비즈니스 로직과 트랜잭션
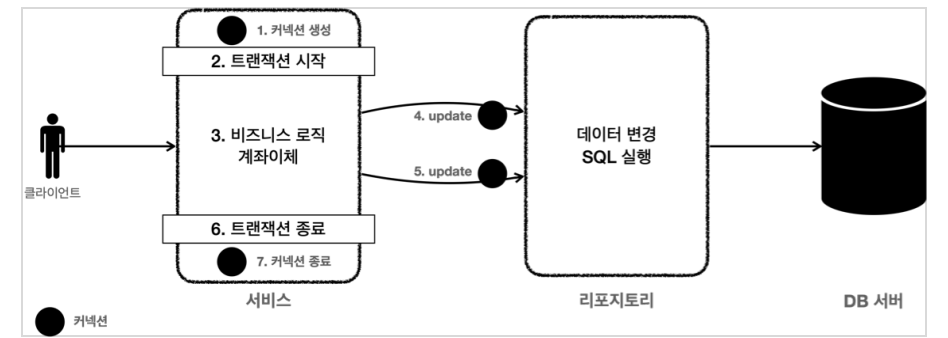
- 트랜잭션은 비즈니스 로직이 있는 서비스 계층에서 시작해야 한다.
비즈니스 로직이 잘못되면 해당 비즈니스 로직으로 인해 문제가 되는 부분을 함께 롤백해야 하기 때문이다.
- 그런데 트랜잭션을 시작하려면 커넥션이 필요하다.
결국 서비스 계층에서 커넥션을 만들고 트랜잭션 커밋 이후에 커넥션을 종료해야 한다.
- 애플리케이션에서 DB 트랜잭션을 사용하려면 트랜잭션을 사용하는 동안 같은 커넥션을 유지해야 한다.
그래야 같은 세션을 사용할 수 있다.
커넥션과 세션
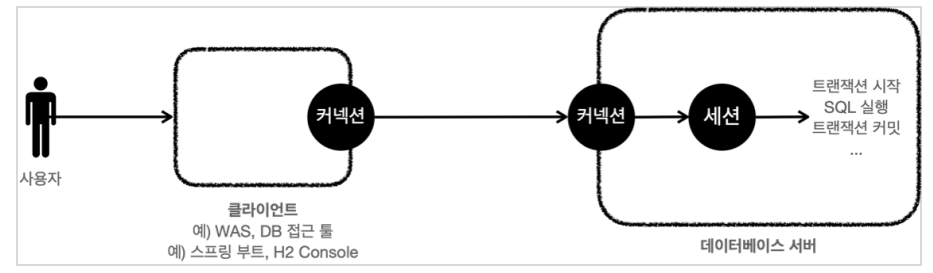
- 애플리케이션에서 같은 커넥션을 유지하려면 어떻게 해야 할까?
가장 단순한 방법은 커넥션을 파라미터로 전달해서 같은 커넥션이 사용되도록 유지하는 것이다.
- 하지만 애플리케이션에서 DB 트랜잭션을 적용하러면 서비스 계층이 매우 지저분해지고 생각보다 매우 복잡한 코드를 요구하게 된다.
추가로 커넥션을 유지하도록 코드를 변경하는 것도 쉬운 일이 아니다.
문제점들
애플리케이션 구조
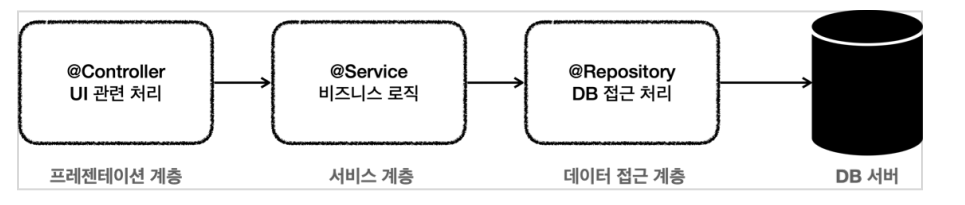
서비스 계층
- 애플리케이션 구조에서 서비스 계층이 제일 중요하다.
UI(웹)와 관련된 부분이 변하고 데이터 저장 기술을 다른 기술로 변경해도 비즈니스 로직은 최대한 변경 없이 유지되어야 한다.
변경없이 유지하기 위해선?
서비스 계층을 특정 기술에 종속적이지 않게 개발해야 한다.
- 애플리케이션 구조를 계층별로 나눈 이유도 서비스 계층을 최대한 순수하게 유지하기 위한 목적이 크다.
기술에 종속적인 부분은 프레젠테이션 계층, 데이터 접근 계층에서 가지고 간다.
- 프레젠테이션 계층은 클라이언트가 접근하는 UI와 관련된 기술인 웹, 서블릿, HTTP와 관련된 부분을 담당해준다.
그래서 서비스 계층을 이런 UI와 관련된 기술로부터 보호해준다.
ex) HTTP API -> GRPC 로 변경
- 데이터 접근 계층은 데이터를 저장하고 관리하는 기술을 담당해준다.
그래서 JDBC, JPA 같은 구체적인 데이터 접근 기술로부터 서비스 계층을 보호해준다.
ex) JDBC -> JPA로 변경
- 서비스 계층이 특정 기술에 종속되지 않기 때문에 비즈니스 로직을 유지보수 하기도 쉽고 테스트 하기도 쉽다.
- 정리하면 서비스 계층은 가급적 비즈니스 로직만 구현하고 특정 구현 기술에 직접 의존해서는 안된다.
이렇게 하면 향후 구현 기술이 변경될 때 변경의 영향 범위를 최소화 할 수 있다.
트랜잭션 적용한 비즈니스 로직의 문제점 (스프링 X)
@Slf4j
@RequiredArgsConstructor
public class MemberServiceV2 {
private final DataSource dataSource;
private final MemberRepositoryV2 memberRepository;
public void accountTransfer(String fromId, String toId, int money) throws SQLException {
final var con = dataSource.getConnection();
try {
con.setAutoCommit(false); // 트랜잭션 시작
// 비즈니스 로직
bizLogic(fromId, toId, money, con);
con.commit(); // 성공 시 커밋
} catch (Exception e) {
con.rollback(); // 실패 시 롤백
throw new IllegalStateException(e);
} finally {
release(con);
}
}
private void bizLogic(String fromId, String toId, int money, Connection con) throws SQLException {
final var fromMember = memberRepository.findById(con, fromId);
final var toMember = memberRepository.findById(con, toId);
memberRepository.update(con, fromId, fromMember.getMoney() - money);
validation(toMember);
memberRepository.update(con, toId, toMember.getMoney() + money);
}
private void release(Connection con) {
if (con != null) {
try {
con.setAutoCommit(true); // 커넥션 풀 고려
con.close();
} catch (Exception e) {
log.error("error", e);
}
}
}
- 트랜잭션은 비즈니스 로직이 있는 서비스 계층에서 시작하는 것이 좋다.
- 그런데 문제는 트랜잭션을 사용하기 위해서 DataSource, Connection, SQLException 같은 JDBC 기술에 의존해야 한다는 점이다.
- 트랜잭션을 사용하기 위해 JDBC 기술에 의존한다.
결과적으로 비즈니스 로직보다 JDBC를 사용해서 트랜잭션을 처리하는 코드가 더 많다.
- 또한 향후 JDBC에서 JPA 같은 다른 기술로 바꾸어 사용하게 되면 서비스 코드도 모두 함께 변경해야 한다.
(JPA는 트랜잭션을 사용하는 코드가 JDBC와 다르다.)
- 핵심 비즈니스 로직과 JDBC 기술이 섞여 있어서 유지보수 하기 어렵다.
문제 정리
- 트랜잭션 문제
- 예외 누수 문제
- JDBC 반복 문제
트랜잭션 문제
JDBC 구현 기술이 서비스 계층에 누수되는 문제
- 트랜잭션을 적용하기 위해 JDBC 구현 기술이 서비스 계층에 누수되었다.
- 서비스 계층은 순수해야 한다. -> 구현 기술을 변경해도 서비스 계층 코드는 최대한 유지할 수 있어야 한다. (변화에 대응)
- 그래서 데이터 접근 계층에 JDBC 코드를 다 몰아두는 것이다.
- 물론 데이터 접근 계층의 구현 기술이 변경될 수도 있으니 데이터 접근 계층은 인터페이스를 제공하는 것이 좋다.
- 서비스 계층은 특정 기술에 종속되지 않아야 한다.
하지만 트랜잭션을 적용하면서 서비스 계층에 JDBC 구현 기술의 누수가 발생했다.
트랜잭션 동기화 문제
- 같은 트랜잭션을 유지하기 위해 커넥션을 파라미터로 넘겨야 한다.
- 이때 파생되는 문제들도 있다.
똑같은 기능도 트랜잭션용 기능과 트랜잭션을 유지하지 않아도 되는 기능으로 분리해야 한다.
트랜잭션 적용 반복 문제
- 트랜잭션 적용 코드를 보면 반복이 많다.
ex) try, catch, finally
예외 누수
- 데이터 접근 계층의 JDBC 구현 기술 예외가 서비스 계층으로 전파된다.
- SQLException은 체크 예외이기 때문에 데이터 접근 계층을 호출한 서비스 계층에서 해당 예외를 잡아서 처리하거나 명시적으로 throws를 통해서 다시 밖으로 던져야 한다.
- SQLException은 JDBC 전용 기술이다. 향후 JPA나 다른 데이터 접근 기술을 사용하면 그에 맞는 다른 예외로 변경해야 하고 결국 서비스 코드도 수정해야 한다.
JDBC 반복 문제
- try, catch, finally 같은 유사한 코드의 반복이 너무 많다.
- 커넥션을 열어 PerparedStatement를 사용하고 결과를 매핑하고 커넥션과 리소스를 정리하는 코드도 반복이 많다.

현시깁니다