AWS Lambda에 FastAPI YOLO 모델 배포하기
프로젝트 개요
본 프로젝트는 간단한 물고기 종 분류 YOLO 모델을 활용하여,
백엔드 서비스를 혼자서 설계·배포까지 완주해보는 것을 목표로 한 개인 프로젝트이다.
동기
데이터 사이언스를 전공하며 모델을 구현하는 경험은 많았지만, 해당 모델이 실제 서비스 환경에서 어떻게 배포되고 운영되는지는 직접 경험해보지 못한 영역이었다.
특히 이전 팀 프로젝트에서는 주로 기능 구현에 집중했기에, 인프라 설계부터 배포까지의 전 과정을 직접 책임지는 경험에 갈증이 있었다.
이에 본 프로젝트에서는 모델의 성능 고도화보다는 모델을 포함한 백엔드 서비스를 설계부터 배포까지 혼자서 완주하는 경험을 목표로 삼았다.
서비스 구성 및 구현 범위
기존에 제작해두었던 물고기 종 분류 YOLO 모델을 기반으로, 해당 모델을 호출할 수 있는 백엔드 API를 FastAPI로 구성하고, 모바일 클라이언트에서는 Kotlin(Android)을 사용해 서비스를 구현하였다.
또한, 단순히 추론 기능만 있는게 아니라 엄연히 서비스다운 모습을 갖추기 위해 수집 요소를 추가하였다. 포켓몬고의 도감 시스템처럼, 사진 분석 결과로 등장한 종(예: 상어, 해파리)을 사용자가 사전에 등록·확인할 수 있는 기능을 추가하였다.
서비스 운영에 필요한 데이터와 사용자 수집 정보는 DynamoDB에 저장하였으며,클라이언트에서 생성한 랜덤 UUID를 사용자 식별자로 사용하여, 로그인 기능을 따로 구현하지 않고도 사용자 식별이 가능하도록 하였다.
Lambda 선택 배경
원래 서버를 EC2로 띄우려고 했는데 프리티어 기간이 만료가 되었다(...)
개인 프로젝트라는 특성상 서버 운영과 비용 관리에 많은 리소스를 쓰고 싶지 않았기 때문에 프리티어를 넉넉하게 제공해주고 운영 부담도 적은 AWS Lambda를 서버 실행 환경으로 선택하였다.
AWS Lambda 서비스는 DynamoDB와 같은 ServerLess서비스이기 때문에, DynamoDB와 연계되어 서버 관리가 거의 필요 없는 완전한 서버리스(Serverless) 아키텍처를 구성할 수 있다는 장점도 있었다.
서버리스라는 표현은 서버가 존재하지 않는다는 의미가 아니라, 개발자가 서버의 운영·확장·장애 대응을 직접 관리하지 않아도 된다는 의미이다.
AWS에서 알아서 운영, 수요 예측 등을 다 해주기 때문에 서버 안정성이나 스케일링에 대한 고민없이 개발자는 오직 서비스의 개발에만 집중할 수 있다.
게다가 EC2는 서버가 24시간 내내 돌아가기 때문에 서버를 실행하는 동안 비용이 지속적으로 발생하는 반면, Lambda는 이벤트가 발생할 때만 실행되는 온디맨드 방식으로, 월별 320만초 or 40만 GB-Second 까지 무료라 소규모 개인 프로젝트에서는 거의 무료로 평생 사용할 수 있다.
다만 AWS에서 자체적으로 여러 서비스들을 결합해 자동으로 관리해주는 거라 아키텍처가 복잡하게 얽혀있다는 단점과, 한 번 서버리스 방식으로 서버를 구축하면 다른 방식으로 마이그레이션이 쉽지 않다는 단점이 있다. (한마디로 AWS 람다 서비스 종료되면 내 서비스도 영원히 종료된다는것... 근데 람다 서비스가 끝날 가능성도 거의 0%이긴하다.) 그리고 Stateless한 서비스이기 때문에 EC2처럼 EBS같은 메모리에 데이터 저장이 불가능하다. 람다 자체에 저장 기능이 없기 때문에, 기억해야 할 데이터가 있다면 반드시 S3나 DB같은 외부 저장소가 필요하다.
물론 람다에게도 아주 작은 로컬 디스크 공간인 /tmp 폴더(최소 512MB 제공)가 있긴 하다.
그러나 이 역시 함수가 종료되고 컨테이너가 내려가면 삭제된다. 주로 실행 중에 잠깐 압축을 풀거나, 큰 파일을 임시로 내려받아 처리하는 용도로만 사용된다.
Lambda 이용하여 배포하기
일반적으로 람다에 서버를 배포하려면 그냥 라이브러리와 코드를 zip파일로 묶어서 올리면 된다. 이 방식은 환경설정에 문제만 없다면(EC2랑은 다르게 OS환경이 리눅스로 고정되어있어 다른 OS를 선택할수 없다.) 매우 간단하지만 파일이 50MB 이하여야 한다.
하지만 내가 만든 서비스는
1. 모델 파일과 무거운 라이브러리등이 포함되어 있기 때문에 용량이50MB을 한참 넘어가고
2. PyTorch, OpenCV, NumPy 같은 라이브러리는 빠른 연산을 위해 내부에 OS별로 컴파일된 바이너리 파일을 포함하고 있다. 그런데 내 컴퓨터(윈도우)에서 설치한 라이브러리에는 윈도우용 바이너리가 들어있어서, 이를 그대로 압축해 리눅스 환경인 람다에 올리면 해당 바이너리를 실행할 수 없어 충돌이 발생한다.
그리하여 이런 용량과 버전충돌 문제를 해결하기 위해 도커를 이용하여 배포하기로 하였다.(도커는 10GB까지 가능하다!)
Mangum 라이브러리 설정
먼저 Mangum라이브러리를 설치해주어야 하는데 이게 왜 필요하냐면...
AWS Lambda는 HTTP 서버가 아닌 이벤트 기반 실행 환경이기 때문에,
클라이언트의 HTTP 요청을 직접 처리할 수 없다. 대신 API Gateway가 앞단에서 요청을 받아 이를 Lambda Event(JSON) 형식으로 변환해 Lambda에 전달한다.
이때 람다 안의 FastAPI에게 Lambda Event(JSON)객체를 그대로 전해주면 FastAPI가 무슨 말인지 못 알아먹기 때문에 다시 FastAPI가 이해할 수 있는 ASGI객체로 변환해주어야 한다.(FastAPI는 ASGI 기반의 웹 애플리케이션 프레임워크이기 때문)
따라서 API Gateway를 통해 전달된 Lambda Event(JSON)를 FastAPI가 이해할 수 있는 ASGI 요청 객체로 변환하는 어댑터 계층이 필요하며, 이 역할을 Mangum이 해줄것이다.
- 로컬 환경에서는 주로 Uvicorn이라는 웹 서버가 API 게이트웨이와 Mangum의 역할인 HTTP 소켓 연결과 ASGI 변환을 혼자 수행해준다.
Mangum공식 깃허브에 들어가보면 Fastapi를 사용한 Mangum호출법이 나와있다.
[Mangum 공식 깃허브]
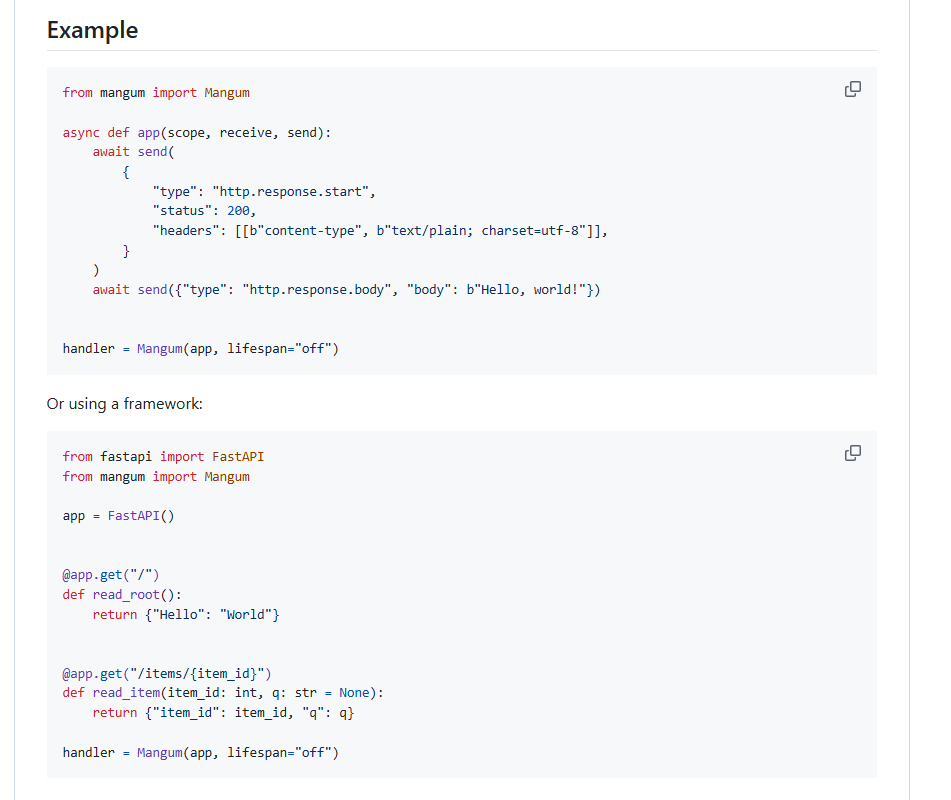
간단하게 Handler변수를 기존 코드 밑에 추가해주면 되는데, Handler는 람다가 신호를 받았을때 처음 실행시키는 진입 함수이다.
만들어둔 Fastapi의 app객체를 Mangum에 전달하고 이걸 handler변수에 저장한다. 그럼 람다가 실행되면 자동으로 이 handler 변수(app객체가 전달된 Mangum 객체)를 찾아서 실행하게 된다.
[파이썬 람다 핸들러 함수 정의]
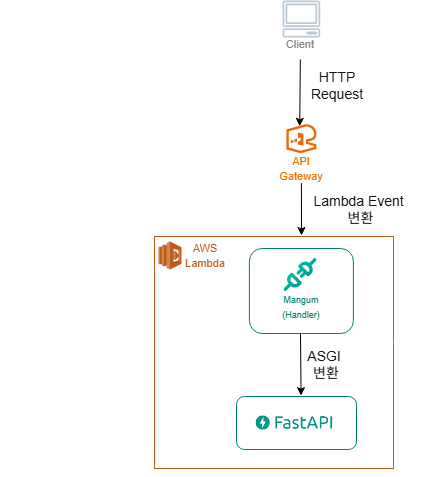
클라이언트(https 소켓) -> API 게이트웨이(JSON 변환) -> Lambda -> mangum(ASGI 변환) -> FastAPI 코드 돌아감
대략적으로 이런 구조를 예상했다.
Dockerfile 이미지 만들기
이제 handler까지 추가해준 코드파일을 도커 이미지로 구워보자. 우선 도커 설정이 들어있는 Dockerfile을 작성해주어야 한다.
작성한 내용은 다음과 같다
FROM public.ecr.aws/lambda/python:3.10
RUN yum install -y mesa-libGL
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN pip install --no-cache-dir -r requirements.txt
COPY . ${LAMBDA_TASK_ROOT}
CMD [ "main.handler" ]yum install -y mesa-libGL는 소스 코드에서 사용된 OpenCV와 YOLO가 이미지를 행렬로 계산할 때 사용하는 그래픽 관련 라이브러리인데 람다용 리눅스에는 이게 빠져있기 때문에 별도로 설치해준다.
그리고 requirements.txt의 라이브러리 목록을 설치할때는 용량 확보를 위해 --no-cache-dir옵션을 넣어준다.(보통 pip은 재설치를 대비해 설치 파일을 임시로 저장(Cache)해 두기 때문에.)
라이브러리 설치는 매우 오래 걸리기 때문에 이후 main.py 소스파일 수정이 있을시, 또 다시 처음부터 설치될일이 없도록 Dockerfile 상단에서 먼저 라이브러리를 설치한다.
Docker는 위쪽 레이어에 변경이 발생하면 그 아래 모든 레이어의 캐시를 무효화하고 다시 실행하기 때문에, 변경 가능성이 낮은 라이브러리 설치 단계를 앞부분에 배치하고 이후에 소스 코드와 모델 파일을 복사하도록 구성한 것이다.
.dockerignore에 쓸데없는 파일들까지 같이 빌드되지 않도록 파일을 추가해준다. 가상환경에서 테스트로 여러 라이브러리들을 설치하고 실행해보았가 때문에, 무조건 제외 목록에 추가해주어야 쓸데없는 용량이 소모되지 않고 빌드 시간이 길어지지 않는다.
__pycache__/
venv/
.venv/
.git/
.env또한 프로젝트에 사용된 라이브러리 목록을 기재한 requirements.txt도 작성해준다.
# FastAPI 및 람다 핸들러
fastapi
mangum
python-multipart
# AWS 서비스 연동
boto3
# AI 모델 및 수치 계산 (CPU 전용 버전으로 용량 최적화)
--index-url https://download.pytorch.org/whl/cpu
torch
torchvision
ultralytics
# 이미지 처리 (람다 에러 방지용 화면 띄우는 GUI기능이 없는 headless 버전)
opencv-python-headless
Pillow
numpy--index-url https://download.pytorch.org/whl/cpu는 torch와 torchvision을 보다 가벼운 CPU버전으로 설치하라는 명령어이다. 그냥 설치하면 도커가 무거운 GPU용 파일(수 GB)까지 다 받아오려고 하는데, 이걸 적어주면 람다에 딱 맞는 가벼운 CPU 전용 파일만 찾아낸다.
애초 람다는 GPU가 없기 때문에 GPU용 파일을 깔아봤자 쓰지도 못하고 실행 속도만 느려진다...
이렇게 준비가 되었으면 docker build -t fish-app . 명령어로 도커를 빌드해준다.
🛠️ Troubleshooting: Docker pytorch 라이브러리 버전 오류
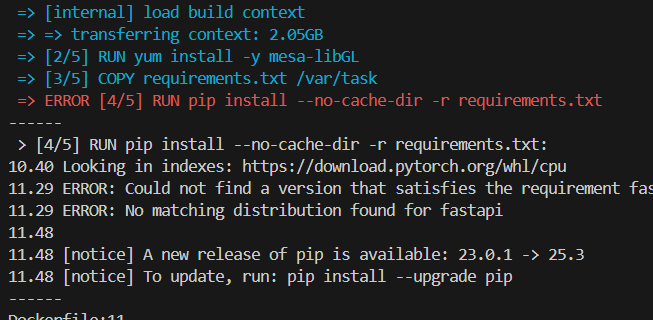
도커 이미지 빌드 중 에러가 뜨며 빌드가 중단되었다.
원인 :
뜬 에러 메시지는 다음과 같다.
Looking in indexes: https://download.pytorch.org/whl/cpu ERROR: Could not find a version that satisfies the requirement fastapi
라이브러리들을 설치하는 과정에서 에러가 생겼는데, cpu용 pytorch설치하라고 입력해준 주소에서 쌩뚱맞게 fastapi를 찾아서 다운로드 하려다가 없으니까 뜬 에러 메시지이다. 아무래도 --index-url https://download.pytorch.org/whl/cpu명령이 다른 라이브러리들 설치될때도 적용이 되었던 모양이다.
1차 시도 :
fastapi
mangum
python-multipart
boto3
opencv-python-headless
Pillow
numpy
ultralytics
# torch 종류만 아래 url에서 다운
--extra-index-url https://download.pytorch.org/whl/cpu
torch
torchvision--extra-index-url명령어로 변경해준다. 해당 명령어는 일단 pip가 PyPI에서 해당 라이브러리를 찾아본다음 없으면 그때 해당 url에서 다운받는 명령어이다.
이제 다시 빌드를 해준다.
=> [4/5] RUN pip install --no-cache-dir -r requirements.txt 450.3s
=> => # Installing collected packages: triton, nvidia-cusparselt-cu12, mpmath, urllib3, typing-extensions, sympy, six, pyyaml, python-multipart, pyparsing, psuti
=> => # l, polars-runtime-32, Pillow, packaging, nvidia-nvtx-cu12, nvidia-nvjitlink-cu12, nvidia-nccl-cu12, nvidia-curand-cu12, nvidia-cufft-cu12, nvidia-cuda-ru
=> => # ntime-cu12, nvidia-cuda-nvrtc-cu12, nvidia-cuda-cupti-cu12, nvidia-cublas-cu12, numpy, networkx, MarkupSafe, kiwisolver, jmespath, idna, fsspec, fonttool
=> => # s, filelock, cycler, charset_normalizer, certifi, annotated-types, annotated-doc, typing-inspection, scipy, requests, python-dateutil, pydantic-core, pol
=> => # ars, opencv-python-headless, opencv-python, nvidia-cusparse-cu12, nvidia-cudnn-cu12, mangum, jinja2, exceptiongroup, contourpy, pydantic, nvidia-cusolver
=> => # -cu12, matplotlib, botocore, anyio, torch, starlette, s3transfer, ultralytics-thop, torchvision, fastapi, boto3, ultralytics 그런데 몇십분이 지나도 빌드가 끝나지 않고 딱 봐도 뭔가 웅장한 라이브러리들이 우후죽순 설치되고 있다는 로그가 뜨더니...
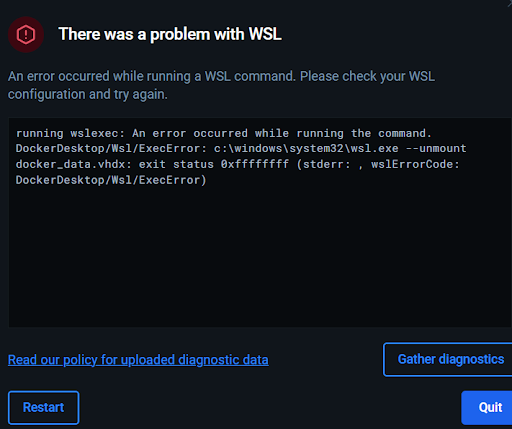
결국 WSL(윈도우용 리눅스 가상 엔진) 용량 부족 엔딩.
원인 :
--extra-index-url 명령어는 먼저 PyPI를 살펴보고 PyPI에 존재하지 않으면 https://download.pytorch.org/whl/cpu에서 cpu버전을 다운받는다고 하지 않았는가?
그런데 PyPI에 pytorch GPU버전이 이미 존재하기 때문에 pip는 응? https://download.pytorch.org/whl/cpu 갈 필요 없겠는데? 하고 그냥 PyPI에서 GPU버전 다운받아 버린 거다.
위의 여러 라이브러리들 중 nvidia-로 시작하는 라이브러리들은 GPU 연산용 부품들인데(람다에서 돌리지도 못하는), 이것들이 다 합쳐지면 이미지 용량이 어마어마하니 연약한 내 컴퓨터가 버틸리가 없다.
2차 시도 :
일단 wsl --shutdown명령어로 wsl을 강제종료 시키고, docker system prune -a --volumes 명령어로 도커 이미지, 컨테이너, 캐시 등등 전부 다 지워 초기화 시켜 용량을 정상화시킨다. (14GB가 지워졌다ㄷㄷ)
--extra-index-url https://download.pytorch.org/whl/cpu
torch==2.0.1+cpu
torchvision==0.15.2+cpu
ultralytics
fastapi
mangum
python-multipart
boto3
opencv-python-headless
Pillow
numpy이번엔 GPU용 라이브러리 설치를 막기 위해, torch와 torchvision 뒤에 cpu버전까지 확실하게 명시해주었다.
그리고 빌드....

C:\Users\khsta\OneDrive\바탕 화면\Python\fish_application>docker build -t fish-app .
[+] Building 685.7s (10/10) FINISHED docker:desktop-linux
FINISHED문구와 함께 빌드가 성공했다.
결과 :
도커 데스크탑에서도 만들어진 이미지를 볼 수 있다.
빌드가 완료되었으니 docker run -p 8080:8080 fish-app명령어로 람다 환경을 모방한 서버를 내 컴퓨터의 8080포트로 띄운다.
그리고 docker run -p 8080:8080 -e AWS_DEFAULT_REGION=ap-northeast-2 fish-app 도커 실행 명령어를 실행하면(-e AWS_DEFAULT_REGION=ap-northeast-2는 리전 환경 변수 정해주는 것)
C:\Users\khsta\OneDrive\바탕 화면\Python\fish_application>curl -XPOST "http://localhost:8080/2015-03-31/functions/function/invocations" -d '{}'
{"errorMessage": "Unable to unmarshal input: Expecting value: line 1 column 1 (char 0)", "errorType": "Runtime.UnmarshalError", "requestId": "57fac8c5-7236-4834-a764-ef6f3dd447b1", "stackTrace": []}다음과 같은 결과가 나온다. 에러메시지이긴 한데 Runtime.UnmarshalError은 분석할 이미지가 함께 오지 않았다는 뜻이라서 일단 서버가 돌아가고 있다는 뜻이다.
ECR 설치
ECR은 도커 컨테이너 전용 저장소라고 생각하면 된다. 람다에 도커로 배포하려면 무조건 ECR을 거쳐야 한다.

aws 콘솔에서 ECR 리포지토리를 하나 생성해준다.
AWS CLI로 IAM 사용자 로그인을 해 주고
IAM 권한에 EC2ContainerRegistryFullAccess를 추가해주면 된다.(내 IAM계정은 AdministratorAccess가 부여되어 있어 필요없음)
그리고 ECR콘솔창에 있는 푸시 명령 보기버튼을 누르면
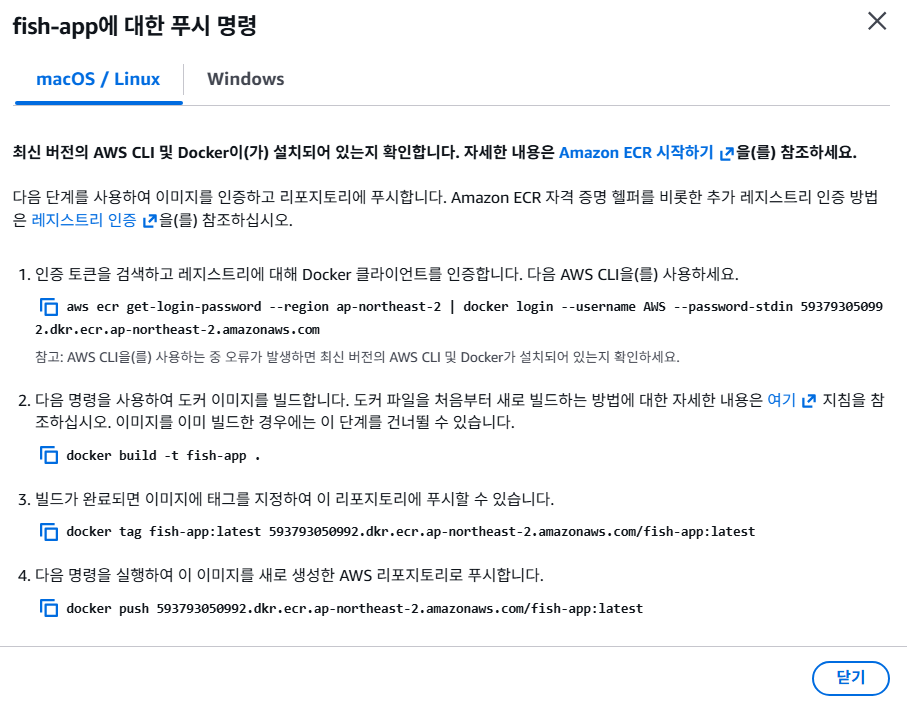
다음과 같은 명령어들을 안내해주는데 그냥 복붙하면 된다.(2번은 이미 빌드했으니 패스)

이미지가 ECR에 잘 올라갔다.
람다 함수 생성
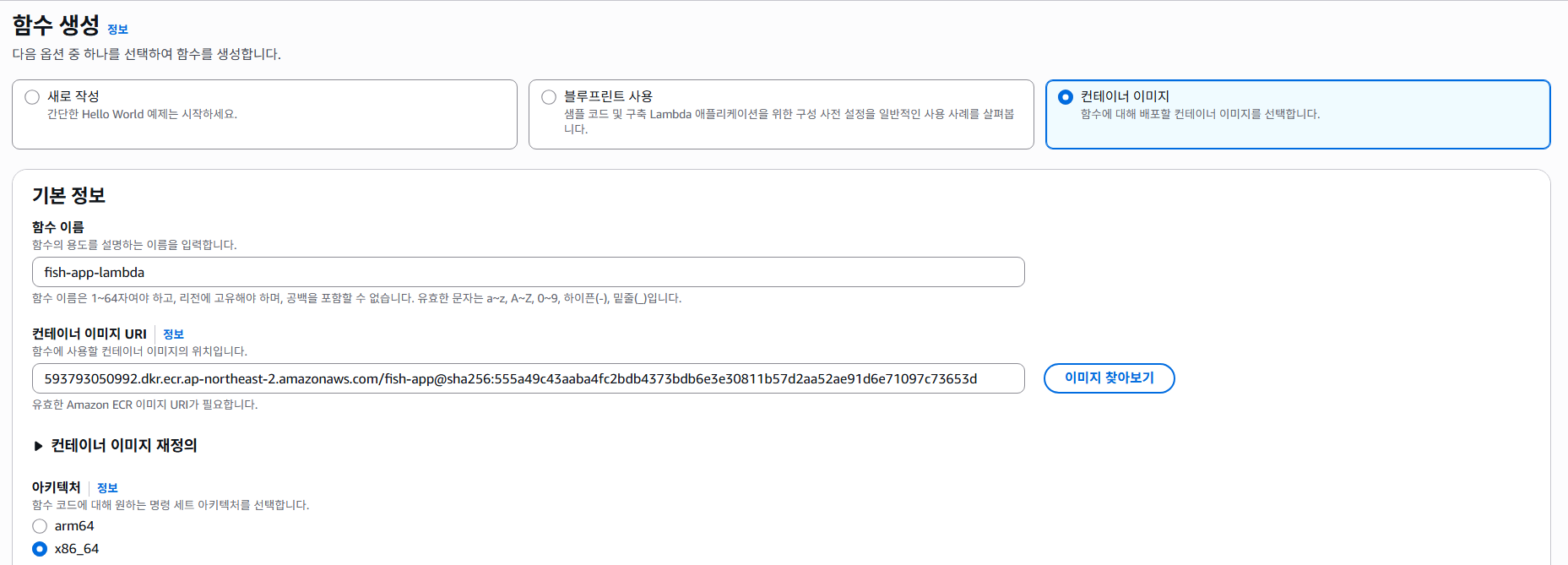
이제 람다 함수를 생성해보자. 컨테이너 이미지 옵션을 선택하고 함수 이름을 입력해준뒤 방금 리포에 올린 이미지를 선택해주면 된다.
🛠️ Troubleshooting: Lambda의 'Not Supported' 이미지 에러 해결

콘솔에서 람다 함수를 생성하려는데 에러 창이 떴다
원인 :
AWS 람다 공식문서 요구사항 탭을 보면
Lambda는 다중 아키텍처 기본 이미지를 제공합니다. 하지만 함수에 대해 빌드하는 이미지는 아키텍처 중 하나만 대상으로 해야 합니다. Lambda는 다중 아키텍처 컨테이너 이미지를 사용하는 함수를 지원하지 않습니다.
라고 기재되어 있다.
도커의 최신 빌드 엔진인 buildx의 v0.10 이상 버전에서는 여러 CPU 환경을 지원하기 위해 기본적으로 OCI image index 형식을 사용해 멀티 플랫폼 이미지를 빌드하는데, 위 문서 내용처럼 람다는 다중 아키텍처 컨테이너 이미지(=멀티 플랫폼 이미지)를 지원하지 않아 manifest not supported 에러가 발생한것이다.
최신 Docker Buildx 환경에서는 기본적으로 OCI Image Index 형식을 사용하며, 빌드 메타데이터인 Provenance를 포함시킨다. 하지만 AWS Lambda는 단일 플랫폼의 Docker V2 Manifest 포맷만 지원하기 때문에, manifest not supported 에러가 발생한것이다.
해결 방법 :
간단히 메타데이터인 Provenance를 제외시키는 --provenance=false 옵션을 붙여 형식을 강제 변환시킨 후 다시 빌드해주면 단일 이미지 포멧으로 다시 빌드된다.
docker build --platform linux/amd64 --provenance=false -t fish-app:latest .
위 명령어로 다시 이미지를 구워준다.
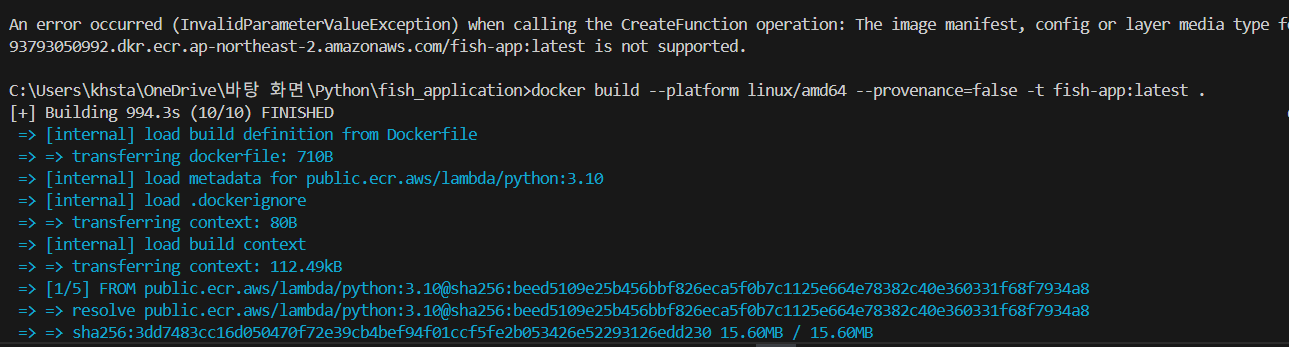
결과:
굿. 람다함수가 잘 생성되었다.
람다 함수 설정 변경:
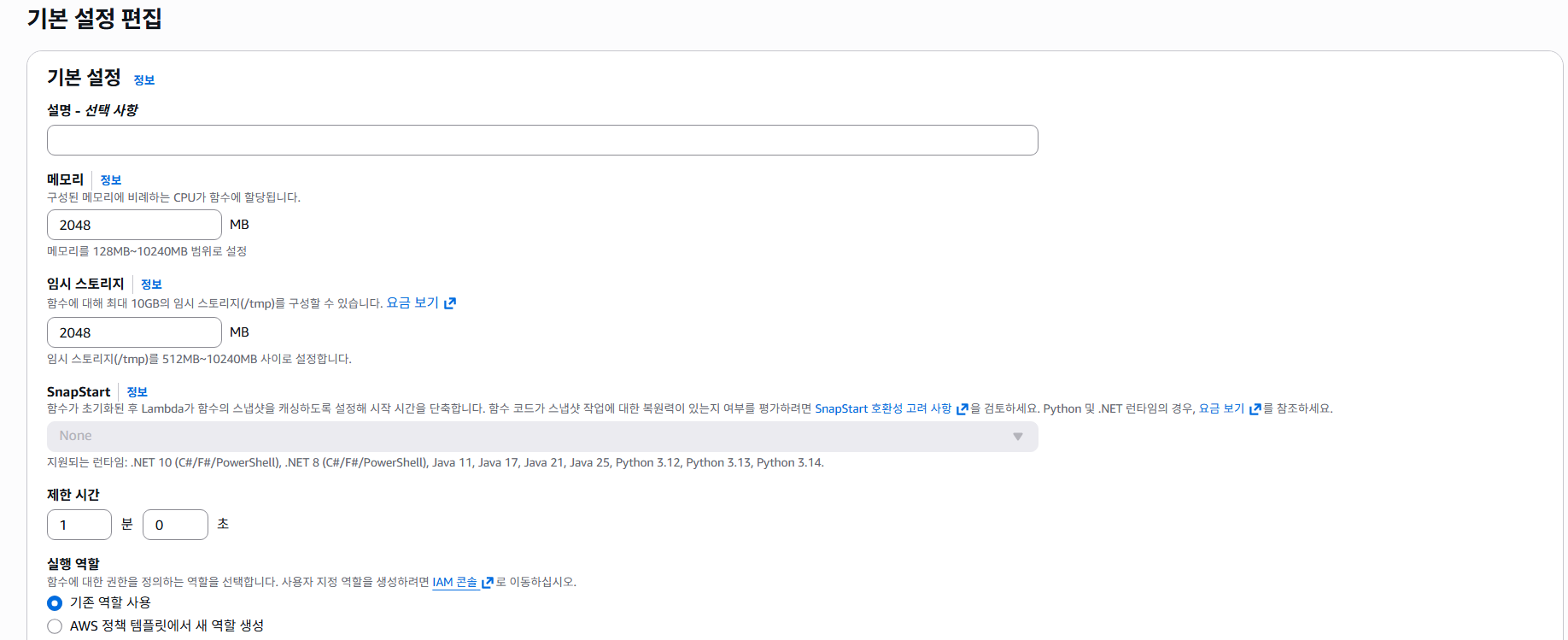
함수가 생성되었으니 설정을 조금 바꿔준다. 무거운 모델이 돌아가야 하기 때문에 메모리와 제한 시간을 2048MB, 1분으로 늘려주었다.(기본설정은 128MB에 3초)
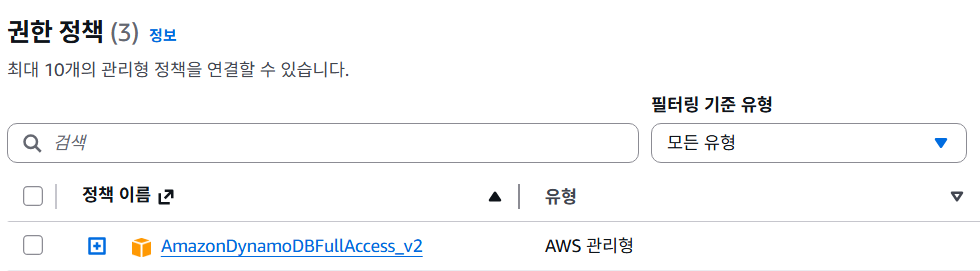
또한, AWS Lambda 콘솔 → [구성] → [권한(Permissions)] → 역할 이름(Role name) → [권한 추가] → [정책 연결]에서 AmazonDynamoDBFullAccess_v2 권한을 검색하여 dynamoDB에 대한 권한을 추가해 준다.
API 게이트웨이
인터넷 게이트웨이랑 다른거다.
람다는 정확히 말하면 일반 서버처럼 데이터를 stream형식으로 받는게 아니라 이벤트에 의해 실행되는 함수이기 때문에 클라이언트와 TCP연결을 맺지 않는다.
이때 람다의 앞에서 API 게이트웨이가 대신 클라이언트와 TCP연결을 맺고, 들어온 HTTP 요청을 JSON 이벤트 객체로 변환하여 람다에 넘겨준다.
왜 JSON으로 변환해줘야 함?
람다(Lambda) 함수가 '입력값'으로 받을 수 있는 유일한 표준 규격이 JSON 형식의 이벤트 객체이기 때문에.
물론 2022년에 람다 함수 URL(Function URL)이라는 람다 내장 기능이 추가되어, API 게이트웨이 없이 람다만으로도 고유한 URL 엔드포인트를 생성하고 JSON 규격(Payload Format 2.0)으로 변환하는게 가능해졌지만, API 게이트웨이는 JSON 이벤트 형식 변환 외에도 요청 속도 제한(Throttling), 캐싱, 그리고 보안 및 인증 등 여러 기능을 수행해주기 때문에 앵간하면 람다랑 같이 쓰는 게 좋다.
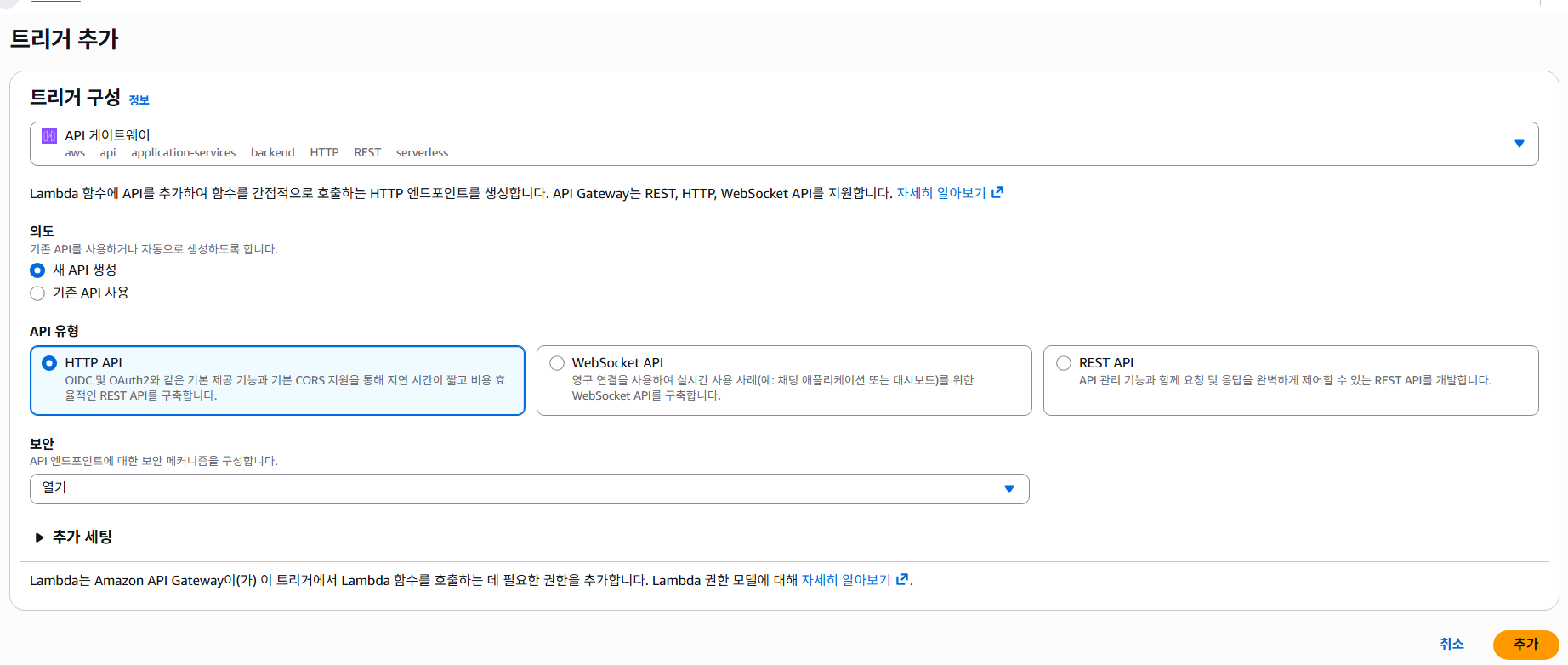
람다 함수의 트리거 추가를 눌러 API 게이트웨이를 생성해준다.
🛠️ Troubleshooting: API 게이트웨이 스테이지 경로 주소 오류

생성된 주소로 Postman을 이용해서 형식을 맞춰 요청을 보내봤지만 계속해서
404 Not Found 응답이 뜨며 2ms대의 짧은 실행 이후 끊겼다.
원인 :
Gemini에게 물어보니 "detail": "Not Found" 메시지는 FastAPI 프레임워크가 공식적으로 내보내는 404 에러 양식이기 때문에, 람다 함수쪽이 문제가 아니라 FastAPI 쪽의 문제일 확률이 높고, 이 경우엔 서버(FastAPI)가 요청을 받자마자 담당경로가 아니기 때문에 바로 거절을 한 것 같다고 했다.
API 엔드포인트 주소를 확인해보면 https://아이디.execute-api.리전.amazonaws.com/default/{proxy+} 라고 되어있다. 호스트주소 바로 뒤에 default라는 경로가 붙은 것이 보인다. ({proxy+}는 FastAPI의 api엔드포인트가 오는 곳)
문제는 FastAPI의 라우팅 방식이다. FastAPI는 호스트 주소 이후의 전체 경로인 /default/{proxy+}를 자신의 라우팅 테이블과 대조한다. 하지만 내 서버 코드는 /analyze처럼 루트 경로를 기준으로 설계되어 있다 보니, 앞에 붙은 /default라는 불청객 때문에 경로를 찾지 못하고 404 Not Found를 뱉으며 즉시 종료되었던 것이다.
그렇다면 저
default의 정체는 무엇인가?
API Gateway는 개발용(dev), 테스트용(test), 실제 배포용(prod)등의 버전(Stage)을 관리하기 위해 https://아이디.execute-api.리전.amazonaws.com/스테이지명/~~ 같이 스테이지 이름을 주소에 강제로 포함한다.
현재 나의 코드 같은 경우 기본(default) 스테이지를 사용 중이라 주소 중간에 /default가 자동으로 박혀버린 것이다.
해결 방법1:
요청 코드 주소 자체를 바꾸어주는 방법이다.
API 게이트웨이의 주소에 맞추어, FastAPI의 루트 주소에 /default를 포함해준다.
기존의 app = FastAPI()를 다음과 같이 바꾸어준다.
app = FastAPI(root_path="/default")이러면 모든 주소 앞에 /default가 자동으로 붙게되어 /default/{proxy+}형식을 만족시킨다.
해결 방법2:
람다에 접속하는 URL을 아예 다른 주소로 사용하는 방법이다.
위에서 명시했듯이 람다 함수 URL을 사용하면, API 게이트웨이 없이 람다만으로도 고유한 URL 엔드포인트를 생성하고 자체적으로 JSON으로 변환하는것이 가능하다.
람다 함수의 [구성] 탭에서 쉽게 함수 URL을 생성할 수 있다.
두 방법으로 만들어진 주소들을 모두 테스트 해봤더니 200 OK 결과와 함께 정상적으로 분석 결과가 나온것을 볼 수 있었다.
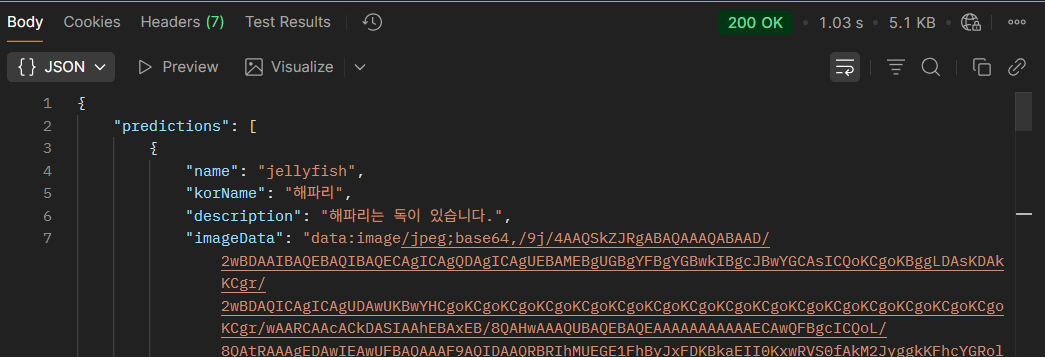
최종적으로는 API 게이트웨이 대신 함수 URL을 선택했는데, 그 이유로는
-
API 게이트웨이의 스테이지 경로 문제가 해결되어 FastAPI의 라우팅이 꼬이는 문제가 다시 생길 걱정이 없고
-
API Gateway는 요청 횟수에 따라 별도의 요금이 발생하지만, 함수 URL은 완전히 무료이기 때문에 비용 걱정이 없으며
-
API Gateway는 최대 타임아웃이 29초로 제한되어 있어, 무거운 인공지능 모델(YOLO 등)을 돌릴 때 시간이 부족할 수 있는데, 반면 함수 URL은 람다 자체의 최대 타임아웃인 15분까지 그대로 사용할 수 있어 타임아웃 제한이 완화된다.
물론 API Gateway를 통해 인가(Authorizer)나 유량 제어(Throttling) 등 정교한 기능을 활용할 수 있으나, 나의 프로젝트 같은 경우 1. 서비스의 복잡도가 낮고 2. 별도의 사용자 인증 및 인가를 요구하지 않는 서비스이기 때문에 현재 프로젝트의 규모와 빠른 프로토타이핑이라는 목적을 고려했을 때, 불필요한 복잡성을 줄이고 직관적인 아키텍처를 유지할 수 있는 함수 URL이 더 적합하다고 판단하여 최종 선택하게 되었다.
최종 프로젝트 아키텍처
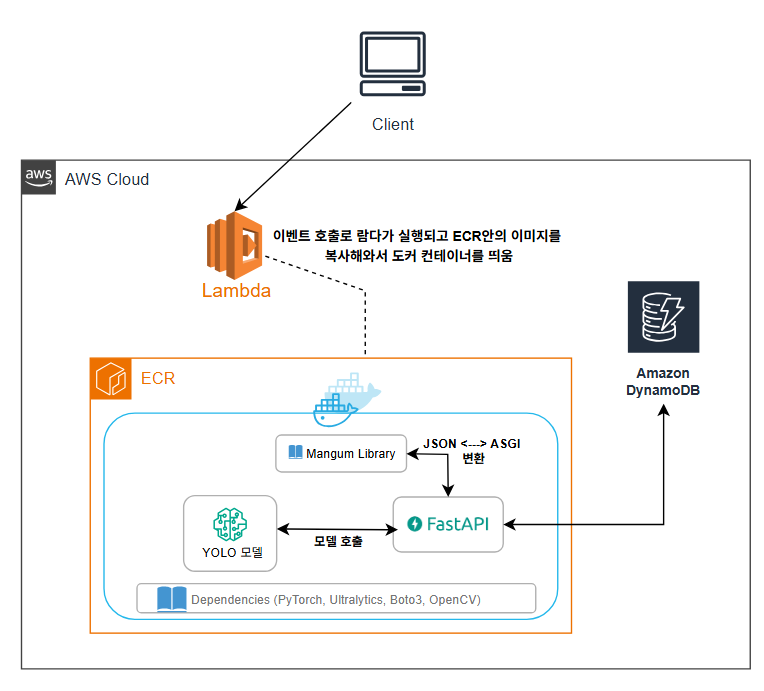
추가적인 성능 개선은 해당 포스팅에서 -> [Lambda Cold Start 해결]
