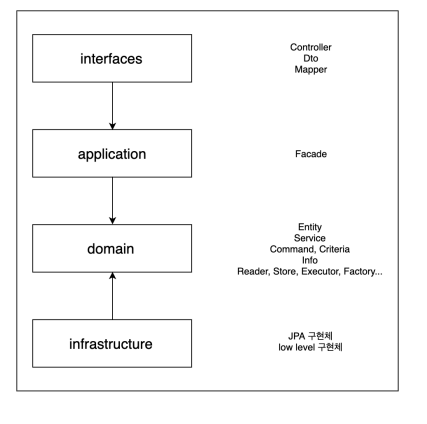
Layer 계층
Layer 계층
레이어간의 참조 관계에서는 단방향 의존을 유지하고 계층간 호출에서는 인터페이스를 통한 호출이 되어야 한다.
Layer 별 특징과 역할
사용자 인터페이스(interfaces)
사용자에게 정보를 보여주고 사용자의 명령을 해석하는 책임을 진다.
ex) Controller, Dto, Mapper(Converter)
응용 계층 (application)
수행할 작업을 정의하고 표현력 있는 도메인 객체가 문제를 해결하게 한다.
이 계층에서 책임지는 작업은 업무상 중요하거나 다른 시스템의 응용 계층과 상호 작용하는 데 필요한 것들이다.
이 계층은 얇게 유지되고, 오직 작업을 조정하고 아래에 위치한 계층에 포함된 도메인 객체의 협력자에게 작업을 위임한다.
ex) Facade
도메인 계층 (domain)
업무 개념과 업무 상황에 대한 정보, 업무 규칙을 표현하는 일을 책임진다.
이 계층에서는 업무 상황을 반영하는 상태를 제어하고 사용하며, 그와 같은 상태 저장과 관련된 기술적인 세부사항은 인프라 스트럭쳐에 위임한다.
이 계층이 업무용 소프트웨어의 핵심이다.
ex) Entity, Sevice, Command, Criteria, Info, Reader, Store, Executor, Factory(interface)
인프라 스트럭쳐 (infrastructure)
상위 계층을 지원하는 일반화된 기술적 기능을 제공한다.
이러한 기능에는 애플리케이션에 대한 메시지 전송, 도메인 영속화, UI에 위젯을 그리는 것 등이 있다.
ex) low level 구현체 (ReaderImpl, StoreImpl, Spring JPA, RedisConnector ...)
Layer간 참조 관계
- Layer 간의 참조 관계에서 application과 infrastructure는 domain layer를 바라보게 하고 양방향 참조는 허용하지 않게 한다.
- domain layer는 low level의 기술에 상관없이 독립적으로 존재할 수 있어야 한다.
- 이를 위해 대부분의 주요 로직은 추상화되고, 런타임시에는 DIP 개념을 활용하여 실제 구현체가 동작하게 한다.
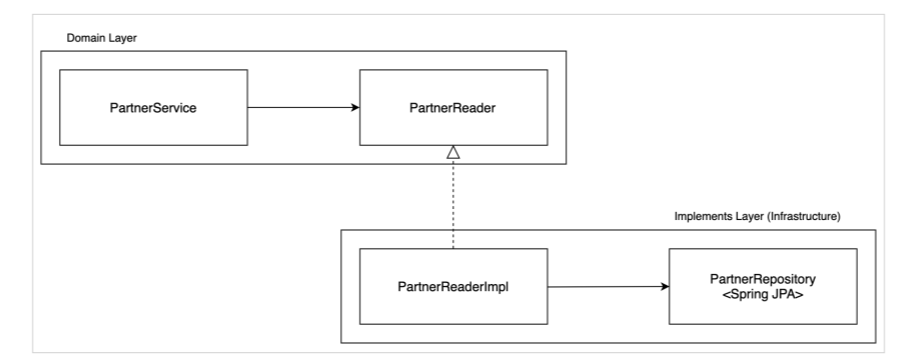
domain layer
1. domain layer에서의 Service에서는 해당 도메인의 전체 흐름을 파악할 수 있도록 구현되어야 한다.
- 이를 위해서 추상화 레벨을 많이 높여야 한다.
- 도메인 로직에서는 어떤 기술을 사용했는지는 중요하지 않다. 어떤 업무를 어떤 순서로 처리했는지가 더욱 중요한 관심사이다.
- 도메인 업무는 적절한 interface를 사용하여 추상화하고 실제 구현은 다른 layer에 맡기는게 맞다.
- 세세한 기술 구현은 Service가 아니라 infrastructure의 implements 클래스에 위임하고, Service에서는 이를 활용하기 위한 interface를 선언하고 사용한다.
- DIP를 활용하여 도메인이 사용하는 interface의 실제 구현체를 주입받아(injection) 사용할 수 있도록 한다.
- 영속화된 객체를 로딩하기 위해 Spring JPA를 사용할 수도 있지만 Querydsl을 사용할 수도 있는 것이다. domain layer에서는 객체를 로딩하기 위한 추상화된 interface를 사용하고, 실제 동작은 하위 layer의 기술 구현체에 맡긴다.
2. domain layer에서의 모든 클래스 명이 XxxxService로 선언될 필요는 없다.
- 하나의 도메인 패키지 내에 수많은 Service 클래스가 존재하게 되면, 도메인 전체의 흐름을 컨트롤하는 Service가 무엇인지 알기 어렵다.
- 주요 도메인의 흐름을 관리하는 Service는 하나로 유지하고, 이를 위한 support 역할을 하는 클래스는 Service 이외의 네이밍을 가져가는 것이 좋다.
- 또한 하나의 책임을 가져가는 각각의 구현체는 그 책임과 역할에 맞는 네이밍으로 선언하는 것이 가독성에 좋다.
- 적절한 예시
- XxxxReader
- XxxxStore
- XxxxExecutor
- XxxxFactory
- XxxxAggregator
- 다만 해당 구현체는 domain layer에서는 interface로 추상화하고 실제 구현체는 infrastructure layer에서 구현한다.
- 즉 domain layer에서는 도메인 로직의 흐름을 표현하고 구현하는 Service와 ServiceImpl이 있지만 그 외에 상세한 구현은 Reader, Store, Executor 같은 interface를 선언하여 사용하고 이에 대한 실제 구현체는 infrastructure layer에 두고 활용한다.(DIP)
3. Service 간에는 참조 관계를 가지지 않도록 한다.
- DDD의 Aggragate Root 개념을 알고 있다면 도메인 내의 Entity 간에도 상하 관계가 명확히 생긴다는 것을 알게 된다.
- 이와 마찬가지로 Service 로직을 구현하다보면 좀 더 상위 레벨의 Service와 하위 레벨의 Service가 도출되기 마련인데, 이런 구조를 허용하게 되면 상위 레벨의 Service가 하위 레벨의 Service를 다수 참조하게 되면서 로직이 구성된다.
- 이는 테스트 코드 작성을 어렵게ㅐ하고 가독성을 떨어지게 한다.
- Service 간에는 참조 관계를 가지지 않도록 원칙을 세우는 것이 좋다.
- Service 내의 로직은 추상화 수준을 높게 가져가고
- 각 추상화의 실제 구현체는 잘게 쪼개어 만들면 도메인의 전체 흐름이 파악되면서도 로직이 간결하게 유지되는 코드를 가져갈 수 있다.
Infrastructure Layer
상위 계층을 지원하는 일반화된 기술적 기능을 제공한다.
1. domain layer에 선언되고 사용되는 추상화된 interface를 실제로 구현하여 런타임 시에는 실제 로직이 동작하게 한다.
- DIP 개념을 활용한다.
2. 세세한 기술 스택을 활용하여 domain의 추상화된 interface를 구현하는 것이 비교적 구현에서의 자유도를 높게 가져갈 수 있다.
3. Service 간의 참조 관계는 막았지만, infrastructure layer에서의 구현체 간에는 참조 관계를 허용한다.
- infrastruture 에서의 구현체는 domain layer에 선언된 interface를 구현하는 경우가 대부분이므로 Service에 비해 의존성을 많이 가지지 않게 된다.
- 로직의 재활용을 위해 infrastructure 내의 구현체를 의존 관계로 활용해도 된다.
- 다만 이 과정에서도 순환 참조가 발생하지 않도록 적절한 상하관계를 정의하는 것이 좋다.
4. @Component를 활용한다.
- Spring 내의 동일한 Bean 이라도 @Service와 @Component를 구분하여 선언하여 명시적인 의미를 부여하고자 한다.
- Spring 에서 @Service와 @Component는 동일하게 class를 bean으로 등록하고 큰 차이는 없지만 annotation을 통해 해당 class의 의미를 부여할 수 있다.
Application Layer
- 수행할 작업을 정의한다.
- 도메인 객체가 문제를 해결하도록 지시한다.
- 다른 애플리케이션 계층과의 상호 작용을 한다.
- 비즈니스 규칙은 포함하지 않으며, 작업을 조정하고, 다음 하위 계층에서 도메인 객체의 협력을 위해 업무를 위임한다.
- 그렇게 때문에 해당 Layer는 얇게 유지 된다.
- 작업을 조정하기만 하고 도메인의 상태를 가지면 안된다.
1. application layer에서는
- transaction으로 묶여야 하는 도메인 로직과
- 그 외의 로직을 aggregation 하는 역할로 한정 짓는다.
- 그러므로 해당 로직이 두꺼워질 요소는 없다.
2. 해당 Layer의 클래스 네이밍은 xxxFacade로 정한다.
- Facade의 개념은 복잡한 여러 개의 API를 하나의 인터페이스로 aggregation하는 역할이지만
- 우리가 정의하는 application layer내의 Facade는 서비스 간의 조합으로 하나의 요구사항을 처리하는 클래스로 정의하였다.
3. 실제적인 요구사항을 예시로 하여 Facade 구현을 정의해보면 다음과 같다.
- "주문 완료 후 유저에게 카카오톡으로 주문 성공 알림이 전달된다." 라는 요구사항이 있다.
- 주문 처리 과정에서의 모든 도메인 로직은 하나의 transaction으로 묶여야 합성에 이슈가 없다.
- 그러나 주문 완료 직후의 카카오톡 알림 발송이 실패하더라도, 주문 로직이 전체 롤백될 필요는 없다.
- 카카오톡 알림 발송이 실패했더라도 유저는 메인 서비스를 통해서 주문 완료를 확인할 수 있기 때문에
- Facade내에 주문 완료 메소드 구현은 다음과 같다.
public String completeOrder(OrderCommand.RegisterOrder registerOrder) { var orderToken : String = orderService.completeOrder(registerOrder); notificationService.sendKakao("ORDER_COMPLETE", "content"); return orderToken; }
- Facade 안의 completeOrder 메소드에는 transaction을 선언하지 않는다.
- orderService.completeOrder(registerOrder) 내에는 transaction이 선언되어 있고 주문 완료 처리 중에 예외가 발생하면 Order Aggregate 전체 데이터가 rollback이 된다. (정합성이 지켜진다.)
- orderService.completeOrder(registerOrder)가 성공하고 notification.sendKakako()가 실패하더라도, 주문완료 처리는 rollback 되지 않는다.
- Order Aggregate의 정합성은 지키면서도, 주요 도메인 로직에는 포함되지 않는 외부 서비스 call(카카오 알림 발송)은 성공/실패에 크게 민감하지 않게 요구사항을 처리하게 된다.
Interfaces Layer
사용자에게 정보를 보여주고 사용자의 명령을 해석하는 책임을 진다.
1. API를 설계할 떄에는 없어도 되는 Request Parameter는 제거하고, 외부에 리턴하는 Response도 최소한을 유지하도록 노력한다.
- 요구하는 Request Parameter가 많다는 것은 관련된 메소드나 객체에서 처리해야 하는 로직이 많다는 것을 의미하고, 이는 관련된 객체가 생가보다 많은 역할을 하고 있따는 신호일 수 있다.
- Response의 경우도 불필요한 응답을 제공하고 있고 이를 가져다 쓰는 외부 로직이 있다면, 추후 해당 Response에서 특정 프로퍼티는 제거하기 어렵게 될 수 있다.
- API는 한번 외부에 오픈하면 바꿀 수 없는것이라고 생각해야한다. 따라서 처음부터 제한적으로 설계하고 구현해야 한다.
2. HTTP, gRPC, 비동기 메시징과 같은 서비스간 통신 기술은 Interfaces Layer에서만 사용되도록 한다.
- 가령 JSON 처리 관련 로직이나 http cookie 파싱 로직 등이 Domain Layer에서 사용되는 식의 구현은 피해야 한다.
- 그렇게 하지 않으면 언제든지 교체될 수 있는 외부 통신 기술로 인해 domain 로직까지 변경되어야 하는 상황이 발생한다.

현시깁니다