문제풀이
0에 위치한 개구리가 X+1로 가기 위한 최단 시간을 구하는 문제이다. 배열 A에 주어진 숫자들은 각 초(인덱스)에 떨어진 나뭇잎의 위치를 가리킨다. 그리고 X+1로 가기 위한 길이 완성된 최단 시간을 구하면 된다.
ex.배열 A가 [1,3,1,4,2,3,5,4]라면 0초엔 1번 위치, 1초엔 3번 위치에 떨어진다는 뜻. 최단 시간은 2번 위치에 나뭇잎이 떨어진 다음 초인 5초.
고민 포인트
문제 주요 조건들을 정리해보면
1. 1~X까지가 매워져야함
2. 이동 불가능이라면 -1반환
3. 시간 복잡도 효율성 생각하기
어떻게 할 지 고민되었던 지점
이미 나온 위치인지 아닌지 어케 구분하지?
-> 얘만 구분되면 개수를 세든 해서 길이 완성되었는지 여부 판단은 쉬울듯
일단 1차원적으로 X크기의 배열을 만든 다음에 전부 -1로 초기화해서, A배열에서 해당하는 위치의 숫자를 발견하면 그 배열의 해당 인덱스를 양수로 바꾸는 방법을 생각해보았다. 그런데 이 방법은 배열A를 X번 순회하는 것도 시간복잡도가 큰데, X크기의 배열이 전부 양수가 되었는지 또한 계속해서 검토를 해주어야 하기 때문에 무조건 시간 초과할 것 같아서 기각.
그래서 1~X까지 빠짐없이 매워야 한다는 특징을 이용했다. 즉, 랜덤한 숫자를 찾는게 아니므로 1~X까지의 정돈된 수를 차례대로 찾아간다는 느낌.
두 방식의 차이라고 한다면 두 번째 방법은 수를 차례대로 찾기 때문에 첫 번째처럼 이미 메워진 위치인지를 검사할 필요가 없이 마지막 칸(X)를 찾으면 바로 다 찾았음을 알 수 있다.
- 배열에서 1~X까지 하나하나 원소를 찾는데 해당 원소를 찾은 인덱스 위치가 큰 것으로 점점 교체해나가기
- 만약 중간에 발견되지 않으면 즉시 중단하고 -1반환
# you can write to stdout for debugging purposes, e.g.
# print("this is a debug message")
def solution(X, A):
result_time = 0
for i in range(1, X+1):
for idx, num in enumerate(A):
if i == num:
if result_time < idx:
result_time = idx
break # 남은 배열 원소들은 확인할 필요 X
# 여기까지 왔다는 것은 배열에 해당 요소가 없다는 뜻
if idx >= (len(A)-1):
return -1
return result_time트러블 슈팅
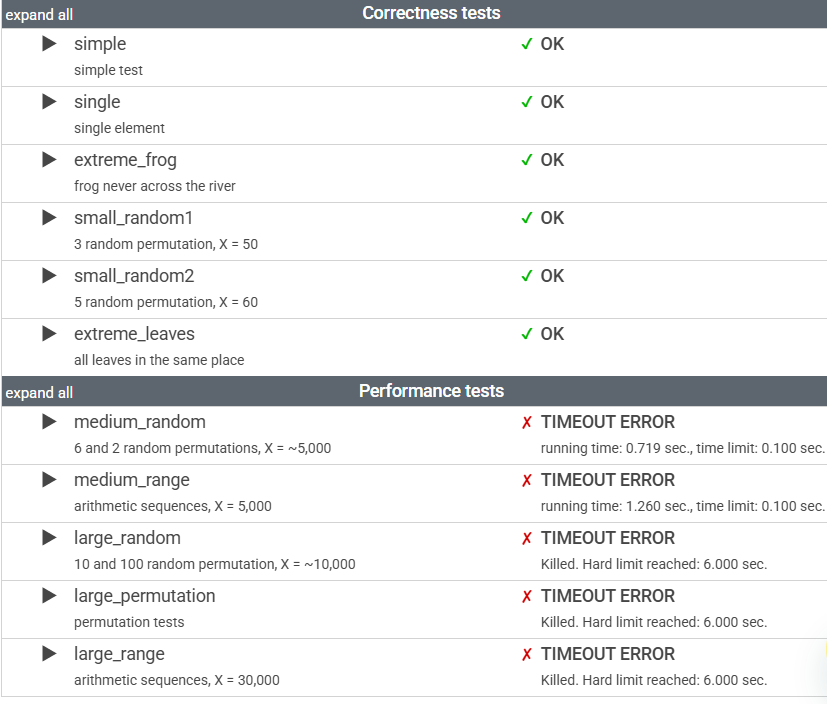
정확성 테스트는 모두 통과했는데 성능 테스트는 모조리 타임아웃 에러가 났다.
지금 코드의 시간복잡도는 O(n^2)이니 여기서 더 줄여야한다. 입력 범위가 이니, 최악의 경우를 가정했을 때 또는 복잡도 내에 해결해야한다.
데이터 크기에 따른 시간 복잡도
보통 코딩문제 제한시간이 1~6초이고 파이썬의 초당 연산 횟수를 대략 20000000회라고 가정.
| 또는 | 재귀, 백트래킹, 완전 탐색 (브루트 포스)
| | 플로이드-워셜, 단순 3중 for문
| | 이중 for문, 삽입 정렬, 거품 정렬
| | 정렬, 이진 탐색, 우선순위 큐(Heap)
| | 단일 for문, 스택, 큐, 해시(Set/Dict)
| | 유클리드 호제법, 고속 거듭제곱
위의 표는 N의 범위별 적용하기 적절한 시간복잡도이다.
예를들어 N의 범위가 1,000,000이하라면 시간복잡도가 N이거나 logN인 방법으로 풀 수있다. 이것보다 큰 것들(ex.N^2)을 사용하면 시간초과.
원래 코드는 O(N^2)의 시간복잡도라 100000 x 100000 = 10000000000(100억) 번의 연산이 수행된다. 즉, 100억 % 2천만 = 500(초)가 걸린다는 소리.
중요한건 N의 입력가능 범위! 가능하면 N의 최악의 연산 횟수가 1000만 단위를 넘지 않게 하는게 좋다. (파이썬의 연산 횟수를 고려했을때)
그래도 이참에 시간복잡도 계산법은 확실히 알고가게 된 듯...
배열을 정렬 후 이진탐색하는것을 생각해봤는데 이건 잎이 떨어진 순서가 섞여버려서 안된다.
도저히 아이디어가 생각이 안 나서 AI에게 힌트를 달라했더니 Set이나 체크 배열을 활용하여 전체를 단 한 번만 훑어보되 그때그때 새로운 것을 발견하면 찾은 개수를 증가시키라 조언을 주었다. 이러면 언제 다 찾았는지도 쉽게 알 수 있다.
내가 기존에 짠 코드는 1찾으려고 전체 함 훑고, 2찾으려고 전체 함 훑고 이런 식인데 저 방식은 한 번 쫙 훑을 때 어 3이네? 어 1이네? 하고 새로운 것들 그때그때 찾아내고 한 번 본건 2번 확인하지 않는다. 종료조건 쉽게 알아내는 법에 꽃혀서 효율적인 탐색 방법은 생각 못 한게 패착의 원인인듯.
최종 제출 코드
Set방식
# you can write to stdout for debugging purposes, e.g.
# print("this is a debug message")
def solution(X, A):
visited = set()
for idx, num in enumerate(A):
if num <= X:
visited.add(num)
if len(visited) == X:
return idx # 마지막으로 찾은 수의 인덱스가 젤 클테니까
return -1 # for문에서 끝나지 않았다면 해당 위치가 존재하지 않는다는 뜻뜻
# A를 한 번 순회
# 처음 찾는 위치면 set에 추가(X보다 작은수만 추가가능)
# set의 크기가 X와 같을때까지 반복set은 탐색할때 Hash알고리즘을 사용하기 때문에 값을 추가할때 이미 중복된 값인지 검사할때의 시간복잡도가 O(1)이다.
