Pod - ReadinessProbe, LivenessProbe의 필요성
우리가 Pod를 만들면 그 안에 Container가 생기고 Pod와 Container의 상태가 Running이 되면서 그 안에 있는 App도 정상적으로 구동이 될 것이다.
그리고 Service에 연결 되고 Service의 IP가 외부에 알려지면서 외부에서는 이 Service를 통해 많은 사용자들이 접근할 수 있다.
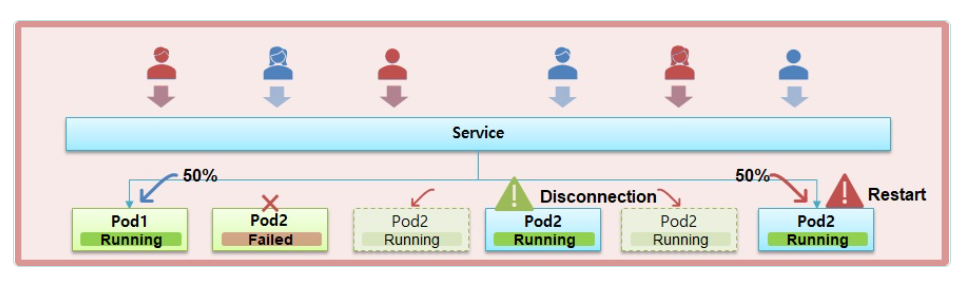
Service에 Pod가 2개 연결되어 있고 각각의 Pod들에게 50%씩 트래픽이 분산되고 있다고 가정해보자.
만약 Node2가 갑자기 다운이 되었다면 그 안에 있는 Pod2의 상태가 Failed가 되면서 트래픽이 Node1로 100% 요청이 들어올 것이다.
하지만 Pod1이 이 트래픽을 견뎌준다면 Service에 유지되는데 문제가 없다.
그리고 죽은 Pod2는 Controller의 Auto Healing 기능을 통해 Node3(다른노드)에 재생성될 것인데
그 과정에서 Pod와 Container가 Running 상태가 되면서 Service와 연결이 되는데 아직 App이 구동(Booting)중인 순간이 발생한다. 하지만 Service가 연결이 되자마자 Pod2로 트래픽이 유입되기 때문에 App이 구동(Booting)되고 있는 순간에는 사용자는 50%의 확률로 에러페이지를 보게 된다.
하지만 Pod를 만들 때 ReadinessProbe를 주게 되면 이러한 문제를 피할 수 있다.
ReadinessProbe가 App이 구동되기 전까지는 Service와 연결이 되지 않게 해주기 때문이다.
따라서 Pod2의 상태가 Running이지만 트래픽은 Pod1에게만 가게 되고 App이 완전히 준비된 것이 확인된 이후(Running)에야 Service와 연결을 해서 트래픽을 받게된다.
그러다가 Pod2의 App이 다운되었고 Pod2는 Running 상태라고 가정해보자.
이런 상황이 될려면 톰캣은 돌고 있지만 그 위의 메모리가 Overflow 라던지 문제가 생겨서 접속이 되면 5xx 에러가 발생할 때다.
이 때는 톰캣 자체의 프로세스가 죽은게 아니라 그 위에 돌고 있는 서비스에 문제가 생긴거라 톰캣 프로세스를 보고있는 Pod입장에서는 계속 Running 상태로 있게 될 것이고 이 상황이되면 Pod2로 오고 있는 트래픽은 다시 문제가 될 것이다.
이 때 App에 대한 장애 상황을 감지해주는 것이 바로 LivenessProbe다.
Pod를 만들 때 LivenessProbe를 달아주면 해당 App에 문제가 되면 Pod를 재실행하게 만들어서 잠깐의 트래픽 에러는 발생하겠지만 지속적으로 에러상태가 되는 것을 방지해준다.
ReadinessProbe를 통해 App이 구동되는 순간에 트래픽 실패를 없애고 LivenessProbe를 통해 App 장애시 지속적인 에러를 방지할 수 있어 안정적인 서비스를 운영할 수 있게 해준다.
ReadinessProbe와 LivenessProbe의 속성
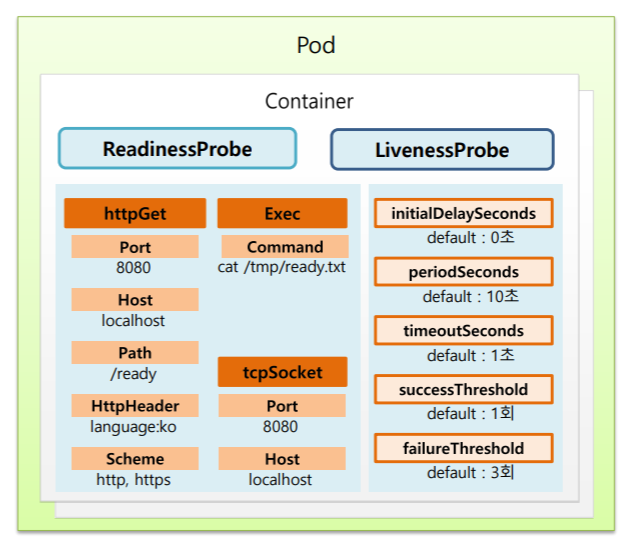
ReadinessProbe와 LivenessProbe의 공통적으로 들어갈 수 있는 속성을 보면 httpGet, Exec, tcpSocket으로 해당 App에 대한 상태를 확인할 수 있고 상세적으로 httpGet에 경우 Port 번호나 Host이름, Path 경로, HttpHeader, Scheme를 체크할 수 있다.
Exec는 특정 명령어를 날려서 그에 따른 결과를 체크할 수 있다.
tcpSocket은 Port, Host 명을 체크해서 ReadinessProbe와 LivenessProbe에 대한 성공 여부를 체크할 수 있다.
이 셋중에 하나는 반드시 정해야 하는 속성이다.
아래의 값들은 반드시 필요한 속성이 아닌 옵션 값들이다.
만약 아래의 옵션들을 설정하지 않았을 경우 default값으로 설정이 된다.
- initialDelaySeconds: Probe를 하기 전에 Delay되는 시간 (default: 0초)
- periodSeconds: Probe를 체크하는 시간의 간격 (default: 10초)
- timeoutSeconds: 이 지정된 시간까지 결과가 나오는데 시간 (default: 1초)
- successThreshold: 몇 번 성공 결과를 받아야 진짜 성공이라고 인정할 건지 결정 (default: 1회)
- failureThreshold: 몇 번 실패 결과를 받아야 진짜 실패라고 인정할 건지 결정 (default: 3회)
ReadinessProbe
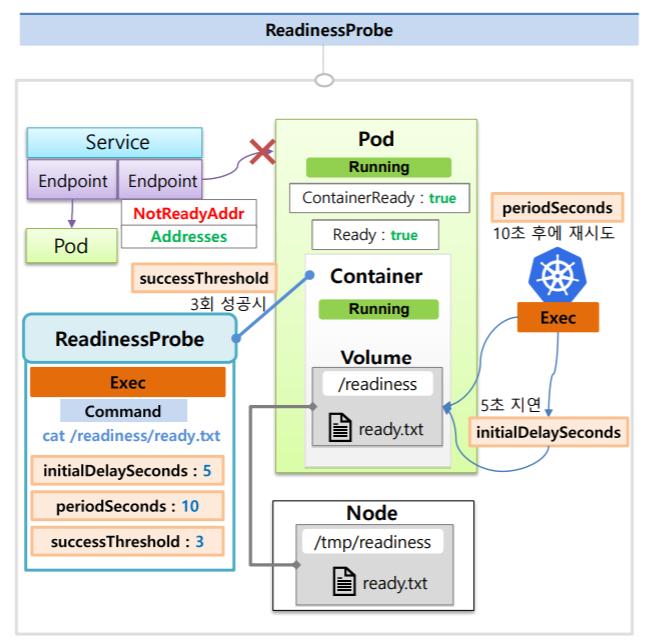
위의 사진 예시를 보면 한 Service에 Pod가 연결되어있는 상태에서 Pod를 하나 더 만들건데 Container의 hostPath로 Node에 Volume이 연결되어 있다. 그리고 그 Container에 ReadinessProbe를 설정하는데 ReadinessProbe는 Exec의 명령어(Command)를 통해서 ready.txt를 조회해보는 예시다.
옵션으로는 최초 딜레이 시간은 5초, 체크 간격 시간은 10초, 성공 확인 여부는 3회라고 지정했다.
이렇게 ReadinessProbe를 설정했다면 Pod를 만들 때 Node가 스케줄되고 이미지가 다운받아지면서 Pod와 Container의 상태는 Running이 되지만 이 Probe가 성공하기 전까지는 Condition에 ContainerReady는 false, Ready는 false로 바뀌지 않는다.
그래서 이 상태가 계속 false로 유지된다면 EndPoint에서는 이 Pod의 Ip를 NotReadyAddr로 간주하고 Service에 연결하지 않는
다.
이제 쿠버네티스가 ReadinessProbe에 정의된대로 App 서비스의 기동 상태를 체크하는데 Container상태가 Running이 되면 최초 5초 동안 지연하고 있다가 5초가 지나면 ready.txt 파일이 있는지 체크해보고 파일이 없다면 10초 후에 다시 체크하게 된다. 그런데 계속 체크하는 파일이 없다면 이 Pod의 Condition은 false로 유지가 될 것이고 이 Node의 ready.txt라는 파일을 추가하면 현재 Container의 Volume과 연결되어 있으니까 다음 ReadinessProbe를 체크할 때 성공결과를 받게 될 것이다. 그리고 총 3번의 성공 결과를 받게 되면 Condition의 상태는 true가 되고 EndPoint도 정상적으로 Address로 간주하면서 Service와 연결된다.
LivenessProbe
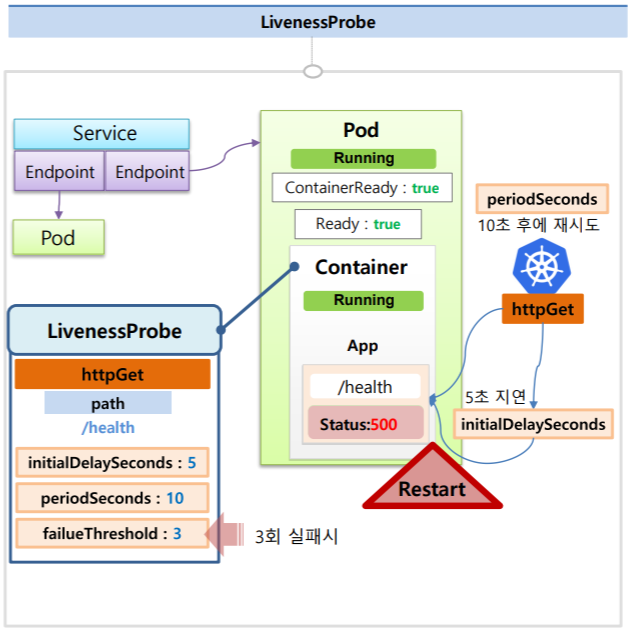
한 Service에 두 Pod가 Running되고 있는 상태고 이 중 한 App에 대한 내용을 보면 /health라는 경로를 날리면 Status 200을 주면서 Service가 정상적으로 운영중이라는 healthCheck가 만들어져있다.
그리고 이 Container에는 LivenessProbe가 달려있고 내용으로는 httpGet으로 /health라는 path경로를 체크한다.
옵션으로는 최초 5초 지연과 10초 간격으로 체크, 3번을 실패하면 Pod가 재시작되도록 설정하였다.
쿠버네티스가 httpGet으로 5초 후에 해당 path를 체크해보고 200 OK를 받을 것이다.
그리고 10초 후에 또 체크를 해보지만 마찬가지로 200 OK를 받으면서 Service가 정상적으로 운영중이라고 판단을 하게 된다.
그런데 어느 순간부터 이 path를 호출하면 InternalServer Error를 발생하면서 500 Status를 받게된다. 즉 Service에 장애가 발생한 것이다.
하지만 Pod는 Running 상태 이기 때문에 500 에러를 3회 받게 되면 쿠버네티스는 문제가 있다고 판단하여 이 Pod를 Restart하게 된다.
