
📝 컬렉션 프레임워크(Collection Framework)
- 기존 배열의 문제점을 해결하고, 다수의 데이터를 쉽게 처리할 수 있는
표준화 된 방법을 제공하는 클래스이다.
자바 컬렉션 프레임워크는 몇 가지 인터페이스를 통해서 다양한 컬렉션 클래스를
이용할 수 있도록 한다.
주요 인터페이스로는 List, Set, Map이 있다.
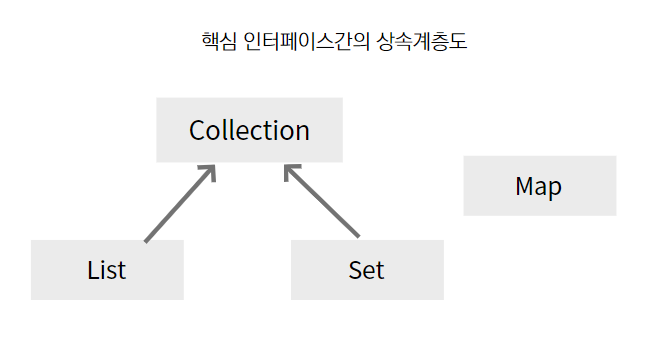
List와 Set은 서로 많은 공통점이 있어서,
공통된 부분을 모아 collection 인터페이스를 정의할 수 있지만
Map은 다른 형태로 컬렉션을 다루기 때문에 같은 상속계층도에 포함되지 못했다.
| 인터페이스 | 특징 | 구현클래스 |
|---|---|---|
| List | 순서가 있는 데이터의 집합 데이터 중복을 허용 | ArrayList, LinkedList, Stack, Vector |
| Set | 순서가 없는 데이터의 집합 데이터의 중복을 허용하지 않음 | HashSet, TreeSet |
| Map | 키(Key)와 값(value)의 쌍으로 이루어진 데이터의 집합 순서는 유지되는 않는다. 키(Key)는 중복을 허용하지 않지만, 값(value)은 중복을 허용한다. | HashMap, TreeMap, Hashtable, Properties |
List 인터페이스
- 객체를 일렬로 늘어놓은 구조를 가지고 있다.
- 객체를 인덱스로 관리하기 때문에 객체를 저장하면 자동 인덱스가 부여되고
인덱스로 객체를 검색, 삭제할 수 있는 기능을 제공한다. - List 인터페이스는 중복을 허용하면서 저장순서가 유지되는 컬렉션을
구현하는데 사용된다.
List 인터페이스에 정의된 메서드
| 메서드 | 설명 |
|---|---|
| void add(int index, Object element) boolean addAll(int index, Collection c) | 지정된 위치(index)에 객체(element) 또는 컬렉션에 포함된 객체들을 추가한다. |
| Object get(int index) | 지정된 위치(index)에 있는 객체를 리턴한다. |
| int indexOf(Object o) | 지정된 객체의 위치(index)를 리턴한다. (List의 첫 번째 요소부터 순방향으로 찾는다.) |
| int lastIndexOf(Object o) | 지정된 객체의 위치(index)를 리턴한다. (List의 마지막 요소부터 순방향으로 찾는다.) |
| int size() | 저장되어 있는 객체의 개수를 리턴한다. |
| Object remove(int index) | 지정된 위치(index)에 있는 객체를 삭제한다. |
| void clear() | 저장된 모든 객체를 삭제한다. |
| Object set(int index, Object element) | 지정된 위치(index)에 객체(element)를 저장한다. |
| void sort(Comparator c) | 지정된 비교자(comparator)로 List를 정렬한다. |
| List subList(int fromIndex, int toIndex) | 지정된 범위(fromIndex부터 toIndex)에 있는 객체를 반환한다. |
ArrayList
-
배열기반
-
ArrayList는 List 인터페이스를 상속받는 클래스로, 데이터를 이름표 없이
무제한으로 보관할 수 있다.
-
ArrayList에 추가되는 데이터는 저장순서가 유지되고 중복을 허용한다.
-
ArrayList에서 특정 인덱스의 객체를 삭제하거나 추가할 경우
바로 뒤 인덱스부터 인덱스가 바뀐다.
📌 일반 배열과의 차이점 📌
- 배열은 생성할 때 크기가 고정되고 사용 중에 크기를 변경할 수 없지만,
ArrayList는 저장 용량(capacity)가 초과한 객체들이 들어오면
자동적으로 저장 용량(capacity)이 늘어난다. ArrayList의 선언
List<저장할 객체 타입> list = new ArrayList<저장할 객체 타입>();✍ ArrayList 코드 예시)
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> numberList = new ArrayList<Integer>();
// 데이터 추가하기
for (int i = 1; i <= 10; i++) {
numberList.add(i);
}
System.out.println("데이터의 크기 : " + numberList.size());
System.out.println("--------------------------------");
// 5번째 요소의 값 얻기,
System.out.println("5번째 요소의 값 : " + numberList.get(4));
System.out.println("--------------------------------");
// 5번째 요소의 값 삭제
numberList.remove(4);
// 하나를 삭제 후, 전체 크기 다시 조회
System.out.println("데이터의 크기 : " + numberList.size());
System.out.println("--------------------------------");
// 5번째 요소의 값 다시 얻기
System.out.println("5번째 요소의 값 : " + numberList.get(4));
System.out.println("--------------------------------");
// 5번째 자리에 데이터 추가
numberList.add(4, 123);
System.out.println("5번째 요소의 값 : " + numberList.get(4));
System.out.println("--------------------------------");
// 전체 삭제
numberList.clear();
System.out.println("데이터의 크기 : " + numberList.size());
}
}👉 실행 결과
데이터의 크기 : 10
--------------------------------
5번째 요소의 값 : 5
--------------------------------
데이터의 크기 : 9
--------------------------------
5번째 요소의 값 : 6
--------------------------------
5번째 요소의 값 : 123
--------------------------------
데이터의 크기 : 0LinkedList
-
LinkedList는 List 구현 클래스이므로 ArrayList와 사용 방법은 똑같지만
내부 구조는 완전히 다르다. -
ArrayList는 모든 데이터가 연속적으로 존재하지만
LinkedList는 불연속적으로 존재하는 데이터를 서로 연결(link)한 형태로 구성되어 있다.- LinkedList의 각 요소들은 자신과 연결된 다음 요소에 대한 참조(주소값)와
데이터로 구성되어 있다.
- LinkedList의 각 요소들은 자신과 연결된 다음 요소에 대한 참조(주소값)와
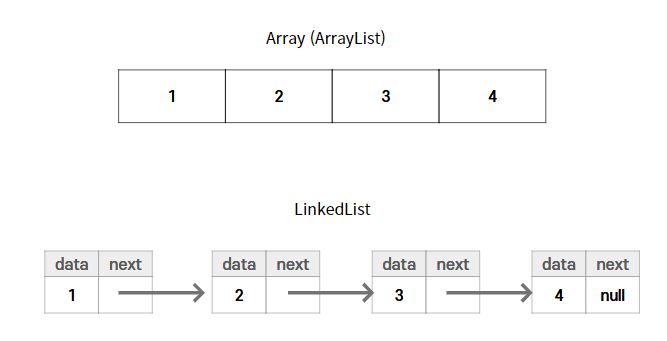
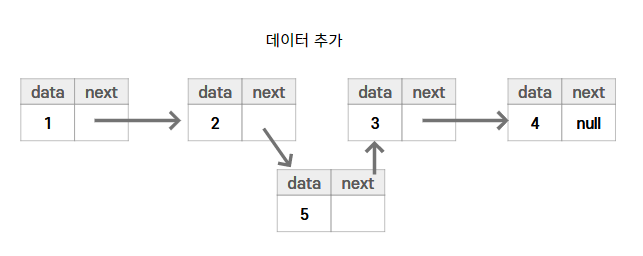
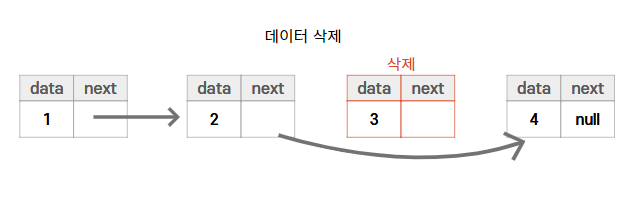
- 특정 인덱스의 객체를 추가 또는 삭제할 경우 앞뒤 링크만 변경되고 나머지 링크는
변경되지 않는다.- 앞뒤 링크 정보만 변경하면 되므로 처리속도가 매우 빠르다.
- LinkedList는 불연속적으로 위치한 각 요소들이 서로 연결된 것이라
처음부터 n번째 데이터까지 차례대로 따라가야만 원하는 값을 얻을 수 있다.
그래서 LinkedList는 저장해야하는 데이터의 개수가 많아질수록
데이터를 읽어 오는 시간(접근시간)이 길어진다는 단점이 있다.
- ArrayList와 LinkedList의 비교
| 컬렉션 | 읽기 (접근시간) | 순차적 추가/삭제 | 중간에 추가/삭제 | 비고 |
|---|---|---|---|---|
| ArrayList | 빠르다 | 빠르다 | 느리다 | 비효율적인 메모리 사용 검색이 빠르다 |
| LinkedList | 느리다 | 느리다 | 빠르다 | 데이터가 많을수록 접근성이 떨어진다. 검색이 느리다 |
LinkedList의 선언
List<저장할 객체 타입> list = new LinkedList<저장할 객체 타입>();Set 인터페이스
- 중복을 허용하지 않고 저장순서가 유지되지 않는다.
- 하나의 null만 저장할 수 있다.
- 인덱스로 관리하지 않기 때문에 인덱스를 매개값으로 갖는 메서드가 없다.
Set 인터페이스에 정의된 메서드
| 메서드 | 설명 |
|---|---|
| boolean add(Object o) | 주어진 객체를 저장 객체가 성공적으로 저장되면 true, 중복 객체면 false를 리턴한다. |
| boolean contains(Object o) | 주어진 객체가 저장되어 있는지 확인한다. |
| void clear() | 저장된 모든 객체를 삭제한다. |
| boolean remove(Object o) | 주어진 객체를 삭제한다. |
| boolean equals(Object o) | 동일한 컬렉션인지 비교한다. |
| boolean isEmpty() | 컬렉션이 비어 있는지 확인한다. |
| lterator iterator() | 저장된 객체를 한 번씩 가져오는 반복자 리턴 |
| int size() | 저장되어 있는 전체 객체 수 리턴한다. |
- Set 컬렉션은 인덱스로 객체를 검색해서 가져오는 메서드가 없다.
그래서 전체 객체를 대상으로 한번씩 반복해서 가져오는 반복자(Iterator)를
제공한다.
Iterator 인터페이스
- Iterator는 컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스이다.
- iterator() 메서드를 호출하면 얻을 수 있다.
Iterator 인터페이스에 선언된 메서드
| 리턴 타입 | 메서드명 | 설명 |
|---|---|---|
| boolean | hasNext() | 가져올 객체가 있으면 true, 없으면 false를 리턴한다. |
| E (제네릭 타입) | next() | 컬렉션에서 하나의 객체를 가져온다. next() 메서드를 사용하기 전에 hasNext() 메서드로 가져올 객체가 있는지 확인하는 것이 좋다. |
| void | remove() | Set 컬렉션에서 객체를 제거한다. |
HashSet
-
Set인터페이스를 구현한 가장 대표적인 컬렉션이며, 중복된 요소를
저장하지 않는다. -
이미 저장되어 있는 요소와 중복된 요소를 추가하고자 한다면
add메서드는 false를 리턴함으로써 중복된 요소이기 때문에 추가에
실패했다는 것을 알린다. -
저장 순서를 유지하지 않으므로 저장순서를 유지하고자 한다면
LinkedHashSet을 사용해야한다.
중복을 걸러내는 과정
-
HashSet은 객체를 저장하기 전에 먼저 객체의 hashCode() 메서드를 호출해서
해시코드를 얻어낸다.
-> 그리고 이미 저장되어 있는 객체들의 해시코드와 비교한다. -
동일한 해시코드가 있다면 다시 equals() 메서드로 두 객체를 비교해서 true가
나오면 동일한 객체로 판단하고 중복 저장을 하지 않는다.
HashSet의 선언
Set<저장할 객체 타입> set = new HashSet<저장할 객체 타입>(); ✍ HashSet 코드 예시)
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Set<String> color = new HashSet<String>();
// 데이터 추가하기
color.add("Red");
color.add("Blue");
color.add("Black");
color.add("White");
color.add("Pink");
System.out.println("데이터의 크기 : " + color.size());
System.out.println("numSet = " + color); // 저장순서를 유지하지 않는다.
System.out.println("--------------------------------");
// 중복된 값 추가
// -> 중복된 값은 저장되지 않는다.
color.add("Red");
System.out.println("데이터의 크기 : " + color.size());
System.out.println("--------------------------------");
// 데이터 전체 출력하기
Iterator<String> ite = color.iterator();
while(ite.hasNext()) { // 값이 있으면 true, 없으면 false
System.out.print(ite.next() + " ");
}
System.out.println("\n--------------------------------");
// 데이터 삭제
color.remove("Blue");
// 값 검색하기
System.out.println(color.contains("Blue"));
System.out.println(color.contains("Red"));
}
}👉 실행 결과
데이터의 크기 : 5
numSet = [Red, White, Pink, Blue, Black]
--------------------------------
데이터의 크기 : 5
--------------------------------
Red White Pink Blue Black
--------------------------------
false
trueTreeSet
- 이진 탐색 트리(binary search tree)라는 자료구조의 형태로 데이터를
저장하는 컬렉션 클래스이다. - 중복된 데이터의 저장을 허용하지 않으며 정렬된 위치에 저장하므로
저장순서를 유지하지도 않는다.
TreeSet의 선언
TreeSet<저장할 객체 타입> treeSet = new TreeSet<저장할 객체 타입>();이진 탐색 트리(binary search tree)
- 이진 트리의 한 종류로
정렬, 검색, 범위검색(range search)에 높은 성능을 보이는 자료구조이다.
이진 트리(binary tree)란?
- 여러 개의 노드(node)가 트리 형태로 연결된 구조로,
'루트(root)'라고 불리는 하나의 노드에서부터 시작해서 각 노드에 최대 2개의
노드를 연결할 수 있는 구조를 가지고 있다.
- 위 아래로 연결된 두 노드를 '부모-자식관계'에 있다고 하며
위의 노드를 부모 노드, 아래의 노드를 자식 노드라 한다.
- 하나의 부모 노드는 최대 두 개의 자식 노드와 연결될 수 있다.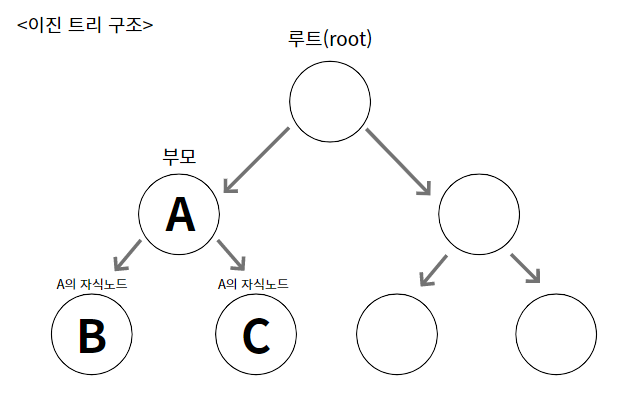
- 이진 탐색 트리는
왼쪽 자식노드의 값은 부모노드의 값보다 작고,
오른쪽 자식노드의 값은 부모노드의 값보다 커야한다.
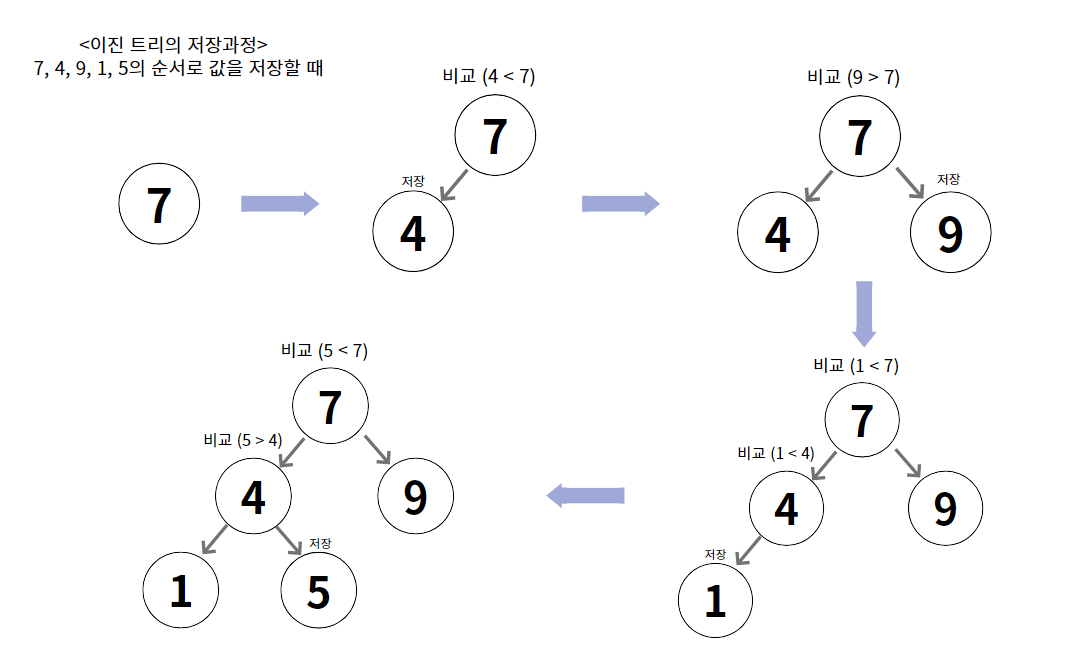
왼쪽 마지막 값에서부터 오른쪽 값까지 값을 '왼쪽 노드 -> 부모 노드 -> 오른쪽노드'
순으로 읽어오면 오름차순으로 정렬된 순서를 얻을 수 있다.
-
즉, 정렬에 유리하다.
-
TreeSet은 이처럼 정렬된 상태을 유지하기 때문에 단일 값 검색과 범위검색이
매우 빠르다. -
하지만 반복 비교로 자리를 찾아 저장하기 때문에 노드의 추가 삭제에 시간이 걸린다.
TreeSet의 메서드
| 생성자 또는 메서드 | 설명 |
|---|---|
| Comparator comparator() | TreeSet의 정렬기준(Comparator)을 반환 |
| NavigableSet descendingSet() | TreeSet의 저장된 요소들을 역순으로 정렬해서 반환 |
| Object first() | 정렬된 순서에서 첫 번째 객체(제일 낮은 객체)를 반환 |
| Object last() | 정렬된 순서에서 마지막 객체(제일 높은 객체)를 반환 |
| Object lower(Object o) | 지정된 객체보다 작은 값을 가진 객체 중 제일 가까운 값의 객체를 반환 없으면 null |
| Object higher(Object o) | 지정된 객체보다 높은 값을 가진 객체 중 제일 가까운 값의 객체를 반환 없으면 null |
| Object floor(Object o) | 지정된 객체와 같은 객체를 반환 없으면 작은 값을 가진 객체 중 제일 가까운 객체를 반환 없으면 null |
| Object ceiling(Object o) | 지정된 객체와 같은 객체를 반환 없으면 높은 값을 가진 객체 중 제일 가까운 객체를 반환 없으면 null |
| Object pollFirst() | TreeSet의 첫 번째 요소(제일 작은 값의 객체)를 반환 후 컬렉션에서 제거함 |
| Object pollLast() | TreeSet의 마지막 요소(제일 높은 값의 객체)를 반환 후 컬렉션에서 제거함 |
| NavigableSet headSet(Object toElement, boolean inclusive) | 지정된 객체보다 작은 값의 객체들을 반환 inclusive가 true이면, 같은 값의 객체도 포함 |
| NavigableSet tailSet(Object toElement, boolean inclusive) | 지정된 객체보다 높은 값의 객체들을 반환 inclusive가 true이면, 같은 값의 객체도 포함 |
| NavigableSet sunSet(Object fromElement, boolean fromInclusive, Object toElement, boolean toInclusive | 범위 검색(fromElement와 toElement사이)의 결과를 반환 fromInclusive가 true면 시작값이 포함되고, toInclusive가 true면 끝값이 포함된다. |
✍ TreeSet 코드 예시)
import java.util.NavigableSet;
import java.util.TreeSet;
public class Main {
public static void main(String[] args) {
TreeSet<Integer> scores = new TreeSet<Integer>();
// 데이터 추가하기
scores.add(new Integer(87));
scores.add(new Integer(64));
scores.add(new Integer(98));
scores.add(new Integer(75));
scores.add(new Integer(95));
scores.add(new Integer(80));
// 특정 객체 찾기
System.out.println("가장 낮은 점수 : " + scores.first());
System.out.println("가장 높은 점수 : " + scores.last() + "\n");
System.out.println("90점 아래 점수 : " + scores.lower(new Integer(90)));
System.out.println("90점 위의 점수 : " + scores.higher(new Integer(90)) + "\n");
// 객체 정렬하기
NavigableSet<Integer> descendingSet = scores.descendingSet();
for (Integer score : descendingSet) {
System.out.print(score + " ");
}
System.out.println("\n");
// pollFirst() 메서드
while (!scores.isEmpty()) {
System.out.println(scores.pollFirst() + " [남은 객체 수 : "
+ scores.size() + "]" );
}
}
}👉 실행 결과
가장 낮은 점수 : 64
가장 높은 점수 : 98
90점 아래 점수 : 87
90점 위의 점수 : 95
98 95 87 80 75 64
64 [남은 객체 수 : 5]
75 [남은 객체 수 : 4]
80 [남은 객체 수 : 3]
87 [남은 객체 수 : 2]
95 [남은 객체 수 : 1]
98 [남은 객체 수 : 0]✍ TreeSet 코드 예시2)
import java.util.NavigableSet;
import java.util.TreeSet;
public class Main {
public static void main(String[] args) {
TreeSet<String> words = new TreeSet<String>();
words.add("apple");
words.add("cherry");
words.add("forever");
words.add("zoo");
words.add("dance");
words.add("car");
words.add("flower");
words.add("green");
// 범위 검색하기
System.out.println("[c~f 사이의 단어 검색]");
NavigableSet<String> rangeSearch = words.subSet("c", true, "g", true);
for(String word : rangeSearch) {
System.out.println(word);
}
}
}👉 실행 결과
[c~f 사이의 단어 검색]
car
cherry
dance
flower
foreverMap 인터페이스
- 키(key)와 값(value)을 하나의 쌍으로 묶어서 저장하는 컬렉션
클래스를 구현하는데 사용된다.- 여기서 키와 값은 모두 객체이다.
- 키는 중복될 수 없지만 값은 중복을 허용한다.
- 기존에 저장된 데이터와 중복된 키와 값을 저장하려면 기존의 값은 없어지고,
마지막에 저장된 값이 남게 된다. - 키로 객체들을 관리하기 때문에 키를 매개값으로 갖는 메서드가 많다.
Map 인터페이스에 정의된 메서드
| 메서드 | 설명 |
|---|---|
| Object put(Object key, Object value) | 주어진 키로 값을 저장 새로운 키일 경우 null을 리턴하고 동일한 키가 있을 경우 값을 대체하고 이전 값을 리턴한다. |
| void clear() | Map의 모든 객체를 삭제 |
| Object remove(Object key) | 지정한 key객체와 일치하는 key-value객체를 삭제 |
| boolean containsKey(Object key) | 지정된 키가 있는지 여부 |
| boolean containsValue(Object value) | 지정된 값이 있는지 여부 |
| Set keySet() | Map에 저장된 모든 key객체를 리턴 |
| Collection values() | 저장된 모든 값을 Collection에 담아서 리턴 |
| Set entrySet() | Map에 저장되어 있는 key-value쌍을 Map.Entry타입의 객체로 저장한 Set으로 리턴 |
| Object get(Object key) | 지정된 키가 있는 값을 리턴 |
| boolean equals(Object o) | 동일한 Map인지 비교 |
| boolean isEmpty() | Map이 비어있는지 여부 |
| int size() | 저장된 키의 총 수를 리턴 |
HashMap
- Map 인터페이스를 구현한 대표적인 Map 컬렉션이다.
- Map의 특징, 키(key)와 값(value)을 묶어서 하나의 데이터(entry)로
저장한다는 특징을 갖는다. - 해싱(hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어서
뛰어난 성능을 보인다. - 키(key)는 주로 String을 많이 사용한다.
- 키는 저장된 값을 찾는데 사용되는 것이기 때문에 컬렉션 내에서
유일(unique)해야 한다. - String은 문자열이 같은 경우 동등 객체가 될 수 있도록
hashcod()와 equuals()메서드가 재정의 되어 있다.
- 키는 저장된 값을 찾는데 사용되는 것이기 때문에 컬렉션 내에서
HashMap의 선언
Map<키 타입, 값 타입> map = new HashMap<키 타입, 값 타입>();✍ HashMap 코드 예시)
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<String, Integer>();
// 데이터 추가하기
// -> 중복을 허용하지 않는다. (마지막에 들어간 값이 저장된다.)
map.put("국어", 95);
map.put("수학", 90);
map.put("영어", 85);
map.put("수학", 100);
map.put("영어", null); // 객체를 넣는 것이므로 Null 사용 가능
// 저장된 갯수을 얻기
System.out.println("HashMap size : " + map.size());
System.out.println("-------------------------------------");
// 데이터 꺼내기
System.out.println(map.get("국어"));
System.out.println(map.get("영어"));
System.out.println(map.get("수학"));
System.out.println("-------------------------------------");
// 반복문으로 탐색 -> HashMap은 순서가 유지되지 않는다.
Set<String> keySet = map.keySet();
Iterator<String> it = keySet.iterator();
while(it.hasNext()) {
String key = it.next();
Integer value = map.get(key);
System.out.println(key + " : " + value);
}
}
}👉 실행 결과
HashMap size : 3
-------------------------------------
95
null
100
-------------------------------------
국어 : 95
수학 : 100
영어 : null참고자료 : <Java의 정석>, <이것이 자바다>