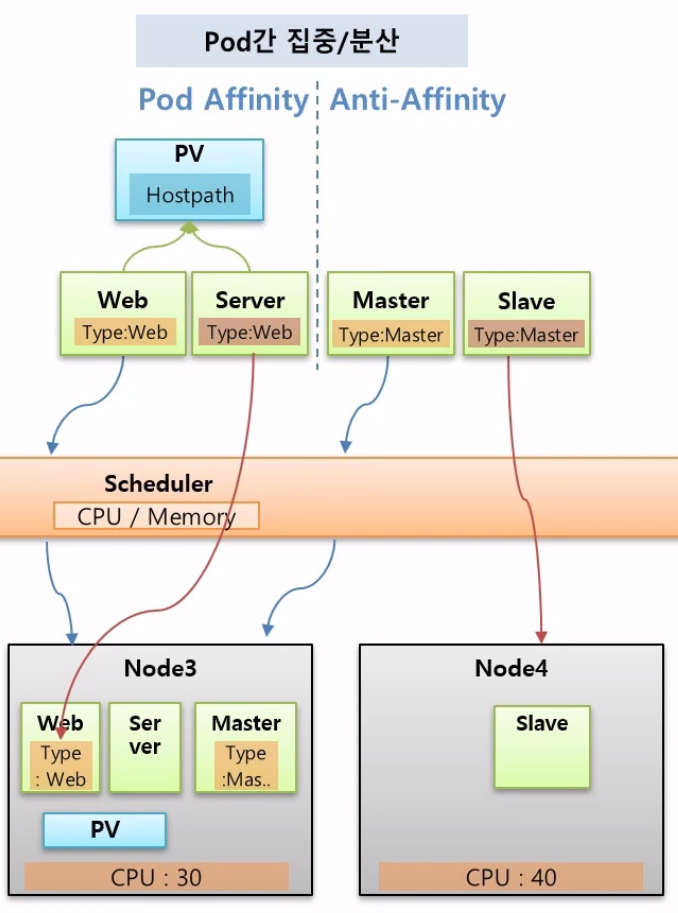
Pod Affinity, Anti-Affinity
Pod Affinity
여러 Pod들을 한 Node에 집중해서 할당하거나 Pod들 간에 겹치는 Node없이 분산해서 할당할 수 있다.
예를 들어 Web과 Server가 있는데 이 두 Pod는 한 PV에 연결되어 있고 이 PV가 hostPath를 쓴다고 했을 때 이 두 Pod는 같은 Node상에 있어야지만 문제가 발생하지 않는다.
그래서 두 Pod를 같은 Node에 할당하려면 Pod Affinity를 사용해야 하는데 동작을 보면 처음 Web Pod가 스케줄러에 의해서 특정 한 Node에 할당되면 그 hostPath에 PV가 생긴다.
그러면 이제 Server Pod가 Web Pod가 있는 Node에 들어가게 하려면 Pod를 만들 때 Pod Affinity 속성을 넣고 Web에 있는 Label을 지정하면 된다.
그렇게되면 Server Pod도 Web Pod가 있는 Node로 할당이 된다.
Anti-Affinity
Master와 Slave 두 Pod가 있다. Slave Pod는 Master Pod가 죽으면 백업을 해주는 Pod다.
두 Pod가 같은 Node로 들어갈 경우 해당 Node가 죽으면 두 Pod 모두 다운이 되기 때문에 서로 다른 Node에 스케줄링 되어야 한다.
Master가 스케줄링에 의하여 한 Node에 들어가고 Slave Pod를 만들 때 Anti-Affinity 속성을 넣고 Label에 MasterPod의 Key Value를 설정하면 이 Pod는 Master와 다른 Node에 할당된다.
Pod Affinity, Pod Anti-Affinity 상세 설명
Pod Affinity
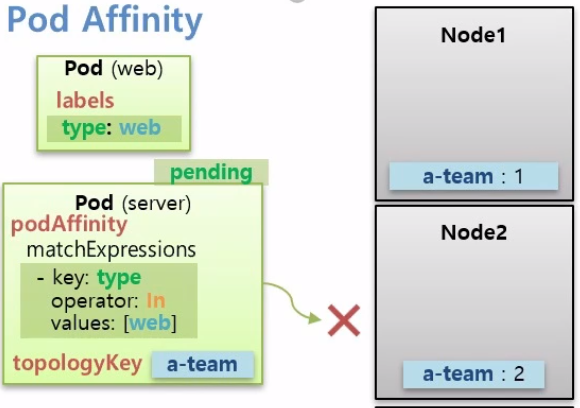
Node들이 있고 두 Node는 a-team이라는 Key를 가진 Label을 그리고 다른 두 Node는 b-team이라는 Key를 가진 Label이 있다고 가정해보자.
먼저 Pod Affinity는 type:web이라는 Label을 가진 Web Pod가 스케줄러에 의해서 Node1에 할당되었다.
그럼 이제 Server Pod를 이 Web Pod와 같은 Node에 넣으러면podAffinity: matchExpressions: - {key: type, operator: In, value:[web]} topologyKey: a-team이렇게 Pod에 podAffinity라는 속성으로 matchExpressions가 있는데 Node의 Label을 가리키는 것이 아니라 Pod와 매칭되는 Label의 조건을 찾는다. 그래서 Web Pod와 같은 Node에 할당된다.
topologyKey는 Node의 Key를 본다.
따라서 Node의 Key가 topologyKey와 매칭되는 Node에서만 matchExpressions로 Pod와 매칭되는 Label을 찾는다.
만약 Web Pod가 Key가 b-team인 Node3에 할당 되었다면 Server Pod는 Pending 상태가 되고 해당 조건이 만족할 떄까지 할당되지 않는다.
Pod Anti-Affinity
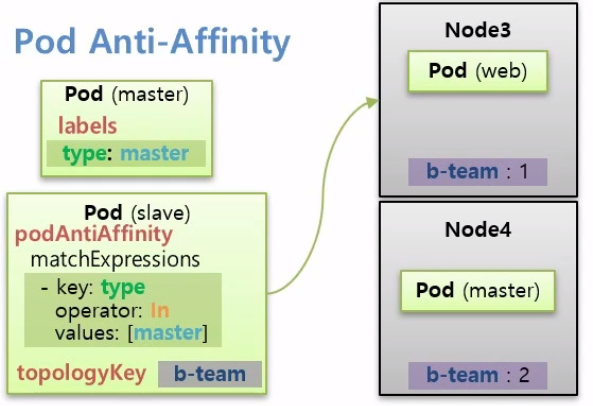
type이 master인 Master Pod가 Node4에 스케줄링 되었을 때 Slave Pod는 Node4가 아닌 다른 Node에 할당되기 위해서
podAntiAffinity matchExpressions: - {key: type, operator: In, value:[master]} topologyKey: b-teamSlave Pod를 생성할 때 podAntiAffinity 속성을 달고 위와 같이 matchExpressions로 Master Pod의 Label을 달면 Master Pod에 있는 Node에는 할당되지 않는다.
PodAffinity와 마찬가지로 topologyKey를 줘서 특정 Label이 있는 Node 범위로 설정할 수 있다.
또한 PodAntiAffinity도 podAffinity와 같이 required와 preferred 옵션이 적용된다.
Toleration / Taint
특정 Node에는 아무 Pod나 할당 되지 않도록 제한하는 상황에서 사용된다.
예를 들어 Node5는 높은 사양의 그래픽을 요구하는 App을 돌리는 용도로 GPU를 설정해놓았을 때
운영자는 Taint라는 설정도 해놓는다.
그러면 일반적인 Pod들은 스케줄러가 이 Node로 할당시키지 않는다.
Pod가 직접 Node를 지정해도 할당되지 않는다.
이 Node에 할당되려면 Pod는 Toleration을 달고 와야지만 할당이 된다.
Toleration / Taint 상세 설명
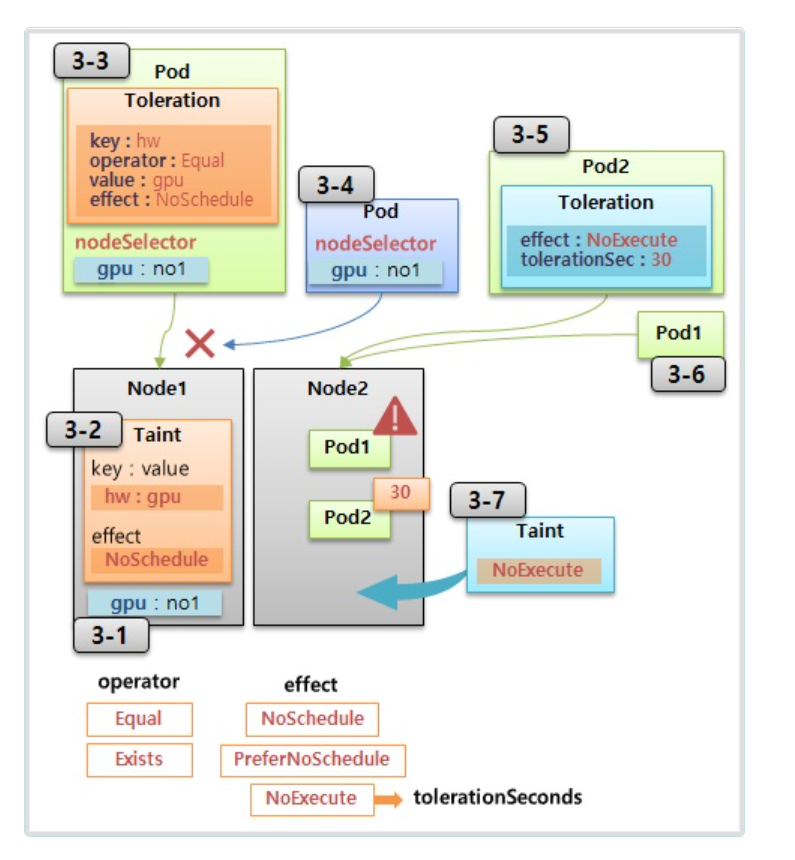
위의 사진을 보면 Node1은 다른 Node들과 달리 GPU가 구성되어있다고 가정해보자.
일반적인 Pod들이 Node1으로 할당되는 것을 방지하려면 Taint라는 것을 Node1에 달아주면 된다.
Taint 내용에는 Taint를 식별하는 Label인 Key와 Value가 있고 effect라는 옵션이 있어서 NoSchedule이라는 옵션을 주면 Pod들이 Node1에 할당되지 않는다.
cf) effect에는 PreferNoSchedule이라는 옵션도 있는데 이 옵션은 가급적 스케줄링이 안되도록 하는 옵션이다.
따라서 Pod들이 정말로 할당될 Node가 없을 경우에는 Taint가 붙어있는 Node1에 할당 될 수도 있다.
cf) 또한 effect에는 NoExecute라는 옵션도 있는데 NoSchedule과 차이점을 비교하자면 Pod1이 Node2에 할당되어서 운영이 되고 있다고 가정했을 때 NoSchedule 상태를 가진 옵션을 Node2에 달면 Pod1은 이미 Node2에 할당 되어있는 상태이므로 삭제되지 않고 정상적으로 운영된다.
이와 반대로 Node2에 Taint NoExecute 옵션을 달면 그 안에 있는 Pod1은 삭제가 된다.
Node2에 Taint가 달려있어도 Pod가 삭제되지 않기 위해서는 Pod를 만들 때 마찬가지로 Node2와 매칭되는 Toleration을 달면 된다. 하지만 또 tolerationSeconds라는 옵션이 있는데 이게 없으면 삭제가 되지 않지만 이걸 달아주면 해당 시간이 지난 후에는 삭제가 된다.
다시 위의 내용으로 가자면 Node1에는 일반적인 Pod들이 할당되지 않는다.
그런데 실제로 GPU를 사용하는 Pod여서 Node1에 할당되어야 할 경우에는 Pod를 만들 때 Toleration을 주면 된다.
내용으로는 Key, Operator, Value가 있고 이 조건이 Taint의 Label과 맞아야 하고 Operator의 옵션으로는 Equal과 Exists만 있다. 그리고 effect의 옵션까지 모두 매칭이 되어야지만 Node1에 할당할 수 있다.
만약 위에 조건 중 하나라도 만족하지 못한다면 Node1에 할당되지 않는다.
Pod에 Toleration으로 매칭되는 Taint가 있는 Node를 찾는다고 생각할 수도 있는데 그게 아니라 Pod가 Node1에 스케줄링 되었을 때 Pod에는 Node1의 Taint와 매칭되는 Toleration이 있기 때문에 Node1에 할당될 수 있는 조건에 부합되는 것이다.
이 말은 즉 Pod 상태에서는 다른 Node에서도 스케줄링 될 수 있다는 점이다.
따라서 별도의 nodeSelector를 달아서 이 Pod가 Node1에 할당될 수 있도록 해야 한다.
정리를 하면 Taint를 단 Node에는 아무 Pod나 들어올 수 없고 해당 Taint와 매칭이 되는 Toleration을 단 Pod만 허락되지만 Pod가 해당 Node로 스케줄링 되도록 하는 건 nodeSelector같이 별도의 옵션을 추가해야 한다.
쿠버네티스에서의 NoSchedule, NoExecute
NoSchedule은 Master Node에 기본적으로 달려 있어서 Pod를 만들 때 Master Node에 할당이 되지 않도록 하고 있고 ReplicaSet에 의해 Pod가 운영중인데 Node에 장애가 발생하게 되면 쿠버네티스는 해당 Node에 있는 Pod들이 정상적으로 동작하지 않을 수 있기 때문에 NoExecute 옵션의 Taint를 해당 Node에 달아준다.
그렇게 되면 ReplicaSet은 자신의 Pod가 하나 없어졌기 때문에 다른 Node에 Pod를 다시 만들어서 Service가 잘 유지될 수 있도록 해준다.
